Friday, April 24. 2015
Analyst Watch: Ten reasons why open-source software will eat the world
Via SD Times
-----

I recently attended Facebook’s F8 developer conference in San Francisco, where I had a revelation on why it is going to be impossible to succeed as a technology vendor in the long run without deeply embracing open source. Of the many great presentations I listened to, I was most captivated by the ones that explained how Facebook internally developed software. I was impressed by how quickly the company is turning such important IP back into the community.
To be sure, many major Web companies like Google and Yahoo have been leveraging open-source dynamics aggressively and contribute back to the community. My aim is not to single out Facebook, except that it was during the F8 conference I had the opportunity to reflect on the drivers behind Facebook’s actions and why other technology providers may be wise to learn from them.
Here are my 10 reasons why open-source software is effectively becoming inevitable for infrastructure and application platform companies:
- Not reinventing the wheel: The most obvious reason to use open-source software is to build software faster, or to effectively stand on the shoulders of giants. Companies at the top of their game have to move fast and grab the best that have been contributed by a well-honed ecosystem and build their added innovation on top of it. Doing anything else is suboptimal and will ultimately leave you behind.
- Customization with benefits: When a company is at the top of its category, such as a social network with 1.4 billion users, available open-source software is typically only the starting point for a quality solution. Often the software has to be customized to be leveraged. Contributing your customizations back to open source allows them to be vetted and improved for your benefit.
- Motivated workforce: Beyond a good wage and a supportive work environment, there is little that can push developers to do high-quality work more than peer approval, community recognition, and the opportunity for fame. Turning open-source software back to the community and allowing developers to bask in the recognition of their peers is a powerful motivator and an important tool for employee retention.
- Attracting top talent: A similar dynamic is in play in the hiring process as tech companies compete to build their engineering teams. The opportunity to be visible in a broader developer community (or to attain peer recognition and fame) is potentially more important than getting top wages for some. Not contributing open source back to the community narrows the talent pool for tech vendors in an increasingly unacceptable way.
- The efficiency of standardized practices: Using open-source solutions means using standardized solutions to problems. Such standardization of patterns of use or work enforces a normalized set of organizational practices that will improve the work of many engineers at other firms. Such standardization leads to more-optimized organizations, which feature faster developer on-ramping and less wasted time. In other words, open source brings standardized organizational practices, which help avoid unnecessary experimentation.
- Business acceleration: Even in situations where a technology vendor is focused on bringing to market a solution as a central business plan, open source is increasingly replacing proprietary IP for infrastructure and application platform technologies. Creating an innovative solution and releasing it to open source can facilitate broader adoption of the technology with minimal investment in sales, marketing or professional service teams. This dynamic can also be leveraged by larger vendors to experiment in new ventures, and to similarly create wide adoption with minimal cost.
- A moat in plain sight: Creating IP in open source allows the creators to hone their skills and learn usage patterns ahead of the competition. The game then becomes to preserve that lead. Open source may not provide the lock-in protection to the owner that proprietary IP does, but the constant innovation and evolution required in operating in open-source environments fosters fast innovation that has now become essential to business success. Additionally, the visibility of the source code can further enlarge the moat around its innovation, discouraging other businesses from reinventing the wheel.
- Cleaner software: Creating IP in open source also means that the engineers have to operate in full daylight, enabling them to avoid the traps of plagiarized software and generally stay clear of patents. Many proprietary software companies have difficulty turning their large codebases into open source because of necessary time-consuming IP scrubbing processes. Open-source IP-based businesses avoid this problem from the get-go.
- Strategic safety: Basing a new product on open-source software can go a long way to persuade customers who might otherwise be concerned about the vendor’s financial resources or strategic commitment to the technology. It used to be that IT organizations only bought important (but proprietary) software from large, established tech companies. Open source allows smaller players to provide viable solutions by using openness as a competitive weapon to defuse the strategic safety argument. Since the source is open, in theory (and often only in theory) IT organizations can skill up on and support it if and when a small vendor disappears or loses interest.
- Customer goodwill: Finally, open source allows a tech vendor to accrue a great deal of goodwill with its customers and partners. If you are a company like Facebook, constantly and controversially disrupting norms in social interaction and privacy, being able to return value to the larger community through open-source software can go a long way to making up for the negatives of your disruption.
Monday, April 13. 2015
BitTorrent launches its Maelstrom P2P Web Browser in a public beta
Via TheNextWeb
-----

Back in December, we reported on the alpha for BitTorrent’s Maelstrom, a browser that uses BitTorrent’s P2P technology in order to place some control of the Web back in users’ hands by eliminating the need for centralized servers.
Maelstrom is now in beta, bring it one step closer to official release.
BitTorrent says more than 10,000 developers and 3,500 publishers signed
up for the alpha, and it’s using their insights to launch a more stable
public beta.
Along with the beta comes the first set of developer tools for the browser, helping publishers and programmers to build their websites around Maelstrom’s P2P technology. And they need to – Maelstrom can’t decentralize the Internet if there isn’t any native content for the platform.
It’s only available on Windows at the moment but if you’re interested and on Microsoft’s OS, you can download the beta from BitTorrent now.
? Project MaelstromThursday, February 26. 2015
Researchers produce Global Risks report, AI and other technologies included in it
Via betanews
-----

Let's face it, we're always at risk, and I speak for human kind, not just the personal risks we take each time we leave our homes. Some of these potential terrors are unavoidable -- we can't control the asteroid we find hurtling towards us or the next super volcano that may erupt as the Siberian Traps once did.
Some risks however, are well within our control, yet we continue down paths that are both exciting and potentially dangerous. In his book Demon Haunted World, the great astronomer, teacher and TV personality Carl Sagan wrote "Avoidable human misery is more often caused not so much by stupidity as by ignorance, particularly our ignorance about ourselves".
Now researchers have published a list of the risks we face and several of them are self-created. Perhaps the most prominent is artificial intelligence, or AI as it generally referred to. The technology has been fairly prominent in the news recently as both Elon Musk and Bill Gates have warned of its dangers. Musk went as far as to invest in some of the companies so that he could keep an eye on things.
The new report states "extreme intelligences could not easily be controlled (either by the groups creating them, or by some international regulatory regime), and would probably act to boost their own intelligence and acquire maximal resources for almost all initial AI motivations".
Stephen Hawking, perhaps the world's most famous scientist, told the BBC "The development of full artificial intelligence could spell the end of the human race".
That's three obviously intelligent men telling us it's a bad idea, but of course that will not deter those who wish to develop it and if it is controlled correctly then it may not be the huge danger we worry about.
What else is on the list of doom and gloom? Several more man-made problems, including nuclear war, global system collapse, synthetic biology, and nanotechnology. There is also the usual array of asteroids, super volcanoes and global pandemics. For good measure, the scientists even added in bad global governance.
If you would like to read the report for yourself it can be found at the Global Challenges Foundation website. It may keep you awake at night -- even better than a good horror movie could.
Tuesday, February 24. 2015
If software looks like a brain and acts like a brain—will we treat it like one?
Monday, February 23. 2015
Android to Become 'Workhorse' of Cybercrime
Via EE Times
-----
PARIS — As of the end of 2014, 16 million mobile devices worldwide have been infected by malicious software, estimated Alcatel-Lucent’s security arm, Motive Security Labs, in its latest security report released Thursday (Feb. 12).
Such malware is used by “cybercriminals for corporate and personal espionage, information theft, denial of service attacks on business and governments and banking and advertising scams,” the report warned.
Some of the key facts revealed in the report -- released two weeks in advance of the Mobile World Congress 2015 -- could dampen the mobile industry’s renewed enthusiasm for mobile payment systems such as Google Wallet and Apple Pay.
At risk is also the matter of privacy. How safe is your mobile device? Consumers have gotten used to trusting their smartphones, expecting their devices to know them well enough to accommodate their habits and preferences. So the last thing consumers expect them to do is to channel spyware into their lives, letting others monitor calls and track web browsing.
Cyber attacks
The latest in a drumbeat of data
hacking incidents is the massive database breach reported last week by
Anthem Inc., the second largest health insurer in the United States.
There was also the high profile corporate security attack on Sony in
late 2014.
Declaring that 2014 “will be remembered as the year of cyber-attacks,” Kevin McNamee, director, Alcatel-Lucent Motive Security Labs, noted in his latest blog other cases of hackers stealing millions of credit and debit card account numbers at retail points of sale. They include the security breach at Target in 2013 and similar breaches repeated in 2014 at Staples, Home Depot Sally Beauty Supply, Neiman Marcus, United Parcel Service, Michaels Stores and Albertsons, as well as the food chains Dairy Queen and P. F. Chang.
“But the combined number of these attacks pales in comparison to the malware attacks on mobile and residential devices,” McNamee insists. In his blog, he wrote, “Stealing personal information and data minutes from individual device users doesn’t tend to make the news, but it’s happening with increased frequency. And the consequences of losing one’s financial information, privacy, and personal identity to cyber criminals are no less important when it’s you.”
'Workhorse of cybercrime'
Indeed, malware
infections in mobile devices are on the rise. According to the Motive
Security Labs report, malware infections in mobile devices jumped by 25%
in 2014, compared to a 20% increase in 2013.
According to the report, in the mobile networks, “Android devices have now caught up to Windows laptops as the primary workhorse of cybercrime.” The infection rates between Android and Windows devices now split 50/50 in 2014, said the report.
This may be hardly a surprise to those familiar with Android security. There are three issues. First, the volume of Android devices shipped in 2014 is so huge that it makes a juicy target for cyber criminals. Second, Android is based on an open platform. Third, Android allows users to download apps from third-party stores where apps are not consistently verified and controlled.
In contrast, the report said that less than 1% of infections come from iPhone and Blackberry smartphones. The report, however, quickly added that this data doesn’t prove that iPhones are immune to malware.
The Motive Security Labs report cited findings by Palo Alto Networks in early November. The Networks discussed the discovery of WireLurker vulnerability that allows an infected Mac OS-X computer to install applications on any iPhone that connects to it via a USB connection. User permission is not required and the iPhone need not be jail-broken.
News stories reported the source of the infected Mac OS-X apps as an app store in China that apparently affected some 350,000 users through apps disguised as popular games. These infected the Mac computer, which in turn infected the iPhone. Once infected, the iPhone contacted a remote C&C server.
According to the Motive Security Labs report, a couple of weeks later, FireEye revealed Masque Attack vulnerability, which allows third-party apps to be replaced with a malicious app that can access all the data of the original app. In a demo, FireEye replaced the Gmail app on an iPhone, allowing the attacker complete access to the victim’s email and text messages.
Spyware on the rise
It’s important to note that
among varieties of malware, mobile spyware is definitely on the
increase. According to Motive Security Labs, “Six of the mobile malware
top 20 list are mobile spyware.” These are apps used to spy on the
phone’s owner. “They track the phone’s location, monitor ingoing and
outgoing calls and text messages, monitor email and track the victim’s
web browsing,” according to Motive Security Labs.
Impact on mobile payment
For consumers and mobile operators, the malware story hits home hardest
in how it may affect mobile payment. McNamee wrote in his blog:
The rise of mobile malware threats isn’t unexpected. But as Google Wallet, Apple Pay and others rush to bring us mobile payment systems, security has to be a top focus. And malware concerns become even more acute in the workplace where more than 90% of workers admit to using their personal smartphones for work purposes.
Fixed broadband networks
The Motive Security
Labs report didn’t stop at mobile security. It also looked at
residential fixed broadband networks. The report found the overall
monthly infection rate there is 13.6%, “substantially up from the 9%
seen in 2013,” said the report. The report attributed it to “an increase
in infections by moderate threat level adware.”
Why is this all happening?
The short answer to
why this is all happening today is that “a vast majority of mobile
device owners do not take proper device security precautions,” the
report said.
Noting that a recent Motive Security Labs survey found that 65 percent of subscribers expect their service provider to protect both their mobile and home devices, the report seems to suggest that the onus is on operators. “They are expected to take a proactive approach to this problem by providing services that alert subscribers to malware on their devices along with self-help instructions for removing it,” said Patrick Tan, General Manager of Network Intelligence at Alcatel-Lucent, in a statement.
Due to the large market share it holds within communication networks, Alcatel-Lucent says that it’s in a unique position to measure the impact of mobile and home device traffic moving over those networks to identify malicious and cyber-security threats. Motive Security Labs is an analytics arm of Motive Customer Experience Management.
According to Alcatel-Lucent, Motive Security Labs (formerly Kindsight Security Labs), processes more than 120,000 new malware samples per day and maintains a library of 30 million active samples.
In the following pages, we will share the hilights of data collected by Motive Security Labs.

Mobile infection rate since December 2012
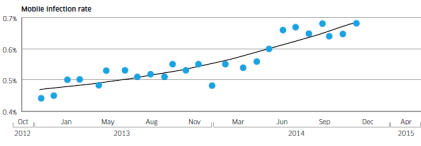
Alcatel-Lucent’s Motive Security Labs found 0.68% of mobile devices are infected with malware.
Using the ITU’s figure of 2.3 billion mobile broadband subscriptions, Motive Security Labs estimated that 16 million mobile devices had some sort of malware infection in December 2014.
The report called this global estimate “likely to be on the conservative side.” Motive Security Labs’ sensors do not have complete coverage in areas such as China and Russia, where mobile infection rates are known to be higher.
Mobile malware samples since June 2012
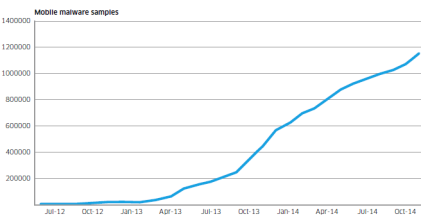
Motive Security Labs used the increase in the number of samples in its malware database to show Android malware growth.
The chart above shows numbers since June 2012. The number of samples grew by 161% in 2014.
In addition to the increase in raw numbers, the sophistication of Android malware also got better, according to Motive Security Labs. Researchers in 2014 started to see malware applications that had originally been developed for the Windows/PC platform migrate to the mobile space, bringing with them more sophisticated command and control and rootkit technologies.
Infected device types in 2013 and 2014
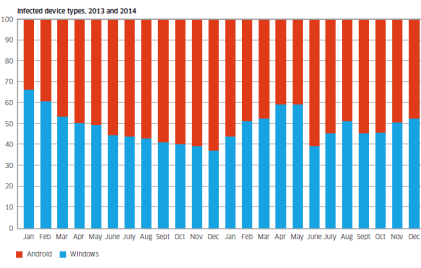
The chart shows the breakdown of infected device types that have been observed in 2013 and 2014. Shown in red is Android and shown in blue is Windows.
While the involvement of such a high proportion of Windows/PC devices may be a surprise to some, these Windows/PCs are connected to the mobile network via dongles and mobile Wi-Fi devices or simply tethered through smartphones.
They’re responsible for about 50% of the malware infections observed.
The report said, “This is because these devices are still the favorite of hardcore professional cybercriminals who have a huge investment in the Windows malware ecosystem. As the mobile network becomes the access network of choice for many Windows PCs, the malware moves with them.”
Android phones and tablets are responsible for about 50% of the malware infections observed.
Currently most mobile malware is distributed as “Trojanized” apps. Android offers the easiest target for this because of its open app environment, noted the report.
Tuesday, December 30. 2014
The fall of GPL and the rise of permissive open-source licenses
Via ZDNet
-----
I know very few open-source programmers, no matter how skilled they may with the intricacies of C++, who relish learning about the ins and outs of open-source licenses. I can't blame them. Like it or not, though, picking an open-source license is a necessity.
Idiots.
Things have improved a little. In July 2013 when Black Duck Software found that 77 percent of projects on GitHub have no declared license. Earlier that year Aaron Williamson, senior staff counsel at the Software Freedom Law Center, discovered that 85.1 percent of GitHub programs had no license.
In 2014, many GitHub programmers, using arguably the most popular code hosting system in the world, still don't use any license at all.
That's a big mistake. If you don't have a license, you're leaving the door open for people to fool with your code. You may think that's just fine... just like the poor sods did who used a permissive Creative Common license for "their" photographs that they'd stored on Yahoo's Flikr only to discover that Yahoo had started to sell prints of their photos ... and keeping all the money.
Maybe you're cool with that. I'm not.
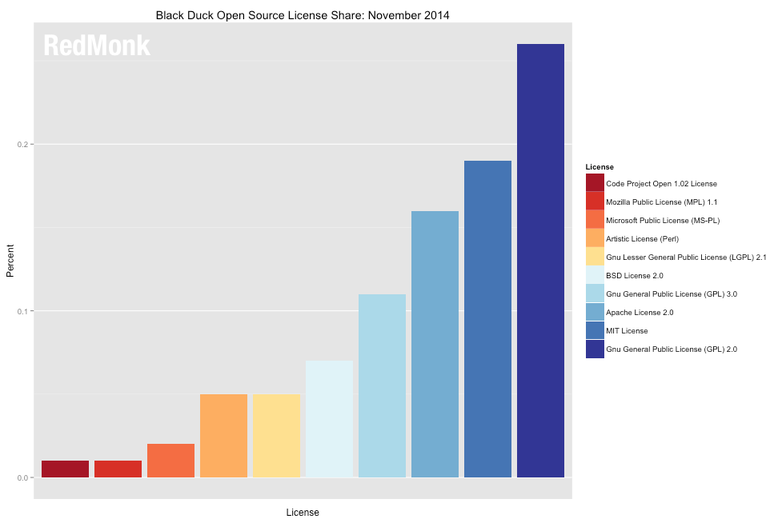
Now, as Stephen O'Grady, co-founder of Red Monk, a major research group, has observed, as software is shifting to being used more in a service mode rather than deployed, you may not need to protect your code with a more restrictive license such as the GPLv3 since "if the code is not a competitive advantage, it is likely not worth protecting." Even in the case of code with little intrinsic value, however, O'Grady believes that, "permissive licenses [such as the MIT License] are a perfect alternative."
So while O'Grady using Black Duck data found that "the GPL has been the overwhelmingly most selected license," these two licenses, GPLv2 and v3 are, "no longer more popular than most of the other licenses put together."
Instead, "The three primary permissive license choices (Apache/BSD/MIT) ... collectively are employed by 42 percent. They represent, in fact, three of the five most popular licenses in use today." These permissive licenses has been gaining ground at GPL's expense. The two biggest gainers, the Apache and MIT licenses, were up 27 percent, while the GPLv2, Linux's license, has declined by 24 percent.
This trend towards more permissive licensing is not, however, just the result of younger programmers switching to thinking of code as means to an end for a cloud services such as Software-as-a-Service (SaaS). Instead, it's been moving that way since 2004 according to a 2012 study by Donnie Berkholz, a Red Monk analyst.
Berkholz learned, using data from Ohloh, an open-source code research project now known as Open Hub, that "Since 2010, this trend has reached a point where permissive is more likely than copyleft [GPL] for a new open-source project."
I'm not sure that's wise, but this is 2014, not 1988. Many program's functionality are now delivered as a service rather than from a program residing on your computer. What I do know, though, is that if you want some say in how your code will be used tomorrow, you still need to put in under some kind of license.
Yes, without any license, your code defaults to falling under copyright law. In that case, legally speaking no one can reproduce, distribute, or create derivative works from your work. You may or may not want that. In any case, that's only the theory. In practice you'd find defending your rights to be difficult.
You should also keep in mind that when you "publish" your code on GitHub, or any other "public" site, you're giving up some of your rights. Which ones? Well, it depends on the site's Terms of Service. On GitHub, for example, if you choose to make your project repositories public -- which is probably the case or why would be on GitHub in the first place? --then you've agreed to allow others to view and fork your repositories. Notice the word "fork?" Good luck defending your copyright.
Seriously, you can either figure out what you want to do with your code before you start exposing it to the world, or you can do it after it's become a problem. Me? I think figuring it out first is the smart play.
Friday, December 19. 2014
Bots Now Outnumber Humans on the Web
Via Wired
-----

Getty Images
Diogo Mónica once wrote a short computer script that gave him a secret weapon in the war for San Francisco dinner reservations.
This was early 2013. The script would periodically scan the popular online reservation service, OpenTable, and drop him an email anytime something interesting opened up—a choice Friday night spot at the House of Prime Rib, for example. But soon, Mónica noticed that he wasn’t getting the tables that had once been available.
By the time he’d check the reservation site, his previously open reservation would be booked. And this was happening crazy fast. Like in a matter of seconds. “It’s impossible for a human to do the three forms that are required to do this in under three seconds,” he told WIRED last year.
Mónica could draw only one conclusion: He’d been drawn into a bot war.
Everyone knows the story of how the world wide web made the internet accessible for everyone, but a lesser known story of the internet’s evolution is how automated code—aka bots—came to quietly take it over. Today, bots account for 56 percent of all of website visits, says Marc Gaffan, CEO of Incapsula, a company that sells online security services. Incapsula recently an an analysis of 20,000 websites to get a snapshot of part of the web, and on smaller websites, it found that bot traffic can run as high as 80 percent.
People use scripts to buy gear on eBay and, like Mónica, to snag the best reservations. Last month, the band, Foo Fighters sold tickets for their upcoming tour at box offices only, an attempt to strike back against the bots used by online scalpers. “You should expect to see it on ticket sites, travel sites, dating sites,” Gaffan says. What’s more, a company like Google uses bots to index the entire web, and companies such as IFTTT and Slack give us ways use the web to use bots for good, personalizing our internet and managing the daily informational deluge.
But, increasingly, a slice of these online bots are malicious—used to knock websites offline, flood comment sections with spam, or scrape sites and reuse their content without authorization. Gaffan says that about 20 percent of the Web’s traffic comes from these bots. That’s up 10 percent from last year.
Often, they’re running on hacked computers. And lately they’ve become more sophisticated. They are better at impersonating Google, or at running in real browsers on hacked computers. And they’ve made big leaps in breaking human-detecting captcha puzzles, Gaffan says.
“Essentially there’s been this evolution of bots, where we’ve seen it become easier and more prevalent over the past couple of years,” says Rami Essaid, CEO of Distil Networks, a company that sells bot-blocking software.
But despite the rise of these bad bots, there is some good news for the human race. The total percentage of bot-related web traffic is actually down this year from what it was in 2013. Back then it accounted for 60 percent of the traffic, 4 percent more than today.
Thursday, December 18. 2014
BitTorrent Opens Alpha For Maelstrom, Its New, Distributed, Torrent-Based Web Browser
Tuesday, December 16. 2014
We’ve Put a Worm’s Mind in a Lego Robot's Body
Via Smithsonian
-----
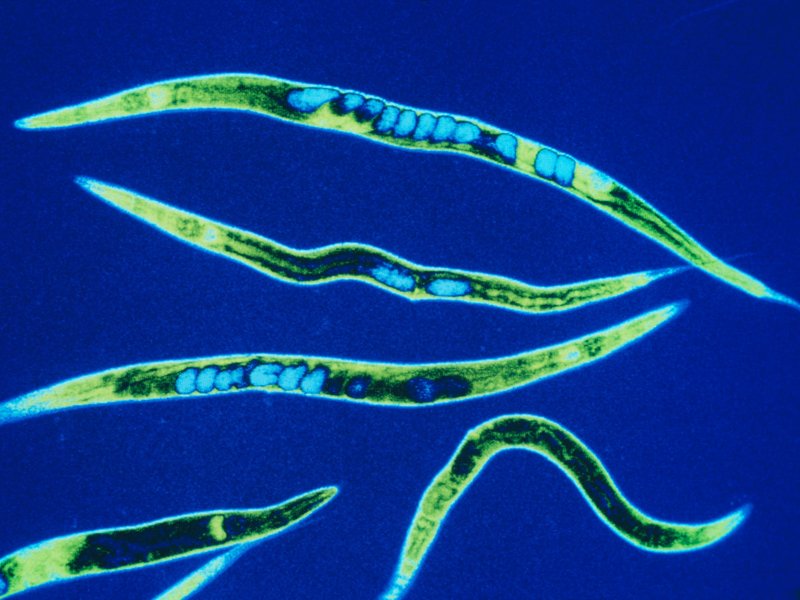
If the brain is a collection of electrical signals, then, if you could catalog all those those signals digitally, you might be able upload your brain into a computer, thus achieving digital immortality.
While the plausibility—and ethics—of this upload for humans can be debated, some people are forging ahead in the field of whole-brain emulation. There are massive efforts to map the connectome—all the connections in the brain—and to understand how we think. Simulating brains could lead us to better robots and artificial intelligence, but the first steps need to be simple.
So, one group of scientists started with the roundworm Caenorhabditis elegans, a critter whose genes and simple nervous system we know intimately.
The OpenWorm project has mapped the connections between the worm’s 302 neurons and simulated them in software. (The project’s ultimate goal is to completely simulate C. elegans as a virtual organism.) Recently, they put that software program in a simple Lego robot.
The worm’s body parts and neural networks now have LegoBot equivalents: The worm’s nose neurons were replaced by a sonar sensor on the robot. The motor neurons running down both sides of the worm now correspond to motors on the left and right of the robot, explains Lucy Black for I Programmer. She writes:
---
It is claimed that the robot behaved in ways that are similar to observed C. elegans. Stimulation of the nose stopped forward motion. Touching the anterior and posterior touch sensors made the robot move forward and back accordingly. Stimulating the food sensor made the robot move forward.
---
Timothy Busbice, a founder for the OpenWorm project, posted a video of the Lego-Worm-Bot stopping and backing:
The simulation isn’t exact—the program has some simplifications on the thresholds needed to trigger a "neuron" firing, for example. But the behavior is impressive considering that no instructions were programmed into this robot. All it has is a network of connections mimicking those in the brain of a worm.
Of course, the goal of uploading our brains assumes that we aren’t already living in a computer simulation. Hear out the logic: Technologically advanced civilizations will eventually make simulations that are indistinguishable from reality. If that can happen, odds are it has. And if it has, there are probably billions of simulations making their own simulations. Work out that math, and "the odds are nearly infinity to one that we are all living in a computer simulation," writes Ed Grabianowski for io9.
Is your mind spinning yet?
Tuesday, December 02. 2014
Big Data Digest: Rise of the think-bots
Quicksearch
Popular Entries
- The great Ars Android interface shootout (131534)
- Norton cyber crime study offers striking revenue loss statistics (102464)
- MeCam $49 flying camera concept follows you around, streams video to your phone (100548)
- The PC inside your phone: A guide to the system-on-a-chip (58722)
- Norton cyber crime study offers striking revenue loss statistics (58693)
Categories

Show tagged entries
Syndicate This Blog
Calendar
|
|
July '26 | |||||
| Mon | Tue | Wed | Thu | Fri | Sat | Sun |
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 | ||