Chrome, Internet Explorer, and Firefox are vulnerable to
easy-to-execute techniques that allow unscrupulous websites to construct
detailed histories of sites visitors have previously viewed, an attack
that revives a long-standing privacy threat many people thought was
fixed.
Until a few years ago, history-sniffing attacks were accepted as an
unavoidable consequence of Web surfing, no matter what browser someone
used. By abusing a combination of features in JavaScript and cascading style sheets,
websites could probe a visitor's browser to check if it had visited one
or more sites. In 2010, researchers at the University of California at
San Diego caught YouPorn.com and 45 other sites using the technique to determine if visitors viewed other pornographic sites. Two years later, a widely used advertising network settled federal charges that it illegally exploited the weakness to infer if visitors were pregnant.
Until about four years ago, there was little users could do other
than delete browsing histories from their computers or use features such
as incognito or in-private browsing available in Google Chrome and
Microsoft Internet Explorer respectively. The privacy intrusion was
believed to be gradually foreclosed thanks to changes made in each
browser. To solve the problem, browser developers restricted the styles
that could be applied to visited links and tightened the ways JavaScript
could interact with them. That allowed visited links to show up in
purple and unvisited links to appear in blue without that information
being detectable to websites.
Now, a graduate student at Hasselt University in Belgium
said he has confirmed that Chrome, IE, and Firefox users are once again
susceptible to browsing-history sniffing. Borrowing from a browser-timing attack disclosed last year
by fellow researcher Paul Stone, student Aäron Thijs was able to
develop code that forced all three browsers to divulge browsing history
contents. He said other browsers, including Safari and Opera, may also
be vulnerable, although he has not tested them.
"The attack could be used to check if the victim visited certain
websites," Thijs wrote in an e-mail to Ars. "In my example attack
vectors I only check 'https://www.facebook.com'; however, it could be
modified to check large sets of websites. If the script is embedded into
a website that any browser user visits, it can run silently in the
background and a connection could be set up to report the results back
to the attacker."
The sniffing of his experimental attack code was relatively modest,
checking only the one site when the targeted computer wasn't under heavy
load. By contrast, more established exploits from a few years ago were
capable of checking, depending on the browser, about 20 URLs per second.
Thijs said it's possible that his attack might work less effectively if
the targeted computer was under heavy load. Then again, he said it
might be possible to make his attack more efficient by improving his
URL-checking algorithm.
I know what sites you viewed last summer
The browser timing attack technique Thijs borrowed from fellow researcher Stone abuses a programming interface known as requestAnimationFrame,
which is designed to make animations smoother. It can be used to time
the browser's rendering, which is the time it takes for the browser to
display a given webpage. By measuring variations in the time it takes
links to be displayed, attackers can infer if a particular website has
been visited. In addition to browsing history, earlier attacks that
exploited the JavaScript feature were able to sniff out telephone
numbers and other details designated as private in a Google Plus
profile. Those vulnerabilities have been fixed in Chrome and Firefox,
the two browsers that were susceptible to the attack, Thijs said. Stone unveiled the attack at last year's Black Hat security conference in Las Vegas.
The resurrection of viable sniffing history attacks underscores a key
dynamic in security. When defenders close a hole, attackers will often
find creative ways to reopen it. For the time being, users should assume
that any website they visit is able to obtain at least a partial
snapshot of other sites indexed in their browser history. As mentioned
earlier, privacy-conscious people should regularly flush their history
or use private browsing options to conceal visits to sensitive sites.
How anonymous are you when browsing online? If you're not sure, head
to StayInvisible, where you'll get an immediate online privacy test
revealing what identifiable information is being collected in your
browser.
The site displays the location (via IP address) and
language collected, possible tracking cookies, and other browser
features that could create a unique fingerprint of your browser and session.
If you'd prefer your browsing to be private and anonymous, we have lotsof guidesfor that. Although StayInvisible no longer has the list of proxy tools we mentioned previously, the site is also still useful if you want to test your proxy or VPN server's effectiveness. (Could've come in handy too for a certain CIA director and his biographer.)
At today’s hearing
of the Subcommittee on Intellectual Property, Competition and the
Internet of the House Judiciary Committee, I referred to an attempt to
“sabotage” the forthcoming Do Not Track standard. My written testimony
discussed a number of other issues as well, but Do Not Track was
clearly on the Representatives’ minds: I received multiple questions on
the subject. Because of the time constraints, oral answers at a
Congressional hearing are not the place for detail, so in this blog
post, I will expand on my answers this morning, and explain why I think
that word is appropriate to describe the current state of play.
Background
For years, advertising networks have offered the option to opt out
from their behavioral profiling. By visiting a special webpage provided
by the network, users can set a browser cookie saying, in effect, “This
user should not be tracked.” This system, while theoretically offering
consumers choice about tracking, suffers from a series of problems that
make it frequently ineffective in practice. For one thing, it relies
on repetitive opt-out: the user needs to visit multiple opt-out pages, a
daunting task given the large and constantly shifting list of
advertising companies, not all of which belong to industry groups with
coordinated opt-out pages. For another, because it relies on
cookies—the same vector used to track users in the first place—it is
surprisingly fragile. A user who deletes cookies to protect her privacy
will also delete the no-tracking cookie, thereby turning tracking back
on. The resulting system is a monkey’s paw: unless you ask for what you want in exactly the right way, you get nothing.
The idea of a Do Not Track header gradually emerged
in 2009 and 2010 as a simpler alternative. Every HTTP request by which
a user’s browser asks a server for a webpage contains a series of headers
with information about the webpage requested and the browser. Do Not
Track would be one more. Thus, the user’s browser would send, as part
of its request, the header:
DNT: 1
The presence of such a header would signal to the website that the
user requests not to be tracked. Privacy advocates and technologists
worked to flesh out the header; privacy officials in the United States
and Europe endorsed it. The World Wide Web Consortium (W3C) formed a
public Tracking Protection Working Group with a charter to design a technical standard for Do Not Track.
Significantly, a W3C standard is not law. The legal effect of Do Not
Track will come from somewhere else. In Europe, it may be enforced directly on websites under existing data protection law. In the United States, legislation has been introduced in the House and Senate
that would have the Federal Trade Commission promulgate Do Not Track
regulations. Without legislative authority, the FTC could not require
use of Do Not Track, but would be able to treat a website’s false claims
to honor Do Not Track as a deceptive trade practice. Since most online
advertising companies find it important from a public relations point
of view to be able to say that they support consumer choice, this last
option may be significant in practice. And finally, in an important recent paper,
Joshua Fairfield argues that use of the Do Not Track header itself
creates an enforceable contract prohibiting tracking under United States
law.
In all of these cases, the details of the Do Not Track standard will
be highly significant. Websites’ legal duties are likely to depend on
the technical duties specified in the standard, or at least be strongly
influenced by them. For example, a company that promises to be Do Not
Track compliant thereby promises to do what is required to comply with
the standard. If the standard ultimately allows for limited forms of
tracking for click-fraud prevention, the company can engage in those
forms of tracking even if the user sets the header. If not, it cannot.
Thus, there is a lot at stake in the Working Group’s discussions.
Internet Explorer and Defaults
On May 31, Microsoft announced that Do Not Track would be on by default
in Internet Explorer 10. This is a valuable feature, regardless of how
you feel about behavioral ad targeting itself. A recurring theme of
the online privacy wars is that unusably complicated privacy interfaces
confuse users in ways that cause them to make mistakes and undercut
their privacy. A default is the ultimate easy-to-use privacy control.
Users who care about what websites know about them do not need to
understand the details to take a simple step to protect themselves.
Using Internet Explorer would suffice by itself to prevent tracking from
a significant number of websites.
This is an important principle. Technology can empower users to
protect their privacy. It is impractical, indeed impossible, for users
to make detailed privacy choices about every last detail of their online
activities. The task of getting your privacy right is profoundly
easier if you have access to good tools to manage the details.
Antivirus companies compete vigorously to manage the details of malware
prevention for users. So too with privacy: we need thriving markets in
tools under the control of users to manage the details.
There is immense value if users can delegate some of their privacy
decisions to software agents. These delegation decisions should be dead
simple wherever possible. I use Ghostery
to block cookies. As tools go, it is incredibly easy to use—but it
still is not easy enough. The choice of browser is a simple choice, one
that every user makes. That choice alone should be enough to count as
an indication of a desire for privacy. Setting Do Not Track by default
is Microsoft’s offer to users. If they dislike the setting, they can
change it, or use a different browser.
The Pushback
Microsoft’s move intersected with a long-simmering discussion on the
Tracking Protection Working Group’s mailing list. The question of Do
Not Track defaults had been one of the first issues the Working Group raised when it launched in September 2011. The draft text that emerged by the spring remains painfully ambiguous on the issue. Indeed, the group’s May 30 teleconference—the
day before Microsoft’s announcement—showed substantial disagreement
about defaults and what a server could do if it believed it was seeing a
default Do Not Track header, rather than one explicitly set by the
user. Antivirus software AVG includes a cookie-blocking tool
that sets the Do Not Track header, which sparked extensive discussion
about plugins, conflicting settings, and explicit consent. And the last
few weeks following Microsoft’s announcement have seen a renewed debate
over defaults.
Many industry participants object to Do Not Track by default.
Technology companies with advertising networks have pushed for a crucial
pair of positions:
User agents (i.e. browsers and apps) that turned on Do Not Track by default would be deemed non-compliant with the standard.
Websites that received a request from a noncompliant user agent would be free to disregard a DNT: 1 header.
This position has been endorsed by representatives the three
companies I mentioned in my testimony today: Yahoo!, Google, and Adobe.
Thus, here is an excerpt from an email to the list by Shane Wiley from Yahoo!:
If you know that an UA is non-compliant, it should be fair to NOT
honor the DNT signal from that non-compliant UA and message this back to
the user in the well-known URI or Response Header.
Here is an excerpt from an email to the list by Ian Fette from Google:
There’s other people in the working group, myself included, who feel that
since you are under no obligation to honor DNT in the first place (it is
voluntary and nothing is binding until you tell the user “Yes, I am
honoring your DNT request”) that you already have an option to reject a
DNT:1 request (for instance, by sending no DNT response headers). The
question in my mind is whether we should provide websites with a mechanism
to provide more information as to why they are rejecting your request, e.g.
“You’re using a user agent that sets a DNT setting by default and thus I
have no idea if this is actually your preference or merely another large
corporation’s preference being presented on your behalf.”
And here is an excerpt from an email to the list by Roy Fielding from Adobe:
The server would say that the non-compliant browser is broken and
thus incapable of transmitting a true signal of the user’s preferences.
Hence, it will ignore DNT from that browser, though it may provide
other means to control its own tracking. The user’s actions are
irrelevant until they choose a browser capable of communicating
correctly or make use of some means other than DNT.
Pause here to understand the practical implications of writing this
position into the standard. If Yahoo! decides that Internet Explorer 10
is noncompliant because it defaults on, then users who picked Internet
Explorer 10 to avoid being tracked … will be tracked. Yahoo! will claim
that it is in compliance with the standard and Internet Explorer 10 is
not. Indeed, there is very little that an Internet Explorer 10 user
could do to avoid being tracked. Because her user agent is now flagged
by Yahoo! as noncompliant, even if she manually sets the header herself,
it will still be ignored.
The Problem
A cynic might observe how effectively this tactic neutralizes the
most serious threat that Do Not Track poses to advertisers: that people
might actually use it. Manual opt-out cookies are tolerable
because almost no one uses them. Even Do Not Track headers that are off
by default are tolerable because very few people will use them.
Microsoft’s and AVG’s decisions raise the possibility that significant
numbers of web users would be removed from tracking. Pleasing user
agent noncompliance is a bit of jujitsu, a way of meeting the threat
where it is strongest. The very thing that would make Internet Explorer
10’s Do Not Track setting widely used would be the very thing to
“justify” ignoring it.
But once websites have an excuse to look beyond the header they
receive, Do Not Track is dead as a practical matter. A DNT:1 header is
binary: it is present or it is not. But second-guessing interface
decisions is a completely open-ended question. Was the check box to
enable Do Not Track worded clearly? Was it bundled with some other user
preference? Might the header have been set by a corporate network
rather than the user? These are the kind of process questions that can
be lawyered to death. Being able to question whether a user really meant her Do Not Track header is a license to ignore what she does mean.
Return to my point above about tools. I run a browser with multiple
plugins. At the end of the day, these pieces of software collaborate to
set a Do Not Track header, or not. This setting is under my control: I
can install or uninstall any of the software that was responsible for
it. The choice of header is strictly between me and my user agent. As far as the Do Not Track specification is concerned,
websites should adhere to a presumption of user competence: whatever
value the header has, it has with the tacit or explicit consent of the
user.
Websites are not helpless against misconfigured software. If they
really think the user has lost control over her own computer, they have a
straightforward, simple way of finding out. A website can display a
popup window or an overlay, asking the user whether she really wants to
enable Do Not Track, and explaining the benefits disabling it would
offer. Websites have every opportunity to press their case for
tracking; if that case is as persuasive as they claim, they should have
no fear of making it one-on-one to users.
This brings me to the bitterest irony of Do Not Track defaults. For
more than a decade, the online advertising industry has insisted that
notice and an opportunity to opt out is sufficient choice for consumers.
It has fought long and hard against any kind of heightened consent
requirement for any of its practices. Opt-out, in short, is good
enough. But for Do Not Track, there and there alone, consumers
allegedly do not understand the issues, so consent must be explicit—and opt-in only.
Now What?
It is time for the participants in the Tracking Protection Working
Group to take a long, hard look at where the process is going. It is
time for the rest of us to tell them, loudly, that the process is going
awry. It is true that Do Not Track, at least in the present regulatory
environment, is voluntary. But it does not follow that the standard
should allow “compliant” websites to pick and choose which pieces to
comply with. The job of the standard is to spell out how a user agent
states a Do Not Track request, and what behavior is required of websites
that choose to implement the standard when they receive such a request.
That is, the standard must be based around a simple principle:
A Do Not Track header expresses a meaning, not a process.
The meaning of “DNT: 1” is that the receiving website should not
track the user, as spelled out in the rest of the standard. It is not
the website’s concern how the header came to be set.
Microsoft has let it be known that their final release of the Internet Explorer 10
web browser software will have “Do Not Track” activated right out of
the box. This information has upset advertisers across the board as web
ad targeting – based on your online activities – is one of the current
mainstays of big-time advertiser profits. What Do Not Track, or DNT does
is to send out signal from your web browser, Internet Explorer 10 in
this case, to websites letting them know that the user refuses to be
seen in such a way.
A very similar Do Not Track feature currently exists on Mozilla’s Firefox browser
and is swiftly becoming ubiquitous around the web as a must-have
feature for web privacy. This will very likely bring about a large
change in the world of online advertising specifically as, again,
advertisers rely on invisible tracking methods so heavily. Tracking in
place today also exists on sites such as Google where your search
history will inform Google on what you’d like to see for search results, News posts, and advertisement content.
The Digital Advertising Aliance, or DAA, has countered Microsoft’s
announcement saying that the IE10 browser release would oppose
Microsoft’s agreement with the White House earlier this year. This
agreement had the DAA agreeing to recognize and obey the Do Not Track
signals from IE10 just so long as the option to have DNT activated was
not turned on by default. Microsoft Chief Privacy Officer Brendan Lynch
spoke up this week on the situation this week as well.
“In a world where consumers live a large part of their
lives online, it is critical that we build trust that their personal
information will be treated with respect, and that they will be given a
choice to have their information used for unexpected purposes.
While there is still work to do in agreeing on an industry-wide
definition of DNT, we believe turning on Do Not Track by default in IE10
on Windows 8 is an important step in this process of establishing
privacy by default, putting consumers in control and building trust
online.” – Lynch
It's no secret that there's big money to be made in violating your
privacy. Companies will pay big bucks to learn more about you, and
service providers on the web are eager to get their hands on as much
information about you as possible.
So what do you do? How do you keep your information out of everyone
else's hands? Here's a guide to surfing the web while keeping your
privacy intact.
The adage goes, "If you're not paying for a service, you're the
product, not the customer," and it's never been more true. Every day
more news breaks about a new company that uploads your address book to their servers, skirts in-browser privacy protection, and tracks your every move on the web
to learn as much about your browsing habits and activities as possible.
In this post, we'll explain why you should care, and help you lock down
your surfing so you can browse in peace.
Why You Should Care
Your personal information is valuable. More valuable than you might think. When we originally published our guide to stop Facebook from tracking you around the web,
some people cried "So what if they track me? I'm not that important/I
have nothing to hide/they just want to target ads to me and I'd rather
have targeted ads over useless ones!" To help explain why this is
short-sighted and a bit naive, let me share a personal story.
Before I joined the Lifehacker team, I worked at a company that
traded in information. Our clients were huge companies and one of the
services we offered was to collect information about people, their
demographics, income, and habits, and then roll it up so they could get a
complete picture about who you are and how to convince you to buy their
products. In some cases, we designed web sites and campaigns to
convince you to provide even more information in exchange for a coupon,
discount, or the simple promise of other of those. It works very, very
well.
The real money is in taking your data and shacking up with third parties to help them
come up with new ways to convince you to spend money, sign up for
services, and give up more information. Relevant ads are nice, but the
real value in your data exists where you won't see it until you're too
tempted by the offer to know where it came from, whether it's a coupon
in your mailbox or a new daily deal site with incredible bargains
tailored to your desires. It all sounds good until you realize the only
thing you have to trade for such "exciting" bargains is everything
personal about you: your age, income, family's ages and income, medical
history, dietary habits, favorite web sites, your birthday...the list
goes on. It would be fine if you decided to give up this information for
a tangible benefit, but you may never see a benefit aside from an ad,
and no one's including you in the decision. Here's how to take back that
control.
Click for instructions for your browser of choice:
How to Stop Trackers from Following Where You're Browsing with Chrome
If you're a Chrome user, there are tons of great add-ons and tools
designed to help you uncover which sites transmit data to third parties
without your knowledge, which third parties are talking about you, and
which third parties are tracking your activity across sites. This list
isn't targeted to a specific social network or company—instead, these
extensions can help you with multiple offenders.
Adblock Plus
- We've discussed AdBlock plus several times, but there's never been a
better time to install it than now. For extra protection, one-click
installs the Antisocial
subscription for AdBlock. With it, you can banish social networks like
Facebook, Twitter, and Google+ from transmitting data about you after
you leave those sites, even if the page you visit has a social plugin on
it.
Ghostery -
Ghostery does an excellent job at blocking the invisible tracking
cookies and plug-ins on many web sites, showing it all to you, and then
giving you the choice whether you want to block them one-by-one, or all
together so you'll never worry about them again. The best part about
Ghostery is that it's not just limited to social networks, but will also
catch and show you ad-networks and web publishers as well.
ScriptNo for Chrome
- ScriptNo is much like Ghostery in that any scripts running on any
site you visit will sound its alarms. The difference is that while
Ghostery is a bit more exclusive about the types of information it
alerts you to, ScriptNo will sound the alarm at just about everything,
which will break a ton of websites. You'll visit the site, half
of it won't load or work, and you'll have to selectively enable scripts
until it's usable. Still, its intuitive interface will help you choose
which scripts on a page you'd like to allow and which you'd like to
block without sacrificing the actual content on the page you'd like to
read.
Do Not Track Plus - The "Do Not Track" feature that most browsers have is useful, but if you want to beef them up, the previously mentioned
Do Not Track Plus extension puts a stop to third-party data exchanges,
like when you visit a site like ours that has Facebook and Google+
buttons on it. By default, your browser will tell the network that
you're on a site with those buttons—with the extension installed, no
information is sent until you choose to click one. Think of it as opt-in
social sharing, instead of all-in.
Ghostery, AdBlock Plus, and Do Not Track are the ones you'll need the
most. ScriptNo is a bit more advanced, and may take some getting used
to. In addition to installing extensions, make sure you practice basic
browser maintenance that keeps your browser running smoothly and
protects your privacy at the same time. Head into Chrome's Advanced
Content Settings, and make sure you have third-party cookies blocked and
all cookies set to clear after browsing sessions. Log out of social
networks and web services when you're finished using them instead of
just leaving them perpetually logged in, and use Chrome's "Incognito
Mode" whenever you're concerned about privacy.
Mobile Browsing
Mobile browsing is a new frontier. There are dozens of mobile
browsers, and even though most people use the one included on their
device, there are few tools to protect your privacy by comparison to the
desktop. Check to see if your preferred browser has a "privacy mode"
that you can use while browsing, or when you're logged in to social
networks and other web services. Try to keep your social network use
inside the apps developed for it, and—as always—make sure to clear your
private data regularly.
If none of these extensions make you feel any better, or you want to
take protecting your privacy and personal data to the next level, it's
time to break out the big guns. One tip that came up during our last
discussion about Facebook was to use a completely separate web browser
just for logged-in social networks and web services, and another browser
for potentially sensitive browsing, like your internet shopping,
banking, and other personal activities. If you have some time to put
into it, check out our guide to browsing without leaving a trace, which was written for Firefox, but can easily be adapted to any browser you use.
If you're really tired of companies tracking you and trading in your
personal information, you always have the option to just provide false
information. The same way you might give a fake phone number or address
to a supermarket card sign-up sheet, you can scrub or change personal
details about yourself from your social network profiles, Google
accounts, Windows Live account, and others.
Change your birthdate, or your first name. Set your phone number a
digit off, or omit your apartment number when asked for your street
address. We've talked about how to disappear before,
and carefully examine the privacy and account settings for the web
services you use. Keep in mind that some of this goes against the terms
of service for those companies and services—they have a vested interest
in knowing the real you, after all, so tread carefully and tread lightly
if you want to go the "make yourself anonymous" route. Worst case,
start closing accounts with offending services, and migrate to other,
more privacy-friendly options.
These are just a few tips that won't significantly change your
browsing experience, but can go a long way toward protecting your
privacy. This issue isn't going anywhere, and as your personal
information becomes more valuable and there are more ways to keep it
away from prying eyes, you'll see more news of companies finding ways to
eke out every bit of data from you and the sites you use. Some of these
methods are more intrusive than others, and some of them may turn you
off entirely, but the important thing is that they all give you
control over how you experience the web. When you embrace your privacy,
you become engaged with the services you use. With a little effort and
the right tools, you can make the web more opt-in than it is opt-out.
Microsoft announced that it will be launching silent updates for IE9 in January.
Despite
the controversy of user control, Microsoft especially has a reason to
make this move to react to browser "update fatigue" that has resulted in
virtually "stale" IE users who won't upgrade their browsers unless they
upgrade their operating system as well.
The most recent upgrade of Google's Chrome browser
shows just how well the silent update feature works. Within five days
of introduction, Chrome 15 market share fell from 24.06 percent to just
6.38 percent, while the share of Chrome 16 climbed from 0.35 percent to
19.81 percent, according to StatCounter.
Within five days, Google moved about 75 percent of its user base - more
than 150 million users - from one browser to another. Within three
days, Chrome 16 market share surpassed the market share of IE9
(currently at about 10.52 percent for this month), in four days it
surpassed Firefox 8 (currently at about 15.60 percent) and will be
passing IE8 today, StatCounter data indicates.
What makes this data so important is the fact that Google is
dominating HTML5 capability across all operating system platforms and
not just Windows 7, where IE9 has a slight advantage, according to
Microsoft (StatCounter does not break out data for browser share on
individual operating systems). IE9 was introduced on March 14 of 2011,
has captured only 10.52 percent market share and has followed a similar
slow upgrade pattern as its predecessors. For example, IE, which was
introduced in March 2009, reached its market share peak in the month IE9
was introduced - at 30.24 percent. Since then, the browser has declined
to only 22.17 percent and 57.52 percent of the IE user base still uses
IE8 today.
With the silent updates becoming available for IE8 and IE9,
Microsoft is likely to avoid another IE6 disaster with IE8. Even more
important for Microsoft is that those users who update to IE9 may be
less likely to switch to Chrome.
Once Upon is a brilliant project that has recreated three popular sites from today as if they were built in the dial-up era, in 1997.
Witness Facebook, with no real-names policy and photos displayed in
an ugly grey table; YouTube, with a choice of encoding options to select
before you watch a video, and Google+, where Circles of contacts are
displayed as far easier to render squares. Be prepared for a wait though
– the recreations are limited to 8kbps transfer speeds, as if you were
loading it on a particularly slow dial-up connection.
This is perhaps the most extreme version of Web nostalgia we’ve seen. On a related note, these imaginings of what online social networking would have been like in centuries gone by are worth a look. Also, our report on 10 websites that changed the world is worth reading- they’re not what you might expect.
When Tim Berners-Lee arrived at CERN,
Geneva's celebrated European Particle Physics Laboratory in 1980, the
enterprise had hired him to upgrade the control systems for several of
the lab's particle accelerators. But almost immediately, the inventor of
the modern webpage noticed a problem: thousands of people were floating
in and out of the famous research institute, many of them temporary
hires.
"The big challenge for contract programmers was to try to
understand the systems, both human and computer, that ran this fantastic
playground," Berners-Lee later wrote. "Much of the crucial information
existed only in people's heads."
So in his spare time, he wrote up some software to address this
shortfall: a little program he named Enquire. It allowed users to create
"nodes"—information-packed index card-style pages that linked to other
pages. Unfortunately, the PASCAL application ran on CERN's proprietary
operating system. "The few people who saw it thought it was a nice idea,
but no one used it. Eventually, the disk was lost, and with it, the
original Enquire."
Some years later Berners-Lee returned to CERN.
This time he relaunched his "World Wide Web" project in a way that
would more likely secure its success. On August 6, 1991, he published an
explanation of WWW on the alt.hypertext usegroup. He also released a code library, libWWW, which he wrote with his assistant
Jean-François Groff. The library allowed participants to create their own Web browsers.
"Their efforts—over half a dozen browsers within 18 months—saved
the poorly funded Web project and kicked off the Web development
community," notes a commemoration of this project by the Computer History Museum in Mountain View, California. The best known early browser was Mosaic, produced by Marc Andreesen and Eric Bina at the
National Center for Supercomputing Applications (NCSA).
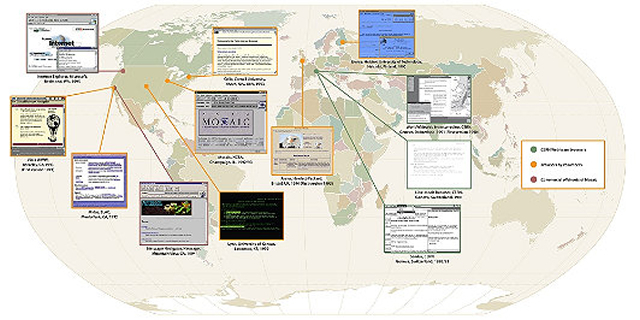
Mosaic was soon spun into Netscape, but it was not the first browser. A map
assembled by the Museum offers a sense of the global scope of the early
project. What's striking about these early applications is that they
had already worked out many of the features we associate with later
browsers. Here is a tour of World Wide Web viewing applications, before
they became famous.
The CERN browsers
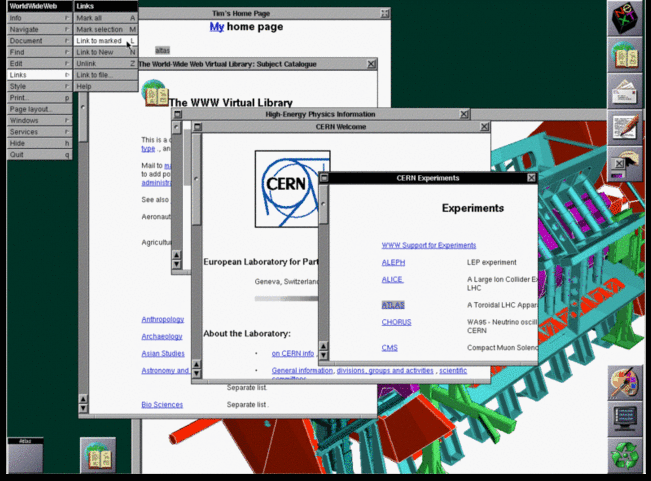
Tim Berners-Lee's original 1990 WorldWideWeb browser was both a
browser and an editor. That was the direction he hoped future browser
projects would go. CERN has put together a reproduction
of its formative content. As you can see in the screenshot below, by
1993 it offered many of the characteristics of modern browsers.
Tim Berners-Lee's original WorldWideWeb browser running on a NeXT computer in 1993
The software's biggest limitation was that it ran on the NeXTStep
operating system. But shortly after WorldWideWeb, CERN mathematics
intern Nicola Pellow wrote a line mode browser that could function
elsewhere, including on UNIX and MS-DOS networks. Thus "anyone could
access the web," explains Internet historian Bill Stewart, "at that point consisting primarily of the CERN phone book."
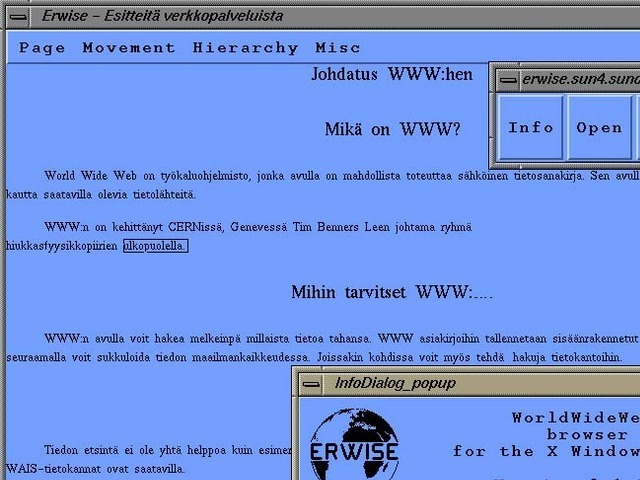
Erwise came next. It was written by four Finnish college students in 1991 and released in 1992. Erwise is credited as the first browser that offered a graphical interface. It could also search for words on pages.
Berners-Lee wrote a review
of Erwise in 1992. He noted its ability to handle various fonts,
underline hyperlinks, let users double-click them to jump to other
pages, and to host multiple windows.
"Erwise looks very smart," he declared, albeit puzzling over a
"strange box which is around one word in the document, a little like a
selection box or a button. It is neither of these—perhaps a handle for
something to come."
So why didn't the application take off? In a later interview, one of
Erwise's creators noted that Finland was mired in a deep recession at
the time. The country was devoid of angel investors.
"We could not have created a business around Erwise in Finland then," he explained.
"The only way we could have made money would have been to continue our
developing it so that Netscape might have finally bought us. Still, the
big thing is, we could have reached the initial Mosaic level with
relatively small extra work. We should have just finalized Erwise and
published it on several platforms."
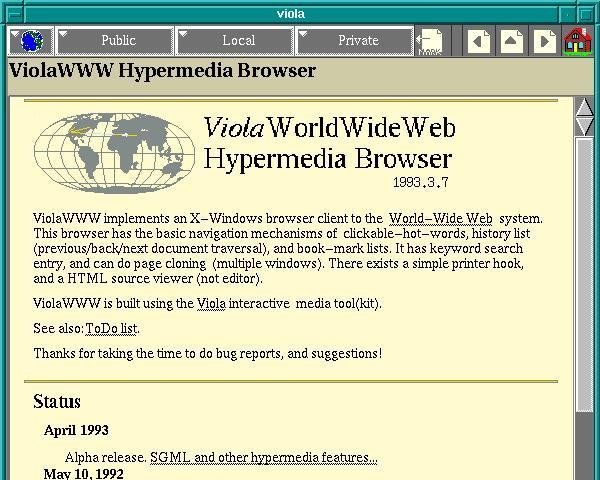
ViolaWWW was released in April
of 1992. Developer
Pei-Yuan Wei wrote it at the University of California at Berkeley via
his UNIX-based Viola programming/scripting language. No, Pei Wei didn't
play the viola, "it just happened to make a snappy abbreviation" of
Visually Interactive Object-oriented Language and Application, write
James Gillies and Robert Cailliau in their history of the World Wide
Web.
Wei appears to have gotten his inspiration from the early Mac
program HyperCard, which allowed users to build matrices of formatted
hyper-linked documents. "HyperCard was very compelling back then, you
know graphically, this hyperlink thing," he later recalled. But the
program was "not very global and it only worked on Mac. And I didn't
even have a Mac."
But he did have access to UNIX X-terminals at UC Berkeley's
Experimental Computing Facility. "I got a HyperCard manual and looked at
it and just basically took the concepts and implemented them in
X-windows." Except, most impressively, he created them via his Viola
language.
One of the most significant and innovative features of ViolaWWW was
that it allowed a developer to embed scripts and "applets" in the
browser page. This anticipated the huge wave of Java-based applet
features that appeared on websites in the later 1990s.
In his documentation, Wei also noted various "misfeatures" of ViolaWWW, most notably its inaccessibility to PCs.
Not ported to PC platform.
HTML Printing is not supported.
HTTP is not interruptable, and not multi-threaded.
Proxy is still not supported.
Language interpreter is not multi-threaded.
"The author is working on these problems... etc," Wei acknowledged
at the time. Still, "a very neat browser useable by anyone: very
intuitive and straightforward," Berners-Lee concluded in his review
of ViolaWWW. "The extra features are probably more than 90% of 'real'
users will actually use, but just the things which an experienced user
will want."
In September of 1991, Stanford Linear Accelerator physicist Paul
Kunz visited CERN. He returned with the code necessary to set up the
first North American Web server at SLAC. "I've just been to CERN," Kunz
told SLAC's head librarian Louise Addis, "and I found this wonderful
thing that a guy named Tim Berners-Lee is developing. It's just the
ticket for what you guys need for your database."
Addis agreed. The site's head librarian put the research center's
key database over the Web. Fermilab physicists set up a server shortly
after.
Then over the summer of 1992 SLAC physicist Tony Johnson wrote Midas, a graphical browser for the Stanford physics community. The big draw
for Midas users was that it could display postscript documents, favored
by physicists because of their ability to accurately reproduce
paper-scribbled scientific formulas.
"With these key advances, Web use surged in the high energy physics community," concluded a 2001 Department of Energy assessment of SLAC's progress.
Meanwhile, CERN associates Pellow and Robert Cailliau released the
first Web browser for the Macintosh computer. Gillies and Cailliau
narrate Samba's development.
For Pellow, progress in getting Samba up and running was slow,
because after every few links it would crash and nobody could work out
why. "The Mac browser was still in a buggy form,' lamented Tim
[Berners-Lee] in a September '92 newsletter. 'A W3 T-shirt to the first
one to bring it up and running!" he announced. The T shirt duly went to
Fermilab's John Streets, who tracked down the bug, allowing Nicola
Pellow to get on with producing a usable version of Samba.
Samba "was an attempt to port the design of the original WWW
browser, which I wrote on the NeXT machine, onto the Mac platform,"
Berners-Lee adds,
"but was not ready before NCSA [National Center for Supercomputing
Applications] brought out the Mac version of Mosaic, which eclipsed it."
Mosaic was "the spark that lit the Web's explosive growth in 1993,"
historians Gillies and Cailliau explain. But it could not have been
developed without forerunners and the NCSA's University of Illinois
offices, which were equipped with the best UNIX machines. NCSA also had
Dr. Ping Fu, a PhD computer graphics wizard who had worked on morphing
effects for Terminator 2. She had recently hired an assistant named Marc Andreesen.
"How about you write a graphical interface for a browser?" Fu
suggested to her new helper. "What's a browser?" Andreesen asked. But
several days later NCSA staff member Dave Thompson gave a demonstration
of Nicola Pellow's early line browser and Pei Wei's ViolaWWW. And just
before this demo, Tony Johnson posted the first public release of Midas.
The latter software set Andreesen back on his heels. "Superb!
Fantastic! Stunning! Impressive as hell!" he wrote to Johnson. Then
Andreesen got NCSA Unix expert Eric Bina to help him write their own
X-browser.
Mosaic offered many new web features, including support for video
clips, sound, forms, bookmarks, and history files. "The striking thing
about it was that unlike all the earlier X-browsers, it was all
contained in a single file," Gillies and Cailliau explain:
Installing it was as simple as pulling it across the network and
running it. Later on Mosaic would rise to fame because of the
<IMG> tag that allowed you to put images inline for the first
time, rather than having them pop up in a different window like Tim's
original NeXT browser did. That made it easier for people to make Web
pages look more like the familiar print media they were use to; not
everyone's idea of a brave new world, but it certainly got Mosaic
noticed.
"What I think Marc did really well," Tim Berners-Lee later wrote,
"is make it very easy to install, and he supported it by fixing bugs via
e-mail any time night or day. You'd send him a bug report and then two
hours later he'd mail you a fix."
Perhaps Mosaic's biggest breakthrough, in retrospect, was that it
was a cross-platform browser. "By the power vested in me by nobody in
particular, X-Mosaic is hereby released," Andreeson proudly declared on
the www-talk group on January 23, 1993. Aleks Totic unveiled his Mac
version a few months later. A PC version came from the hands of Chris
Wilson and Jon Mittelhauser.
The Mosaic browser was based on Viola and Midas, the Computer History museum's exhibit notes.
And it used the CERN code library. "But unlike others, it was reliable,
could be installed by amateurs, and soon added colorful graphics within
Web pages instead of as separate windows."
The Mosaic browser was available for X Windows, the Mac, and Microsoft Windows
But Mosaic wasn't the only innovation to show up on the scene around that same time. University of Kansas student Lou Montulli
adapted a campus information hypertext browser for the Internet and
Web. It launched in March, 1993. "Lynx quickly became the preferred web
browser for character mode terminals without graphics, and remains in
use today," historian Stewart explains.
And at Cornell University's Law School, Tom Bruce was writing a Web
application for PCs, "since those were the computers that lawyers tended
to use," Gillies and Cailliau observe. Bruce unveiled his browser Cello on June 8, 1993, "which was soon being downloaded at a rate of 500 copies a day."
Cello!
Six months later, Andreesen was in Mountain View, California, his
team poised to release Mosaic Netscape on October 13, 1994. He, Totic,
and Mittelhauser nervously put the application up on an FTP server. The
latter developer later recalled the moment. "And it was five minutes and
we're sitting there. Nothing has happened. And all of a sudden the
first download happened. It was a guy from Japan. We swore we'd send him
a T shirt!"
But what this complex story reminds is that is that no innovation is
created by one person. The Web browser was propelled into our lives by
visionaries around the world, people who often didn't quite understand
what they were doing, but were motivated by curiosity, practical
concerns, or even playfulness. Their separate sparks of genius kept the
process going. So did Tim Berners-Lee's insistence that the project stay
collaborative and, most importantly, open.
"The early days of the web were very hand-to-mouth," he writes. "So many things to do, such a delicate flame to keep alive."
Further reading
Tim Berners-Lee, Weaving the Web: The Original Design and Ultimate Destiny of the World Wide Web
James Gillies and R. Cailliau, How the web was born
As new platform versions get released more and more quickly,
are users keeping up? Zeh Fernando, a senior developer at Firstborn,
looks at current adoption rates and points to some intriguing trends
There's a quiet revolution happening on the web, and it's related to one aspect of the rich web that is rarely discussed: the adoption rate of new platform versions.
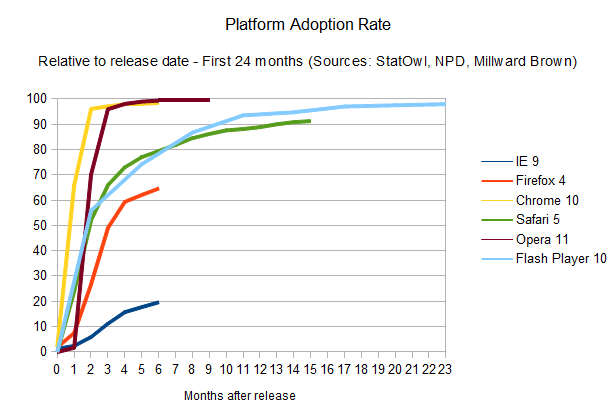
First,
to put things into perspective, we can look at the most popular browser
plug-in out there: Adobe's Flash Player. It's pretty well known that
the adoption of new versions of the Flash plug-in happens pretty
quickly: users update Flash Player quickly and often after a new version
of the plug-in is released [see Adobe's sponsored NPD, United
States, Mar 2000-Jun 2006, and Milward Brown’s “Mature markets”, Sep
2006-Jun 2011 research (here and here) collected by way of the Internet Archive and saved over time; here’s the complete spreadsheet with version release date help from Wikipedia].
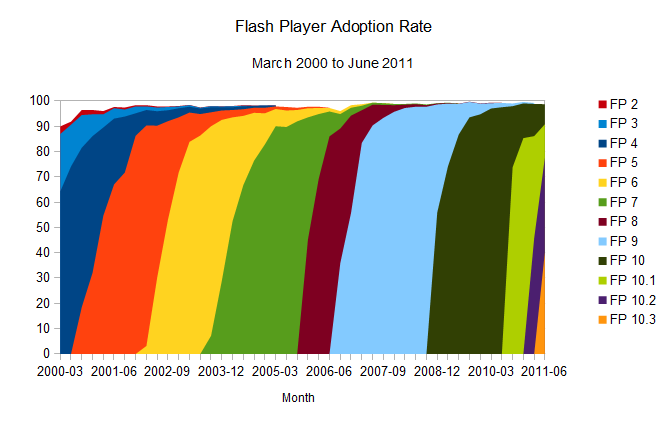
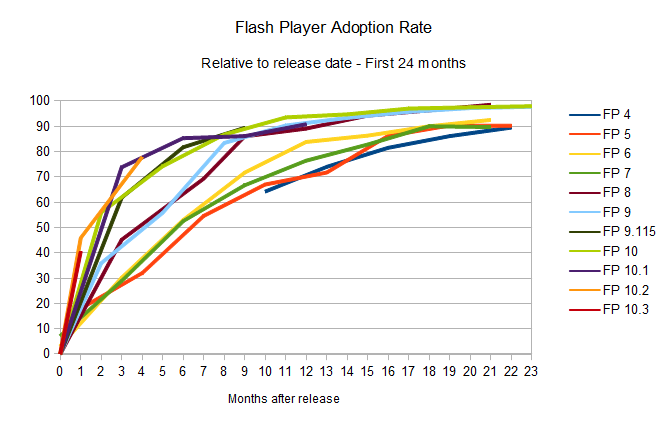
To
simplify it: give it around eight months, and 90 per cent of the
desktops out there will have the newest version of the plug-in
installed. And as the numbers represented in the charts above show, this
update rate is only improving. That’s party due to the fact that
Chrome, now a powerful force in the browser battles, installs new
versions of the Flash Player automatically (sometimes even before it is
formally released by Adobe), and that Firefox frequently detects the
user's version and insists on them installing an updated, more secure
version.
Gone are the days where the Flash platform needed an
event such as the Olympics or a major website like MySpace or YouTube
making use of a new version of Flash to make it propagate faster; this
now happens naturally. Version 10.3 only needed one month to get to a
40.5 per cent install base, and given the trends set by the previous
releases, it's likely that the plug-in's new version 11 will break new speed records.
Any technology that can allow developers and publishers to take advantage of it in a real world scenario
so fast has to be considered a breakthrough. Any new platform feature
can be proposed, developed, and made available with cross-platform
consistency in record time; such is the advantage of a proprietary
platform like Flash. To mention one of the more adequate examples of
the opposite effect, features added to the HTML platform (in any of its
flavours or versions) can take many years of proposal and beta support
until they're officially accepted, and when that happens, it takes many
more years until it becomes available on most of the computers out
there. A plug-in is usually easier and quicker to update than a browser
too.
That has been the story so far. But that's changing.
Advertisement
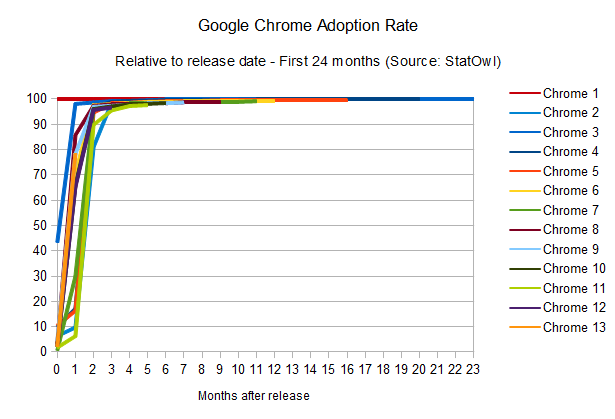
Google Chrome adoption rate
Looking
at the statistics for the adoption rate of the Flash plug-in, it's easy
to see it's accelerating constantly, meaning the last versions of the
player were finding their way to the user's desktops quicker and quicker
with every new version. But when you have a look at similar adoption
rate for browsers, a somewhat similar but more complex story unfolds.
Let's
have a look at Google Chrome's adoption rates in the same manner I've
done the Flash player comparisons, to see how many people had each of
its version installed (but notice that, given that Chrome is not used by
100 per cent of the people on the internet, it is normalised for the
comparison to make sense).
The striking thing here is that the adoption rate of Google Chrome manages to be faster than Flash Player itself [see StatOwl's web browser usage statistics, browser version release dates from Google Chrome on
Wikipedia]. This is helped, of course, by the fact that updates happens
automatically (without user approval necessary) and easily (using its smart diff-based update engine to
provide small update files). As a result, Chrome can get to the same 90
per cent of user penetration rate in around two months only; but what
it really means is that Google manages to put out updates to their HTML engine much faster than Flash Player.
Of
course, there's a catch here if we're to compare that to Flash Player
adoption rate: as mentioned, Google does the same auto-update for the
Flash Player itself. So the point is not that there's a race and
Chrome's HTML engine is leading it; instead, Chrome is changing the
rules of the game to not only make everybody win, but to make them win faster.
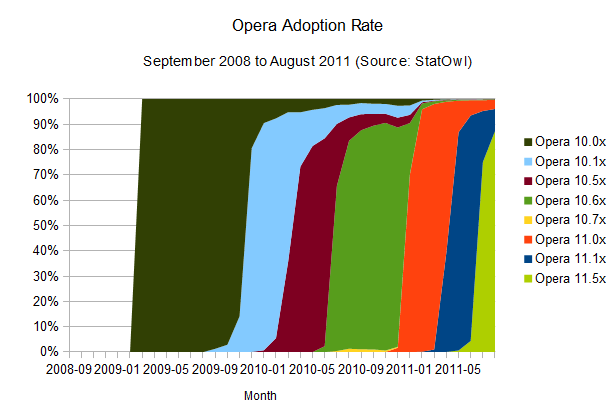
Opera adoption rate
The
fast update rate employed by Chrome is not news. In fact, one smaller
player on the browser front, Opera, tells a similar story.
Opera also manages to have updates reach a larger audience very quickly [see browser version release dates from History of the Opera web browser, Opera 10 and Opera 11
on Wikipedia]. This is probably due to its automatic update feature.
The mass updates seem to take a little bit longer than Chrome, around
three months for a 90 per cent reach, but it's important to notice that
its update workflow is not entirely automatic; last time I tested, it
still required user approval (and Admin rights) to work its magic.
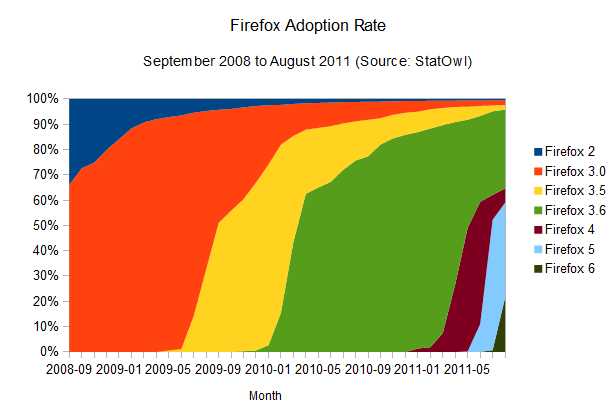
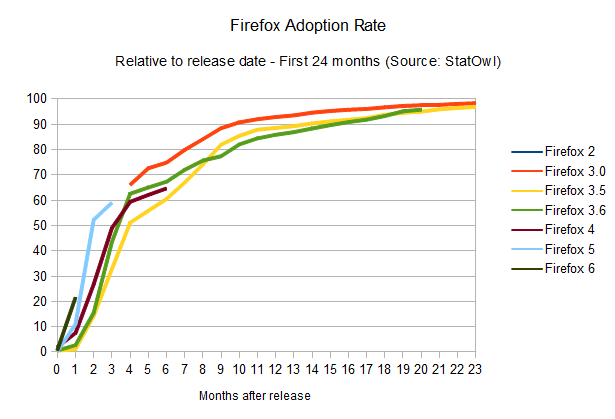
Firefox adoption rate
The
results of this browser update analysis start deviating when we take a
similar look at the adoption rates of the other browsers. Take Firefox,
for example:
It's also clear that Firefox's update rate is accelerating (browser version release dates from Firefox on
Wikipedia), and the time-to-90-per-cent is shrinking: it should take
around 12 months to get to that point. And given Mozilla's decision to
adopt release cycles that mimics Chrome's,
with its quick release schedule, and automatic updates, we're likely to
see a big boost in those numbers, potentially making the update
adoption rates as good as Chrome's.
One interesting point here is
that a few users seem to have been stuck with Firefox 3.6, which is the
last version that employs the old updating method (where the user has
to manually check for new versions), causing Firefox updates to spread
quickly but stall around the 60 per cent mark. Some users still need to
realise there's an update waiting for them; and similarly to the problem the Mozilla team had to face with Firefox 3.5, it's likely that we'll see the update being automatically imposed upon users soon, although they'll still be able to disable it. It's gonna be interesting to see how this develops over the next few months.
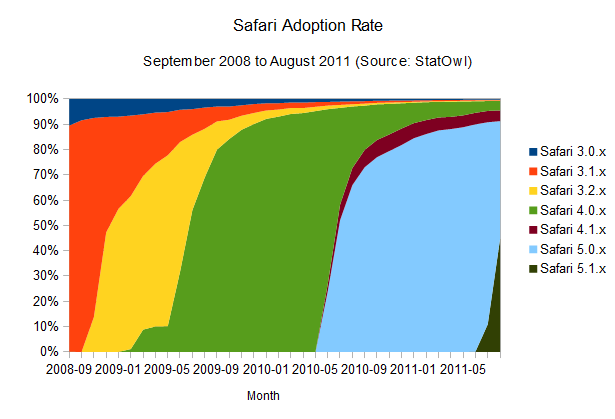
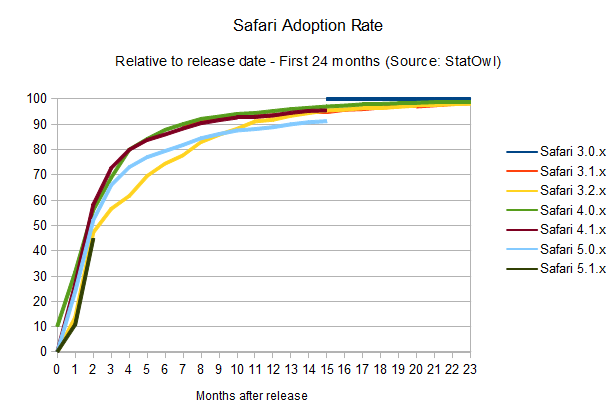
What does Apple's Safari look like?
Safari adoption rate
Right now, adoption rates seem on par with Firefox (browser version release dates from Safari on
Wikipedia), maybe a bit better, since it takes users around 10 months
to get a 90 per cent adoption rate of the newest versions of the
browser. The interesting thing is that this seems to happen in a pretty solid
fashion, probably helped by Apple's OS X frequent update schedule,
since the browser update is bundled with system updates. Overall, update
rates are not improving – but they're keeping at a good pace.
Notice
that the small bump on the above charts for Safari 4.0.x is due to the
public beta release of that version of the browser, and the odd area for
Safari 4.1.x is due to its release in pair with Safari 5.0.x, but for a
different version of OSX.
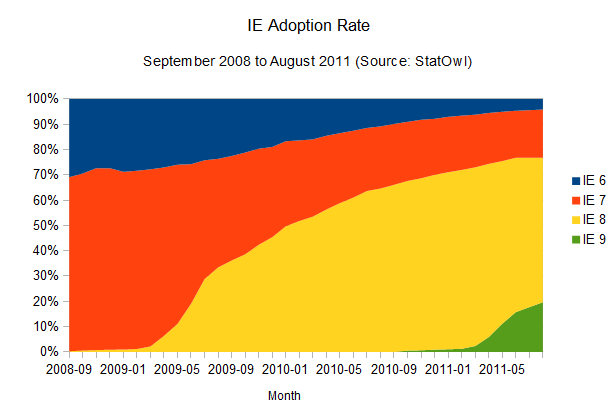
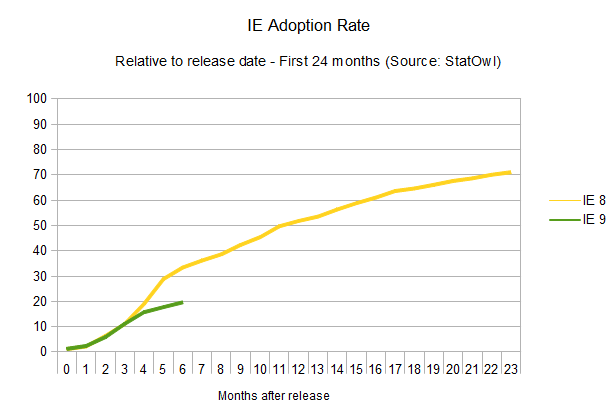
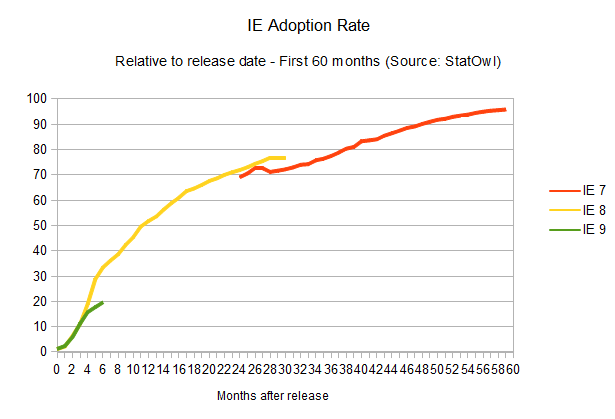
IE adoption rate
All in all it seems to me that browser vendors, as well as the users, are starting to get it. Overall, updates are happening faster and the cycle from interesting idea to a feature that can be used on a real-world scenario is getting shorter and shorter.
There's just one big asterisk in this prognosis: the adoption rate for the most popular browser out there.
The adoption rate of updates to Internet Explorer is not improving at all (browser version release dates from Internet Explorer on Wikipedia). In fact, it seems to be getting worse.
As
is historically known, the adoption rate of new versions of Internet
Explorer is, well, painstakingly slow. IE6, a browser that was released
10 years ago, is still used by four per cent of the IE users, and newer
versions don't fare much better. IE7, released five years ago, is still
used by 19 per cent of all the IE users. The renewing cycle here is so
slow that it's impossible to even try to guess how long it would take
for new versions to reach a 90 per cent adoption rate, given the lack of
reliable data. But considering update rates haven't improved at all for
new versions of the browser (in fact, IE9 is doing worse than IE8 in
terms of adoption), one can assume a cycle of four years until any released version of Internet Explorer reaches 90 per cent user adoption. Microsoft itself is trying to make users abandon IE6,
and whatever the reason for the version lag – system administrators
hung up on old versions, proliferation of pirated XP installations that
can't update – it's just not getting there.
And the adoption rates
of new HTML features is, unfortunately, only as quick as the adoption
rate of the slowest browser, especially when it's someone that still
powers such a large number of desktops out there.
Internet Explorer will probably continue to be the most popular browser for a very long time.
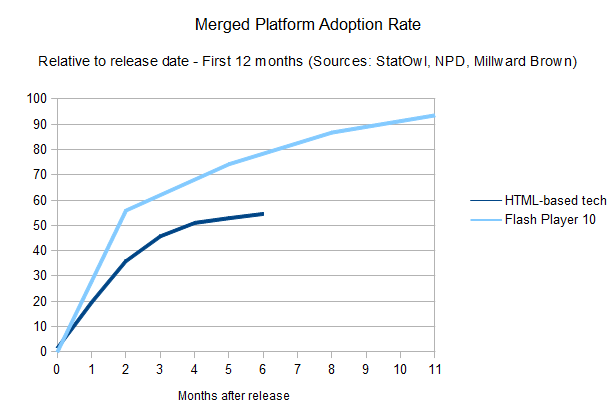
The long road for HTML-based tech
The
story, so far, has been that browser plug-ins are usually easier and
quicker to update. Developers can rely on new features of a proprietary
platform such as Flash earlier than someone who uses the native HTML
platform could. This is changing, however, one browser at a time.
A merged
chart, using the weighted distribution of each browser's penetration
and the time it takes for its users to update, tells that the overall
story for HTML developers still has a long way to go.
Of course, this shouldn't be taken into account blindly. You should always have your audience in mind when developing a website,
and come up with your own numbers when deciding what kind of features
to make use of. But it works as a general rule of thumb to be taken into
account before falling in love with whatever feature has just been
added to a browser's rendering engine (or a new plug-in version, for
that matter). In that sense, be sure to use websites like caniuse.com to
check on what's supported (check the “global user stats” box!), and
look at whatever browser share data you have for your audience (and
desktop/mobile share too, although it's out of the scope of this
article).
Conclusion
Updating the browser has always been a
certain roadblock to most users. In the past, even maintaining
bookmarks and preferences when doing an update was a problem.
That
has already changed. With the exception of Internet Explorer, browsers
vendors are realising how important it is to provide easy and timely
updates for users; similarly, users themselves are, I like to believe,
starting to realise how an update can be easy and painless too.
Personally,
I used to look at the penetration numbers of Flash and HTML in
comparison to each other and it always baffled me how anyone would
compare them in a realistic fashion when it came down to the speed that
any new feature would take to be adopted globally. Looking at them this
time, however, gave me a different view on things; our rich web
platforms are not only getting better, but they're getting better at
getting better, by doing so faster.
In retrospect, it
seems obvious now, but I can only see all other browser vendors adopting
similar quick-release, auto-update features similar to what was
introduced by Chrome. Safari probably needs to make the updates install
without user intervention, and we can only hope that Microsoft will
consider something similar for Internet Explorer. And when that happens,
the web, both HTML-based and plug-ins-based but especially on the HTML
side, will be moving at a pace that we haven't seen before. And
everybody wins with that.
Mozilla has faced some backlash from IT administrators for its move to a rapid release cycle with the Firefox browser,
but you have to hand it to Mozilla for staying the course. For years,
Firefox saw upgrades arrive far less frequently than they arrove for
competitive browsers such as Google Chrome. Since announcing its new
rapid release cycle earlier this year,
Mozilla has released versions 4 and 5 of Firefox, and steadily gotten
better at ironing out short-term kinks, most of which have had to do
with extensions causing problems. Now, Firefox 8 is already being seen
in nightly builds, although it's not released in final form yet, and
early reports show it to be faster than current versions of Chrome
across many benchmarks.
Firefox 7 and 8 run a new graphics engine called Azure, which you can read more about here. And, in broad benchmark tests, ExtremeTech reports the following results:
"Firefox
8, which only just appeared on the Nightly channel, is already 20%
faster than Firefox 5 in almost every metric: start up, session
restore, first paint, JavaScript execution, and even 2D canvas and 3D
WebGL rendering. The memory footprint of Firefox 7 (and thus 8) has
also been drastically reduced, along with much-needed improvements to garbage collection."
Mozilla has already done extensive work on
how memory is handled in Firefox 7, and these issues are likely to be
addressed further with release 8. At this point, Chrome is Firefox's
biggest competition, and ExtremeTech also reports:
"While
comparison with other browsers has become a little passe in recent
months — they’re all so damn similar! — it’s worth noting that Firefox 8
is as fast or faster than the latest Dev Channel build of Chrome 14.
Chrome’s WebGL implementation is still faster, but with Azure,
Firefox’s 2D performance is actually better than Chrome. JavaScript performance is also virtually identical."
I
use Firefox and Chrome, but my primary reason for using Chrome is that
it has been faster. With the early glimpse of Firefox 8, the performance
gap stands a chance of being closed, and it looks like these two open
source browsers have never competed more closely than they do now.











 Despite
the controversy of user control, Microsoft especially has a reason to
make this move to react to browser "update fatigue" that has resulted in
virtually "stale" IE users who won't upgrade their browsers unless they
upgrade their operating system as well.
Despite
the controversy of user control, Microsoft especially has a reason to
make this move to react to browser "update fatigue" that has resulted in
virtually "stale" IE users who won't upgrade their browsers unless they
upgrade their operating system as well. 







 Mozilla has faced some backlash from IT administrators for its move to a rapid release cycle with the Firefox browser,
but you have to hand it to Mozilla for staying the course. For years,
Firefox saw upgrades arrive far less frequently than they arrove for
competitive browsers such as Google Chrome. Since announcing its new
rapid release cycle earlier this year,
Mozilla has released versions 4 and 5 of Firefox, and steadily gotten
better at ironing out short-term kinks, most of which have had to do
with extensions causing problems. Now, Firefox 8 is already being seen
in nightly builds, although it's not released in final form yet, and
early reports show it to be faster than current versions of Chrome
across many benchmarks.
Mozilla has faced some backlash from IT administrators for its move to a rapid release cycle with the Firefox browser,
but you have to hand it to Mozilla for staying the course. For years,
Firefox saw upgrades arrive far less frequently than they arrove for
competitive browsers such as Google Chrome. Since announcing its new
rapid release cycle earlier this year,
Mozilla has released versions 4 and 5 of Firefox, and steadily gotten
better at ironing out short-term kinks, most of which have had to do
with extensions causing problems. Now, Firefox 8 is already being seen
in nightly builds, although it's not released in final form yet, and
early reports show it to be faster than current versions of Chrome
across many benchmarks.

{kind=link}
{kind=link}
{kind=link}