Entries tagged as privacy
Saturday, November 29. 2014
Human rights organizations launch free tool to detect surveillance software
Via Mashable
-----
More and more, governments are using powerful spying software to target human rights activists and journalists, often the forgotten victims of cyberwar. Now, these victims have a new tool to protect themselves.
Called Detekt, it scans a person's computer for traces of surveillance software, or spyware. A coalition of human rights organizations, including Amnesty International and the Electronic Frontier Foundation launched Detekt on Wednesday, with the goal of equipping activists and journalists with a free tool to discover if they've been hacked.
"Our ultimate aim is for human rights defenders, journalists and civil society groups to be able to carry out their legitimate work without fear of surveillance, harassment, intimidation, arrest or torture," Amnesty wroteThursday in a statement.
The open-source tool was developed by security researcher Claudio Guarnieri, a security researcher who has been investigating government abuse of spyware for years. He often collaborates with other researchers at University of Toronto's Citizen Lab.
During their investigations, Guarnieri and his colleagues discovered, for example, that the Bahraini government used software created by German company FinFisher to spy on human rights activists. They also found out that the Ethiopian government spied on journalists in the U.S. and Europe, using software developed by Hacking Team, another company that sells off-the-shelf surveillance tools.
--------------------------
Guarnieri developed Detekt from software he and the other researchers used during those investigations.
--------------------------
"I decided to release it to the public because keeping it private made no sense," he told Mashable. "It's better to give more people as possible the chance to test and identify the problem as quickly as possible, rather than keeping this knowledge private and let it rot."
Detekt only works with Windows, and it's designed to discover malware developed both by commercial firms, as well as popular spyware used by cybercriminals, such as BlackShades RAT (Remote Access Tool) and Gh0st RAT.
The tool has some limitations, though: It's only a scanner, and doesn't remove the malware infection, which is why Detekt's official site warns that if there are traces of malware on your computer, you should stop using it "immediately," and and look for help. It also might not detect newer versions of the spyware developed by FinFisher, Hacking Team and similar companies.
"If Detekt does not find anything, this unfortunately cannot be considered a clean bill of health," the software's "readme" file warns.
For some, given these limitations, Detekt won't help much.
"The tool appears to be a simple signature-based black list that does not promise it knows all the bad files, and admits that it can be fooled," John Prisco, president and CEO of security firm Triumfant, said. "Given that, it seems worthless to me, but that’s probably why it can be offered for free."

Joanna Rutkowska, a researcher who develops the security-minded operating system Qubes, said computers with traditional operating systems are inherently insecure, and that tools like Detekt can't help with that.
"Releasing yet another malware scanner does nothing to address the primary problem," she told Mashable. "Yet, it might create a false sense of security for users."
But Guarnieri disagrees, saying that Detekt is not a silver-bullet solution intended to be used in place of commercial anti-virus software or other security tools.
"Telling activists and journalists to spend 50 euros a year for some antivirus license in emergency situations isn't very helpful," he said, adding that Detekt is not "just a tool," but also an initiative to spark discussion around the government use of intrusive spyware, which is extremely unregulated.
For Mikko Hypponen, a renowned security expert and chief research officer for anti-virus vendor F-Secure, Detekt is a good project because its target audience — activists and journalists — don't often have access to expensive commercial tools.
“Since Detekt only focuses on detecting a handful of spy tools — but detecting them very well — it might actually outperform traditional antivirus products in this particular area,” he told Mashable.
NSA partners with Apache to release open-source data traffic program
Via zdnet
-----
Many of you probably think that the National Security Agency (NSA) and open-source software get along like a house on fire. That's to say, flaming destruction. You would be wrong.

In partnership with the Apache Software Foundation, the NSA announced on Tuesday that it is releasing the source code for Niagarafiles (Nifi). The spy agency said that Nifi "automates data flows among multiple computer networks, even when data formats and protocols differ".
Details on how Nifi does this are scant at this point, while the ASF continues to set up the site where Nifi's code will reside.
In a statement, Nifi's lead developer Joseph L Witt said the software "provides a way to prioritize data flows more effectively and get rid of artificial delays in identifying and transmitting critical information".
The NSA is making this move because, according to the director of the NSA's Technology Transfer Program (TPP) Linda L Burger, the agency's research projects "often have broad, commercial applications".
"We use open-source releases to move technology from the lab to the marketplace, making state-of-the-art technology more widely available and aiming to accelerate U.S. economic growth," she added.
The NSA has long worked hand-in-glove with open-source projects. Indeed, Security-Enhanced Linux (SELinux), which is used for top-level security in all enterprise Linux distributions — Red Hat Enterprise Linux, SUSE Linux Enterprise Server, and Debian Linux included — began as an NSA project.
More recently, the NSA created Accumulo, a NoSQL database store that's now supervised by the ASF.
More NSA technologies are expected to be open sourced soon. After all, as the NSA pointed out: "Global reviews and critiques that stem from open-source releases can broaden a technology's applications for the US private sector and for the good of the nation at large."
Wednesday, September 10. 2014
Project «SurPRISE – Surveillance, Privacy and Security: A large scale participatory assessment of criteria and factors determining acceptability and acceptance of security technologies in Europe»

About the Project
SurPRISE re-examines the relationship between security and privacy, which is commonly positioned as a ‘trade-off’. Where security measures and technologies involve the collection of information about citizens, questions arise as to whether and to what extent their privacy has been infringed. This infringement of individual privacy is sometimes seen as an acceptable cost of enhanced security. Similarly, it is assumed that citizens are willing to trade off their privacy for enhanced personal security in different settings. This common understanding of the security-privacy relationship, both at state and citizen level, has informed policymakers, legislative developments and best practice guidelines concerning security developments across the EU.
However, an emergent body of work questions the validity of the security-privacy trade-off. This work suggests that it has over-simplified how the impact of security measures on citizens is considered in current security policies and practices. Thus, the more complex issues underlying privacy concerns and public skepticism towards surveillance-oriented security technologies may not be apparent to legal and technological experts. In response to these developments, this project will consult with citizens from several EU member and associated states on the question of the security-privacy trade-off as they evaluate different security technologies and measures.
Saturday, June 14. 2014
Google unveils email scanning practices in new terms of service
Via Reuters
-----
Surfboards lean against a wall at the Google office in Santa Monica, California, October 11, 2010.
Credit: Reuters/Lucy Nicholson
(Reuters) - Google Inc updated its terms of service on Monday, informing users that their incoming and outgoing emails are automatically analyzed by software to create targeted ads.
The revisions more explicitly spell out the manner in which Google software scans users' emails, both when messages are stored on Google's servers and when they are in transit, a controversial practice that has been at the heart of litigation.
Last month, a U.S. judge decided not to combine several lawsuits that accused Google of violating the privacy rights of hundreds of millions of email users into a single class action.
Users of Google's Gmail email service have accused the company of violating federal and state privacy and wiretapping laws by scanning their messages so it could compile secret profiles and target advertising. Google has argued that users implicitly consented to its activity, recognizing it as part of the email delivery process.
Google spokesman Matt Kallman said in a statement that the changes "will give people even greater clarity and are based on feedback we've received over the last few months."
Google's updated terms of service added a paragraph stating that "our automated systems analyze your content (including emails) to provide you personally relevant product features, such as customized search results, tailored advertising, and spam and malware detection. This analysis occurs as the content is sent, received, and when it is stored.
(Reporting by Alexei Oreskovic; Editing by Jonathan Oatis, Bernard Orr)
Tuesday, May 13. 2014
How the police can trace photos back to your camera
Via ITProPortal
-----

Forensic experts have long been able to match a series of prints to the hand that left them, or a bullet to the gun that fired it. Now, the same thing is being done with the photos taken by digital cameras, and is ushering in a new era of digital crime fighting.
New technology is now allowing law enforcement officers to search through any collection of images to help track down the identity of photo-taking criminals, such as smartphone thieves and child pornographers.
Investigations in the past have shown that a digital photo can be paired with the exact same camera that took it, due to the patterns of Sensor Pattern Noise (SPN) imprinted on the photos by the camera's sensor.
Since each pattern is idiosyncratic, this allows law enforcement to "fingerprint" any photos taken. And once the signature has been identified, the police can track the criminal across the Internet, through social media and anywhere else they've kept photos.
Researchers have grabbed photos from Facebook, Flickr, Tumblr, Google+, and personal blogs to see whether one individual image could be matched to a specific user's account.
In a paper entitled "On the usage of Sensor Pattern Noise for Picture-to-Identity linking through social network accounts", the team argues that "digital imaging devices have gained an important role in everyone's life, due to a continuously decreasing price, and of the growing interest on photo sharing through social networks"
Monday, April 28. 2014
‘Electronic skin' equipped with memory
Via Nature
-----
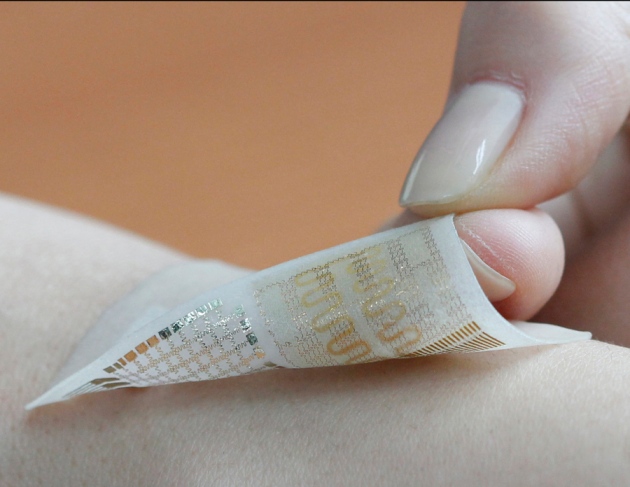
Donghee Son and Jongha Lee - Wearable sensors have until now been unable to store data locally.
Researchers have created a wearable device that is as thin as a temporary tattoo and can store and transmit data about a person’s movements, receive diagnostic information and release drugs into skin.
Similar efforts to develop ‘electronic skin’ abound, but the device is the first that can store information and also deliver medicine — combining patient treatment and monitoring. Its creators, who report their findings today in Nature Nanotechnology1, say that the technology could one day aid patients with movement disorders such as Parkinson’s disease or epilepsy.
The researchers constructed the device by layering a package of stretchable nanomaterials — sensors that detect temperature and motion, resistive RAM for data storage, microheaters and drugs — onto a material that mimics the softness and flexibility of the skin. The result was a sticky patch containing a device roughly 4 centimetres long, 2 cm wide and 0.3 millimetres thick, says study co-author Nanshu Lu, a mechanical engineer at the University of Texas in Austin.
“The novelty is really in the integration of the memory device,” says Stéphanie Lacour, an engineer at the Swiss Federal Institute of Technology in Lausanne, who was not involved in the work. No other device can store data locally, she adds.
The trade-off for that memory milestone is that the device works only if it is connected to a power supply and data transmitter, both of which need to be made similarly compact and flexible before the prototype can be used routinely in patients. Although some commercially available components, such as lithium batteries and radio-frequency identification tags, can do this work, they are too rigid for the soft-as-skin brand of electronic device, Lu says.
Even if softer components were available, data transmitted wirelessly would need to be converted into a readable digital format, and the signal might need to be amplified. “It’s a pretty complicated system to integrate onto a piece of tattoo material,” she says. “It’s still pretty far away.”
Wednesday, April 23. 2014
New Drone Can Hack Into Your Smartphone To Steal Usernames And Passwords
Via Think Progress
-----

CREDIT: AP – Mel Evans
A new hacker-developed drone can lift your smartphone’s private data from your GPS location to mobile applications’ usernames and passwords — without you ever knowing. The drone’s power lies with a new software, Snoopy, which can turn a benign video-capturing drone into a nefarious data thief.
Snoopy intercepts Wi-Fi signals when mobile devices try to find a network connection. London researchers have been testing the drone and plan to debut it at the Black Hat Asia cybersecurity conference in Singapore next week. Snoopy-equipped drones can aid in identity theft and pose a security threat to mobile device users.
Despite its capabilities, the drone software project was built to raise awareness and show consumers how vulnerable their data is to theft, Glenn Wilkinson, a Sensepost security researcher and Snoopy’s co-creator, told CNN Money.
As a part of its controversial surveillance programs, the U.S. National Security Agency already uses similar technology to tap into Wi-Fi connections and control mobile devices. And even though Snoopy hasn’t hit the market, phone-hacking drones could become a reality in the United States now that a federal judge recently overturned the U.S. Federal Aviation Administration’s commercial drone ban. Because the ban was lifted, filmmakers and tech companies such as Facebook and Amazon are now allowed to fly drones — be it to increase Web access or deliver packages — for profit.
Before latching onto a Wi-Fi signal, mobile devices first check to see if any previously connected are nearby. The Snoopy software picks up on this and pretends to be one of those old network connections. Once attached, the drone can access all of your phone’s Internet activity. That information can tell hackers your spending habits and where you work.
With the right tools, Wi-Fi hacks are relatively simple to pull off, and are becoming more common. Personal data can even be sapped from your home’s Wi-Fi router. And because the number of Wi-Fi hotspots keeps growing, consumers must take steps, such as using encrypted sites, to protect their data.
Data breaches overall are happening more often. Customers are still feeling the effect of Target’s breach last year that exposed more than 100 million customers’ personal data. But as smartphones increasingly becoming the epicenter of personal data storage, hacks targeting the device rather than individual apps pose a greater privacy and security threat.
According to a recent Pew Research study, about 50 percent of Web users publicly post their birthday, email or place of work — all of which can be used in ID theft. Nearly 25 percent of people whose credit card information is stolen also suffer identity theft, according to a study published by Javelin Strategy & Research of customers who received data breach notifications in 2012. Moreover, most people manage about 25 online accounts and only use six passwords, quadrupling the potential havoc from one account’s password breach.
Tuesday, March 25. 2014
Google joins Global Alliance for Genomics and Health
Via Slash Gear
-----

Google has made clear their intent on joining the Global Alliance for Genomics and Health, a worldwide organization dedicated to standards, policies, and technology for the greater good of human health. Google’s role in this group will be to contribute toward refining technology and evolving the health research ecosystem for the whole planet.
Google will also be submitting open-source projects based on a web-based API to "import, process, store, and search genomic data at scale." In doing so, Google is submitting a proposal for this "simple web-based API" alongside a full preview implementation. This implementation will be utilizing the API built on Google’s cloud infrastructure, and will include sample data from public datasets galore.
The Google Genomics API will focus on the following from the start:
• Focus on science, not servers and file formats
- Use simple web APIs to access data wherever it lives
- Let us manage the servers and disks
• Store genomic data securely
- Private data remains private, public data is available to the community anywhere
- Storage space expands to fit your research needs
• Process as much data as you need, all at once
- Import data for entire cohorts in parallel
- Search and slice data from many samples in a single query
At the moment, potential users are being granted access to the Genomics API through a access request process. This process is done through Google itself, but may one day be hosted by the Global Alliance for Genomics and Health.

Google suggests that they are at the beginning of a big change in the global health and healthcare environment, and asks that other Global Alliance for Genomics and Health members contact them to "share your ideas about how to bring data science and life science together."
Monday, March 03. 2014
Osaka train station set for large face-recognition study
Via PCWorld
-----

Japan’s Osaka Station could become another focal point in the global battle over personal privacy protection as a Japanese research center prepares for a long-term face-recognition study there.
The independent research group National Institute of Information and Communications Technology (NICT) plans to begin the experiment in April to study crowd movements in order to better plan for emergency procedures during disasters.
The train station is western Japan’s busiest, with an average of 413,000 passengers boarding trains there every day. Over a million people use it and neighboring Umeda Station daily.
NICT will deploy cameras in Osaka Station and the adjacent Osaka Station City, a multipurpose complex, that can track faces as they move around the premises. The cameras will be separate from any security cameras that are already installed by operator West Japan Railway (JR West), a spokesman for the railway said.
"The purpose of the study is to determine whether or not sensor data on crowd movements can be used to validate the safety measures of emergency exits for when a disaster strikes,” a NICT spokesperson said.
JR West referred all questions about the protection of passenger privacy to NICT, but the research institute said the experiment was still being prepared.
"At this time, we are considering the technology to be used to obtain statistics on crowd flows,” the NICT spokesman said. “Depending on the technique used, the data that can be obtained on pedestrian flows will be different. So, it’s difficult to say how many people could be subject (to the experiment).”
NICT would not elaborate on technical aspects of the study, but it said previously that it is slated to run for two years and will involve about 90 cameras and 50 servers.
It said the facial-recognition system can track dozens of points on a face. It emphasized that the data cannot be used to identify people and it will abide by Japan’s Personal Information Protection Law when handling it.
The NICT spokesperson said the institute is not aware of any similar large-scale study.
A report in the Yomiuri Shimbun newspaper said computers linked to the cameras will run face-recognition algorithms and assign IDs to faces, which will be tracked for a week.
The dozens of cameras would be able to track the movements of people the algorithms recognize, and record whether they go to a coffee shop or through a ticket gate, for instance.
The technology under consideration for the study can identify faces with an accuracy of 99.99 percent, according to the report.
Monday, February 24. 2014
Qloudlab

Qloudlab is the inventor and patent holder of the world’s first touchscreen-based biosensor. We are developing a cost-effective technology that is able to turn your smartphone touchscreen into a medical device for multiple blood diagnostics testing: no plug-in required with just a simple disposable. Our innovation is at the convergence of Smartphones, Healthcare, and Cloud solutions. The development is supported by EPFL (Pr. Philippe Renaud, Microsystems Laboratory) and by a major industrial player in cutting-edge touchscreen solutions for consumer, industrial and automotive products.
Quicksearch
Popular Entries
- The great Ars Android interface shootout (131548)
- Norton cyber crime study offers striking revenue loss statistics (102504)
- MeCam $49 flying camera concept follows you around, streams video to your phone (100557)
- The PC inside your phone: A guide to the system-on-a-chip (58743)
- Norton cyber crime study offers striking revenue loss statistics (58733)
Categories

Show tagged entries
Syndicate This Blog
Calendar
|
|
August '26 | |||||
| Mon | Tue | Wed | Thu | Fri | Sat | Sun |
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 | ||||||