A startup called Algorithmia
has a new twist on online matchmaking. Its website is a place for
businesses with piles of data to find researchers with a dreamboat
algorithm that could extract insights–and profits–from it all.
The aim is to make better use of the many algorithms that are
developed in academia but then languish after being published in
research papers, says cofounder Diego Oppenheimer. Many have the
potential to help companies sort through and make sense of the data they
collect from customers or on the Web at large. If Algorithmia makes a
fruitful match, a researcher is paid a fee for the algorithm’s use, and
the matchmaker takes a small cut. The site is currently in a private
beta test with users including academics, students, and some businesses,
but Oppenheimer says it already has some paying customers and should
open to more users in a public test by the end of the year.
“Algorithms solve a problem. So when you have a collection of
algorithms, you essentially have a collection of problem-solving
things,” says Oppenheimer, who previously worked on data-analysis
features for the Excel team at Microsoft.
Oppenheimer and cofounder Kenny Daniel, a former graduate student at
USC who studied artificial intelligence, began working on the site full
time late last year. The company raised $2.4 million in seed funding
earlier this month from Madrona Venture Group and others, including
angel investor Oren Etzioni, the CEO of the Allen Institute for Artificial Intelligence and a computer science professor at the University of Washington.
Etzioni says that many good ideas are essentially wasted in papers
presented at computer science conferences and in journals. “Most of them
have an algorithm and software associated with them, and the problem is
very few people will find them and almost nobody will use them,” he
says.
One reason is that academic papers are written for other academics,
so people from industry can’t easily discover their ideas, says Etzioni.
Even if a company does find an idea it likes, it takes time and money
to interpret the academic write-up and turn it into something testable.
To change this, Algorithmia requires algorithms submitted to its site
to use a standardized application programming interface that makes them
easier to use and compare. Oppenheimer says some of the algorithms
currently looking for love could be used for machine learning,
extracting meaning from text, and planning routes within things like
maps and video games.
Early users of the site have found algorithms to do jobs such as
extracting data from receipts so they can be automatically categorized.
Over time the company expects around 10 percent of users to contribute
their own algorithms. Developers can decide whether they want to offer
their algorithms free or set a price.
All algorithms on Algorithmia’s platform are live, Oppenheimer says,
so users can immediately use them, see results, and try out other
algorithms at the same time.
The site lets users vote and comment on the utility of different
algorithms and shows how many times each has been used. Algorithmia
encourages developers to let others see the code behind their algorithms
so they can spot errors or ways to improve on their efficiency.
One potential challenge is that it’s not always clear who owns the
intellectual property for an algorithm developed by a professor or
graduate student at a university. Oppenheimer says it varies from school
to school, though he notes that several make theirs open source.
Algorithmia itself takes no ownership stake in the algorithms posted on
the site.
Eventually, Etzioni believes, Algorithmia can go further than just
matching up buyers and sellers as its collection of algorithms grows. He
envisions it leading to a new, faster way to compose software, in which
developers join together many different algorithms from the selection
on offer.
When it comes to speeding up Web traffic over the Internet, sometimes
too much of a good thing may not be such a good thing at all.
The Internet Engineering Task Force is putting the final touches on
HTTP/2, the second version of the Hypertext Transport Protocol (HTTP).
The working group has issued a last call draft, urging interested parties to voice concerns before it becomes a full Internet specification.
Not everyone is completely satisfied with the protocol however.
“There is a lot of good in this proposed standard, but I have some
deep reservations about some bad and ugly aspects of the protocol,”
wrote Greg Wilkins, lead developer of the open source Jetty server
software, noting his concerns in a blog item posted Monday.
Others, however, praise HTTP/2 and say it is long overdue.
“A lot of our users are experimenting with the protocol,” said Owen
Garrett, head of products for server software provider NGINX. “The
feedback is that generally, they have seen big performance benefits.”
First created by Web originator Tim Berners-Lee and associates, HTTP
quite literally powers today’s Web, providing the language for a browser
to request a Web page from a server.
SPDY is speediest
Version 2.0 of HTTP, based largely on the SPDY protocol developed by Google, promises to be a better fit for how people use the Web.
“The challenge with HTTP is that it is a fairly simple protocol, and
it can be quite laborious to download all the resources required to
render a Web page. SPDY addresses this issue,” Garrett said.
While the first generation of Web sites were largely simple and
relatively small, static documents, the Web today is used as a platform
for delivering applications and bandwidth intensive real-time multimedia
content.
HTTP/2 speeds basic HTTP in a number of ways. HTTP/2 allows servers
to send all the different elements of a requested Web page at once,
eliminating the serial sets of messages that have to be sent back and
forth under plain HTTP.
HTTP/2 also allows the server and the browser to compress HTTP, which
cuts the amount of data that needs to be communicated between the two.
As a result, HTTP/2 “is really useful for organization with
sophisticated Web sites, particularly when its users are distributed
globally or using slower networks—mobile users for instance,” Garrett
said.
While enthusiastic about the protocol, Wilkins did have several areas
of concern. For instance, HTTP/2 could make it more difficult to
incorporate new Web protocols, most notably the communications protocol WebSocket, Wilkins asserted.
Wilkins noted that HTTP/2 blurs what were previously two distinct
layers of HTTP—the semantic layer, which describes functionality, and
the framework layer, which is the structure of the message. The idea is
that it is simpler to write protocols for a specification with discrete
layers.
The protocol also makes it possible to hide content, including
malicious content, within the headers, bypassing the notice of today’s
firewalls, Wilkins said.
Servers need more power
HTTP/2 could also put a lot more strain on existing servers, Wilkins
noted, given that they will now be fielding many more requests at once.
HTTP/2 “clients will send requests much more quickly, and it is quite
likely you will see spikier traffic as a result,” Garrett agreed.
As a result, a Web application, if it doesn’t already rely on caching
or load balancing, may have to do so with HTTP/2, Garrett said.
The SPDY protocol is already used by almost 1 percent of all the websites, according to an estimate of the W3techs survey company.
NGINX has been a big supporter of SPDY and HTTP/2, not surprising
given that the company’s namesake server software was designed for
high-traffic websites.
Approximately 88 percent of sites that offer SPDY do so with NGINX, according to W3techs.
Yet NGINX has characterized SPDY to its users as “experimental,”
Garrett said, largely because the technology is still evolving and
hasn’t been nailed down yet by the formal specification.
“We’re really forward to when the protocol is rubber-stamped,”
Garrett said. Once HTTP/2 is approved, “We can recommend it to our
customers with confidence,” Garrett said.
Aiming to do for Machine Learning what MySQL did for database servers, U.S. and UK-based PredictionIO has raised $2.5 million in seed funding from a raft of investors including Azure Capital, QuestVP, CrunchFund (of which TechCrunch founder Mike Arrington is a Partner), Stanford University‘s StartX Fund, France-based Kima Ventures,
IronFire, Sood Ventures and XG Ventures. The additional capital will be
used to further develop its open source Machine Learning server, which
significantly lowers the barriers for developers to build more
intelligent products, such as recommendation or prediction engines,
without having to reinvent the wheel.
Being an open source company — after pivoting from offering a “user behavior prediction-as-a-service” under its old TappingStone product name — PredictionIO
plans to generate revenue in the same way MySQL and other open source
products do. “We will offer an Enterprise support license and, probably,
an enterprise edition with more advanced features,” co-founder and CEO
Simon Chan tells me.
The problem PredictionIO is setting out to solve is that building
Machine Learning into products is expensive and time-consuming — and in
some instances is only really within the reach of major and
heavily-funded tech companies, such as Google or Amazon, who can afford a
large team of PhDs/data scientists. By utilising the startup’s open
source Machine Learning server, startups or larger enterprises no longer
need to start from scratch, while also retaining control over the
source code and the way in which PredictionIO integrates with their
existing wares.
In fact, the degree of flexibility and reassurance an open source
product offers is the very reason why PredictionIO pivoted away from a
SaaS model and chose to open up its codebase. It did so within a couple
of months of launching its original TappingStone product. Fail fast, as
they say.
“We changed from TappingStone (Machine Learning as a Service) to
PredictionIO (open source server) in the first 2 months once we built
the first prototype,” says Chan. “As developers ourselves, we realise
that Machine Learning is useful only if it’s customizable to each unique
application. Therefore, we decided to open source the whole product.”
The pivot appears to be working, too, and not just validated by
today’s funding. To date, Chan says its open source Machine Learning
server is powering thousands of applications with 4000+ developers
engaged with the project. “Unlike other data science tools that focus on
solving data researchers’ problems, PredictionIO is built for every
programmer,” he adds.
Other competitors Chan cites include “closed ‘black box” MLaaS
services or software’, such as Google Prediction API, Wise.io, BigML,
and Skytree.
Examples of who is currently using PredictionIO include Le Tote, a
clothing subscription/rental service that is using PredictionIO to
predict customers’ fashion preferences, and PerkHub, which is using
PredictionIO to personalize product recommendations in the weekly ‘group
buying’ emails they send out.
Following
broad security scares like that caused by the Heartbleed bug, it can be
frustratingly difficult to find out if a site you use often still has
gaping flaws. But a little known community of software developers is
trying to change that, by creating a searchable, public index of
websites with known security issues.
Think of Project Un1c0rn as
a Google for site security. Launched on May 15th, the site's creators
say that so far it has indexed 59,000 websites and counting. The goal,
according to its founders, is to document open leaks caused by the
Heartbleed bug, as well as "access to users' databases" in Mongo DB and
MySQL.
According
to the developers, those three types of vulnerabilities are most
widespread because they rely on commonly used tools. For example, Mongo
databases are used by popular sites like LinkedIn, Expedia, and
SourceForge, while MySQL powers applications such as WordPress, Drupal
or Joomla, and are even used by Twitter, Google and Facebook.
Having
a website’s vulnerability indexed publicly is like advertising that you
leave your front doors unlocked and your flat screen in the basement.
But Un1c0rn’s founder sees it as teaching people the value of security.
And his motto is pretty direct. “Raising total awareness by ‘kicking in
the nuts’ is our target,” said the founder, who goes by the alias
SweetCorn.
“The
exploits and future exploits that will be added are just exploiting
people's stupidity or misconception about security from a company
selling or buying bullshit protections,” he said. SweetCorn thinks
Project Un1c0rn is exposing what is already visible without a lot of
effort.
While the Heartbleed bug alerted
the general public to how easily hackers can exploit widely used code,
clearly vulnerabilities don’t begin and end with the bug. Just last week
the CCS Injection vulnerability was discovered, and the OpenSSL foundation posted a security advisory.
“Billions of people are leaving information and trails in
billions of different databases, some just left with default
configurations that can be found in a matter of seconds for whoever has
the resources,” SweetCorn said. Changing and updating passwords is a
crucial practice.
I
reached out to José Fernandez, a computer security expert and professor
at the Polytechnique school in Montreal, to get his take on Project
Un1c0rn. "The (vulnerability) tests are quite objective," he said.
"There are no reasons not to believe the vulnerabilities listed."
Fernandez
added that the only caveat for the search engine was that a listed
server could have been patched after the vulnerability scan had been
run.
The
project is still in its very early stages, with some indexed websites
not yet updated, which means not all of the 58,000 websites listed are
currently vulnerable to the same weaknesses.
“The Un1c0rn is still weak”, admitted SweetCorn. “We
did this with 0.4 BitCoin, I just can't imagine what someone having
enough money to spend on information mining could do.” According to
SweetCorn, those funds were used to buy the domain name and rent
servers.
SweetCorn
is releasing few details about the backend of the project, although he
says it relies heavily on the Tor network. Motherboard couldn’t
independently confirm what kind of search functions SweetCorn is
operating or whether they are legal. In any case, he has bigger plans
for his project: making it the first peer-to-peer decentralized exploit
system, where individuals could host their own scanning nodes.
“We
took some easy steps, Disqus is one of them, we would love to see
security researchers going on Un1c0rn, leave comments and help (us) fix
stuff,” he said.
He hopes that the attention raised by his project will make people understand “what their privacy really (looks like).”
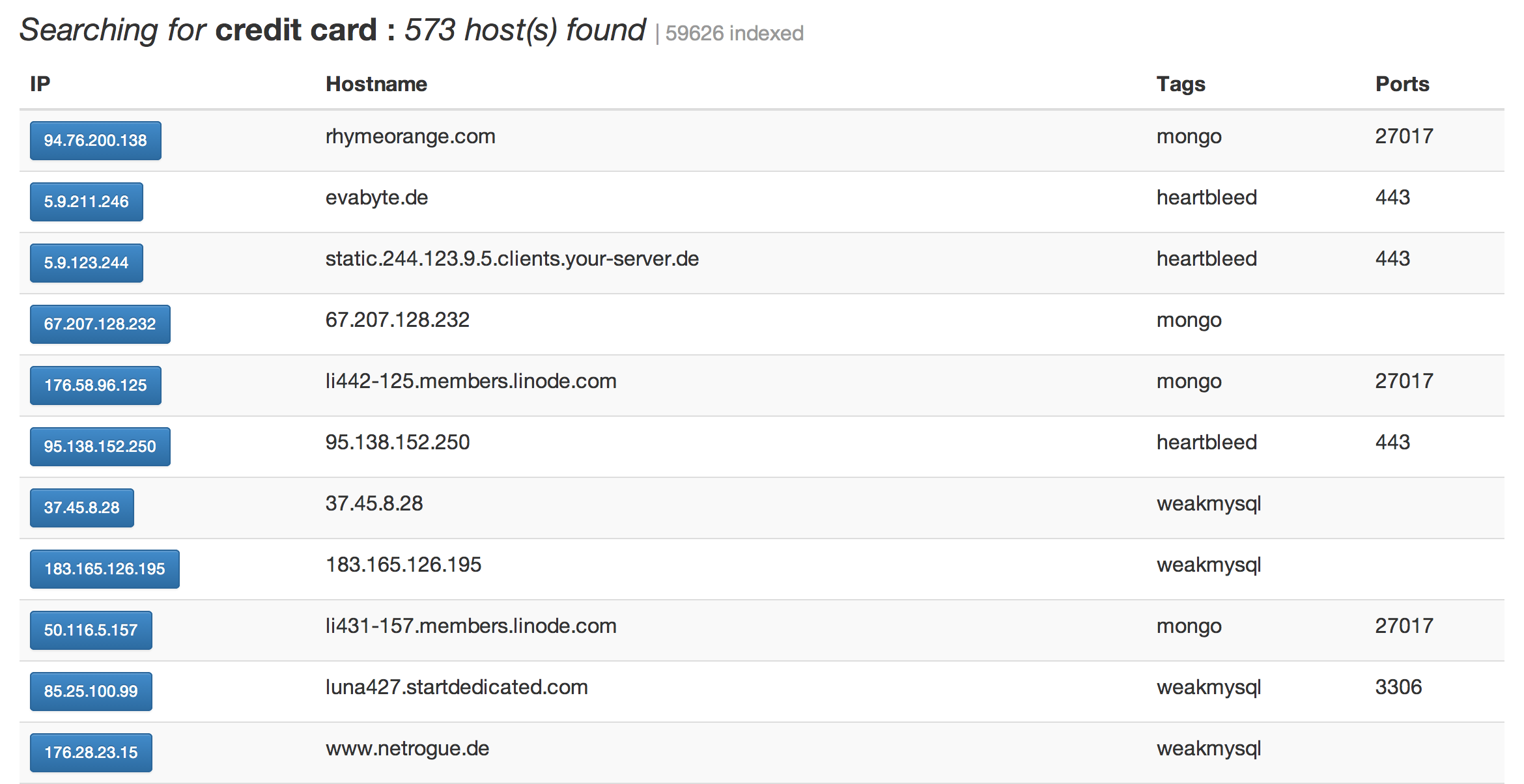
A
quick scan through Un1c0rn’s database brings up some interesting
results. McGill University in Montreal had some trouble with one of
their MySQL databases. The university has since been notified, and their IT team told me the issue had been addressed.
The UK’s cyberspies at the GHCQ
probably forgot they had a test database open (unless it’s a honeypot),
though requests for comments were not answered. A search for “credit
card” retrieves 573 websites, some of which might just host card data if
someone digs enough.
In an example of how bugs can pervade all corners of the
web, the IT team in charge of the VPN for the town of Mandurah in
Australia were probably napping while the rest of the world was patching their broken version of OpenSSL. Tests run with the Qualys SSL Lab and filippo.io tools confirmed the domain was indeed vulnerable to Heartbleed.
While tools to scan for vulnerabilities across the Internet already exist. Last year, the project critical.io did a mass scan of the Internet to look for vulnerabilities, for research purposes. The data was released online and further analyzed by security experts.
But Project Un1c0rn is certainly one of the first to publicly index
the vulnerabilities found. Ultimately, if Project Un1c0rn or something
like it is successful and open sourced, checking if your bank or online
dating site is vulnerable to exploits will be a click away.
Can computers learn to read? We think so. "Read the Web" is a
research project that attempts to create a computer system that learns
over time to read the web. Since January 2010, our computer system
called NELL (Never-Ending Language Learner) has been running
continuously, attempting to perform two tasks each day:
First, it attempts to "read," or extract facts from text found in hundreds of millions of web pages (e.g., playsInstrument(George_Harrison, guitar)).
Second, it attempts to improve its reading competence, so that tomorrow it can extract more facts from the web, more accurately.
So far, NELL has accumulated over 50 million candidate beliefs by
reading the web, and it is considering these at different levels of
confidence. NELL has high confidence in 2,132,551 of these beliefs —
these are displayed on this website. It is not perfect, but NELL is
learning. You can track NELL's progress below or @cmunell on Twitter, browse and download its knowledge base, read more about our technical approach, or join the discussion group.
Chrome, Internet Explorer, and Firefox are vulnerable to
easy-to-execute techniques that allow unscrupulous websites to construct
detailed histories of sites visitors have previously viewed, an attack
that revives a long-standing privacy threat many people thought was
fixed.
Until a few years ago, history-sniffing attacks were accepted as an
unavoidable consequence of Web surfing, no matter what browser someone
used. By abusing a combination of features in JavaScript and cascading style sheets,
websites could probe a visitor's browser to check if it had visited one
or more sites. In 2010, researchers at the University of California at
San Diego caught YouPorn.com and 45 other sites using the technique to determine if visitors viewed other pornographic sites. Two years later, a widely used advertising network settled federal charges that it illegally exploited the weakness to infer if visitors were pregnant.
Until about four years ago, there was little users could do other
than delete browsing histories from their computers or use features such
as incognito or in-private browsing available in Google Chrome and
Microsoft Internet Explorer respectively. The privacy intrusion was
believed to be gradually foreclosed thanks to changes made in each
browser. To solve the problem, browser developers restricted the styles
that could be applied to visited links and tightened the ways JavaScript
could interact with them. That allowed visited links to show up in
purple and unvisited links to appear in blue without that information
being detectable to websites.
Now, a graduate student at Hasselt University in Belgium
said he has confirmed that Chrome, IE, and Firefox users are once again
susceptible to browsing-history sniffing. Borrowing from a browser-timing attack disclosed last year
by fellow researcher Paul Stone, student Aäron Thijs was able to
develop code that forced all three browsers to divulge browsing history
contents. He said other browsers, including Safari and Opera, may also
be vulnerable, although he has not tested them.
"The attack could be used to check if the victim visited certain
websites," Thijs wrote in an e-mail to Ars. "In my example attack
vectors I only check 'https://www.facebook.com'; however, it could be
modified to check large sets of websites. If the script is embedded into
a website that any browser user visits, it can run silently in the
background and a connection could be set up to report the results back
to the attacker."
The sniffing of his experimental attack code was relatively modest,
checking only the one site when the targeted computer wasn't under heavy
load. By contrast, more established exploits from a few years ago were
capable of checking, depending on the browser, about 20 URLs per second.
Thijs said it's possible that his attack might work less effectively if
the targeted computer was under heavy load. Then again, he said it
might be possible to make his attack more efficient by improving his
URL-checking algorithm.
I know what sites you viewed last summer
The browser timing attack technique Thijs borrowed from fellow researcher Stone abuses a programming interface known as requestAnimationFrame,
which is designed to make animations smoother. It can be used to time
the browser's rendering, which is the time it takes for the browser to
display a given webpage. By measuring variations in the time it takes
links to be displayed, attackers can infer if a particular website has
been visited. In addition to browsing history, earlier attacks that
exploited the JavaScript feature were able to sniff out telephone
numbers and other details designated as private in a Google Plus
profile. Those vulnerabilities have been fixed in Chrome and Firefox,
the two browsers that were susceptible to the attack, Thijs said. Stone unveiled the attack at last year's Black Hat security conference in Las Vegas.
The resurrection of viable sniffing history attacks underscores a key
dynamic in security. When defenders close a hole, attackers will often
find creative ways to reopen it. For the time being, users should assume
that any website they visit is able to obtain at least a partial
snapshot of other sites indexed in their browser history. As mentioned
earlier, privacy-conscious people should regularly flush their history
or use private browsing options to conceal visits to sensitive sites.
Forensic experts have long been able to match a series of prints to
the hand that left them, or a bullet to the gun that fired it. Now, the
same thing is being done with the photos taken by digital cameras, and
is ushering in a new era of digital crime fighting.
New technology is now allowing law enforcement officers to search
through any collection of images to help track down the identity of
photo-taking criminals, such as smartphone thieves and child
pornographers.
Investigations in the past have shown that a digital photo can be
paired with the exact same camera that took it, due to the patterns of
Sensor Pattern Noise (SPN) imprinted on the photos by the camera's
sensor.
Since each pattern is idiosyncratic, this allows law enforcement to
"fingerprint" any photos taken. And once the signature has been
identified, the police can track the criminal across the Internet,
through social media and anywhere else they've kept photos.
Researchers have grabbed photos from Facebook, Flickr, Tumblr,
Google+, and personal blogs to see whether one individual image could be
matched to a specific user's account.
In a paper
entitled "On the usage of Sensor Pattern Noise for Picture-to-Identity
linking through social network accounts", the team argues that "digital
imaging devices have gained an important role in everyone's life, due to
a continuously decreasing price, and of the growing interest on photo
sharing through social networks"
Today, "everyone continuously leaves visual 'traces' of his/her
presence and life on the Internet, that can constitute precious data for
forensic investigators."
The researchers were able to match a photo with a specific person 56
per cent of the time in their experiment, which examined 10 different
people's photos found on two separate websites each.
The team concludes that the technique has yielded a "promising result,"
which demonstrates that such it has "practical value for forensic
practitioners".
While the certainty of the technique is only just better than chance,
the technology is pretty new, and the numbers could get a bit more
promising in the future. And, like fingerprints, the SPN signature would
likely only be a part of the case being brought against a suspect.
Virtual 3D faces can now be produced from DNA code. The application,
developed by Mark Shriver of Pennsylvania State University, produces a
virtual mug shot of potential criminals. Pictured here is a work flow
diagram showing how facial features were processed for the application. (Photo : PLOS ONE)
Models of a criminal's face may so be generated from any trace of DNA
left at the scene of a crime. Computer-generated 3D maps will show
exactly how the suspect would have looked from an angle.
Mark Shriver of Pennsylvania State University and his team developed
the application, which produces a virtual mug shot of potential
criminals.
Shriver and his team took 3D images of almost 600 volunteers, coming
from a wide range of racial and ethnic groups. They superimposed more
than 7,000 digital points of reference on the facial features and
recorded the exact position of each of those markers. These grids were
used to measure how the facial features of a subject differ from the
norm. For instance, they would quantify the distance between the eyes of
a subject, and record how much more narrow or wide they were than
average.
A computer model was created to see how facial features were affected
by sex, genes and race. Each of the study participants were tested for
76 genetic variants that cause facial mutations. Once corrected for
race and sex, 20 genes with 24 variants appeared to reliably predict
facial shape.
"Results on a set of 20 genes showing significant effects on facial
features provide support for this approach as a novel means to identify
genes affecting normal-range facial features and for approximating the
appearance of a face from genetic markers," the researchers wrote in the article announcing the results.
As part of data collection, the team asked participants to rate faces based on perceived ethnicity, as well as gender.
Digital facial reconstructions from DNA have proven to be notoriously
unreliable. Even seemingly simple information like height can be
difficult to determine through genetic analysis. Other aspects of human
physiology, such as eye color, are easier to predict using genetic
analysis.
"One thing we're certain of [is] there's no single gene that suddenly
makes your nose big or small," Kun Tang, from the Shanghai Institutes
for Biological Sciences in China, said.
In order to further refine the system, Shriver has already started
sampling more people. Adding further diversity to the database should
allow the application to make even more accurate recreations of a
person's face. In the next round of testing, 30,000 different points
will be used instead of 7,000. Merging this development with 3D
printers would make it possible to print out 3D models of a person, just based on a piece of DNA.
Such models - digital or physical - are not likely to be used in
courts anytime soon. A more likely scenario is use as modern day version
of police sketches, assisting police in finding suspects. Only after an
arrest would the DNA of a suspect be compared to that collected at the
scene of a crime.
Creating 3D facial models from genetic evidence was detailed in Nature.
Your old phones and tablets don’t have to become e-waste. They can do
real work as repurposed sidekicks for your PC. Think of them as bonus
touchscreen displays and you’ll begin to see the possibilities. They
just need to be plugged in, wiped of unneeded apps and notifications,
and they’re ready to serve as desktop companions. Here are some of the
best ways to reuse that old tech.
Turn your tablet into a second monitor
Air Display can turn your tablet into a true second screen for your PC or Mac.
One simple way to get some extra mileage out of an old tablet is to turn
it into a dedicated PC monitor. Even with just 7-inch tablet, you can
use the extra screen to keep an eye on instant messages, email, or
social networks. If you’re working with photos, video or music, the
second screen could even serve as a dedicated space for toolbars. It’s
also an easy second screen to pack up and take with you.
I suggest Air Display, a $10 app for iOS andAndroid that connects to your main computer over Wi-Fi. (A $5 app called iDisplay
also supports USB connections on Android devices, but I had trouble
getting it to work on a 2012 Nexus 7.) You may also want to pick up a
cheap tablet stand, such as this one.
Use your phone as an air mouse or dictation tool
Unified Remote for Android can be used as an impromptu gesture or voice control tool, among other things.
If you need a break from hunching
over your desk, a spare smartphone can serve as a touchscreen mouse for
your PC. All you need is a remote mouse app that communicates with a
companion desktop app over Wi-Fi.
On the iPhone, Mobile Mouse
is a fine option that supports gestures such as two-finger scrolling.
You can add gyroscopic air mouse controls by upgrading to the $2 Pro version. Mobile Mouse’s Android version isn’t quite as slick, so for that platform I recommend Unified Remote instead.
Here’s a neat trick for either app: With your phone’s on-screen keyboard, use the microphone key for voice dictation on your PC.
Turn your tablet into a full-blown command center
With a little effort and a few bucks, your tablet can be more than just
an extra trackpad. The touch screen can also quickly launch applications
and execute commands faster than you can point and click with a mouse.
iPad users should check out Actions,
a $5 app that lets you create buttons for all the things you do most on
your PC. You can quickly launch a new window in Chrome, expose the
desktop, open the search bar, or control media playback. Just install
the companion server app for Windows or Mac and start shaving the
minutes off your work routine.
Actions for iPad is a colorful, customizable, and incredibly handy tool for controlling your PC.
For Android, the premium version of Unified Remote
comes close to what Actions offers, even if it isn’t as snazzy. The $4
upgrade gives access to lots of app-specific control panels, plus a way
to create your own panels.
Set up a small file server with battery backup
In terms of raw storage, an old phone or tablet can’t compare to a
networked hard drive. But it’s good enough for documents or a small
number of media files—especially if you can pop in a microSD card for
extra capacity. Plus, mobile devices can hum along for days on battery
power, so you can still get to your files even if someone shuts off your
computer. Think of it as do-it-yourself cloud storage, without the
cloud.
To transfer files onto your phone or tablet, you could just plug it into
your PC and drag-and-drop. Or you could go the automated route: Install
BitTorrent Sync on your PC and your phone, and use the “sync folders” option to back up whatever folders you want.
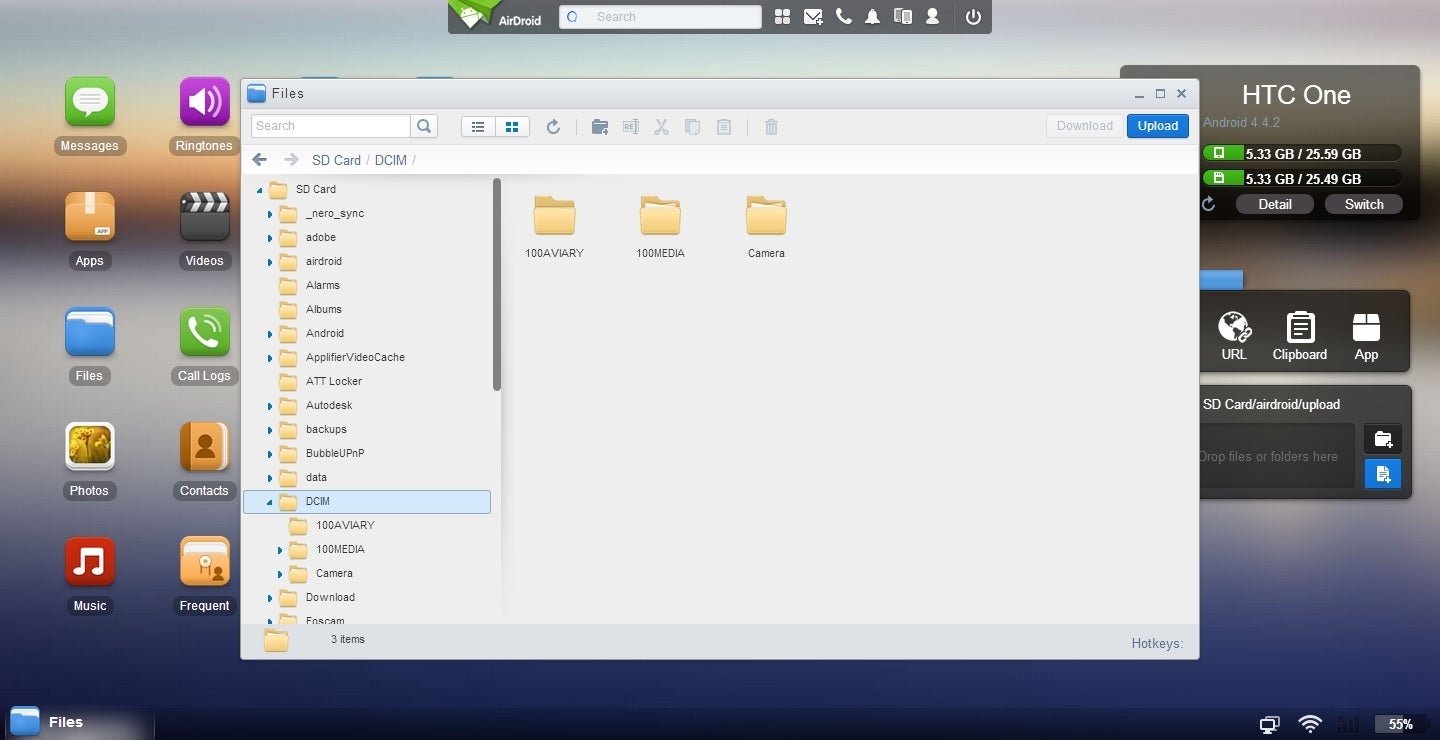
AirDroid makes shifting files from your phone to your PC and back again absolutely painless. (Click to enlarge.)
The easiest way to access Android files remotely is with AirDroid. Install the app on your phone and create a login (or just sign in with your Google account), then visit web.airdroid.com
from any browser. After signing in, you’ll be able to access your
phone’s file directory and snag anything you need. (Just make sure to
disable “power saving mode” in AirDroid’s settings first.)
Create a desktop calculator or document scanner
Tapping digits on a touch screen is easier than pointing and clicking on your PC’s built-in calculator program. (PCalc for iOS and Real Calc for Android are both free for basic calculations, and you can upgrade to paid versions if you need more features.)
CamScanner’s a handy tool for quickly scanning documents, complete with
baked-in optical character regonition technology to extract text from
pics as well as tools to optimize your images.
As long as you’re making up for missing peripherals, you can also use
your phone as a document scanner. CamScanner, available for both iOS and Android, is loaded with features, and you can try it for free. The paid version costs $5 per month on both platforms.
Dedicate it to calls and video chats
If you’re working on a small laptop or an older PC with limited
processing power, you may want to offload Skype calls, Google Hangouts,
or other video chat applications to a separate phone or tablet. That
way, you can free up your PC’s resources—and its screen—for taking notes
or pulling up reference files. This one’s easy: All you need is a phone
or tablet with a front-facing camera and a cheap stand or monitor
mount. (You could also MacGyver your own phone stand or monitor mount for practically nothing.)
Create minimalist writing/sketching station
Working on a connected tablet is a great way to eliminate the distractions that crop up on PCs.
The lack of a windowing system on iOS and Android can be a burden for
serious work, but sometimes a break from multitasking can help you
focus. Grab a cheap Bluetooth keyboard if you want, and dedicate a spot
in your office for writing without distractions. A good note-taking app that syncs online, such as Evernote or the Android-only Google Keep, is especially useful, since whatever you write will be waiting for you when you get back to your computer.
Of course, a text editor isn’t the only tool you could have at your disposal. You could also install a diagram app, such as Lucidchart or Idea Sketch, or grab a pressure-sensitive stylus for free-form sketching.
The advantage of
repurposing an older device is that you can completely dedicate it to
the task. There’s nothing stopping you from using a brand-new phone or
tablet for any of these purposes, however. Check out PCWorld’s guide to 13 highly productive Android appsthat play nice with your PC.
This week the experimental developer-aimed group known as Google ATAP
- aka Advanced Technology and Projects (skunkworks) have announced
Project Tango. They’ve suggested Project Tango will appear first as a
phone with 3D sensors. These 3D sensors will be able to scan and build a
map of the room they’re in, opening up a whole world of possibilities.
The device that Project Tango will release first will be just about
as limited-edition as they come. Issued in an edition of 200, this
device will be sent to developers only. This developer group will be
hand-picked by Google’s ATAP - and sign-ups start today. (We’ll be
publishing the sign-up link once active.)
Speaking on this skunkworks project this morning was Google
user Johnny Lee. Mister Johnny Lee is ATAP’s technical program lead,
and he’ll be heading this project for the public, as you’ll see it. This
is the same group that brought you Motorola’s digital tattoos, if you’ll remember.