Entries tagged as algorythm
Tuesday, December 16. 2014
We’ve Put a Worm’s Mind in a Lego Robot's Body
Via Smithsonian
-----
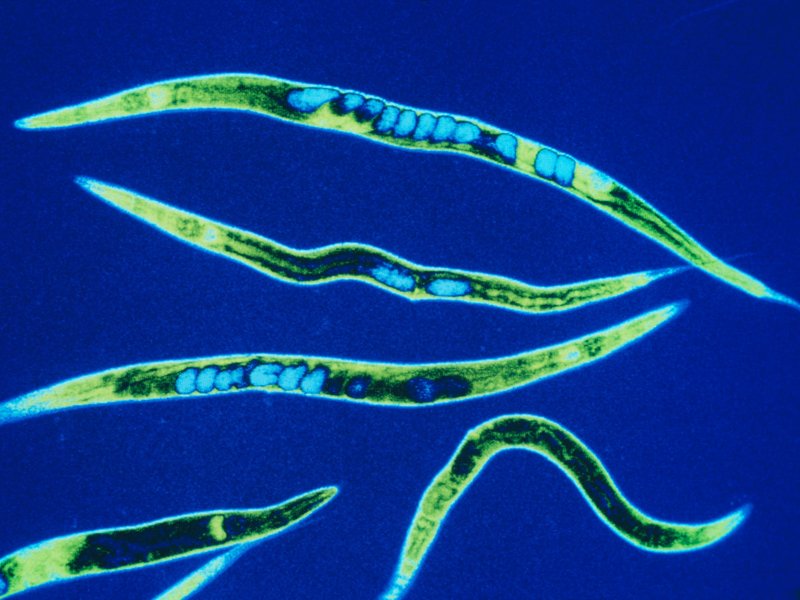
If the brain is a collection of electrical signals, then, if you could catalog all those those signals digitally, you might be able upload your brain into a computer, thus achieving digital immortality.
While the plausibility—and ethics—of this upload for humans can be debated, some people are forging ahead in the field of whole-brain emulation. There are massive efforts to map the connectome—all the connections in the brain—and to understand how we think. Simulating brains could lead us to better robots and artificial intelligence, but the first steps need to be simple.
So, one group of scientists started with the roundworm Caenorhabditis elegans, a critter whose genes and simple nervous system we know intimately.
The OpenWorm project has mapped the connections between the worm’s 302 neurons and simulated them in software. (The project’s ultimate goal is to completely simulate C. elegans as a virtual organism.) Recently, they put that software program in a simple Lego robot.
The worm’s body parts and neural networks now have LegoBot equivalents: The worm’s nose neurons were replaced by a sonar sensor on the robot. The motor neurons running down both sides of the worm now correspond to motors on the left and right of the robot, explains Lucy Black for I Programmer. She writes:
---
It is claimed that the robot behaved in ways that are similar to observed C. elegans. Stimulation of the nose stopped forward motion. Touching the anterior and posterior touch sensors made the robot move forward and back accordingly. Stimulating the food sensor made the robot move forward.
---
Timothy Busbice, a founder for the OpenWorm project, posted a video of the Lego-Worm-Bot stopping and backing:
The simulation isn’t exact—the program has some simplifications on the thresholds needed to trigger a "neuron" firing, for example. But the behavior is impressive considering that no instructions were programmed into this robot. All it has is a network of connections mimicking those in the brain of a worm.
Of course, the goal of uploading our brains assumes that we aren’t already living in a computer simulation. Hear out the logic: Technologically advanced civilizations will eventually make simulations that are indistinguishable from reality. If that can happen, odds are it has. And if it has, there are probably billions of simulations making their own simulations. Work out that math, and "the odds are nearly infinity to one that we are all living in a computer simulation," writes Ed Grabianowski for io9.
Is your mind spinning yet?
Thursday, October 02. 2014
A Dating Site for Algorithms
-----
![]()
A startup called Algorithmia has a new twist on online matchmaking. Its website is a place for businesses with piles of data to find researchers with a dreamboat algorithm that could extract insights–and profits–from it all.
The aim is to make better use of the many algorithms that are developed in academia but then languish after being published in research papers, says cofounder Diego Oppenheimer. Many have the potential to help companies sort through and make sense of the data they collect from customers or on the Web at large. If Algorithmia makes a fruitful match, a researcher is paid a fee for the algorithm’s use, and the matchmaker takes a small cut. The site is currently in a private beta test with users including academics, students, and some businesses, but Oppenheimer says it already has some paying customers and should open to more users in a public test by the end of the year.
“Algorithms solve a problem. So when you have a collection of algorithms, you essentially have a collection of problem-solving things,” says Oppenheimer, who previously worked on data-analysis features for the Excel team at Microsoft.
Oppenheimer and cofounder Kenny Daniel, a former graduate student at USC who studied artificial intelligence, began working on the site full time late last year. The company raised $2.4 million in seed funding earlier this month from Madrona Venture Group and others, including angel investor Oren Etzioni, the CEO of the Allen Institute for Artificial Intelligence and a computer science professor at the University of Washington.
Etzioni says that many good ideas are essentially wasted in papers presented at computer science conferences and in journals. “Most of them have an algorithm and software associated with them, and the problem is very few people will find them and almost nobody will use them,” he says.
One reason is that academic papers are written for other academics, so people from industry can’t easily discover their ideas, says Etzioni. Even if a company does find an idea it likes, it takes time and money to interpret the academic write-up and turn it into something testable.
To change this, Algorithmia requires algorithms submitted to its site to use a standardized application programming interface that makes them easier to use and compare. Oppenheimer says some of the algorithms currently looking for love could be used for machine learning, extracting meaning from text, and planning routes within things like maps and video games.
Early users of the site have found algorithms to do jobs such as extracting data from receipts so they can be automatically categorized. Over time the company expects around 10 percent of users to contribute their own algorithms. Developers can decide whether they want to offer their algorithms free or set a price.
All algorithms on Algorithmia’s platform are live, Oppenheimer says, so users can immediately use them, see results, and try out other algorithms at the same time.
The site lets users vote and comment on the utility of different algorithms and shows how many times each has been used. Algorithmia encourages developers to let others see the code behind their algorithms so they can spot errors or ways to improve on their efficiency.
One potential challenge is that it’s not always clear who owns the intellectual property for an algorithm developed by a professor or graduate student at a university. Oppenheimer says it varies from school to school, though he notes that several make theirs open source. Algorithmia itself takes no ownership stake in the algorithms posted on the site.
Eventually, Etzioni believes, Algorithmia can go further than just matching up buyers and sellers as its collection of algorithms grows. He envisions it leading to a new, faster way to compose software, in which developers join together many different algorithms from the selection on offer.
Monday, August 12. 2013
IBM Looks to Human Brain to Devise New Programming Model
Tuesday, December 04. 2012
The Relevance of Algorithms
By Tarleton Gillespie
-----
I’m really excited to share my new essay, “The Relevance of Algorithms,” with those of you who are interested in such things. It’s been a treat to get to think through the issues surrounding algorithms and their place in public culture and knowledge, with some of the participants in Culture Digitally (here’s the full litany: Braun, Gillespie, Striphas, Thomas, the third CD podcast, and Anderson‘s post just last week), as well as with panelists and attendees at the recent 4S and AoIR conferences, with colleagues at Microsoft Research, and with all of you who are gravitating towards these issues in their scholarship right now.
The motivation of the essay was two-fold: first, in my research on online platforms and their efforts to manage what they deem to be “bad content,” I’m finding an emerging array of algorithmic techniques being deployed: for either locating and removing sex, violence, and other offenses, or (more troublingly) for quietly choreographing some users away from questionable materials while keeping it available for others. Second, I’ve been helping to shepherd along this anthology, and wanted my contribution to be in the spirit of the its aims: to take one step back from my research to articulate an emerging issue of concern or theoretical insight that (I hope) will be of value to my colleagues in communication, sociology, science & technology studies, and information science.
The anthology will ideally be out in Fall 2013. And we’re still finalizing the subtitle. So here’s the best citation I have.
Gillespie, Tarleton. “The Relevance of Algorithms. forthcoming, in Media Technologies, ed. Tarleton Gillespie, Pablo Boczkowski, and Kirsten Foot. Cambridge, MA: MIT Press.
Below is the introduction, to give you a taste.

Algorithms play an increasingly important role in selecting what information is considered most relevant to us, a crucial feature of our participation in public life. Search engines help us navigate massive databases of information, or the entire web. Recommendation algorithms map our preferences against others, suggesting new or forgotten bits of culture for us to encounter. Algorithms manage our interactions on social networking sites, highlighting the news of one friend while excluding another’s. Algorithms designed to calculate what is “hot” or “trending” or “most discussed” skim the cream from the seemingly boundless chatter that’s on offer. Together, these algorithms not only help us find information, they provide a means to know what there is to know and how to know it, to participate in social and political discourse, and to familiarize ourselves with the publics in which we participate. They are now a key logic governing the flows of information on which we depend, with the “power to enable and assign meaningfulness, managing how information is perceived by users, the ‘distribution of the sensible.’” (Langlois 2012)
Algorithms need not be software: in the broadest sense, they are encoded procedures for transforming input data into a desired output, based on specified calculations. The procedures name both a problem and the steps by which it should be solved. Instructions for navigation may be considered an algorithm, or the mathematical formulas required to predict the movement of a celestial body across the sky. “Algorithms do things, and their syntax embodies a command structure to enable this to happen” (Goffey 2008, 17). We might think of computers, then, fundamentally as algorithm machines — designed to store and read data, apply mathematical procedures to it in a controlled fashion, and offer new information as the output.
But as we have embraced computational tools as our primary media of expression, and have made not just mathematics but all information digital, we are subjecting human discourse and knowledge to these procedural logics that undergird all computation. And there are specific implications when we use algorithms to select what is most relevant from a corpus of data composed of traces of our activities, preferences, and expressions.
These algorithms, which I’ll call public relevance algorithms, are — by the very same mathematical procedures — producing and certifying knowledge. The algorithmic assessment of information, then, represents a particular knowledge logic, one built on specific presumptions about what knowledge is and how one should identify its most relevant components. That we are now turning to algorithms to identify what we need to know is as momentous as having relied on credentialed experts, the scientific method, common sense, or the word of God.
What we need is an interrogation of algorithms as a key feature of our information ecosystem (Anderson 2011), and of the cultural forms emerging in their shadows (Striphas 2010), with a close attention to where and in what ways the introduction of algorithms into human knowledge practices may have political ramifications. This essay is a conceptual map to do just that. I will highlight six dimensions of public relevance algorithms that have political valence:
1. Patterns of inclusion: the choices behind what makes it into an index in the first place, what is excluded, and how data is made algorithm ready
2. Cycles of anticipation: the implications of algorithm providers’ attempts to thoroughly know and predict their users, and how the conclusions they draw can matter
3. The evaluation of relevance: the criteria by which algorithms determine what is relevant, how those criteria are obscured from us, and how they enact political choices about appropriate and legitimate knowledge
4. The promise of algorithmic objectivity: the way the technical character of the algorithm is positioned as an assurance of impartiality, and how that claim is maintained in the face of controversy
5. Entanglement with practice: how users reshape their practices to suit the algorithms they depend on, and how they can turn algorithms into terrains for political contest, sometimes even to interrogate the politics of the algorithm itself
6. The production of calculated publics: how the algorithmic presentation of publics back to themselves shape a public’s sense of itself, and who is best positioned to benefit from that knowledge.
Considering how fast these technologies and the uses to which they are put are changing, this list must be taken as provisional, not exhaustive. But as I see it, these are the most important lines of inquiry into understanding algorithms as emerging tools of public knowledge and discourse.
It would also be seductively easy to get this wrong. In attempting to say something of substance about the way algorithms are shifting our public discourse, we must firmly resist putting the technology in the explanatory driver’s seat. While recent sociological study of the Internet has labored to undo the simplistic technological determinism that plagued earlier work, that determinism remains an alluring analytical stance. A sociological analysis must not conceive of algorithms as abstract, technical achievements, but must unpack the warm human and institutional choices that lie behind these cold mechanisms. I suspect that a more fruitful approach will turn as much to the sociology of knowledge as to the sociology of technology — to see how these tools are called into being by, enlisted as part of, and negotiated around collective efforts to know and be known. This might help reveal that the seemingly solid algorithm is in fact a fragile accomplishment.
~ ~ ~
Here is the full article [PDF]. Please feel free to share it, or point people to this post.
Thursday, January 19. 2012
The faster-than-fast Fourier transform
Quicksearch
Popular Entries
- The great Ars Android interface shootout (129277)
- MeCam $49 flying camera concept follows you around, streams video to your phone (97971)
- Norton cyber crime study offers striking revenue loss statistics (94465)
- The PC inside your phone: A guide to the system-on-a-chip (55661)
- Norton cyber crime study offers striking revenue loss statistics (50694)
Categories

Show tagged entries
Syndicate This Blog
Calendar
|
|
July '24 | |||||
| Mon | Tue | Wed | Thu | Fri | Sat | Sun |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 | ||||