Monday, April 17. 2017
Google says its custom machine learning chips are often 15-30x faster than GPUs and CPUs
Via Tech Crunch
-----

It’s no secret that Google has developed its own custom chips to accelerate its machine learning algorithms. The company first revealed those chips, called Tensor Processing Units (TPUs), at its I/O developer conference back in May 2016, but it never went into all that many details about them, except for saying that they were optimized around the company’s own TensorFlow machine-learning framework. Today, for the first time, it’s sharing more details and benchmarks about the project.
If you’re a chip designer, you can find all the gory glorious details of how the TPU works in Google’s paper.
The numbers that matter most here, though, are that based on Google’s
own benchmarks (and it’s worth keeping in mind that this is Google
evaluating its own chip), the TPUs are on average 15x to 30x faster in
executing Google’s regular machine learning workloads than a standard
GPU/CPU combination (in this case, Intel Haswell processors and Nvidia
K80 GPUs). And because power consumption counts in a data center, the
TPUs also offer 30x to 80x higher TeraOps/Watt (and with using faster
memory in the future, those numbers will probably increase).
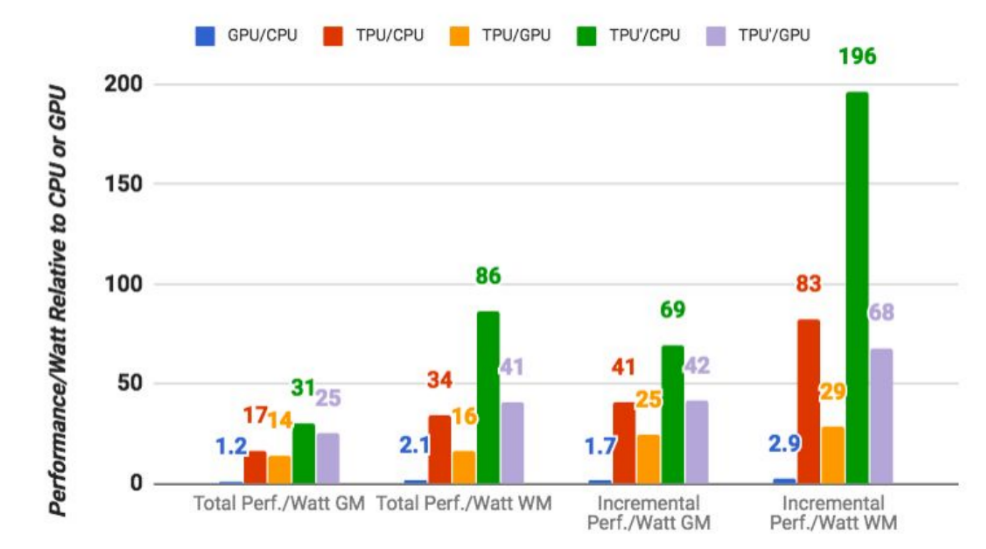
It’s worth noting that these numbers are about using machine learning models in production, by the way — not about creating the model in the first place.
Google also notes that while most architects optimize their chips for convolutional neural networks (a specific type of neural network that works well for image recognition, for example). Google, however, says, those networks only account for about 5 percent of its own data center workload while the majority of its applications use multi-layer perceptrons.
Google says it started looking into how it could use GPUs, FPGAs and custom ASICS (which is essentially what the TPUs are) in its data centers back in 2006. At the time, though, there weren’t all that many applications that could really benefit from this special hardware because most of the heavy workloads they required could just make use of the excess hardware that was already available in the data center anyway. “The conversation changed in 2013 when we projected that DNNs could become so popular that they might double computation demands on our data centers, which would be very expensive to satisfy with conventional CPUs,” the authors of Google’s paper write. “Thus, we started a high-priority project to quickly produce a custom ASIC for inference (and bought off-the-shelf GPUs for training).” The goal here, Google’s researchers say, “was to improve cost-performance by 10x over GPUs.”
Google isn’t likely to make the TPUs available outside of its own cloud, but the company notes that it expects that others will take what it has learned and “build successors that will raise the bar even higher.”
Quicksearch
Popular Entries
- The great Ars Android interface shootout (131524)
- Norton cyber crime study offers striking revenue loss statistics (102442)
- MeCam $49 flying camera concept follows you around, streams video to your phone (100540)
- The PC inside your phone: A guide to the system-on-a-chip (58715)
- Norton cyber crime study offers striking revenue loss statistics (58671)
Categories

Show tagged entries
Syndicate This Blog
Calendar
|
|
July '26 | |||||
| Mon | Tue | Wed | Thu | Fri | Sat | Sun |
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 | ||