Tuesday, November 24. 2015
Via The Daily Dot
-----
People with Android devices might be a bit frustrated with Google after a report
from the New York District Attorney's office provided detailed
information about smartphone security, and Google's power to access
devices when asked to by law enforcement. The report went viral on Reddit over the weekend.
Google can unlock many Android phones remotely when given a search
warrant, bypassing lock codes on particular devices. The report reads:
Forensic
examiners are able to bypass passcodes on some of those [Android]
devices using a variety of forensic techniques. For some other types of
Android devices, Google can reset the passcodes when served with a
search warrant and an order instructing them to assist law enforcement
to extract data from the device. This process can be done by Google
remotely and allows forensic examiners to view the contents of a device.
When compared to Apple devices, which encrypt by default on iOS 8 and
later, Google's seemingly lax protection is irksome. The report
continues:
For Android devices running operating
systems Lollipop 5.0 and above, however, Google plans to use default
full-disk encryption, like that being used by Apple, that will make it
impossible for Google to comply with search warrants and orders
instructing them to assist with device data extraction. Generally, users
have the option to enable full-disk encryption on their current Android
devices, whether or not the device is running Lollipop 5.0, but doing
so causes certain inconveniences, risks, and performance issues, which
are likely to exist until OEMs are required to standardize certain
features.
In October, Google announced
that new devices that ship with the Marshmallow 6.0 operating system
(the most recent version of Android) must enable full-disk encryption by
default. Nexus devices running Lollipop 5.0 are encrypted by default as
well. This means that Google is unable to bypass lock codes on those
devices. However, because of the massive fragmentation of Android
devices and operating systems, Google can still access lots of Android
devices running older versions when asked to by law enforcement.
And
despite the encryption updates to the Android compatibility
documentation, a number of devices are exempt from full-disk encryption,
including older devices, devices without a lock screen, and those that
don't meet the minimum security requirements.
The number of
devices that actually have full-disk encryption appears to be low. Just
0.3 percent of Android devices are running Marshmallow and more than 25
percent of Android devices are running Lollipop 5.0, but most of those
aren't Nexus, according to ZDNet.
When
compared to Apple, Google's security appears lacking. Apple made
encryption mandatory in iOS 8 back in 2014, which of course extends to
iOS 9, its most recent mobile OS update. Data shows
that 67 percent of Apple users are on iOS 9, and 24 percent of devices
are still on iOS 8. Just nine percent of devices run an older version of
iOS.
Android users are often at the mercy of carriers who decide
when to roll out Android updates, which is an obstacle for some Android
owners who want the latest OS.
If you do have a compatible
device and want to enable encryption, head over to your security
settings and select "encrypt device."
Tuesday, October 06. 2015

"A Blind Legend" is a game developped by Dowino based on binaural audio technology... only.
Binaural audio consists in recording audio sounds in the exact same way as humans are naturally perceiving it. Listening to binaural audio may only be performed by the use of a headset, making the resulting experience hyper-realistic. Many more details may be found on the binaural recording wikipedia page.
"A Blind Legend" game was crowd-funded and is now available for free on Google Play and the App Store.
Wednesday, September 09. 2015
Via IFLScience
-----

We invariably imagine electronic devices to be made from silicon
chips, with which computers store and process information as binary
digits (zeros and ones) represented by tiny electrical charges. But it
need not be this way: among the alternatives to silicon are organic
mediums such as DNA.
DNA computing was first demonstrated in 1994 by Leonard Adleman who encoded and solved the travelling salesman problem, a maths problem to find the most efficient route for a salesman to take between hypothetical cities, entirely in DNA.
Deoxyribonucleaic acid, DNA, can store vast amounts of information
encoded as sequences of the molecules, known as nucleotides, cytosine
(C), guanine (G), adenine (A), or thymine (T). The complexity and
enormous variance of different species’ genetic codes demonstrates how
much information can be stored within DNA encoded using CGAT, and this
capacity can be put to use in computing. DNA molecules can be used to
process information, using a bonding process between DNA pairs known as
hybridisation. This takes single strands of DNA as input and produces
subsequent strands of DNA through transformation as output.
Since Adleman’s experiment, many DNA-based “circuits” have been proposed that implement computational methods such as Boolean logic, arithmetical formulas, and neural network computation. Called molecular programming, this approach applies concepts and designs customary to computing to nano-scale approaches appropriate for working with DNA.

It’s circuitry, but not as we know it. Caltech/Lulu Qian, CC BY
In this sense “programming” is really biochemistry. The “programs”
created are in fact methods of selecting molecules that interact in a
way that achieves a specific result through the process of DNA
self-assembly, where disordered collections of molecules will
spontaneously interact to form the desired arrangement of strands of
DNA.
DNA ‘Robots’
DNA can also be used to control motion, allowing for DNA-based nano-mechanical devices. This was first achieved by Bernard Yurke and colleagues in 2000, who created from DNA strands a pair of tweezers that opened and pinched. Later experiments such as by Shelley Wickham and colleagues in 2011 and at Andrew Turberfield’s lab at Oxford demonstrated nano-molecular walking machines made entirely from DNA that could traverse set routes.
One possible application is that such a nano-robot DNA walker could
progress along tracks making decisions and signal when reaching the end
of the track, indicating computation has finished. Just as electronic
circuits are printed onto circuit boards, DNA molecules could be used to
print similar tracks arranged into logical decision trees on a DNA
tile, with enzymes used to control the decision branching along the
tree, causing the walker to take one track or another.
DNA walkers can also carry molecular cargo, and so could be used to deliver drugs inside the body.
Why DNA Computing?
DNA molecules’ many appealing features include their size (2nm
width), programmability and high storage capacity – much greater than
their silicon counterparts. DNA is also versatile, cheap and easy to
synthesise, and computing with DNA requires much less energy than
electric powered silicon processors.
Its drawback is speed: it currently takes several hours to compute
the square root of a four digit number, something that a traditional
computer could compute in a hundredth of a second. Another drawback is
that DNA circuits are single-use, and need to be recreated to run the
same computation again.
Perhaps the greatest advantage of DNA over electronic circuits is
that it can interact with its biochemical environment. Computing with
molecules involves recognising the presence or absence of certain
molecules, and so a natural application of DNA computing is to bring
such programmability into the realm of environmental biosensing, or
delivering medicines and therapies inside living organisms.
DNA programs have already been put to medical uses, such as diagnosing tuberculosis. Another proposed use is a nano-biological “program” by Ehud Shapiro of the Weizmann Institute of Science in Israel, termed the “doctor in the cell”
that targets cancer molecules. Other DNA programs for medical
applications target lymphocytes (a type of white blood cell), which are
defined by the presence or absence of certain cell markers and so can be
naturally detected with true/false Boolean logic. However, more effort
is required before we can inject smart drugs directly into living organisms.
Future of DNA Computing
Taken broadly, DNA computation has enormous future potential. Its
huge storage capacity, low energy cost, ease of manufacturing that
exploits the power of self-assembly and its easy affinity with the
natural world are an entry to nanoscale computing, possibly through
designs that incorporate both molecular and electronic components. Since
its inception, the technology has progressed at great speed, delivering
point-of-care diagnostics and proof-of-concept smart drugs – those that
can make diagnostic decisions about the type of therapy to deliver.
There are many challenges, of course, that need to be addressed so
that the technology can move forward from the proof-of-concept to real
smart drugs: the reliability of the DNA walkers, the robustness of DNA
self-assembly, and improving drug delivery. But a century of traditional
computer science research is well placed to contribute to developing
DNA computing through new programming languages, abstractions, and
formal verification techniques – techniques that have already
revolutionised silicon circuit design, and can help launch organic
computing down the same path.

Marta Kwiatkowska is Professor of Computing Systems at University of Oxford
This article was originally published on The Conversation. Read the original article.
Tuesday, June 30. 2015
Via Wired
-----

The ancient Library of Alexandria may have been the largest collection of human knowledge in its time,
and scholars still mourn its destruction. The risk of so devastating a
loss diminished somewhat with the advent of the printing press and
further still with the rise of the Internet. Yet centralized
repositories of specialized information remain, as does the threat of a
catastrophic loss.
Take GitHub, for example.
GitHub has in recent years become the world’s biggest collection of open source software.
That’s made it an invaluable education and business resource. Beyond
providing installers for countless applications, GitHub hosts the source
code for millions of projects, meaning anyone can read the code used to
create those applications. And because GitHub also archives past
versions of source code, it’s possible to follow the development of a
particular piece of software and see how it all came together. That’s
made it an irreplaceable teaching tool.
The odds of Github meeting a fate similar to that of the Library of Alexandria are slim. Indeed, rumor has it that
Github soon will see a new round of funding that will place the
company’s value at $2 billion. That should ensure, financially at least,
that GitHub will stay standing.
But GitHub’s pending emergence as Silicon Valley’s latest unicorn holds
a certain irony. The ideals of open source software center on freedom,
sharing, and collective benefit—the polar opposite of venture
capitalists seeking a multibillion-dollar exit. Whatever its stated
principles, GitHub is under immense pressure to be more than just a
sustainable business. When profit motives and community ideals clash,
especially in the software world, the end result isn’t always pretty.
Sourceforge: A Cautionary Tale
Sourceforge is another popular hub for open source software that predates GitHub by nearly a decade. It was once the place to find open source code before GitHub grew so popular.
There are many reasons for GitHub’s ascendance, but Sourceforge
hasn’t helped its own cause. In the years since career services outfit DHI Holdings acquired
it in 2012, users have lamented the spread of third-party ads that
masquerade as download buttons, tricking users into downloading
malicious software. Sourceforge has tools that enable users to report
misleading ads, but the problem has persisted. That’s part of why the
team behind GIMP, a popular open source alternative to Adobe Photoshop, quit hosting its software on Sourceforge in 2013.
Instead of trying to make nice, Sourceforge stirred up more hostility earlier this month when it declared
the GIMP project “abandoned” and began hosting “mirrors” of its
installer files without permission. Compounding the problem, Sourceforge
bundled installers with third party software some have called adware or
malware. That prompted other projects, including the popular media
player VLC, the code editor Notepad++, and WINE, a tool for running Windows apps on Linux and OS X, to abandon ship.
It’s hard to say how many projects have truly fled Sourceforge
because of the site’s tendency to “mirror” certain projects. If you
don’t count “forks” in GitHub—copies of projects developers use to make
their own tweaks to the code before submitting them to the main
project—Sourceforge may still host nearly as many projects as GitHub,
says Bill Weinberg of Black Duck Software, which tracks and analyzes
open source software.
But the damage to Sourceforge’s reputation may already have been
done. Gaurav Kuchhal, managing director of the division of DHI Holdings
that handles Sourceforge, says the company stopped its mirroring program
and will only bundle installers with projects whose
originators explicitly opt in for such add-ons. But misleading
“download” ads likely will continue to be a game of whack-a-mole as long
as Sourceforge keeps running third-party ads. In its hunt for revenue,
Sourceforge is looking less like an important collection of human
knowledge and more like a plundered museum full of dangerous traps.
No Ads (For Now)
GitHub has a natural defense against ending up like this: it’s never
been an ad-supported business. If you post your code publicly on GitHub,
the service is free. This incentivizes code-sharing and collaboration.
You pay only to keep your code private. GitHub also makes money offering
tech companies private versions of GitHub, which has worked out well:
Facebook, Google and Microsoft all do this.
Still, it’s hard to tell how much money the company makes from this
model. (It’s certainly not saying.) Yes, it has some of the world’s
largest software companies as customers. But it also hosts millions of
open source projects free of charge, without ads to offset the costs
storage, bandwidth, and the services layered on top of all those repos.
Investors will want a return eventually, through an acquisition or IPO.
Once that happens, there’s no guarantee new owners or shareholders will
be as keen on offering an ad-free loss leader for the company’s
enterprise services.
Other freemium services that have raised large rounds of funding,
like Box and Dropbox, face similar pressures. (Box even more so since
going public earlier this year.) But GitHub is more than a convenient
place to store files on the web. It’s a cornerstone of software
development—a key repository of open-source code and a crucial body of
knowledge. Amassing so much knowledge in one place raises the specter of
a catastrophic crash and burn or disastrous decay at the hands of
greedy owners loading the site with malware.
Yet GitHub has a defense mechanism the librarians of ancient
Alexandria did not. Their library also was a hub. But it didn’t have
Git.
Git Goodness
The “Git” part of GitHub is an open source technology that helps
programmers manage changes in their code. Basically, a team will place a
master copy of the code in a central location, and programmers make
copies on their own computers. These programmers then periodically merge
their changes with the master copy, the “repository” that remains the
canonical version of the project.
Git’s “versioning” makes managing projects much easier when multiple
people must make changes to the original code. But it also has an
interesting side effect: everyone who works on a GitHub project ends up
with a copy own their computers. It’s as if everyone who borrowed a book
from the library could keep a copy forever, even after returning it. If
GitHub vanished entirely, it could be rebuilt using individual users’
own copies of all the projects. It would take ages to accomplish, but it
could be done.
Still, such work would be painful. In addition to the source code
itself, GitHub is also home to countless comments, bug reports and
feature requests, not to mention the rich history of changes. But the
decentralized nature of Git does make it far easier to migrate projects
to other hosts, such as GitLab, an open source alternative to GitHub that you can run on your own server.
In short, if GitHub as we know it went away, or under future
financial pressures became an inferior version of itself, the world’s
code will survive. Libraries didn’t end with Alexandria. The question is
ultimately whether GitHub will find ways to stay true to its ideals
while generating returns—or wind up the stuff of legend.
Friday, June 19. 2015
Via Tech Crunch
-----

Google, Microsoft, Mozilla and the engineers on the WebKit project today announced that they have teamed up to launch WebAssembly, a new binary format for compiling applications for the web.
The web thrives on standards and, for better or worse, JavaScript is
its programming language. Over the years, however, we’ve seen more and
more efforts that allow developers to work around some of the
limitations of JavaScript by building compilers that transpile code in
other languages to JavaScript. Some of these projects focus on adding
new features to the language (like Microsoft’s TypeScript) or speeding up JavaScript (like Mozilla’s asm.js project). Now, many of these projects are starting to come together in the form of WebAssmbly.
The new format is meant to allow programmers to compile their code
for the browser (currently the focus is on C/C++, with other languages
to follow), where it is then executed inside the JavaScript engine.
Instead of having to parse the full code, though, which can often take
quite a while (especially on mobile), WebAssembly can be decoded
significantly faster
The idea is that WebAssembly will provide developers with a single compilation target for the web that will, eventually, become a web standard that’s implemented in all browsers.
By default, JavaScript files are simple text files that are
downloaded from the server and then parsed and compiled by the
JavaScript engine in the browser. The WebAssembly team decided to go
with a binary format because that code can be compressed even more than
the standard JavaScript text files and because it’s much faster for the
engine to decode the binary format (up to 23x faster in the current
prototype) than parsing asm.js code, for example.
Mozilla’s asm.js has long aimed to bring near-native speeds to the web. Google’s Native Client
project for running native code in the browser had similar aims, but
got relatively little traction. It looks like WebAssemly may be able to
bring the best of these projects to the browser now.
As a first step, the WebAssembly team aims to offer about the same
functionality as asm.js (and developers will be able to use the same
Emscripten tool for WebAssembly as they use for compiling asm.js code
today).
In this early stage, the team also plans to launch a so-called polyfill library
that will translate WebAssembly code into JavaScript so that it can run
in any browser — even those without native WebAssembly support (that’s
obviously a bit absurd, but that last step won’t be needed once browsers
can run this code natively). Over time then, the teams will build more tools (compilers, debuggers, etc.) and add support for more languages (Rust, Go and C#, for example).
As JavaScript inventor (and short-term Mozilla CEO) Brendan Eich points out today, once the main browsers support the new format natively, JavaScript and WebAssembly will be able to diverge again.
The team notes that the idea here is not to replace JavaScript, by
the way, but to allow many more languages to be compiled for the Web.
Indeed, chances are that both JavaScript and WebAssembly will be used
side-by-side and some parts of the application may use WebAssembly
modules (animation, visualization, compression, etc.), while the user
interface will still be mostly written in JavaScript, for example.
It’s not often that we see all the major browser vendors work
together on a project like this, so this is definitely something worth
watching in the months and years ahead.
Thursday, June 18. 2015
Via Tech Crunch
-----

While companies like Facebook have been relatively open
about their data center networking infrastructure, Google has
generally kept pretty quiet about how it connects the thousands of
servers inside its data centers to each other (with a few exceptions). Today, however, the company revealed a bit more about the technology that lets its servers talk to each other.
It’s no secret that Google often builds its own custom hardware for
its data centers, but what’s probably less known is that Google uses
custom networking protocols that have been tweaked for use in its data
centers instead of relying on standard Internet protocols to power its
networks.
Google says its current ‘Jupiter’ networking setup — which represents
the fifth generation of the company’s efforts in this area — offers
100x the capacity of its first in-house data center network. The current
generation delivers 1 Petabit per second of bisection bandwidth (that
is, the bandwidth between two parts of the network). That’s enough to allow 100,000 servers to talk to each other at 10GB/s each.
Google’s technical lead for networking, Amin Vahdat, notes that the
overall network control stack “has more in common with Google’s
distributed computing architectures than traditional router-centric
Internet protocols.”
Here is how he describes the three key principles behind the design of Google’s data center networks:
-
We arrange our network around a Clos topology,
a network configuration where a collection of smaller (cheaper)
switches are arranged to provide the properties of a much larger logical
switch.
-
We use a centralized software control stack to manage
thousands of switches within the data center, making them effectively
act as one large fabric.
-
We build our own software and hardware using silicon from
vendors, relying less on standard Internet protocols and more on custom
protocols tailored to the data center.
Sadly, there isn’t all that much detail here — especially compared to some of the information
Facebook has shared in the past. Hopefully Google will release a bit
more in the months to come. It would be especially interesting to see
how its own networking protocols work and hopefully the company will
publish a paper or two about this at some point.
Thursday, June 11. 2015
Via io9
-----

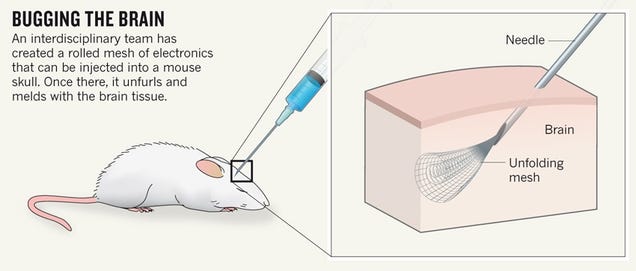
Above:
Bright-field image showing the mesh electronics being injected through
sub-100 micrometer inner diameter glass needle into aqueous solution.
(Lieber Research Group/Harvard University
Harvard scientists have developed an electrical scaffold that can be
injected directly into the brain with a syringe. By using the technique
to “cyborg”-ize the brains of mice, the team was able to investigate and
manipulate the animals’ individual neurons—a technological feat the
researchers say holds tremendous medical promise.
As reported in Nature News,
the soft, conductive polymer mesh can be injected into a mouse’s brain,
where it unfurls and takes root. And because the mesh can be laced with
tiny electronic devices, the implant can be custom-designed to perform a
number of tasks, from monitoring brain activity to stimulating brain
functions. Once proven safe, the technology could be applied in humans,
where it could be used to treat Parkinson’s, among other cognitive
disorders. The details of this research, led by Harvard’s Charles
Lieber, can be found in the journal Nature Nanotechnology.
“I do feel that this has the potential to be revolutionary,” Lieber noted in a Harvard statement.
“This opens up a completely new frontier where we can explore the
interface between electronic structures and biology. For the past 30
years, people have made incremental improvements in micro-fabrication
techniques that have allowed us to make rigid probes smaller and
smaller, but no one has addressed this issue — the electronics/cellular
interface — at the level at which biology works.”
(Credit: Nature News/Nature Nanotechnology/Lieber Research Group/Harvard University)
Nature News’s Elizabeth Gibney explains how it works:
"The
Harvard team [used] a mesh of conductive polymer threads with either
nanoscale electrodes or transistors attached at their intersections.
Each strand is as soft as silk and as flexible as brain tissue itself.
Free space makes up 95% of the mesh, allowing cells to arrange
themselves around it.
In
2012, the team showed that living cells grown in a dish can be coaxed
to grow around these flexible scaffolds and meld with them, but this
‘cyborg’ tissue was created outside a living body. “The problem is, how
do you get that into an existing brain?” says Lieber.
The
team’s answer was to tightly roll up a 2D mesh a few centimetres wide
and then use a needle just 100 micrometres in diameter to inject it
directly into a target region through a hole in the top of the skull.
The mesh unrolls to fill any small cavities and mingles with the tissue.
Nanowires that poke out can be connected to a computer to take
recordings and stimulate cells."
Using this
technique, the researchers implanted meshes consisting of 16 electric
elements into two different brain regions, enabling them to monitor and
stimulate individual neurons. The researchers would like to scale up to
hundreds of devices outfitted with different kinds of sensors. In the
future, these arrays might be used to treat motor disorders, paralysis,
and repair brain damage caused by stroke. What’s more, these implants
could conceivably be used in other parts of the body. But before they
get too carried away, the researchers will have to prove that the
implantable technology is safe in the longterm.
Read more at Nature News. And check out the scientific study at Nature: “Syringe-injectable Electronics”.
Monday, June 08. 2015
Via TechCrunch
-----
According to the Labor Department, the U.S. economy is in
its strongest stretch in corporate hiring since 1997. Given the rapidly
escalating competition for talent, it is important for employers, job
seekers, and policy leaders to understand the dynamics behind some of
the fastest growing professional roles in the job market.
For adults with a bachelor’s degree or above, the unemployment rate stood at just 2.7 percent in May 2015.
The national narrative about “skills gaps” often focuses on
middle-skill jobs that rely on shorter-term or vocational training – but
the more interesting pressure point is arguably at the professional
level, which has accounted for much of the wage and hiring growth in the
U.S. economy in recent years. Here, the reach and impact of technology
into a range of professional occupations and industry sectors is
impressive.
Software is eating the world
In 2011, Netscape and Andreessen Horowitz co-founder Marc Andreessen coined the phrase “software is eating the world” in an article
outlining his hypothesis that economic value was increasingly being
captured by software-focused businesses disrupting a wide range of
industry sectors. Nearly four years later, it is fascinating that around
1 in every 20 open job postings in the U.S. job market relates to
software development/engineering.
The shortage of software developers is well-documented and
increasingly discussed. It has spawned an important national dialogue
about economic opportunity and encouraged more young people, women, and
underrepresented groups to pursue computing careers – as employers seek
individuals skilled in programming languages such as Python, JavaScript, and SQL.
Although most of these positions exist at the experienced level, it is no surprise that computer science and engineering are among the top three most-demanded college majors in this spring’s undergraduate employer recruiting season, according to the National Association of Colleges and Employers.
Discussion about the robust demand and competition for software
developers in the job market is very often focused around high-growth
technology firms such Uber, Facebook, and the like. But from the
“software is eating the world” perspective, it is notable that
organizations of all types are competing for this same talent – from
financial firms and hospitals to government agencies. The demand for
software skills is remarkably broad.
For example, the top employers with the greatest number of developer
job openings over the last year include JP Morgan Chase, UnitedHealth,
Northrup Gruman, and General Motors, according to job market database
firm Burning Glass Technologies.
Data science is just the tip of the iceberg
Another surge of skills need related to technology is analytics and
the ability to work with, process, and interpret insights from big data.
Far more than just a fad or buzzword, references to analytical and
data-oriented skills appeared in 4 million postings over the last year –
and data analysis is one of the most demanded skills by U.S. employers,
according to Burning Glass data.
The Harvard Business Review famously labeled data scientist roles “the sexiest job of the 21st century”
– but while this is a compelling new profession by any measure, data
scientists sit at the top of the analytics food chain and likely only
account for tens of thousands of positions in a job market of 140
million.
What often goes unrecognized is that similar to and even more so than
software development, the demand for analytical skills cuts across all
levels and functions in an organization, from financial analysts and web
developers to risk managers. Further, a wide range of industries is
hungry for analytics skills – ranging from the nursing field and public
health to criminal justice and even the arts and cultural sector.
As suggested by analytics experts such as Tom Davenport,
organizations that are leveraging analytics in their strategy have not
only world-class data scientists – but they also support “analytical
amateurs” and embed analytics throughout all levels of their
organization and culture. For this reason, the need for analytics skills
is exploding within a variety of employers, and analytics and
data-related themes top many corporate strategy agendas.
Analytics: Digital marketing demands experienced talent
Change is also afoot as digital and mobile channels are disrupting the marketing landscape. According to the CMO Council, spending on mobile marketing is doubling each year,
and two-thirds of the growth in consumer advertising is in digital. In
an economic expansion cycle, awareness-building and customer acquisition
is where many companies are investing. For these reasons, marketing
managers are perhaps surprisingly hard to find.
For example, at high-growth tech companies such as Amazon and
Facebook, the highest volume job opening after software
developer/engineer is marketing manager. These individuals are
navigating new channels, as well as approaches to customer acquisition,
and they are increasingly utilizing analytics. The marketing manager is
an especially critical station in the marketing and sales career ladder
and corporate talent bench – with junior creative types aspiring to it
and senior product and marketing leadership coming from it.
The challenge is that marketing management requires experience: Those
with a record of results in the still nascent field of digital
marketing will be especially in demand.
Social media: not just a marketing and communications skill
Traditionally thought of in a marketing context, social media skills
represent a final “softer” area that is highly in demand and spans a
range of functional silos and levels in the job market — as social media
becomes tightly woven into the fabric of how we live, work, consume and
play.
While many organizations are, of course, hiring for social
media-focused marketing roles, a quick search of job listings at an
aggregator site such as Indeed.com reveals 50,000 job openings referencing social media.
These range from privacy officers in legal departments that need to
account for social media in policy and practice, to technologists who
need to integrate social media APIs with products, and project managers
and chiefs of staff to CEOs who will manage and communicate with
internal and external audiences through social media.
Just as skills in Microsoft Office have become a universal foundation
for most professional roles, it will be important to monitor how the
use of social media platforms, including optimization and analytics,
permeates the job market.
The aforementioned in-demand skills areas represent more of a
structural shift than an issue du jour or passing trend. It is precisely
the rapid, near daily change in software- and technology-related skills
needs that necessitates new approaches to human capital development.
While traditional long-term programs such as college degrees remain
meaningful, new software platforms, languages, apps and tools rise
annually. Who in the mainstream a few years ago had heard of Hadoop or
Ruby?
Each month, new partnerships and business models are being formed
between major employers, educational institutions and startups – all
beginning to tackle novel approaches to skills development in these
areas. Certificate programs, boot camps, new forms of executive
education, and credentialing are all targeting the problem of producing
more individuals with acumen in these areas.
As technology continues to extend its reach and reshape the
workforce, it will be important to monitor these issues and explore new
solutions to talent development.
Sunday, May 17. 2015
Via The Register
-----
Mozilla has released the first version of its Firefox browser to
include support for Encrypted Media Extensions, a controversial World
Wide Web Consortium (W3C) spec that brings digital rights management
(DRM) to HTML5's video tag.
The nonprofit grudgingly agreed to add EME support to Firefox last year, despite the vocal objections of both Mozilla's then-CTO Brendan Eich and the Free Software Foundation.
"Nearly everyone who implements DRM says they are
forced to do it" the FSF said at the time, "and this lack of
accountability is how the practice sustains itself."
Nonetheless, Mozilla promoted Firefox 38 to the Release channel on Tuesday, complete with EME enabled – although it said it's still doing so reluctantly.
"We don't believe DRM is a desirable market solution,
but it's currently the only way to watch a sought-after segment of
content," Mozilla senior veep of legal affairs Danielle Dixon-Thayer
said in a blog post.
The first firm to leap at the chance to shovel its
DRM into Firefox was Adobe, whose Primetime Content Delivery Module for
decoding encrypted content shipped with Firefox 38 on Tuesday. Thayer
said various companies, including Netflix, are already evaluating
Adobe's tech to see if it meets their requirements.
Mozilla says that because Adobe's CDM is proprietary
"black box" software, it has made certain to wrap it in a sandbox within
Firefox so that its code can't interfere with the rest of the browser.
(Maybe that's why it took a year to get it integrated.)
The CDM will issue an alert when it's on a site that
uses DRM-wrapped content, so people who don't want to use it will have
the option of bowing out.

Restricted content ahead ...
If you don't want your browser tainted by DRM at all, you still have options.
You can disable the Adobe Primetime CDM so it never activates. If
that's not good enough, there's a menu option in Firefox that lets you
opt out of DRM altogether, after which you can delete the Primetime CDM
(or any future CDMs from other vendors) from your hard drive.
Finally, if you don't want DRM in your browser and you don't want to bother with any of the above, Mozilla has made available a separate download that doesn't include the Primetime CDM and has DRM disabled by default.
As it happens, however, many users won't have to deal
with the issue at all – at least not for now. The first version of
Adobe's CDM for Firefox is only available on Windows Vista and later and
then only for 32-bit versions of the browser. Windows XP, OS X, Linux,
and 64-bit versions of Firefox are not yet supported, and there's no
word yet on when they might be.
Thursday, April 30. 2015
Via Information week
-----
Technology giant IBM announced two major breakthroughs
towards the building of a practical quantum computer, the next evolution
in computing that will be required as Moore’s Law runs out of steam.
Described in the April 29 issue of the journal Nature Communications,
the breakthroughs include the ability to detect and measure both kinds
of quantum errors simultaneously and a new kind of circuit design, which
the company claims is "the only physical architecture that could
successfully scale to larger dimensions."
The two innovations are interrelated: The quantum bit
circuit, based on a square lattice of four superconducting "qubits" --
short for quantum bits -- on a chip roughly one-quarter-inch square,
enables both types of quantum errors to be detected at the same time.
The IBM project, which was funded in part by the
Intelligence Advanced Research Projects Activity (IARPA) Multi-Qubit
Coherent Operations program, opts for a square-shaped design as opposed
to a linear array, which IBM said prevents the detection of both kinds
of quantum errors simultaneously.
Jerry M. Chow, manager of the Experimental Quantum Computing
group at IBM’s T.J. Watson Research Center, and the primary
investigator on the IARPA-sponsored Multi-Qubit Coherent Operations
project, told InformationWeek that one area they are excited about is
the potential for quantum computers to simulate systems in nature.
"In physics and chemistry, quantum computing will allow us
to design new materials and drug compounds without the expensive
trial-and-error experiments in the lab, dramatically speeding up the
rate and pace of innovation," Chow said. "For instance, the
effectiveness of drugs is governed by the precise nature of the chemical
bonds in the molecules constituting the drug."
He noted the computational chemistry required for many of
these problems is out of the reach of classical computers, and this is
one example of where quantum computers may be capable of solving such
problems leading to better drug design.
The qubits, IBM said, could be designed and manufactured
using standard silicon fabrication techniques, once a handful of
superconducting qubits can be manufactured quickly and reliably, and
boast low error-rates.
"Quantum information is very fragile, requiring the quantum
elements to be cooled to near absolute zero temperature and shielded
from its environment to minimize errors," Chow explained. "A quantum
bit, the component that carries information in a quantum system, can be
susceptible to two types of errors -- bit-flip and phase-flip. It either
error occurs, the information is destroyed and it cannot carry out the
operation."
He said it is important to detect and measure both types of
errors in order to know what errors are present and how to address them,
noting no one has been able to do this before in a scalable
architecture.
"We are at the stage of figuring out the building blocks of
quantum computers -- a new paradigm of computing completely different
than how computers are built today," Wong said. "In the arc of quantum
computing progress, we are at the moment of time similar to when
scientists were building the first transistor. If built, quantum
computers have the potential to unlock new applications for scientific
discovery and data analysis and will be more powerful than any
supercomputer today."
|


