Entries tagged as technology
Tuesday, December 16. 2014
We’ve Put a Worm’s Mind in a Lego Robot's Body
Via Smithsonian
-----
If the brain is a collection of electrical signals, then, if you could catalog all those those signals digitally, you might be able upload your brain into a computer, thus achieving digital immortality.
While the plausibility—and ethics—of this upload for humans can be debated, some people are forging ahead in the field of whole-brain emulation. There are massive efforts to map the connectome—all the connections in the brain—and to understand how we think. Simulating brains could lead us to better robots and artificial intelligence, but the first steps need to be simple.
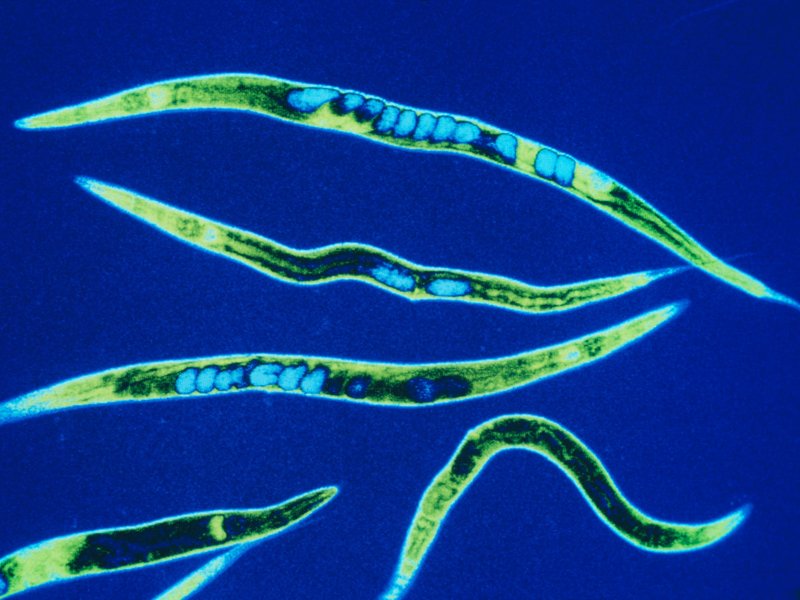
So, one group of scientists started with the roundworm Caenorhabditis elegans, a critter whose genes and simple nervous system we know intimately.
The OpenWorm project has mapped the connections between the worm’s 302 neurons and simulated them in software. (The project’s ultimate goal is to completely simulate C. elegans as a virtual organism.) Recently, they put that software program in a simple Lego robot.
The worm’s body parts and neural networks now have LegoBot equivalents: The worm’s nose neurons were replaced by a sonar sensor on the robot. The motor neurons running down both sides of the worm now correspond to motors on the left and right of the robot, explains Lucy Black for I Programmer. She writes:
---
It is claimed that the robot behaved in ways that are similar to observed C. elegans. Stimulation of the nose stopped forward motion. Touching the anterior and posterior touch sensors made the robot move forward and back accordingly. Stimulating the food sensor made the robot move forward.
---
Timothy Busbice, a founder for the OpenWorm project, posted a video of the Lego-Worm-Bot stopping and backing:
The simulation isn’t exact—the program has some simplifications on the thresholds needed to trigger a "neuron" firing, for example. But the behavior is impressive considering that no instructions were programmed into this robot. All it has is a network of connections mimicking those in the brain of a worm.
Of course, the goal of uploading our brains assumes that we aren’t already living in a computer simulation. Hear out the logic: Technologically advanced civilizations will eventually make simulations that are indistinguishable from reality. If that can happen, odds are it has. And if it has, there are probably billions of simulations making their own simulations. Work out that math, and "the odds are nearly infinity to one that we are all living in a computer simulation," writes Ed Grabianowski for io9.
Is your mind spinning yet?
Wednesday, June 18. 2014
The cyborg era begins next week at the World Cup
Via The Verge
-----
Next week at the World Cup, a paralyzed volunteer from the Association for Assistance to Disabled Children will walk onto the field and open the tournament with a ceremonial kick. This modern miracle is made possible by a robotic exoskeleton that will move the user's limbs, taking commands directly from his or her thoughts.
This demonstration is the debut of the Walk Again Project, a consortium of more than 150 scientists and engineers from around the globe who have come together to show off recent advances in the field of brain machine interfaces, or BMI. The paralyzed person inside will be wearing an electroencephalographic (EEG) headset that records brainwave activity. A backpack computer will translate those electrical signals into commands the exoskeleton can understand. As the robotic frame moves, it also sends its own signals back to the body, restoring not just the ability to walk, but the sensation as well.
Just how well the wearer will walk and kick are uncertain. The project has been criticized by other neuroscientists as an exploitative spectacle that uses the disabled to promote research which may not be the best path for restoring health to paralyzed patients. And just weeks before the project is set to debut on television to hundreds of millions of fans, it still hasn’t been tested outdoors and awaits some final pieces and construction. It's not even clear which of the eight people from the study will be the one inside the suit.
The point of the project is not to show finished research, however, or sell a particular technology. The Walk Again Project is meant primarily to inspire. It's a demonstration that we’re on the threshold of achieving science fiction: technologies that will allow humans to truly step into the cyborg era.
It’s only taken a little over two centuries to get there.
The past
Scientists have been studying the way electricity interacts with our biology since 1780, when Luigi Galvani made the legs of a dead frog dance by zapping them with a spark, but the modern history behind the technology that allows our brains to talk directly to machines goes back to the 1950s and John Lilly. He implanted several hundred electrodes into different parts of a monkey’s brain and used these implants to apply shocks, causing different body parts to move. A decade later in 1963, professor Jose Delgado of Yale tested this theory again like a true Spaniard, stepping into the ring to face a charging bull, which he stopped in its tracks with a zap to the brain.
In 1969, professor Eberhard Fetz was able to isolate and record the
firing of a single neuron onto a microelectrode he had implanted into
the brain of a monkey. Fetz learned that primates could actually tune
their brain activity to better interact with the implanted machine. He
rewarded them with banana pellets every time they triggered the
microelectrode, and the primates quickly improved in their ability to
activate this specific section of their brain. This was a critical
observation, demonstrating brain’s unique plasticity, its ability to
create fresh pathways to fit a new language.
Today, BMI research has advanced to not only record the neurons firing in primates’ brains, but to understand what actions the firing of those neurons represent. "I spend my life chasing the storms that emanate from the hundreds of billions of cells that inhabit our brains," explained Miguel Nicolelis, PhD, one of the founders of Center for Neuroengineering at Duke University and the driving force behind the Walk Again Project. "What we want to do is listen to these brain symphonies and try to extract them from the messages they carry."
Nicolelis and his colleagues at Duke were able to record brain activity and match it to actions. From there they could translate that brain activity into instructions a computer could understand. Beginning in the year 2000, Nicolelis and his colleagues at Duke made a series of breakthroughs. In the most well known, they implanted a monkey with an array of microelectrodes that could record the firing of clusters of neurons in different parts of the brain. The monkey stood on a treadmill and began to walk. On the other side of the planet, a robot in Japan received the signal emanating from the primate’s brain and began to walk.
Primates in the Duke lab learned to control robotic arms using only their thoughts. And like in the early experiments done by Fetz, the primates showed a striking ability to improve the control of these new limbs. "The brain is a remarkable instrument," says professor Craig Henriquez, who helped to found the Duke lab. "It has the ability to rewire itself, to create new connections. That’s what gives the BMI paradigm its power. You are not limited just by what you can physically engineer, because the brain evolves to better suit the interface."

The present
After his success with primates, Nicolelis was eager to apply the advances in BMI to people. But there were some big challenges in the transition from lab animals to human patients, namely that many people weren’t willing to undergo invasive brain surgery for the purposes of clinical research. "There is an open question of whether you need to have implants to get really fine grained control," says Henriquez. The Walk Again Project hopes to answer that question, at least partially. While it is based on research in animals that required surgery, it will be using only external EEG headsets to gather brain activity.
The fact that these patients were paralyzed presented another challenge. Unlike the lab monkeys, who could move their own arms and observe how the robot arm moved in response, these participants can’t move their legs, or for many, really remember the subconscious thought process that takes place when you want to travel by putting one foot in front of the other. The first step was building up the pathways in the brain that would send mental commands to the BMI to restore locomotion.
To train the patients in this new way of thinking about movement, researchers turned to virtual reality. Each subject was given an EEG headset and an Oculus Rift. Inside the head-mounted display, the subjects saw a virtual avatar of themselves from the waist down. When they thought about walking, the avatar legs walked, and this helped the brain to build new connections geared towards controlling the exoskeleton. "We also simulate the stadium, and the roar of the crowd," says Regis Kopper, who runs Duke’s VR lab. "To help them prepare for the stress of the big day."
Once the VR training had established a baseline for sending commands to the legs, there was a second hurdle. Much of walking happens at the level of reflex, and without the peripheral nervous system that helps people balance, coordinate, and adjust to the terrain, walking can be a very challenging task. That’s why even the most advanced robots have trouble navigating stairs or narrow hallways that would seem simple to humans. If the patients were going to successfully walk or kick a ball, it wasn’t enough that they be able to move the exoskeleton’s legs — they had to feel them as well.
The breakthrough was a special shirt with vibrating pads on its forearm. As the robot walked, the contact of its heel and toe on the ground made corresponding sensations occur along parts of the right and left arms. "The brain essentially remapped one part of the body onto another," says Henriquez. "This restored what we call proprioception, the spacial awareness humans need for walking."
In recent weeks all eight of the test subjects have successfully walked using the exoskeleton, with one completing an astonishing 132 steps. The plan is to have the volunteer who works best with the exoskeleton perform the opening kick. But the success of the very public demonstration is still up in the air. The suit hasn’t been completely finished and it has yet to be tested in an outdoor environment. The group won't confirm who exactly will be wearing the suit. Nicolelis, for his part, isn’t worried. Asked when he thought the entire apparatus would be ready, he replied: "Thirty minutes before."

The future
The Walk Again project may be the most high-profile example of BMI, but there have been a string of breakthrough applications in recent years. A patient at the University of Pittsburgh achieved unprecedented levels of fine motor control with a robotic arm controlled by brain activity. The Rehabilitation Institute of Chicago introduced the world’s first mind controlled prosthetic leg. For now the use of advanced BMI technologies is largely confined to academic and medical research, but some projects, like DARPA’s Deka arm, have received FDA approval and are beginning to move into the real world. As it improves in capability and comes down in cost, BMI may open the door to a world of human enhancement that would see people merging with machines, not to restore lost capabilities, but to augment their own abilities with cyborg power-ups.
"From the standpoint of defense, we have a lot of good reasons to do it," says Alan Rudolph, a former DARPA scientist and Walk Again Project member. Rudolph, for example, worked on the Big Dog, and says BMI may allow human pilots to control mechanical units with their minds, giving them the ability to navigate uncertain or dynamic terrain in a way that has so far been impossible while keeping soldiers out of harms way. Our thoughts might control a robot on the surface of Mars or a microsurgical bot navigating the inside of the human body.
There is a subculture of DIY biohackers and grinders who are eager to begin adopting cyborg technology and who are willing, at least in theory, to amputate functional limbs if it’s possible to replace them with stronger, more functional, mechanical ones. "I know what the limits of the human body are like," says Tim Sarver, a member of the Pittsburgh biohacker collective Grindhouse Wetwares. "Once you’ve seen the capabilities of a 5000psi hydraulic system, it’s no comparison."
For now, this sci-fi vision all starts with a single kick on the World Cup pitch, but our inevitable cyborg future is indeed coming. A recent demonstration at the University of Washington enabled one person’s thoughts to control the movements of another person’s body — a brain-to-brain interface — and it holds the key to BMI’s most promising potential application. "In this futuristic scenario, voluntary electrical brain waves, the biological alphabet that underlies human thinking, will maneuver large and small robots, control airships from afar," wrote Nicolelis. "And perhaps even allow for the sharing of thoughts and sensations with one individual to another."
-----
ComputedBy comments:
Now, the kick-off video:
Wednesday, April 16. 2014
Qualcomm is getting high on 64-bit chips
Via PCWorld
-----

Qualcomm is getting high on 64-bit chips with its fastest ever Snapdragon processor, which will render 4K video, support LTE Advanced and could run the 64-bit Android OS.
The new Snapdragon 810 is the company’s “highest performing” mobile chip for smartphones and tablets, Qualcomm said in a statement. Mobile devices with the 64-bit chip will ship in the first half of next year, and be faster and more power-efficient. Snapdragon chips are used in handsets with Android and Windows Phone operating systems, which are not available in 64-bit form yet.
The Snapdragon 810 is loaded with the latest communication and graphics technologies from Qualcomm. The graphics processor can render 4K (3840 x 2160 pixel) video at 30 frames per second, and 1080p video at 120 frames per second. The chip also has an integrated modem that supports LTE and its successor, LTE-Advanced, which is emerging.
The 810 also is among the first mobile chips to support the latest low-power LPDDR4 memory, which will allow programs to run faster while consuming less power. This will be beneficial, especially for tablets, as 64-bit chips allow mobile devices to have more than 4GB of memory, which is the limit on current 32-bit chips.

The layout of the Snapdragon 810 chip. (Click to enlarge.)
The quad-core chip has a mix of high-power ARM Cortex-A57 CPU cores for demanding tasks and low-power A53 CPU cores for mundane tasks like taking calls, messaging and MP3 playback. The multiple cores ensure more power-efficient use of the chip, which helps extend battery life of mobile devices.
The company also introduced a Snapdragon 808 six-core 64-bit chip. The chips will be among the first made using the latest 20-nanometer manufacturing process, which is an advance from the 28-nm process used to make Snapdragon chips today.
Qualcomm now has to wait for Google to release a 64-bit version of Android for ARM-based mobile devices. Intel has already shown mobile devices running 64-bit Android with its Merrifield chip, but most mobile products today run on ARM processors. Qualcomm licenses Snapdragon processor architecture and designs from ARM.
Work for 64-bit Android is already underway, and applications like the Chrome browser are already being developed for the OS. Google has not officially commented on when 64-bit Android would be released, but industry observers believe it could be announced at the Google I/O conference in late June.
Qualcomm spokesman Jon Carvill declined to comment on support for 64-bit Android. But the chips are “further evidence of our commitment to deliver top-to-bottom mobile 64-bit leadership across product tiers for our customers,” Carvill said in an email.
Qualcomm’s chips are used in some of the world’s top smartphones, and will appear in Samsung’s Galaxy S5. A Qualcomm executive in October last year called Apple’s A7, the world’s first 64-bit mobile chip, a “marketing gimmick,” but the company has moved on and now has five 64-bit chips coming to medium-priced and premium smartphones and tablets. But no 64-bit Android smartphones are available yet, and Apple has a headstart and remains the only company selling a 64-bit smartphone with its iPhone 5S.
The 810 supports HDMI 1.4 for 4K video output, and the Adreno 430 graphics processor is 30 percent faster on graphics performance and 20 percent more power efficient than the older Adreno 420 GPU. The graphics processor will support 55-megapixel sensors, Qualcomm said. Other chip features include 802.11ac Wi-Fi with built-in technology for faster wireless data transfers, Bluetooth 4.1 and a processing core for location services.
The six-core Snapdragon 808 is a notch down on performance compared to the 810, and also has fewer features. The 808 supports LTE-Advanced, but can support displays with up to 2560 x 1600 pixels. It will support LPDDR3 memory. The chip has two Cortex-A57 CPUs and four Cortex-A53 cores.
The chips will ship out to device makers for testing in the second half of this year.
Friday, May 17. 2013
Landlords Double as Energy Brokers
-----

Equinix’s data center in Secaucus is highly coveted space for financial traders, given its proximity to the servers that move trades for Wall Street.
The trophy high-rises on Madison, Park and Fifth Avenues in Manhattan have long commanded the top prices in the country for commercial real estate, with yearly leases approaching $150 a square foot. So it is quite a Gotham-size comedown that businesses are now paying rents four times that in low, bland buildings across the Hudson River in New Jersey.
Why pay $600 or more a square foot at unglamorous addresses like Weehawken, Secaucus and Mahwah? The answer is still location, location, location — but of a very different sort.
Companies are paying top dollar to lease space there in buildings called data centers, the anonymous warrens where more and more of the world’s commerce is transacted, all of which has added up to a tremendous boon for the business of data centers themselves.
The centers provide huge banks of remote computer storage, and the enormous amounts of electrical power and ultrafast fiber optic links that they demand.
Prices are particularly steep in northern New Jersey because it is also where data centers house the digital guts of the New York Stock Exchange and other markets. Bankers and high-frequency traders are vying to have their computers, or servers, as close as possible to those markets. Shorter distances make for quicker trades, and microseconds can mean millions of dollars made or lost.
When the centers opened in the 1990s as quaintly termed “Internet hotels,” the tenants paid for space to plug in their servers with a proviso that electricity would be available. As computing power has soared, so has the need for power, turning that relationship on its head: electrical capacity is often the central element of lease agreements, and space is secondary.
A result, an examination shows, is that the industry has evolved from a purveyor of space to an energy broker — making tremendous profits by reselling access to electrical power, and in some cases raising questions of whether the industry has become a kind of wildcat power utility.
Even though a single data center can deliver enough electricity to power a medium-size town, regulators have granted the industry some of the financial benefits accorded the real estate business and imposed none of the restrictions placed on the profits of power companies.
Some of the biggest data center companies have won or are seeking Internal Revenue Service approval to organize themselves as real estate investment trusts, allowing them to eliminate most corporate taxes. At the same time, the companies have not drawn the scrutiny of utility regulators, who normally set prices for delivery of the power to residences and businesses.
While companies have widely different lease structures, with prices ranging from under $200 to more than $1,000 a square foot, the industry’s performance on Wall Street has been remarkable. Digital Realty Trust, the first major data center company to organize as a real estate trust, has delivered a return of more than 700 percent since its initial public offering in 2004, according to an analysis by Green Street Advisors.
The stock price of another leading company, Equinix, which owns one of the prime northern New Jersey complexes and is seeking to become a real estate trust, more than doubled last year to over $200.
“Their business has grown incredibly rapidly,” said John Stewart, a senior analyst at Green Street. “They arrived at the scene right as demand for data storage and growth of the Internet were exploding.”
Push for Leasing
While many businesses own their own data centers — from stacks of servers jammed into a back office to major stand-alone facilities — the growing sophistication, cost and power needs of the systems are driving companies into leased spaces at a breakneck pace.
The New York metro market now has the most rentable square footage in the nation, at 3.2 million square feet, according to a recent report by 451 Research, an industry consulting firm. It is followed by the Washington and Northern Virginia area, and then by San Francisco and Silicon Valley.
A major orthopedics practice in Atlanta illustrates how crucial these data centers have become.
With 21 clinics scattered around Atlanta, Resurgens Orthopaedics has some 900 employees, including 170 surgeons, therapists and other caregivers who treat everything from fractured spines to plantar fasciitis. But its technological engine sits in a roughly 250-square-foot cage within a gigantic building that was once a Sears distribution warehouse and is now a data center operated by Quality Technology Services.
Eight or nine racks of servers process and store every digital medical image, physician’s schedule and patient billing record at Resurgens, said Bradley Dick, chief information officer at the company. Traffic on the clinics’ 1,600 telephones is routed through the same servers, Mr. Dick said.
“That is our business,” Mr. Dick said. “If those systems are down, it’s going to be a bad day.”
The center steadily burns 25 million to 32 million watts, said Brian Johnston, the chief technology officer for Quality Technology. That is roughly the amount needed to power 15,000 homes, according to the Electric Power Research Institute.
Mr. Dick said that 75 percent of Resurgens’s lease was directly related to power — essentially for access to about 30 power sockets. He declined to cite a specific dollar amount, but two brokers familiar with the operation said that Resurgens was probably paying a rate of about $600 per square foot a year, which would mean it is paying over $100,000 a year simply to plug its servers into those jacks.
While lease arrangements are often written in the language of real estate,“these are power deals, essentially,” said Scott Stein, senior vice president of the data center solutions group at Cassidy Turley, a commercial real estate firm. “These are about getting power for your servers.”
One key to the profit reaped by some data centers is how they sell access to power. Troy Tazbaz, a data center design engineer at Oracle who previously worked at Equinix and elsewhere in the industry, said that behind the flat monthly rate for a socket was a lucrative calculation. Tenants contract for access to more electricity than they actually wind up needing. But many data centers charge tenants as if they were using all of that capacity — in other words, full price for power that is available but not consumed.
Since tenants on average tend to contract for around twice the power they need, Mr. Tazbaz said, those data centers can effectively charge double what they are paying for that power. Generally, the sale or resale of power is subject to a welter of regulations and price controls. For regulated utilities, the average “return on equity” — a rough parallel to profit margins — was 9.25 percent to 9.7 percent for 2010 through 2012, said Lillian Federico, president of Regulatory Research Associates, a division of SNL Energy.
Regulators Unaware
But the capacity pricing by data centers, which emerged in interviews with engineers and others in the industry as well as an examination of corporate documents, appears not to have registered with utility regulators.
Interviews with regulators in several states revealed widespread lack of understanding about the amount of electricity used by data centers or how they profit by selling access to power.
Bernie Neenan, a former utility official now at the Electric Power Research Institute, said that an industry operating outside the reach of utility regulators and making profits by reselling access to electricity would be a troubling precedent. Utility regulations “are trying to avoid a landslide” of other businesses doing the same.
Some data center companies, including Digital Realty Trust and DuPont Fabros Technology, charge tenants for the actual amount of electricity consumed and then add a fee calculated on capacity or square footage. Those deals, often for larger tenants, usually wind up with lower effective prices per square foot.
Regardless of the pricing model, Chris Crosby, chief executive of the Dallas-based Compass Datacenters, said that since data centers also provided protection from surges and power failures with backup generators, they could not be viewed as utilities. That backup equipment “is why people pay for our business,” Mr. Crosby said.
Melissa Neumann, a spokeswoman for Equinix, said that in the company’s leases, “power, cooling and space are very interrelated.” She added, “It’s simply not accurate to look at power in isolation.”
Ms. Neumann and officials at the other companies said their practices could not be construed as reselling electrical power at a profit and that data centers strictly respected all utility codes. Alex Veytsel, chief strategy officer at RampRate, which advises companies on data center, network and support services, said tenants were beginning to resist flat-rate pricing for access to sockets.
“I think market awareness is getting better,” Mr. Veytsel said. “And certainly there are a lot of people who know they are in a bad situation.”
The Equinix Story
The soaring business of data centers is exemplified by Equinix. Founded in the late 1990s, it survived what Jason Starr, director of investor relations, called a “near death experience” when the Internet bubble burst. Then it began its stunning rise.
Equinix’s giant data center in Secaucus is mostly dark except for lights flashing on servers stacked on black racks enclosed in cages. For all its eerie solitude, it is some of the most coveted space on the planet for financial traders. A few miles north, in an unmarked building on a street corner in Mahwah, sit the servers that move trades on the New York Stock Exchange; an almost equal distance to the south, in Carteret, are Nasdaq’s servers.
The data center’s attraction for tenants is a matter of physics: data, which is transmitted as light pulses through fiber optic cables, can travel no faster than about a foot every billionth of a second. So being close to so many markets lets traders operate with little time lag.
As Mr. Starr said: “We’re beachfront property.”
Standing before a bank of servers, Mr. Starr explained that they belonged to one of the lesser-known exchanges located in the Secaucus data center. Multicolored fiber-optic cables drop from an overhead track into the cage, which allows servers of traders and other financial players elsewhere on the floor to monitor and react nearly instantaneously to the exchange. It all creates a dense and unthinkably fast ecosystem of postmodern finance.
Quoting some lyrics by Soul Asylum, Mr. Starr said, “Nothing attracts a crowd like a crowd.” By any measure, Equinix has attracted quite a crowd. With more than 90 facilities, it is the top data center leasing company in the world, according to 451 Research. Last year, it reported revenue of $1.9 billion and $145 million in profits.
But the ability to expand, according to the company’s financial filings, is partly dependent on fulfilling the growing demands for electricity. The company’s most recent annual report said that “customers are consuming an increasing amount of power per cabinet,” its term for data center space. It also noted that given the increase in electrical use and the age of some of its centers, “the current demand for power may exceed the designed electrical capacity in these centers.”
To enhance its business, Equinix has announced plans to restructure itself as a real estate investment trust, or REIT, which, after substantial transition costs, would eventually save the company more than $100 million in taxes annually, according to Colby Synesael, an analyst at Cowen & Company, an investment banking firm.
Congress created REITs in the early 1960s, modeling them on mutual funds, to open real estate investments to ordinary investors, said Timothy M. Toy, a New York lawyer who has written about the history of the trusts. Real estate companies organized as investment trusts avoid corporate taxes by paying out most of their income as dividends to investors.
Equinix is seeking a so-called private letter ruling from the I.R.S. to restructure itself, a move that has drawn criticism from tax watchdogs.
“This is an incredible example of how tax avoidance has become a major business strategy,” said Ryan Alexander, president of Taxpayers for Common Sense, a nonpartisan budget watchdog. The I.R.S., she said, “is letting people broaden these definitions in a way that they kind of create the image of a loophole.”
Equinix, some analysts say, is further from the definition of a real estate trust than other data center companies operating as trusts, like Digital Realty Trust. As many as 80 of its 97 data centers are in buildings it leases, Equinix said. The company then, in effect, sublets the buildings to numerous tenants.
Even so, Mr. Synesael said the I.R.S. has been inclined to view recurring revenue like lease payments as “good REIT income.”
Ms. Neumann, the Equinix spokeswoman, said, “The REIT framework is designed to apply to real estate broadly, whether owned or leased.” She added that converting to a real estate trust “offers tax efficiencies and disciplined returns to shareholders while also allowing us to preserve growth characteristics of Equinix and create significant shareholder value.”
Thursday, May 02. 2013
Driving Miss dAIsy: What Google’s self-driving cars see on the road
Via Slash Gear
-----
We’ve been hearing a lot about Google‘s self-driving car lately, and we’re all probably wanting to know how exactly the search giant is able to construct such a thing and drive itself without hitting anything or anyone. A new photo has surfaced that demonstrates what Google’s self-driving vehicles see while they’re out on the town, and it looks rather frightening.

The image was tweeted by Idealab founder Bill Gross, along with a claim that the self-driving car collects almost 1GB of data every second (yes, every second). This data includes imagery of the cars surroundings in order to effectively and safely navigate roads. The image shows that the car sees its surroundings through an infrared-like camera sensor, and it even can pick out people walking on the sidewalk.
Of course, 1GB of data every second isn’t too surprising when you consider that the car has to get a 360-degree image of its surroundings at all times. The image we see above even distinguishes different objects by color and shape. For instance, pedestrians are in bright green, cars are shaped like boxes, and the road is in dark blue.
However, we’re not sure where this photo came from, so it could simply be a rendering of someone’s idea of what Google’s self-driving car sees. Either way, Google says that we could see self-driving cars make their way to public roads in the next five years or so, which actually isn’t that far off, and Tesla Motors CEO Elon Musk is even interested in developing self-driving cars as well. However, they certainly don’t come without their problems, and we’re guessing that the first batch of self-driving cars probably won’t be in 100% tip-top shape.
Tuesday, December 11. 2012
IBM silicon nanophotonics speeds servers with 25Gbps light
Via Slash Gear
-----
IBM has developed a light-based data transfer system delivering more than 25Gbps per channel, opening the door to chip-dense slabs of processing power that could speed up server performance, the internet, and more. The company’s research into silicon integrated nanophotonics addresses concerns that interconnects between increasingly powerful computers, such as mainframe servers, are unable to keep up with the speeds of the computers themselves. Instead of copper or even optical cables, IBM envisages on-chip optical routing, where light blasts data between dense, multi-layer computing hubs.

“This future 3D-integated chip consists of several layers connected with each other with very dense and small pitch interlayer vias. The lower layer is a processor itself with many hundreds of individual cores. Memory layer (or layers) are bonded on top to provide fast access to local caches. On top of the stack is the Photonic layer with many thousands of individual optical devices (modulators, detectors, switches) as well as analogue electrical circuits (amplifiers, drivers, latches, etc.). The key role of a photonic layer is not only to provide point-to-point broad bandwidth optical link between different cores and/or the off-chip traffic, but also to route this traffic with an array of nanophotonic switches. Hence it is named Intra-chip optical network (ICON)” IBM
Optical interconnects are increasingly being used to link different server nodes, but by bringing the individual nodes into a single stack the delays involved in communication could be pared back even further. Off-chip optical communications would also be supported, to link the data-rich hubs together.
Although the photonics system would be considerably faster than existing links – it supports multiplexing, joining multiple 25Gbps+ connections into one cable thanks to light wavelength splitting – IBM says it would also be cheaper thanks to straightforward manufacturing integration:
“By adding a few processing modules into a high-performance 90nm CMOS fabrication line, a variety of silicon nanophotonics components such as wavelength division multiplexers (WDM), modulators, and detectors are integrated side-by-side with a CMOS electrical circuitry. As a result, single-chip optical communications transceivers can be manufactured in a conventional semiconductor foundry, providing significant cost reduction over traditional approaches” IBM
Technologies like the co-developed Thunderbolt from Intel and Apple have promised affordable light-based computing connections, but so far rely on more traditional copper-based links with optical versions further down the line. IBM says its system is “primed for commercial development” though warns it may take a few years before products could actually go on sale.
Friday, November 16. 2012
Misc. Gadgets Voxeljet 3D printer used to produce Skyfall's Aston Martin stunt double
Via engadget
-----

Spoiler alert: a reoccurring cast member bids farewell in the latest James Bond flick. When the production of Skyfall called for the complete decimation of a classic 1960s era Aston Martin DB5, filmmakers opted for something a little more lifelike than computer graphics. The movie studio contracted the services of Augsburg-based 3D printing company Voxeljet to make replicas of the vintage ride. Skipping over the residential-friendly MakerBot Replicator, the company used a beastly industrial VX4000 3D printer to craft three 1:3 scale models of the car with a plot to blow them to smithereens. The 18 piece miniatures were shipped off to Propshop Modelmakers in London to be assembled, painted, chromed and outfitted with fake bullet holes. The final product was used in the film during a high-octane action sequence, which resulted in the meticulously crafted prop receiving a Wile E. Coyote-like sendoff. Now, rest easy knowing that no real Aston Martins were harmed during the making of this film. Head past the break to get a look at a completed model prior to its untimely demise.

Wednesday, October 24. 2012
Molecular 3D bioprinting could mean getting drugs through email
Via dvice
-----
What happens when you combine advances in 3D printing with biosynthesis and molecular construction? Eventually, it might just lead to printers that can manufacture vaccines and other drugs from scratch: email your doc, download some medicine, print it out and you're cured.
This concept (which is surely being worked on as we speak) comes from Craig Venter, whose idea of synthesizing DNA on Mars we posted about last week. You may remember a mention of the possibility of synthesizing Martian DNA back here on Earth, too: Venter says that we can do that simply by having the spacecraft email us genetic information on whatever it finds on Mars, and then recreate it in a lab by mixing together nucleotides in just the right way. This sort of thing has already essentially been done by Ventner, who created the world's first synthetic life form back in 2010.
Vetner's idea is to do away with complex, expensive and centralized vaccine production and instead just develop one single machine that can "print" drugs by carefully combining nucleotides, sugars, amino acids, and whatever else is needed while u wait. Technology like this would mean that vaccines could be produced locally, on demand, simply by emailing the appropriate instructions to your closes drug printer. Pharmacies would no longer consists of shelves upon shelves of different pills, but could instead be kiosks with printers inside them. Ultimately, this could even be something you do at home.
While the benefits to technology like this are obvious, the risks are equally obvious. I mean, you'd basically be introducing the Internet directly into your body. Just ingest that for a second and think about everything that it implies. Viruses. LOLcats. Rule 34. Yeah, you know what, maybe I'll just stick with modern American healthcare and making ritual sacrifices to heathen gods, at least one of which will probably be effective.
Monday, October 15. 2012
Constraints on the Universe as a Numerical Simulation
Thursday, September 20. 2012
Three-Minute Tech: LTE
Via TechHive
-----

The iPhone 5 is the latest smartphone to hop on-board the LTE (Long Term Evolution) bandwagon, and for good reason: The mobile broadband standard is fast, flexible, and designed for the future. Yet LTE is still a young technology, full of growing pains. Here’s an overview of where it came from, where it is now, and where it might go from here.
The evolution of ‘Long Term Evolution’
LTE is a mobile broadband standard developed by the 3GPP (3rd Generation Partnership Project), a group that has developed all GSM standards since 1999. (Though GSM and CDMA—the network Verizon and Sprint use in the United States—were at one time close competitors, GSM has emerged as the dominant worldwide mobile standard.)
Cell networks began as analog, circuit-switched systems nearly identical in function to the public switched telephone network (PSTN), which placed a finite limit on calls regardless of how many people were speaking on a line at one time.
The second-generation, GPRS, added data (at dial-up modem speed). GPRS led to EDGE, and then 3G, which treated both voice and data as bits passing simultaneously over the same network (allowing you to surf the web and talk on the phone at the same time).
GSM-evolved 3G (which brought faster speeds) started with UMTS, and then accelerated into faster and faster variants of 3G, 3G+, and “4G” networks (HSPA, HSDPA, HSUPA, HSPA+, and DC-HSPA).
Until now, the term “evolution” meant that no new standard broke or failed to work with the older ones. GSM, GPRS, UMTS, and so on all work simultaneously over the same frequency bands: They’re intercompatible, which made it easier for carriers to roll them out without losing customers on older equipment. But these networks were being held back by compatibility.
That’s where LTE comes in. The “long term” part means: “Hey, it’s time to make a big, big change that will break things for the better.”
LTE needs its own space, man
LTE has “evolved” beyond 3G networks by incorporating new radio technology and adopting new spectrum. It allows much higher speeds than GSM-compatible standards through better encoding and wider channels. (It’s more “spectrally efficient,” in the jargon.)
LTE is more flexible than earlier GSM-evolved flavors, too: Where GSM’s 3G variants use 5 megahertz (MHz) channels, LTE can use a channel size from 1.4 MHz to 20 MHz; this lets it work in markets where spectrum is scarce and sliced into tiny pieces, or broadly when there are wide swaths of unused or reassigned frequencies. In short, the wider the channel—everything else being equal—the higher the throughput.
Speeds are also boosted through MIMO (multiple input, multiple output), just as in 802.11n Wi-Fi. Multiple antennas allow two separate benefits: better reception, and multiple data streams on the same spectrum.
LTE complications
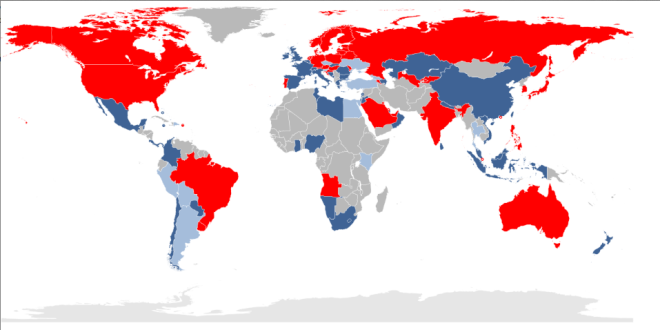
Unfortunately, in practice, LTE implementation gets sticky: There are 33 potential bands for LTE, based on a carrier’s local regulatory domain. In contrast, GSM has just 14 bands, and only five of those are widely used. (In broad usage, a band is two sets of paired frequencies, one devoted to upstream traffic and the other committed to downstream. They can be a few MHz apart or hundreds of MHz apart.)
And while LTE allows voice, no standard has yet been agreed upon; different carriers could ultimately choose different approaches, leaving it to handset makers to build multiple methods into a single phone, though they’re trying to avoid that. In the meantime, in the U.S., Verizon and AT&T use the older CDMA and GSM networks for voice calls, and LTE for data.
LTE in the United States
Of the four major U.S. carriers, AT&T, Verizon, and Sprint have LTE networks, with T-Mobile set to start supporting LTE in the next year. But that doesn’t mean they’re set to play nice. We said earlier that current LTE frequencies are divided up into 33 spectrum bands: With the exception of AT&T and T-Mobile, which share frequencies in band 4, each of the major U.S. carriers has its own band. Verizon uses band 13; Sprint has spectrum in band 26; and AT&T holds band 17 in addition to some crossover in band 4.
In addition, smaller U.S. carriers, like C Spire, U.S. Cellular, and Clearwire, all have their own separate piece of the spectrum pie: C Spire and U.S. Cellular use band 12, while Clearwire uses band 41.
As such, for a manufacturer to support LTE networks in the United States alone, it would need to build a receiver that could tune into seven different LTE bands—let alone the various flavors of GSM-evolved or CDMA networks.
With the iPhone, Apple tried to cut through the current Gordian Knot by releasing two separate models, the A1428 and A1429, which cover a limited number of different frequencies depending on where they’re activated. (Apple has kindly released a list of countries that support its three iPhone 5 models.) Other companies have chosen to restrict devices to certain frequencies, or to make numerous models of the same phone.
Banded together
Other solutions are coming. Qualcomm made a regulatory filing in June regarding a seven-band LTE chip, which could be in shipping devices before the end of 2012 and could allow a future iPhone to be activated in different fashions. Within a year or so, we should see most-of-the-world phones, tablets, and other LTE mobile devices that work on the majority of large-scale LTE networks.
That will be just in time for the next big thing: LTE-Advanced, the true fulfillment of what was once called 4G networking, with rates that could hit 1 Gbps in the best possible cases of wide channels and short distances. By then, perhaps the chip, handset, and carrier worlds will have converged to make it all work neatly together.
Quicksearch
Popular Entries
- The great Ars Android interface shootout (131442)
- Norton cyber crime study offers striking revenue loss statistics (102263)
- MeCam $49 flying camera concept follows you around, streams video to your phone (100454)
- Norton cyber crime study offers striking revenue loss statistics (58492)
- The PC inside your phone: A guide to the system-on-a-chip (58337)
Categories

Show tagged entries
Syndicate This Blog
Calendar
|
|
June '26 | |||||
| Mon | Tue | Wed | Thu | Fri | Sat | Sun |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | |||||