Small cubes with no exterior moving parts can propel themselves forward,
jump on top of each other, and snap together to form arbitrary shapes.
A prototype of a new modular robot,
with its innards exposed and its
flywheel — which gives it the ability to move independently — pulled
out.
Photo: M. Scott Brauer
In 2011, when an MIT senior named John Romanishin proposed a new design
for modular robots to his robotics professor, Daniela Rus, she said,
“That can’t be done.”
Two years later, Rus showed her colleague
Hod Lipson, a robotics researcher at Cornell University, a video of
prototype robots, based on Romanishin’s design, in action. “That can’t
be done,” Lipson said.
In November, Romanishin — now a research
scientist in MIT’s Computer Science and Artificial Intelligence
Laboratory (CSAIL) — Rus, and postdoc Kyle Gilpin will establish once
and for all that it can be done, when they present a paper describing
their new robots at the IEEE/RSJ International Conference on Intelligent
Robots and Systems.
Known as M-Blocks, the robots are cubes with
no external moving parts. Nonetheless, they’re able to climb over and
around one another, leap through the air, roll across the ground, and
even move while suspended upside down from metallic surfaces.
Inside
each M-Block is a flywheel that can reach speeds of 20,000 revolutions
per minute; when the flywheel is braked, it imparts its angular momentum
to the cube. On each edge of an M-Block, and on every face, are
cleverly arranged permanent magnets that allow any two cubes to attach
to each other.
“It’s one of these things that the
[modular-robotics] community has been trying to do for a long time,”
says Rus, a professor of electrical engineering and computer science and
director of CSAIL. “We just needed a creative insight and somebody who
was passionate enough to keep coming at it — despite being discouraged.”
Embodied abstraction
As Rus explains,
researchers studying reconfigurable robots have long used an abstraction
called the sliding-cube model. In this model, if two cubes are face to
face, one of them can slide up the side of the other and, without
changing orientation, slide across its top.
The sliding-cube
model simplifies the development of self-assembly algorithms, but the
robots that implement them tend to be much more complex devices. Rus’
group, for instance, previously developed a modular robot called the Molecule,
which consisted of two cubes connected by an angled bar and had 18
separate motors. “We were quite proud of it at the time,” Rus says.
According
to Gilpin, existing modular-robot systems are also “statically stable,”
meaning that “you can pause the motion at any point, and they’ll stay
where they are.” What enabled the MIT researchers to drastically
simplify their robots’ design was giving up on the principle of static
stability.
“There’s a point in time when the cube is essentially
flying through the air,” Gilpin says. “And you are depending on the
magnets to bring it into alignment when it lands. That’s something
that’s totally unique to this system.”
That’s also what made Rus
skeptical about Romanishin’s initial proposal. “I asked him build a
prototype,” Rus says. “Then I said, ‘OK, maybe I was wrong.’”
Sticking the landing
To
compensate for its static instability, the researchers’ robot relies on
some ingenious engineering. On each edge of a cube are two cylindrical
magnets, mounted like rolling pins. When two cubes approach each other,
the magnets naturally rotate, so that north poles align with south, and
vice versa. Any face of any cube can thus attach to any face of any
other.
The cubes’ edges are also beveled, so when two cubes are
face to face, there’s a slight gap between their magnets. When one cube
begins to flip on top of another, the bevels, and thus the magnets,
touch. The connection between the cubes becomes much stronger, anchoring
the pivot. On each face of a cube are four more pairs of smaller
magnets, arranged symmetrically, which help snap a moving cube into
place when it lands on top of another.
As with any modular-robot
system, the hope is that the modules can be miniaturized: the ultimate
aim of most such research is hordes of swarming microbots that can
self-assemble, like the “liquid steel” androids in the movie “Terminator
II.” And the simplicity of the cubes’ design makes miniaturization
promising.
But the researchers believe that a more refined
version of their system could prove useful even at something like its
current scale. Armies of mobile cubes could temporarily repair bridges
or buildings during emergencies, or raise and reconfigure scaffolding
for building projects. They could assemble into different types of
furniture or heavy equipment as needed. And they could swarm into
environments hostile or inaccessible to humans, diagnose problems, and
reorganize themselves to provide solutions.
Strength in diversity
The
researchers also imagine that among the mobile cubes could be
special-purpose cubes, containing cameras, or lights, or battery packs,
or other equipment, which the mobile cubes could transport. “In the vast
majority of other modular systems, an individual module cannot move on
its own,” Gilpin says. “If you drop one of these along the way, or
something goes wrong, it can rejoin the group, no problem.”
“It’s
one of those things that you kick yourself for not thinking of,”
Cornell’s Lipson says. “It’s a low-tech solution to a problem that
people have been trying to solve with extraordinarily high-tech
approaches.”
“What they did that was very interesting is they
showed several modes of locomotion,” Lipson adds. “Not just one cube
flipping around, but multiple cubes working together, multiple cubes
moving other cubes — a lot of other modes of motion that really open the
door to many, many applications, much beyond what people usually
consider when they talk about self-assembly. They rarely think about
parts dragging other parts — this kind of cooperative group behavior.”
In
ongoing work, the MIT researchers are building an army of 100 cubes,
each of which can move in any direction, and designing algorithms to
guide them. “We want hundreds of cubes, scattered randomly across the
floor, to be able to identify each other, coalesce, and autonomously
transform into a chair, or a ladder, or a desk, on demand,” Romanishin
says.
Newly discovered mechanism could help researchers understand ageing process and lead to ways of slowing it down
Horvath looked at the
DNA of nearly 8,000 samples of 51 different healthy and cancerous cells
and tissues. Photograph: Zoonar GmbH/Alamy
A US scientist has discovered an internal body clock based on DNA that measures the biological age of our tissues and organs.
The
clock shows that while many healthy tissues age at the same rate as the
body as a whole, some of them age much faster or slower. The age of
diseased organs varied hugely, with some many tens of years "older" than
healthy tissue in the same person, according to the clock.
Researchers say that unravelling the mechanisms behind the clock will help them understand the ageing process and hopefully lead to drugs and other interventions that slow it down.
Therapies
that counteract natural ageing are attracting huge interest from
scientists because they target the single most important risk factor for
scores of incurable diseases that strike in old age.
"Ultimately, it would be very exciting to develop therapy interventions to reset the clock and hopefully keep us young," said Steve Horvath, professor of genetics and biostatistics at the University of California in Los Angeles.
Horvath
looked at the DNA of nearly 8,000 samples of 51 different healthy and
cancerous cells and tissues. Specifically, he looked at how methylation,
a natural process that chemically modifies DNA, varied with age.
Horvath
found that the methylation of 353 DNA markers varied consistently with
age and could be used as a biological clock. The clock ticked fastest in
the years up to around age 20, then slowed down to a steadier rate.
Whether the DNA changes cause ageing or are caused by ageing is an
unknown that scientists are now keen to work out.
"Does this
relate to something that keeps track of age, or is a consequence of age?
I really don't know," Horvath told the Guardian. "The development of
grey hair is a marker of ageing, but nobody would say it causes ageing,"
he said.
The clock has already revealed some intriguing results.
Tests on healthy heart tissue showed that its biological age – how worn
out it appears to be – was around nine years younger than expected.
Female breast tissue aged faster than the rest of the body, on average
appearing two years older.
Diseased tissues also aged at different rates, with cancers speeding up the clock by an average of 36 years. Some brain cancer tissues taken from children had a biological age of more than 80 years.
"Female
breast tissue, even healthy tissue, seems to be older than other
tissues of the human body. That's interesting in the light that breast
cancer is the most common cancer in women. Also, age is one of the
primary risk factors of cancer, so these types of results could explain
why cancer of the breast is so common," Horvath said.
Healthy
tissue surrounding a breast tumour was on average 12 years older than
the rest of the woman's body, the scientist's tests revealed.
Writing in the journal Genome Biology,
Horvath showed that the biological clock was reset to zero when cells
plucked from an adult were reprogrammed back to a stem-cell-like state.
The process for converting adult cells into stem cells, which can grow
into any tissue in the body, won the Nobel prize in 2012 for Sir John Gurdon at Cambridge University and Shinya Yamanaka at Kyoto University.
"It
provides a proof of concept that one can reset the clock," said
Horvath. The scientist now wants to run tests to see how
neurodegenerative and infectious diseases affect, or are affected by,
the biological clock.
"These data could prove valuable in
furthering our knowledge of the biological changes that are linked to
the ageing process," said Veryan Codd, who works on the effects of
biological ageing in cardiovascular disease at Leicester University. "It
will be important to determine whether the accelerated ageing, as
described here, is associated with other age-related diseases and if it
is a causal factor in, or a consequence of, disease development.
"As
more data becomes available, it will also be interesting to see whether
a similar approach could identify tissue-specific ageing signatures,
which could also prove important in disease mechanisms," she added.
Researchers at the MIT Media Lab and the Max Planck Institutes
have created a foldable, cuttable multi-touch sensor that works no
matter how you cut it, allowing multi-touch input on nearly any surface.
In traditional sensors the connectors are laid out in a grid and when
one part of the grid is damaged you lose sensitivity in a wide swathe
of other sensors. This system lays the sensors out like a star which
means that cut parts of the sensor only effect other parts down the
line. For example, you cut the corners off of a square and still get the
sensor to work or even cut all the way down to the main, central
connector array and, as long as there are still sensors on the surface,
it will pick up input.
The team that created it, Simon Olberding, Nan-Wei Gong, John Tiab, Joseph A. Paradiso, and Jürgen Steimle, write:
This very direct manipulation allows the end-user to easily make real-world objects and surfaces touch interactive,
to augment physical prototypes and to enhance paper craft. We contribute
a set of technical principles for the design of printable circuitry
that makes the sensor more robust against cuts, damages and removed
areas. This includes
novel physical topologies and printed forward error correction.
You can read the research paper here
but this looks to be very useful in the DIY hacker space as well as for
flexible, wearable projects that require some sort of multi-touch
input. While I can’t imagine we need shirts made of this stuff, I could
see a sleeve with lots of inputs or, say, a watch with a multi-touch
band.
Don’t expect this to hit the next iWatch any time soon – it’s still
very much in prototype stages but definitely looks quite cool.
Is liquid fuel the key to zettascale computing? Dr Patrick Ruch with IBM's test kit
IBM has unveiled a prototype of a new brain-inspired computer powered by what it calls "electronic blood".
The firm says it is learning from nature by building computers fuelled and cooled by a liquid, like our minds.
The human brain packs phenomenal computing power into a tiny
space and uses only 20 watts of energy - an efficiency IBM is keen to
match.
Its new "redox flow" system pumps an electrolyte "blood" through a computer, carrying power in and taking heat out.
A very basic model was demonstrated this week at the technology giant's Zurich lab by Dr Patrick Ruch and Dr Bruno Michel.
Their vision is that by 2060, a one petaflop computer that would fill half a football field today, will fit on your desktop.
"We want to fit a supercomputer inside a sugarcube. To do
that, we need a paradigm shift in electronics - we need to be motivated
by our brain," says Michel.
"The human brain is 10,000 times more dense and efficient than any computer today.
"That's possible because it uses only one - extremely
efficient - network of capillaries and blood vessels to transport heat
and energy - all at the same time."
The victory was hailed as a landmark for cognitive computing - machine had surpassed man.
The future of computing? IBM's model uses a liquid to deliver power and remove heat
But the contest was unfair, says Michel. The brains of Ken
Jennings and Brad Rutter ran on only 20 watts of energy, whereas Watson
needed 85,000 watts.
Energy efficiency - not raw computing power - is the guiding principle for the next generation of computer chips, IBM believes.
Our current 2D silicon chips, which for half a century have doubled in power through Moore's Law, are approaching a physical limit where they cannot shrink further without overheating.
Bionic vision
"The computer industry uses $30bn of energy and throws it out of the window. We're creating hot air for $30bn," says Michel.
"Ninety-nine per cent of a computer's volume is devoted to
cooling and powering. Only 1% is used to process information. And we
think we've built a good computer?"
"The brain uses 40% of its volume for functional performance - and only 10% for energy and cooling."
Michel's vision is for a new "bionic" computing architecture,
inspired by one of the laws of nature - allometric scaling - where an
animal's metabolic power increases with its body size.
An elephant, for example, weighs as much as a million mice.
But it consumes 30 times less energy, and can perform a task even a
million mice cannot accomplish.
The same principle holds true in computing, says Michel, whose bionic vision has three core design features.
The first is 3D architecture, with chips stacked high, and memory storage units interwoven with processors.
"It's the difference between a low-rise building, where
everything is spread out flat, and a high rise building. You shorten the
connection distances," says Matthias Kaiserswerth, director of IBM
Zurich.
But there is a very good reason today's chips are gridiron
pancakes - exposure to the air is critical to dissipate the intense heat
generated by ever-smaller transistors.
Piling chips on top of one another locks this heat inside - a major roadblock to 3D computing.
IBM's solution is integrated liquid cooling - where chips are interlayered with tiny water pipes.
The art of liquid cooling has been demonstrated by Aquasar and put to work inside the German supercomputer SuperMUC which - perversely - harnesses warm water to cool its circuits.
SuperMUC consumes 40% less electricity as a result.
Liquid engineering
But for IBM to truly match the marvels of the brain, there is a
third evolutionary step it must achieve - simultaneous liquid fuelling
and cooling.
Just as blood gives sugar in one hand and takes heat with another, IBM is looking for a fluid that can multitask.
Vanadium is the best performer in their current laboratory
test system - a type of redox flow unit - similar to a simple battery.
First a liquid - the electrolyte - is charged via electrodes,
then pumped into the computer, where it discharges energy to the chip.
SuperMUC uses liquid cooling instead of air - a model for future computer designs
Redox flow is far from a new technology, and neither is it especially complex.
But IBM is the first to stake its chips on this "electronic
blood" as the food of future computers - and will attempt to optimise it
over the coming decades to achieve zettascale computing.
"To power a zettascale computer today would take more electricity than is produced in the entire world," says Michel.
He is confident that the design hurdles in his bionic model
can be surmounted - not least that a whole additional unit is needed to
charge the liquid.
And while other labs are betting on spintronics, quantum computing, or photonics to take us beyond silicon, the Zurich team believes the real answer lies right behind our eyes.
"Just as computers help us understand our brains, if we
understand our brains we'll make better computers," says director
Matthias Kaiserswerth.
He would like to see a future Watson win Jeopardy on a level playing field.
A redox flow test system - the different coloured liquids have different oxidation states
Other experts in computing agree that IBM's 3D principles are sound.
But as to whether bionic computing will be the breakthrough technology,
the jury is out.
"The idea of using a fluid to both power and cool strikes me
as very novel engineering - killing two birds with one stone," says Prof
Alan Woodward, of the University of Surrey's computing department.
"But every form of future computing has its champions -
whether it be quantum computing, DNA computing or neuromorphic
computing.
"There is a long way to go from the lab to having one of these sitting under your desk."
Prof Steve Furber, leader of the SpiNNaker project agrees that "going into the third dimension" has more to offer than continually shrinking transistors.
"The big issue with 3D computing is getting the heat out -
and liquid cooling could be very effective if integrated into 3D systems
as proposed here," he told the BBC.
"But all of the above will not get electronics down to the energy-efficiency of the brain.
"That will require many more changes, including a move to analogue computation instead of digital.
"It will also involve breakthroughs in new non-Turing models
of computation, for example based on an understanding of how the brain
processes information."
Current wireless networks have a problem: The more popular they become, the slower they are. Researchers at Fudan University in Shanghai have just become the latest to demonstrate
a technology that transmits data as light instead of radio waves, which
gets around the congestion issue and could be ten times faster than
traditional Wi-Fi.
In
dense urban areas, the range within which Wi-Fi signals are transmitted
is increasingly crowded with noise—mostly, other Wi-Fi signals. What’s
more, the physics of electromagnetic waves sets an upper limit to the
bandwidth of traditional Wi-Fi. The short version: you can only transmit
so much data at a given frequency. The lower the frequency of the wave,
the less it can transmit.
Li-Fi doesn’t work in the dark or outdoors, but it only has to be a supplement to existing wireless networks to be valuable.AP Photo/Kin Cheung
But
what if you could transmit data using waves of much higher frequencies,
and without needing a spectrum license from your country’s telecoms
regulator? Light, like radio, is an electromagnetic wave, but it has
about 100,000 times the frequency of a Wi-Fi signal, and nobody needs a
license to make a light bulb. All you need is a way to make its
brightness flicker very rapidly and accurately so it can carry a signal.
First,
data are transmitted to an LED light bulb—it could be the one
illuminating the room in which you’re sitting now. Then the lightbulb is
flicked on and off very quickly, up to billions of times per second.
That flicker is so fast that the human eye cannot perceive it. (For
comparison, the average energy-saving compact fluorescent bulb already flickers between 10,000 and 40,000 times per second.)
Then a receiver on a computer or mobile device—basically, a little
camera that can see visible light—decodes that flickering into data. LED
bulbs can be flicked on and off quickly enough to transmit data around
ten times as fast the fastest Wi-Fi networks. (If they could be
manipulated faster, the bandwidth would be even higher.)
If you’ve ever used a solar-powered calculator, you already know how to connect to Li-Fi.Oledcomm
Li-Fi
has one big drawback compared to Wi-Fi: you, or rather your device,
need to be within sight of the bulb. It wouldn’t necessarily need to be a
special bulb; in principle, overhead lights at work or at home could be
wired to the internet. But it would mean that, unlike with Wi-Fi, you
couldn’t go into the next room unless there were wired bulbs there too.
However, a new generation of ultrafast Wi-Fi devices that we’re likely to start using soon
face a similar limitation. They use a higher range of radio
frequencies, which aren’t as crowded with other signals (at least for
now), and have a higher bandwidth, but, like visible light, cannot
penetrate walls.
Engineers and a handful of startups, like Oledcomm, have been experimenting with Li-Fi technology.
The Fudan University team unveiled an experimental Li-Fi network in
which four PCs were all connected to the same light bulb. Other
researchers are working on transmitting data via different colors of LED
lights—imagine, for example, transmitting different signals through
each of the the red, green and blue LEDs inside a multi-colored LED
light bulb.
Because
of its limitations, Li-Fi won’t do away with other wireless networks.
But it could supplement them in congested areas, and replace them in places where radio signals need to be kept to a minimum, like hospitals, or where they don’t work, such as underwater.
Google puts a lot of work into creating a virtual map of the world with Street View, sending cars and backpackers everywhere with huge cameras. But what if a computer program could do all that automatically? Well, there's one that can. All it needs is Wikipedia and Google Images.
Developed by Bryan Russell at
Intel Labs and some colleagues at the University of Washington in
Seattle, the program is almost deceptively simple. First, it trawls the
internet (mainly Flickr) for a wide variety of pictures of a location.
By looking at them from different angles, it's able to piece together a
pretty good idea of what it looks like in 3D space from the outside.
Like this:
Then, for
the interior of that 3D shell, the program cruises through Wikipedia,
making note of every single noun-phrase, since its dumb robot brain
can't tell what is important and what is not. Finally, it searches
Google Images for its big stack of phrases, pulls the relevant pictures
(if it can find any), and plasters them roughly where they belong in the
model's interior. When that's all said and done, it can then behave as a
procedurally generated 3D tour that guides you through a recreation of
whatever you're reading about on Wikipedia. Awesome!
It's a
crazy idea, but it seems to work pretty well for popular landmarks, at
least. The operating logic here is that if a thing is important, there
will be pictures of it on the internet, and text describing the
pictures. So long as that's true, it's possible to start piecing things
together.
For the moment, the program has only compiled complete
virtual representations of exceedingly popular and well-documented
sites like the Sistine Chapel. With less common places, there's less
data to pull. But with the advent of tech like Google Glass, and the
wide proliferation of smartphones that can take a half-decent picture,
the data-voids are slowly getting filled in—and they'll only fill in
faster as time goes on.
So if you ever needed a great reason to keep all your vacation pictures public and publicly indexed, here it is. [Bryan C. Russell via New Scientist]
Sina Weibo, launched in 2010, has more than 500 million registered users with 100 million messages posted daily
More than two million
people in China are employed by the government to monitor web activity,
state media say, providing a rare glimpse into how the state tries to
control the internet.
The Beijing News says the monitors, described as internet opinion analysts, are on state and commercial payrolls.
China's hundreds of millions of web users increasingly use microblogs to criticise the state or vent anger.
Recent research suggested Chinese censors actively target social media.
The report by the Beijing News said that these monitors were not required to delete postings.
They are "strictly to gather and analyse
public opinions on microblog sites and compile reports for
decision-makers", it said. It also added details about how some of these
monitors work.
Tang Xiaotao has been working as a monitor for less than six months, the report says, without revealing where he works.
"He sits in front of a PC every day, and opening up an application, he types in key words which are specified by clients.
"He then monitors negative opinions related to the clients,
and gathers (them) and compile reports and send them to the clients," it
says.
The reports says the software used in the office is even more
advanced and supported by thousands of servers. It also monitors
websites outside China.
China rarely reveals any details concerning the scale and sophistication of its internet police force.
It is believed that the two million internet monitors are
part of a huge army which the government relies on to control the
internet.
The government is also to organise training classes for them for the first time from 14 to 18 October, the paper says.
But it is not clear whether the training will be for existing monitors or for new recruits.
The training will have eight modules, and teach participants
how to analyse and judge online postings and deal with crisis
situations, it says.
The most popular microblogging site Sina Weibo, launched in
2010, now has more than 500 million registered users with 100 million
messages posted daily.
Topics cover a wide range - from personal hobbies, health to
celebrity gossip and food safety but they talso include politically
sensitive issues like official corruption.
Postings deemed to be politically incorrect are routinely deleted.
Hollywood likes to paint movie pirates as freeloaders without morals,
but maybe those so-called dastardly downloaders are simply under-served.
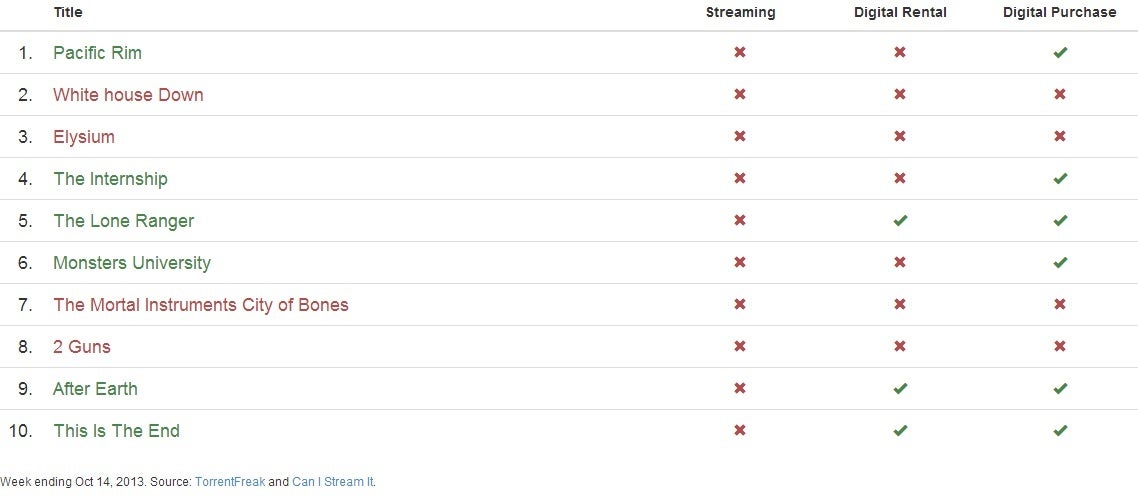
A new website called PiracyData.org tracks the most pirated movies of the week, as reported by TorrentFreak, and taps into Can I Stream It? to show whether file sharers could have bought or rented the movie online instead.
As PiracyData's chart below shows, four out of the 10 most pirated
movies cannot be purchased legally online. Out of the remaining six
movies, three are available for full-priced purchase, but not for rent.
None of the top 10 movies can be watched through subscription streaming
services such as Netflix.
(Click to enlarge.)
On its face, it looks like a missed opportunity for the movie industry.
Viewers may feel pushed toward piracy when they can't purchase or at
least rent the movies they want to watch.
But it's also worth noting the release timing of these movies. Every
single movie on the list came out this year, but is no longer showing in
major theaters. With the exception of three films, most of these movies
are now in an awkward stage where you can buy them on DVD, but cannot
rent them online.
DVD sales are plummeting.
People are growing accustomed to pressing a button and streaming a
movie instantly. The idea of withholding new movies from digital rental
just to juice DVD sales looks increasingly antiquated as people move
beyond the optical disc. For disposable films that people only want to
watch once, a mandatory $15 or $20 purchase is undesirable as well.
Of course, there are exceptions. People do have rental options for The Lone Ranger, After Earth, and This is the End,
yet they remain popular to download on BitTorrent. Unscrupulous
freeloaders do exist, and are not going away. But when the only legal
options are DVD or mandatory purchase, it's no surprise that potential
paying customers will turn to piracy instead.
The world of Big Data is one of pervasive data collection and
aggressive analytics. Some see the future and cheer it on; others rebel.
Behind it all lurks a question most of us are asking — does it really
matter? I had a chance to find out recently, as I got to see what
Acxiom, a large-scale commercial data aggregator, had collected about
me.
At least in theory large-scale data collection matters quite a bit. Large data sets can be used to create social network maps
and can form the seeds for link analysis of connections between
individuals. Some see this as a good thing; others as a bad one — but
whatever your viewpoint, we live in a world which sees increasing power
and utility in Big Data’s large-scale data sets.
Of course, much of the concern is about government collection. But
it’s difficult to assess just how useful this sort of data collection by
the government is because, of course, most governmental data collection
projects are classified. The good news, however, is that we can begin
to test the utility of the program in the private sector arena. A useful
analog in the private sector just became publicly available and it’s
both moderately amusing and instructive to use it as a lens for thinking
about Big Data.
Acxiom is one of the
largest commercial, private sector data aggregators around. It collects
and sells large data sets about consumers — sometimes even to the
government. And for years it did so quietly, behind the scene — as one
writer put it “mapping the consumer genome.” Some saw this as rather ominous; others as just curious. But it was, for all of us, mysterious. Until now.
In September, the data giant made available to the public a portion of its data set. They created a new website — Abouthedata.com
— where a consumer could go to see what data the company had collected
about them. Of course, in order to access the data about yourself you
had to first verify your own identity (I had to send in a photocopy of
my driver’s license), but once you had done so, it would be possible to
see, in broad terms, what the company thought it knew about you — and
how close that knowledge was to reality.
I was curious, so I thought I would go explore myself and see what it
was they knew and how accurate they were. The results were at times
interesting, illuminating and mundane. Here are a few observations:
To begin with, the fundamental purpose of the data collection is to
sell me things — that’s what potential sellers want to know about
potential buyers and what, say, Amazon might want to know about me. So I
first went and looked at a category called “Household Purchase Data” —
in other words what I had recently bought.
It turns out that I buy … well … everything. I buy food, beverages,
art, computing equipment, magazines, men’s clothing, stationary, health
products, electronic products, sports and leisure products, and so
forth. In other words, my purchasing habits were, to Acxiom, just an
undifferentiated mass. Save for the notation that I had bought an
antique in the past and that I have purchased “High Ticket Merchandise,”
it seems that almost everything I bought was something that most any
moderately well-to-do consumer would buy.
I do suppose that the wide variety of purchases I made is, itself,
the point — by purchasing so widely I self-identify as a “good”
consumer. But if that’s the point then the data set seems to miss the
mark on “how good” I really am. Under the category of “total dollars
spent,” for example, it said that I had spent just $1,898 in the past
two years. Without disclosing too much about my spending habits in this
public forum, I think it is fair to say that this is a significant
underestimate of my purchasing activity.
The next data category of “Household Interests” was equally
unilluminating. Acxiom correctly said I was interested in computers,
arts, cooking, reading and the like. It noted that I was interested in
children’s items (for my grandkids) and beauty items and gardening (both
my wife’s interest, probably confused with mine). Here, as well, there
was little differentiation, and I assume the breadth of my interests is
what matters rather that the details. So, as a consumer, examining what
was collected about me seemed to disclose only a fairly anodyne level of
detail.
[Though I must object to the suggestion that I am an Apple user J.
Anyone who knows me knows I prefer the Windows OS. I assume this was
also the result of confusion within the household and a reflection of my
wife’s Apple use. As an aside, I was invited throughout to correct any
data that was in error. This I chose not to do, as I did not want to
validate data for Acxiom – that’s their job not mine—and I had no real
interest in enhancing their ability to sell me to other marketers. On
the other hand I also did not take the opportunity they offered to
completely opt-out of their data system, on the theory that a moderate
amount of data in the world about me may actually lead to being offered
some things I want to purchase.]
Things became a bit more intrusive (and interesting) when I started
to look at my “Characteristic Data” — that is data about who I am. Some
of the mistakes were a bit laughable — they pegged me as of German
ethnicity (because of my last name, naturally) when, with all due
respect to my many German friends, that isn’t something I’d ever say
about myself. And they got my birthday wrong — lord knows why.
But some of their insights were at least moderately invasive of my
privacy, and highly accurate. Acxiom “inferred” for example, that I’m
married. They identified me accurately as a Republican (but notably not
necessarily based on voter registration — instead it was the party I was
“associated with by voter registration or as a supporter”). They knew
there were no children in my household (all grown up) and that I run a
small business and frequently work from home. And they knew which sorts
of charities we supported (from surveys, online registrations and
purchasing activity). Pretty accurate, I’d say.
Finally, it was completely unsurprising that the most accurate data
about me was closely related to the most easily measurable and widely
reported aspect of my life (at least in the digital world) — namely, my
willingness to dive into the digital financial marketplace.
Acxiom knew that I had several credit cards and used them regularly.
Acxiom knew that I had several credit cards and used them regularly. It had a broadly accurate understanding of my household total income range [I’m not saying!].
They also knew all about my house — which makes sense since real
estate and liens are all matters of public record. They knew I was a
home owner and what the assessed value was. The data showed, accurately,
that I had a single family dwelling and that I’d lived there longer
than 14 years. It disclosed how old my house was (though with the rather
imprecise range of having been built between 1900 and 1940). And, of
course, they knew what my mortgage was, and thus had a good estimate of
the equity I had in my home.
So what did I learn from this exercise?
In some ways, very little. Nothing in the database surprised me, and
the level of detail was only somewhat discomfiting. Indeed, I was more
struck by how uninformative the database was than how detailed it was —
what, after all, does anyone learn by knowing that I like to read?
Perhaps Amazon will push me book ads, but they already know I like to
read because I buy directly from them. If they had asserted that I like
science fiction novels or romantic comedy movies, that level of detail
might have demonstrated a deeper grasp of who I am — but that I read at
all seems pretty trivial information about me.
I do, of course, understand that Acxiom has not completely lifted the
curtains on its data holdings. All we see at About The Data is summary
information. You don’t get to look at the underlying data elements. But
even so, if that’s the best they can do ….
In fact, what struck me most forcefully was (to borrow a phrase from
Hannah Arendt) the banality of it all. Some, like me, see great promise
in big data analytics as a way of identifying terrorists or tracking
disease. Others, with greater privacy concerns, look at big data and see
Big Brother. But when I dove into one big data set (albeit only
partially), held by one of the largest data aggregators in the world,
all I really became was a bit bored.
Maybe that’s what they wanted as a way of reassuring me. If so, Acxiom succeeded, in spades.
Qualcomm
is readying a new kind of artificial brain chip, dubbed neural
processing units (NPUs), modeling human cognition and opening the door
to phones, computers, and robots that could be taught in the same ways
that children learn. The first NPUs are likely to go into production by
2014, CTO Matt Grob confirmed at the MIT Technology Review
EmTech conference, with Qualcomm in talks with companies about using
the specialist chips for artificial vision, more efficient and
contextually-aware smartphones and tablets, and even potentially brain
implants.
According to Grob, the advantage of NPUs over traditional chips like
Qualcomm’s own Snapdragon range will be in how they can be programmed.
Instead of explicitly instructing the chips in how processing should
take place, developers would be able to teach the chips by example.
“This ‘neuromorphic’ hardware
is biologically inspired – a completely different architecture – and
can solve a very different class of problems that conventional
architecture is not good at,” Grob explained of the NPUs. “It really
uses physical structures derived from real neurons – parallel and
distributed.”
As a result, “this is a kind of machine that can learn, and be
programmed without software – be programmed the way you teach your kid”
Grob predicted.
In fact, Qualcomm already has a learning machine in its labs that uses the same sort of biologically-inspired programming system
that the NPUs will enable. A simple wheeled robot, it’s capable of
rediscovering a goal location after being told just once that it’s
reached the right point.
However it’s not only robots that can learn which will benefit
from the NPUs, Qualcomm says. “We want to make it easier for
researchers to make a part of the brain” Grob said, bringing abilities
like classification and prediction to a new generation of electronics.
That might mean computers
that are better able to filter large quantities of data to suit the
particular needs of the user at any one time, smartphone assistants like
Google Now with supercharged contextual intuition, and autonomous cars
that can dynamically recognize and understand potential perils in the
road ahead.
The first partnerships actually implementing NPUs in that way are
likely to come in 2014, Grob confirmed, with Qualcomm envisaging hugely
parallel arrays of the chips being put into practice to model how humans
might handle complex problems.












 In fact, Qualcomm already has a learning machine in its labs that uses the same sort of biologically-inspired programming
In fact, Qualcomm already has a learning machine in its labs that uses the same sort of biologically-inspired programming 