Tuesday, February 07. 2012
It's Kinect day! The Kinect For Windows SDK v1 is out!
Friday, January 27. 2012
A New Mathematics for Computing
Via Input Output
-----
We live in a world where digital technology is so advanced that even what used to be science fiction looks quaint. (Really, Kirk, can you download Klingon soap operas on that communicator?) Yet underlying it all is a mathematical theory that dates back to 1948.
That year, Claude Shannon published the foundational information theory paper, A Mathematical Theory of Communication (PDF). Shannon’s work underlies communications channels as diverse as proprietary wireless networks and leads on printed circuits.
Yet in Shannon’s time, as we all know, there were no personal computers, and the only guy communicating without a desk telephone was Dick Tracy. In our current era, the number of transistors on chips has gotten so dense that the potential limits of Moore’s Law are routinely discussed. Multi-core processors, once beyond the dreams of even supercomputers, are now standard on consumer laptops. Is it any wonder then, that even Shannon’s foresighted genius may have reached its limits?

From the Internet to a child’s game of telephone, the challenge in communications is to relay a message accurately, without losing any of it to noise. Prior to Shannon, the answer was a cumbersome redundancy. Imagine a communications channel as a conveyer belt, with every message as a pile of loose diamonds: If you send hundreds of piles down the belt, some individual diamonds might fall off, but at least you get most of the diamonds through quickly. If you wrap every single diamond in bubble wrap, you won’t lose any individual diamonds, but now you can’t send as many in the same amount of time.
Shannon’s conceptual breakthrough was to realize you could wrap the entire pile in bubble wrap and save the correction for the very end. “It was a complete revolution,” says Schulman, “You could get better and better reliability without actually slowing down the communications.”
In its simplest form, Shannon’s idea of global error correction is what we know as a “parity check” or “check sum,” in which a section of end digits should be an accurate summation of all the preceding digits. (In a more technical scheme: The message is a string n-bits long. It is mapped to another, longer string of code words. If you know what the Hamming distance—the difference in their relative positions—should be, you can determine reliability.)

Starting back as far as the late 1970s, researchers in the emerging field of communication complexity were beginning to ask themselves: Could you do what Shannon did, if your communication were more of a dialogue than a monologue?
What was a theoretical question then is becoming a real-world problem today. With faster chips and multi-core processes, communications channels are becoming two-way, with small messages going back and forth. Yet error correction still assumes big messages going in one direction. “How on earth are you going to bubble wrap all these things together, if what you say depends on what I said to you?” says Schulman.
The answer is to develop an “interactive” form of error correction. In essence, a message sent using classic Shannon error correction is like a list of commands, “Go Left, Go Right, Go Left again, Go Right…” Like a suffering dinner date, the receiver only gets a chance to reply at the end of the string.
By contrast, an interactive code sounds like a dialog between sender and receiver:
“Going left.”“Going left too.”
“Going right.”
“Going left instead.”“Gzzing zzzztt.”
“Huh?”
“Going left too.”
The underlying mathematics for making this conversation highly redundant and reliable is a “tree code.” To the lay person, tree codes resemble a branching graph. To a computer scientist they are “a set of structured binary strings, in which the metric space looks like a tree,” says Schulman, who wrote the original paper laying out their design in 1993.

“Consider a graph that describes every possible sequence of words you could say in your lifetime. For every word you say, there’s thousands of possibilities for the next word,” explains Amit Sahai, “A tree code describes a way of labeling this graph, where each label is an instruction. The ways to label the graph are infinite, but remarkably Leonard showed there is actually one out there that’s useful.”
Tree codes can branch to infinity, a dendritic structure which allows for error correction at multiple points. It also permits tree codes to remember entire sequences; how the next reply is encoded depends on the entire history of the conversation. As a result, a tree code can perform mid-course corrections. It’s as if you think you’re on your way to London, but increasingly everyone around you is speaking French, and then you realize, “Oops, I got on at the wrong Chunnel station.”
The result is that instructions are not only conveyed faster; they’re acted on faster as well, with real-time error correction. There’s no waiting to discover too late that an entire string requires re-sending. In that sense, tree codes could help support the parallel processing needs of multi-core machines. They could also help in the increasingly noisy environments of densely packed chips. “We already have chip-level error correction, using parity checks,” says Schulman. But once again, there’s the problem of one-way transmission, in which an error is only discovered at the end. By contrast, a tree code, “gives you a check sum at every stage of a long interaction,” says Schulman.
Unfortunately, those very intricacies are why interactive communications aren’t coming to a computer near you anytime soon. Currently, tree codes are in the proof of concept phase. “We can start from that math and show they exist, without being able to say: here is one,” says Schulman. One of the primary research challenges is to make the error correction as robust as possible.
One potential alternative that may work much sooner was just published by Sahai and his colleagues. They modified Schulman’s work to create a code that, while not quite the full theoretical ideal of a tree code, may actually perform nearly up to that ideal in real-world applications. “It’s not perfect, but for most purposes, if the technology got to where you needed to use it, you could go ahead with that,” says Schulman, “It’s a really nice piece of progress.”
Sahai, Schulman, and other researchers are still working to create perfect tree codes. “As a mathematician, there’s something that gnaws at us,” says Sahai, “We do want to find the real truth—what is actually needed for this to work.” They look to Shannon as their inspiration. “Where we are now is exactly analogous to what Shannon did in that first paper,” Schulman says, “He proved that good error correcting codes could exist, but it wasn’t until the late 1960s that people figured out how to use algebraic methods to do them, and then the field took off dramatically.”
Thursday, January 19. 2012
The faster-than-fast Fourier transform
Tuesday, January 17. 2012
HTML bringing to us old boot sessions

For anyone of us who thinks that past was better... or to show to new comers that, some time ago, a computer device was not supposed to be always switched on!
Wednesday, January 11. 2012
Holographic code
Monday, January 09. 2012
NoSQL’s great, but bring your A game
Via GIGAOM
-----
MongoDB might be a popular choice in NoSQL databases, but it’s not perfect — at least out of the box. At last week’s MongoSV conference in Santa Clara, Calif., a number of users, including from Disney, Foursquare and Wordnik, shared their experiences with the product. The common theme: NoSQL is necessary for a lot of use cases, but it’s not for companies afraid of hard work.
If you’re in the cloud, avoid the disk
 According to Wordnik
technical co-founder and vice president of engineering Tony Tam, unless
you’re willing to spend beaucoup dollars on buying and operating
physical infrastructure, cloud computing is probably necessary to match
the scalability of NoSQL databases.
According to Wordnik
technical co-founder and vice president of engineering Tony Tam, unless
you’re willing to spend beaucoup dollars on buying and operating
physical infrastructure, cloud computing is probably necessary to match
the scalability of NoSQL databases.
As he explained, Wordnik actually launched on Amazon Web Services and used MySQL, but the database hit a wall at around a billion records, he said. So, Wordnik switched to MongoDB, which solved the scaling problem but caused its own disk I/O problems that resulted in a major performance slowdown. So, Wordnik ported everything back onto some big physical servers, which drastically improved performance.
And then came the scalability problem again, only this time it was in terms of infrastructure. So, it was back to the cloud. But this time, Wordnik got smart and tuned the application to account for the strengths and weaknesses of MongoDB (“Your app should be smarter than your database,” he says), and MongoDB to account for the strengths and weaknesses of the cloud.
Among his observations was that in the cloud, virtual disks have virtual performance, “meaning it’s not really there.” Luckily, he said, you can design to take advantage of virtual RAM. It will fill up fast if you let it, though, and there’s trouble brewing if requests start hitting the disk. “If you hit indexes on disk,” he warned, “mute your pager.”
 Foursquare’s Cooper Bethea echoed much of Tam’s sentiment, noting that “for us, paging the disk is really bad.” Because Foursquare
works its servers so hard, he said, high latency and error counts start
occurring as soon as the disk is invoked. Foursquare does use disk in
the form of Amazon Elastic Block Storage, but it’s only for backup.
Foursquare’s Cooper Bethea echoed much of Tam’s sentiment, noting that “for us, paging the disk is really bad.” Because Foursquare
works its servers so hard, he said, high latency and error counts start
occurring as soon as the disk is invoked. Foursquare does use disk in
the form of Amazon Elastic Block Storage, but it’s only for backup.
EBS also brings along issues of its own. At least once a day, Bethea said, queued reads and writes to EBS start backing up excessively, and the only solution is to “kill it with fire.” What that means changes depending on the problem, but it generally means stopping the MongoDB process and rebuilding the affected replica set from scratch.
Monitor everything
Curt Stevens of the Disney Interactive Media Group explained how his team monitors the large MongoDB deployment that underpins Disney’s online games. MongoDB actually has its own tool called the Mongo Monitoring System that Stevens said he swears by, but it isn’t always enough. It shows traffic and performance patterns over time, which is helpful, but only the starting point.
 Once a problem is discovered, “it’s like CSI
on your data” to figure out what the underlying problem is. Sometimes,
an instance just needs to be sharded, he explained. Other times, the
code could be buggy. One time, Stevens added, they found out a
poor-performing app didn’t have database issues at all, but was actually
split across two data centers that were experiencing WAN issues.
Once a problem is discovered, “it’s like CSI
on your data” to figure out what the underlying problem is. Sometimes,
an instance just needs to be sharded, he explained. Other times, the
code could be buggy. One time, Stevens added, they found out a
poor-performing app didn’t have database issues at all, but was actually
split across two data centers that were experiencing WAN issues.
Oh, and just monitoring everything isn’t enough when you’re talking about a large-scale system, Stevens said. You have to have alerts in place to tell you when something’s wrong, and you have to monitor the monitors. If MMS or any other monitoring tools go down, you might think everything is just fine while the kids trying to have a magical Disney experience online are paying the price.
By the numbers
If you’re wondering what kind of performance and scalability requirements forced these companies to MongoDB, and then to customize it so heavily, here are some statistics:
- Foursquare: 15 million users; 8 production MongoDB clusters; 8 shards of user data; 12 shards of check-in data; ~250 updates per second on user database, with maximum output of 46 MBps; ~80 check-ins per second on check-in database, with maximum output of 45 MBps; up to 2,500 HTTP queries per second.
- Wordnik: Tens of billions of documents with more always being added; more than 20 million REST API calls per day; mapping layer supports 35,000 records per second.
- Disney: More than 1,400 MongoDB instances (although “your eyes start watering after 30,” Stevens said); adding new instances every day, via a custom-built self-service portal, to test, stage and host new games.
For more-technical details about their trials and tribulations with MongoDB, all three presentations are available online, along with the rest of the conference’s talks.
Personal Comments:
Here are some basics and information on NoSQL: Wiki, NoSQL Databases, MongoDB
Tuesday, November 01. 2011
Multi-Device Web Design: An Evolution
Via LUKEW
By Luke Wroblewski
-----
As mobile devices have continued to evolve and spread, so has the process of designing and developing Web sites and services that work across a diverse range of devices. From responsive Web design to future friendly thinking, here's how I've seen things evolve over the past year and a half.

If you haven't been keeping up with all the detailed conversations about multi-device Web design, I hope this overview and set of resources can quickly bring you up to speed. I'm only covering the last 18 months because it has been a very exciting time with lots of new ideas and voices. Prior to these developments, most multi-device Web design problems were solved with device detection and many still are. But the introduction of Responsive Web Design really stirred things up.
Responsive Web Design
Responsive Web Design is a combination of fluid grids and images with media queries to change layout based on the size of a device viewport. It uses feature detection (mostly on the client) to determine available screen capabilities and adapt accordingly. RWD is most useful for layout but some have extended it to interactive elements as well (although this often requires Javascript).
Responsive Web Design allows you to use a single URL structure for a site, thereby removing the need for separate mobile, tablet, desktop, etc. sites.
For a short overview read Ethan Marcotte's original article. For the full story read Ethan Marcotte's book. For a deeper dive into the philosophy behind RWD, read over Jeremy Keith's supporting arguments. To see a lot of responsive layout examples, browse around the mediaqueri.es site.
Challenges
Responsive Web Design isn't a silver bullet for mobile Web experiences. Not only does client-side adaptation require a careful approach, but it can also be difficult to optimize source order, media, third-party widgets, URL structure, and application design within a RWD solution.
Jason Grigsby has written up many of the reasons RWD doesn't instantly provide a mobile solution especially for images. I've documented (with concrete) examples why we opted for separate mobile and desktop templates in my last startup -a technique that's also employed by many Web companies like Facebook, Twitter, Google, etc. In short, separation tends to give greater ability to optimize specifically for mobile.

Mobile First Responsive Design
Mobile First Responsive Design takes Responsive Web Design and flips the process around to address some of the media query challenges outlined above. Instead of starting with a desktop site, you start with the mobile site and then progressively enhance to devices with larger screens.
The Yiibu team was one of the first to apply this approach and wrote about how they did it. Jason Grigsby has put together an overview and analysis of where Mobile First Responsive Design is being applied. Brad Frost has a more high-level write-up of the approach. For a more in-depth technical discussion, check out the thread about mobile-first media queries on the HMTL5 boilerplate project.
Techniques
Many folks are working through the challenges of designing Web sites for multiple devices. This includes detailed overviews of how to set up Mobile First Responsive Design markup, style sheet, and Javascript solutions.
Ethan Marcotte has shared what it takes for teams of developers and designers to collaborate on a responsive workflow based on lessons learned on the Boston Globe redesign. Scott Jehl outlined what Javascript is doing (PDF) behind the scenes of the Globe redesign (hint: a lot!).
Stephanie Rieger assembled a detailed overview (PDF) of a real-world mobile first responsive design solution for hundreds of devices. Stephan Hay put together a pragmatic overview of designing with media queries.
Media adaptation remains a big challenge for cross-device design. In particular, images, videos, data tables, fonts, and many other "widgets" need special care. Jason Grigsby has written up the situation with images and compiled many approaches for making images responsive. A number of solutions have also emerged for handling things like videos and data tables.
Server Side Components
Combining Mobile First Responsive Design with server side component (not full page) optimization is a way to extend client-side only solutions. With this technique, a single set of page templates define an entire Web site for all devices but key components within that site have device-class specific implementations that are rendered server side. Done right, this technique can deliver the best of both worlds without the challenges that can hamper each.
I've put together an overview of how a Responsive Design + Server Side Components structure can work with concrete examples. Bryan Rieger has outlined an extensive set of thoughts on server-side adaption techniques and Lyza Gardner has a complete overview of how all these techniques can work together. After analyzing many client-side solutions to dynamic images, Jason Grigsby outlined why using a server-side solution is probably the most future friendly.

Future Thinking
If all the considerations above seem like a lot to take in to create a Web site, they are. We are in a period of transition and still figuring things out. So expect to be learning and iterating a lot. That's both exciting and daunting.
It also prepares you for what's ahead. We've just begun to see the onset of cheap networked devices of every shape and size. The zombie apocalypse of devices is coming. And while we can't know exactly what the future will bring, we can strive to design and develop in a future-friendly way so we are better prepared for what's next.
Resources
I referenced lots of great multi-device Web design resources above. Here they are in one list. Read them in order and rock the future Web!
- Effective Design for Multiple Screen Sizesby Bryan Rieger
- Responsive Web Design (article) by Ethan Marcotte
- Responsive Web Design (book) by Ethan Marcotte
- There Is No Mobile Web by Jeremy Keith
- mediaqueri.es by various artisits
- CSS Media Query for Mobile is Fool’s Gold by Jason Grigsby
- Why Separate Mobile & Desktop Web Pages? by Luke Wroblewski
- About this site... by Yiibu
- Where are the Mobile First Responsive Web Designs? by Jason Grigsby
- Mobile-First Responsive Web Design by Brad Frost
- Mobile-first Media Queries by various artists
- The Responsive Designer’s Workflow by Ethan Marcotte
- Responsible & Responsive (PDF) by Scott Jehl
- Pragmatic Responsive Design (further details) by Stephanie Rieger
- A Closer Look at Media Queries by Stephen Hay
- Responsive IMGs — Part 1 by Jason Grigsby
- Responsive IMGs — Part 2 by Jason Grigsby
- Device detection as the future friendly img option by Jason Grigsby
- Responsive Video Embeds with FitVids by Dave Rupert
- Responsive Data Tables by Chris Coyier
- RESS: Responsive Design + Server Side Components by Luke Wroblewski
- Adaptation (PDF) by Bryan Rieger
- How I Learned to Stop Worrying and Set my Mobile Web Sites Free by Lyza Danger Gardner
- The Coming Zombie Apocalypse by Scott Jenson
- Future Friendly by various artists
Tuesday, September 20. 2011
Google offers Ice Cream Sandwich guidance to Android app devs
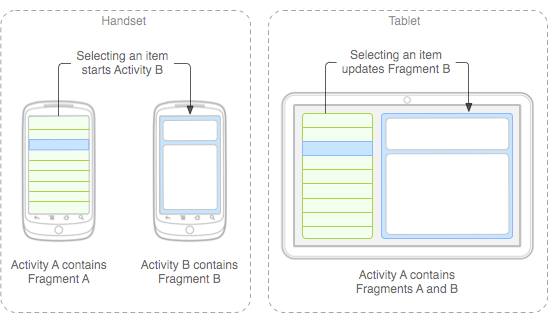
The next major version of Google's Android platform, codenamed Ice Cream Sandwich (ICS), is expected to reach the market in October or November. ICS is expected to bring some significant changes to Android because it will unify Google's tablet and phone variants into a single environment.
Although the SDK is not available yet, Google has published some technical guidance to help third-party application developers start preparing for the ICS transition. An entry posted this week on the Android developer blog describes some steps that developers can take to better accommodate the breadth of screen sizes supported by ICS.
The documentation also provides some insight into how several elements of the Honeycomb user interface could be translated to phone-sized screens in ICS. For example, it includes mockups that show the distinctive Honeycomb action bar on a tablet and a phone. It's not clear, however, if the mockups accurately depict the user experience that will be delivered in ICS.
This seems to suggest that tablet user interfaces developed with standard Honeycomb APIs will largely work on phones in ICS without requiring much modification by third-party developers. That's good news, especially if it ends up being equally true the other way, which would allow phone applications built for ICS to look and feel more native on tablet devices. Google's existing Fragments framework will also help simplify interface scalability by making it easy to transition data-driven applications between single-pane to multi-pane layouts.
Developers who use Fragments and stick to the standard Honeycomb user interface components are on the right track for the upcoming ICS release, but developers who have built more complicated tablet-specific user interfaces or haven't stayed within the boundaries imposed by the documented APIs might face some challenges.
Honeycomb applications that were designed only for the tablet screen size might not scale down correctly on phones. That's a problem, because Android's versioning model doesn't prevent old applications from running on devices with new versions of the operating system—it's going to be possible for users to install Honeycomb tablet applications on ICS phones, even in cases where the result is going to be a very broken application.
In cases where third-party developers can't adapt their tablet software to work well at phone sizes, Google suggests changing the application manifest file to block the application from being installed on devices with small screens.
Another challenge is the large body of legacy devices that aren't going to be updated to ICS. Developers who want to reach the largest possible audience will have to refrain from using the new APIs, which means that it will be harder for them to take advantage of the platform's increasingly sophisticated capabilities for scaling across different screen sizes.
Google has already partially addressed this issue by backporting the Fragments framework and making it available as a static library for older versions of the operating system. It might be beneficial for them to go a step further and do the same with the Action Bar and other critical user interface components that will be designed to scale seamlessly in ICS.
It's going to take some time for the Android application ecosystem to sort all of this out after ICS is released, but Google's approach seems reasonably practical. In theory, developers who are solely targeting ICS APIs might not have to make a significant development investment to get their application working well across tablet and phone form factors.
Monday, September 12. 2011
Narrative Science Is a Computer Program That Can Write
Via Nexus 404
by J Angelo Racoma
-----
Automatic content generators are the scourge of most legitimate writers and publishers, especially if these take some original content, spin it around and generate a mashup of different content but obviously based on something else. An app made by computer science and journalism experts involves artificial intelligence that writes like a human, though.

Developers at the Northwestern University’s Intelligent Information Laboratory have come up with a program called Narrative Science, which composes articles and reports based on data, facts, and styles plugged in. The application is worth more than 10 years’ work by Kris Hammond and Larry Birnbaum who are both professors of journalism and computer science at the university.
Artificial vs Human Intelligence
Currently being used by 20 companies, an example of work done by Narrative Science include post-game reports for collegiate athletics events and articles for medical journals, in which the software can compose an entire, unique article in about 60 seconds or so. What’s striking is that even language experts say you won’t know the difference between the software and an actual human, in terms of style, tone and usage. The developers have recently received $6 million in venture capital, which is indicative that the technology has potential in business and revenue-generating applications.
AI today is increasingly becoming sophisticated in terms of understanding and generating language. AI has gone a long way from spewing out pre-encoded responses from a list of sentences and words in reaction to keywords. Narrative Science can actually compose paragraphs using a human-like voice. The question here is whether the technology will undermine traditional journalism. Will AI simply assist humans in doing research and delivering content? Or, will AI eventually replace human beings in reporting the news, generating editorials and even communicating with other people?
What Does it Mean for Journalism and the Writing Profession?
Perhaps the main indicator here will be cost. Narrative Science charges about $10 each 500-word article, which is not really far from how human copy writers might charge for content. Once this technology becomes popular with newspapers and other publications, will this mean writers and journalists — tech bloggers included — need to find a new career? It seems it’s not just the manufacturing industry that’s prone to being replaced by machines. Maybe we can just input a few keywords like iPhone, iOS, Jailbreak, Touchscreen, Apple and the like, and the Narrative Science app will be able to create an entirely new rumor about the upcoming iPhone 5, for instance!
The potential is great, although the possibility for abuse is also there. Think of spammers and scammers using the software to create more appealing emails that recipients are more likely to act on. Still, with tools like these, it’s only up for us humans to up the ante in terms of quality.
And yes, in case you’re wondering, a real human did write this post.
-----
Personal comments:
One book to read about this: "Exemplaire de démonstration" by Philippe Vasset
Tuesday, August 09. 2011
DNA circuits used to make neural network, store memories
Via ars technica
By Kyle Niemeyer
-----
Even as some scientists and engineers develop improved versions of current computing technology, others are looking into drastically different approaches. DNA computing offers the potential of massively parallel calculations with low power consumption and at small sizes. Research in this area has been limited to relatively small systems, but a group from Caltech recently constructed DNA logic gates using over 130 different molecules and used the system to calculate the square roots of numbers. Now, the same group published a paper in Nature that shows an artificial neural network, consisting of four neurons, created using the same DNA circuits.
The artificial neural network approach taken here is based on the perceptron model, also known as a linear threshold gate. This models the neuron as having many inputs, each with its own weight (or significance). The neuron is fired (or the gate is turned on) when the sum of each input times its weight exceeds a set threshold. These gates can be used to construct compact Boolean logical circuits, and other circuits can be constructed to store memory.
As we described in the last article on this approach to DNA computing, the authors represent their implementation with an abstraction called "seesaw" gates. This allows them to design circuits where each element is composed of two base-paired DNA strands, and the interactions between circuit elements occurs as new combinations of DNA strands pair up. The ability of strands to displace each other at a gate (based on things like concentration) creates the seesaw effect that gives the system its name.
In order to construct a linear threshold gate, three basic seesaw gates are needed to perform different operations. Multiplying gates combine a signal and a set weight in a seesaw reaction that uses up fuel molecules as it converts the input signal into output signal. Integrating gates combine multiple inputs into a single summed output, while thresholding gates (which also require fuel) send an output signal only if the input exceeds a designated threshold value. Results are read using reporter gates that fluoresce when given a certain input signal.
To test their designs with a simple configuration, the authors first constructed a single linear threshold circuit with three inputs and four outputs—it compared the value of a three-bit binary number to four numbers. The circuit output the correct answer in each case.
For the primary demonstration on their setup, the authors had their linear threshold circuit play a computer game that tests memory. They used their approach to construct a four-neuron Hopfield network, where all the neurons are connected to the others and, after training (tuning the weights and thresholds) patterns can be stored or remembered. The memory game consists of three steps: 1) the human chooses a scientist from four options (in this case, Rosalind Franklin, Alan Turing, Claude Shannon, and Santiago Ramon y Cajal); 2) the human “tells” the memory network the answers to one or more of four yes/no (binary) questions used to identify the scientist (such as, “Did the scientist study neural networks?” or "Was the scientist British?"); and 3) after eight hours of thinking, the DNA memory guesses the answer and reports it through fluorescent signals.
They played this game 27 total times, for a total of 81 possible question/answer combinations (34). You may be wondering why there are three options to a yes/no question—the state of the answers is actually stored using two bits, so that the neuron can be unsure about answers (those that the human hasn't provided, for example) using a third state. Out of the 27 experimental cases, the neural network was able to correctly guess all but six, and these were all cases where two or more answers were not given.
In the best cases, the neural network was able to correctly guess with only one answer and, in general, it was successful when two or more answers were given. Like the human brain, this network was able to recall memory using incomplete information (and, as with humans, that may have been a lucky guess). The network was also able to determine when inconsistent answers were given (i.e. answers that don’t match any of the scientists).
These results are exciting—simulating the brain using biological computing. Unlike traditional electronics, DNA computing components can easily interact and cooperate with our bodies or other cells—who doesn’t dream of being able to download information into your brain (or anywhere in your body, in this case)? Even the authors admit that it’s difficult to predict how this approach might scale up, but I would expect to see a larger demonstration from this group or another in the near future.
Quicksearch
Popular Entries
- The great Ars Android interface shootout (131507)
- Norton cyber crime study offers striking revenue loss statistics (102396)
- MeCam $49 flying camera concept follows you around, streams video to your phone (100519)
- The PC inside your phone: A guide to the system-on-a-chip (58696)
- Norton cyber crime study offers striking revenue loss statistics (58625)
Categories

Show tagged entries
Syndicate This Blog
Calendar
|
|
July '26 | |||||
| Mon | Tue | Wed | Thu | Fri | Sat | Sun |
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 | ||