The Intel® HTML5 App Porter Tool - BETA is an application
that helps mobile application developers to port native iOS* code into
HTML5, by automatically translating portions of the original code into
HTML5. This tool is not a complete solution to automatically port 100%
of iOS* applications, but instead it speeds up the porting process by
translating as much code and artifacts as possible.
It helps in the translation of the following artifacts:
Objective-C* (and a subset of C) source code into JavaScript
iOS* API types and calls into JavaScript/HTML5 objects and calls
Layouts of views inside Xcode* Interface Builder (XIB) files into HTML + CSS files
Xcode* project files into Microsoft* Visual Studio* 2012 projects
This document provides a high-level explanation about how the
tool works and some details about supported features. This overview will
help you determine how to process the different parts of your project
and take the best advantage from the current capabilities.
How does it work?
The Intel® HTML5 App Porter Tool - BETA is essentially a
source-to-source translator that can handle a number of conversions from
Objective-C* into JavaScript/HTML5 including the translation of APIs
calls. A number of open source projects are used as foundation for the
conversion including a modified version of Clang front-end, LayerD framework and jQuery Mobile for widgets rendering in the translated source code.
Translation of Objective-C into JavaScript
At a high level, the transformation pipeline looks like this:
This pipeline follows the following stages:
Parsing of Objective-C* files into an intermediate AST (Abstract Syntax Tree).
Mapping of supported iOS* API calls into equivalent JavaScript calls.
Generation of placeholder definitions for unsupported API calls.
Final generation of JavaScript and HTML5 files.
About coverage of API mappings
Mapping APIs from iOS* SDK into JavaScript is a task that involves a
good deal of effort. The iOS* APIs have thousands of methods and
hundreds of types. Fortunately, a rather small amount of those APIs are
in fact heavily used by most applications. The graph below conceptually
shows how many APIs need to be mapped in order to have certain level of
translation for API calls .
Currently, the Intel® HTML5 App Porter Tool - BETA supports the most used types and methods from:
UIKit framework
Foundation framework
Additionally, it supports a few classes of other frameworks such
as CoreGraphics. For further information on supported APIs refer to the
list of supported APIs.
Generation of placeholder definitions and TODO JavaScript files
For the APIs that the Intel® HTML5 App Porter Tool - BETA
cannot translate, the tool generates placeholder functions in "TODO"
files. In the translated application, you will find one TODO file for
each type that is used in the original application and which has API
methods not supported by the current version. For example, in the
following portion of code:
If property setter for showsTouchWhenHighligthed is not supported by the tool, it will generate the following placeholder for you to provide its implementation:
These placeholders are created for methods, constants, and types that
the tool does not support. Additionally, these placeholders may be
generated for APIs other than the iOS* SDK APIs. If some files from the
original application (containing class or function definitions) are not
included in the translation process, the tool may also generate
placeholders for the definitions in those missing files.
In each TODO file, you will find details about where those types,
methods, or constants are used in the original code. Moreover, for each
function or method the TODO file includes information about the type of
the arguments that were inferred by the tool. Using these TODO files,
you can complete the translation process by the providing the
placeholders with your own implementation for that API.
Translation of XIB files into HTML/CSS code
The Intel® HTML5 App Porter Tool - BETA translates most of the definitions in the Xcode* Interface Builder files (i.e.,
XIB files) into equivalent HTML/CSS code. These HTML files use JQuery*
markup to define layouts equivalent to the views in the original XIB
files. That markup is defined based on the translated version of the
view classes and can be accessed programmatically. Moreover, most
of the events that are linked with handlers in the original application
code are also linked with their respective handles in the translated
version. All the view controller objects, connection logic between
objects and event handlers from all translated XIB files are included in
the XibBoilerplateCode.js. Only one XibBoilerplateCode.js file is created per application.
The figure below shows how the different components of each XIB file are translated.
This is a summary of the artifacts generated from XIB files:
For each view inside an XIB file, a pair of HTML+CSS files is generated.
Objects inside XIB files, such as Controllers and Delegates, and instantiation code are generated in the XibBoilerplateCode.js file.
Connections between objects and events handlers for views described
inside XIB files are also implemented by generated code in the XibBoilerplateCode.js file.
The translated application keeps the very same high level structure
as the original one. Constructs such as Objective-C* interfaces,
categories, C structs, functions, variables, and statements are kept
without significant changes in the translated code but expressed in
JavaScript.
The execution of the Intel® HTML5 App Porter Tool – BETA produces a set of files that can be divided in four groups:
The translated app code: These are the JavaScript files that were created as a translation from the original app Objective-C* files.
For each translated module (i.e. each .m file) there should be a .js file with a matching name.
The default.html file is the entry point for the HTML5 app, where all the other .js files are included.
Additionally, there are some JavaScript files included in the \lib folder that corresponds to some 3rd party libraries and Intel® HTML5 App Porter Tool – BETA library which implements most of the functionality that is not available in HTML5.
Translated .xib files (if any): For each translated .xib file there should be .html and .css files with matching names. These files correspond to their HTML5 version.
“ToDo” JavaScript files: As the translation of some of the
APIs in the original app may not be supported by the current version,
empty definitions as placeholders for those not-mapped APIs are
generated in the translated HTML5 app. This “ToDo” files contain those
placeholders and are named after the class of the not-mapped APIs. For
instance, the placeholders for not-mapped methods of the NSData class, would be located in a file named something like todo_api_js_apt_data.js or todo_js_nsdata.js.
Resources: All the resources from the original iOS* project will be copied to the root folder of the translated HTML5 app.
The generated JavaScript files have names which are practically the
same as the original ones. For example, if you have a file called AppDelegate.m in the original application, you will end up with a file called AppDelegate.js
in the translated output. Likewise, the names of interfaces, functions,
fields, or variables are not changed, unless the differences between
Objective-C* and JavaScript require the tool to do so.
In short, the high level structure of the translated application is
practically the same as the original one. Therefore, the design and
structure of the original application will remain the same in the
translated version.
About target HTML5 APIs and libraries
The Intel® HTML5 App Porter Tool - BETA both translates the
syntax and semantics of the source language (Objective-C*) into
JavaScript and maps the iOS* SDK API calls into an equivalent
functionality in HTML5. In order to map iOS* API types and calls into
HTML5, we use the following libraries and APIs:
The standard HTML5 API: The tool maps iOS*
types and calls into plain standard objects and functions of HTML5 API
as its main target. Most notably, considerable portions of supported
Foundation framework APIs are mapped directly into standard HTML5. When
that is not possible, the tool provides a small adaptation layer as part
of its library.
The jQuery Mobile library: Most of the UIKit
widgets are mapped jQuery Mobile widgets or a composite of them and
standard HTML5 markup. Layouts from XIB files are also mapped to jQuery
Mobile widgets or other standard HTML5 markup.
The Intel® HTML5 App Porter Tool - BETA library:
This is a 'thin-layer' library build on top of jQuery Mobile and HTML5
APIs and implements functionality that is no directly available in those
libraries, including Controller objects, Delegates, and logic to
encapsulate jQuery Mobile widgets. The library provides a facade very
similar to the original APIs that should be familiar to iOS* developers.
This library is distributed with the tool and included as part of the
translated code in the lib folder.
You should expect that future versions of the tool will incrementally
add more support for API mapping, based on further statistical analysis
and user feedback.
Translated identifier names
In Objective-C*, methods names can be composed by several parts
separated with colons (:) and the methods calls interleaved these parts
with the actual arguments. Since that peculiar syntactic construct is
not available in JavaScript, those methods names are translated by
combining all the methods parts replacing the colons (:) with
underscores (_). For example, a function called initWithColor:AndBackground: is translated to use the name initWithColor_AndBackground
Identifier names, in general, may also be changed in the translation
if there are any conflicts in JavaScript scope. For example, if you have
duplicated names for interfaces and protocol, or one instance method
and one class method that share the same name in the same interface.
Because identifier scoping rules are different in JavaScript, you cannot
share names between fields, methods, and interfaces. In any of those
cases, the tool renames one of the clashing identifiers by prepending an
underscore (_) to the original name.
Additional tips to get the most out of the Intel® HTML5 App Porter Tool – BETA
Here is a list of recommendations to make the most of the tool.
Keep your code modular Having a
well-designed and architected source code may help you to take the most
advantage of the translation performed by tool. If the modules of the
original source code can be easily decoupled, tested, and refactored the
same will be true for the translated code. Having loosely coupled
modules in your original application allows you to isolate the modules
that are not translated well into JavaScript. In this way, you should be
able to simply skip those modules and only select the ones suitable for
translation.
Avoid translating third party libraries source code with equivalents in JavaScript
For some iOS* libraries you can find replacement libraries or APIs in
JavaScript. Common examples are libraries to parse JSON, libraries to
interact with social networks, or utilities libraries such as Box2D* for
games development. If your project originally uses the source code of
third party library which has a replacement version in JavaScript, try
to use the replacement version instead of translated code, whenever it
is possible.
Isolate low level C or any C++ code behind Objective-C* interfaces:
The tool currently supports translating from Objective-C*, only. It
covers the translation of most of C language constructs, but it does not
support some low level features such as unions, pointers, or bit
fields. Moreover, the current version does not support C++ or
Objective-C++ code. Because of this limitation, it is advisable to
encapsulate that code behind Objective-C interfaces to facilitate any
additional editing, after running the tool.
In conclusion, having a well-designed application in the first place
will make your life a lot easier when porting your code, even in a
completely manual process.
Further technical information
This section provides additional information for developers and it is not required to effectively use Intel® HTML5 App Porter Tool - BETA. You can skip this section if you are not interested in implementation details of the tool.
Implementation of the translation steps
Here, you can find some high level details of how the different processing steps of the Intel® HTML5 App Porter Tool - BETA are implemented.
Objective-C* and C files parsing
To parse Objective-C* files, the tool uses a modified version of clang parser. A custom version of the parser is needed because:
iOS* SDK header files are not available.
clang is only used to parse the source files (not to compile them) and dump the AST to disk.
The following picture shows the actual detailed process for parsing .m and .c files:
Missing iOS* SDK headers are inferred as part of the parsing process.
The header inference process is heuristic, so you may get parsing
errors, in some cases. Thus, you can help the front-end of the tool by
providing forward declaration of types or other definitions in header
files that are accessible to the tool.
Also, you can try the "Header Generator" module in individual files
by using the command line. In the binary folder of the tool, you will
find an executable headergenerator.exe that rubs that process.
Objective-C* language transformation into JavaScript
The translation of Objective-C* language into JavaScript involves a
number of steps. We can divide the process in what happens in the
front-end and what is in the back-end.
Steps in the front-end:
Parsing .m and .c into an XML AST.
Parsing comments from .m, .c and .h files and dumping comments to disk.
Translating Clang AST into Zoe AST and re-appending the comments.
The output of the front-end is a Zoe program. Zoe is an
intermediate abstract language used by LayerD framework; the engine that
is used to apply most of the transformations.
The back-end is fully implemented in LayerD by using compile time
classes of Zoe language that apply a number of transformations in the
AST.
Steps in the back-end:
Handling some Objective-C* features such as properties getter/setter injection and merging of categories into Zoe classes.
Supported iOS* API conversion into target JavaScript API.
Injection of not supported API types, or types that were left outside of the translation by the user.
Injection of dummy methods for missing API transformations or any other code left outside of the translation by the user.
JavaScript code generation.
iOS* API mapping into JavaScript/HTML5
The tool supports a limited subset of iOS* API. That subset is
developed following statistical information about usage of each API.
Each release of the tool will include support for more APIs. If you miss
a particular kind of API your feedback about it will be very valuable
in our assessment of API support.
For some APIs such as Arrays and Strings the tool provides direct
mappings into native HTML5 objects and methods. The following table
shows a summary of the approach followed for each kind of currently
supported APIs.
Framework
Mapping design guideline
Foundation
Direct mapping to JavaScript when possible. If direct mapping is not possible, use a new class built over standard JavaScript.
Core Graphics
Direct mapping to Canvas and related HTML5 APIs when possible. If
direct mapping is not possible, use a new class built over standard
JavaScript.
UIKit Views
Provide a similar class in package APT, such as APT.View for UIView,
APT.Label for UILabel, etc. All views are implemented using jQuery
Mobile markup and library. When there are not equivalent jQuery widgets
we build new ones in the APT library.
UIKit Controllers and Delegates
Because HTML5 does not provide natively controllers or delegate
objects the tool provides an implementation of base classes for
controllers and delegates inside the APT package.
Direct mapping implies that the original code
will be transformed into plain JavaScript without any type of additional
layer. For example,
The entire API mapping happens in the back-end of the tool. This
process is implemented using compile time classes and other
infrastructure provided by the LayerD framework.
XIB files conversion into HTML/CSS
XIB files are converted in two steps:
XIB parsing and generation of intermediate XML files.
Intermediate XML files are converted into final HTML, CSS and JavaScript boilerplate code.
The first step generates one XML file - with extension .gld -
for each view inside the XIB file and one additional XML file with
information about other objects inside XIB files and connections between
objects and views such as outlets and event handling.
The second stage runs inside the Zoe compiler of LayerD to convert
intermediate XML files into final HTML/CSS and JavaScript boilerplate
code to duplicate all the functionality that XIB files provides in the
original project.
Generated HTML code is as similar as possible to static markup used
by jQuery Mobile library or standard HTML5 markup. For widgets that do
not have an equivalent in jQuery Mobile, HTML5, or behaves differently,
simple markup is generated and handled by classes in APT library.
Supported iOS SDK APIs for Translation
The following table details the APIs supported by the current version of the tool.
Notes:
Types refers to Interfaces, Protocols, Structs, Typedefs or Enums
Type 'C global' mean that it is not a type, but it is a supported global C function or constant
Colons in Objective-C names are replaced by underscores
Objective-C properties are detailed as a pair of getter/setter method names such as 'title' and 'setTitle'
Objective-C static members appear with a prefixed underscore like in '_dictionaryWithObjectsAndKeys'
Inherited members are not listed, but are supported. For example,
NSArray supports the 'count' method. The method 'count' is not listed in
NSMutableArray, but it is supported because it inherits from NSArray
These are the top NoSQL Solutions in the market today that are open
source, readily available, with a strong and active community, and
actively making forward progress in development and innovations in the
technology. I’ve provided them here, in no order, with basic
descriptions, links to their main website presence, and with short lists
of some of their top users of each database. Toward the end I’ve
provided a short summary of the database and the respective history of
the movement around No SQL and the direction it’s heading today.
Cassandra is a distributed databases that offers high availability
and scalability. Cassandra supports a host of features around
replicating data across multiple datacenters, high availability,
horizontal scaling for massive linear scaling, fault tolerance and a
focus, like many NoSQL solutions around commodity hardware.
Cassandra is a hybrid key-value & row based database, setup on
top of a configuration focused architecture. Cassandra is fairly easy to
setup on a single machine or a cluster, but is intended for use on a
cluster of machines. To insure the availability of features around fault
tolerance, scaling, et al you will need to setup a minimal cluster, I’d
suggest at least 5 nodes (5 nodes being my personal minimum clustered
database setup, this always seems to be a solid and safe minimum).
Cassandra also has a query language called CQL or Cassandra Query
Langauge. Cassandra also support Apache Projects Hive, Pig with Hadoop
integration for map reduce.
In the book, Seven Databases in Seven Weeks,
the Apache HBase Project is described as a nail gun. You would not use
HBase to catalog your sales list just like you wouldn’t use a nail gun
to build a dollhouse. This is an apt description of HBase.
HBase is a column-oriented database. It’s very good at scaling out. The origins of HBase are rooted in BigTable by Google.
The proprietary database is described in in the 2006 white paper,
“Bigtable: A Distributed Storage System for Structured Data.”
HBase stores data in buckets called tables, the tables contain cells
that are at the intersection of rows and columns. Because of this HBase
has a lot of similar characteristics to a relational database. However
the similarities are only in name.
HBase also has several features that aren’t available in other
databases, such as; versioning, compression, garbage collection and in
memory tables. One other feature that is usually only available in
relational databases is strong consistency guarantees.
The place where HBase really shines however is in queries against enormous datasets.
HBase is designed architecturally to be fault tolerate. It does this
through write-ahead logging and distributed configuration. At the core
of the architecture HBase is built on Hadoop. Hadoop is a sturdy,
scalable computing platform that provides a distribute file system and
mapreduce capabilities.
Who is using it?
Facebook uses HBase for its messaging infrastructure.
Stumpleupon uses it for real-time data storage and analytics.
Twitter uses HBase for data generation around people search & storing logging & monitoring data.
Meetup uses it for site data.
There are many others including Yahoo!, eBay, etc.
MongoDB is built and maintained by a company called 10gen. MongoDB
was released in 2009 and has been rising in popularity quickly and
steadily since then. The name, contrary to the word mongo, comes from
the word humongous. The key goals behind MongoDB are performance and
easy data access.
The architecture of MongoDB is around document database principles.
The data can be queried in an ad-hoc way, with the data persisted in a
nested way. This database also, like most NoSQL databases enforces no
schema, however can have specific document fields that can be queried
off of.
Who is using it?
Foursquare
bit.ly
CERN for collecting data from the large Hadron Collider
Redis stands for Remote Dictionary Service. The most common
capability Redis is known for, is blindingly fast speed. This speed
comes from trading durability. At a base level Redis is a key-value
store, however sometimes classifying it isn’t straight forward.
Redis is a key-value store, and often referred to as a data structure
server with keys that can be string, hashes, lists, sets and sorted
sets. Redis is also, stepping away from only being a key-value store,
into the realm of being a publish-subscribe and queue stack. This makes
Redis one very flexible tool in the tool chest.
Who is using it?
Blizzard (You know, that World of Warcraft game maker) ;)
Another Apache Project, CouchDB is the idealized JSON and REST
document database. It works as a document database full of key-value
pairs with the values a set number of types including nested with other
key-value objects.
The primary mode of querying CouchDB is to use incremental mapreduce to produce indexed views.
One other interesting characteristic about CouchDB is that it’s built
with the idea of a multitude of deployment scenarios. CouchDB might be
deployed to some big servers or may be a mere service running on your
Android Phone or Mac OS-X Desktop.
Like many NoSQL options CouchDB is RESTful in operation and uses JSON to send data to and from clients.
The Node.js Community also has an affinity for Couch since NPM and a
lot of the capabilities of Couch seem like they’re just native to
JavaScript. From the server aspect of the database to the JSON format
usage to other capabilities.
Who uses it?
NPM – Node Package Manager site and NPM uses CouchDB for storing and providing the packages for Node.js.
Couchbase (UPDATED January 18th)
Ok, I realized I’d neglected to add Couchbase (thus
the Jan 18th update), which is an open source and interesting solution
built off of Membase and Couch. Membase isn’t particularly a distributed
database, or database, but between it and couch joining to form
Couchbase they’ve turned it into a distributed database like couch
except with some specific feature set differences.
A lot of the core architecture features of Couch are available, but
the combination now adds auto-sharding clusters, live/hot swappable
upgrades and changes, memchaced APIs, and built in data caching.
Neo4j steps away from many of the existing NoSQL databases with its
use of a graph database model. It stored data as a graph, mathematically
speaking, that relates to the other data in the database. This
database, of all the databases among the NoSQL and SQL world, is very
whiteboard friendly.
Neo4j also has a varied deployment model, being able to deploy to a
small or large device or system. It has the ability to store dozens of
billions of edges and nodes.
Who is using it?
Accenture
Adobe
Lufthansa
Mozilla
…others…
Riak
Riak is a key-value, distributed, fault tolerant, resilient database
written in Erlang. It uses the Riak Core project as a codebase for the
distributed core of the system. I further explained Riak, since yes, I
work for Basho who are the makers of Riak, in a separate blog entry “Riak is… A Big List of Things“. So for a description of the features around Riak check that out.
One of the things you’ll notice with a lot of these databases and the
NoSQL movement in general is that it originated from companies needing
to go “web scale” and RDBMSs just couldn’t handle or didn’t meet the
specific requirements these companies had for the data. NoSQL is in no
way a replacement to relational or SQL databases except in these
specific cases where need is outside of the capability or scope of SQL
& Relational Databases and RDBMSs.
Almost every NoSQL database has origins that go pretty far back, but
the real impetus and push forward with the technology came about with
key efforts at Google and Amazon Web Services. At Google it was with BigTable Paper and at Amazon Web Services it was with the Dynamo Paper.
As time moved forward with the open source community taking over as the
main innovator and development model around big data and the NoSQL
database movement. Today the Apache Project has many of the projects
under its guidance along with other companies like Basho and 10gen.
In the last few years, many of the larger mainstays of the existing
database industry have leapt onto the bandwagon. Companies like Microsoft, Dell, HP and Oracle
have made many strategic and tactical moves to stay relevant with this
move toward big data and nosql databases solutions. However, the
leadership is still outside of these stalwarts and in the hands of the
open source community. The related companies and organizations that are
focused on that community such as 10gen, Basho and the Apache
Organization still hold much of the future of this technology in the
strategic and tactical actions that they take since they’re born from
and significant parts of the community itself.
For an even larger list of almost every known NoSQL Database in existence check out NoSQL Database .org.
Researchers have created software that predicts when and where disease outbreaks might occur based on two decades of New York Times articles and other online data. The research comes from Microsoft and the Technion-Israel Institute of Technology.
The system could someday help aid organizations and others be more
proactive in tackling disease outbreaks or other problems, says Eric Horvitz,
distinguished scientist and codirector at Microsoft Research. “I truly
view this as a foreshadowing of what’s to come,” he says. “Eventually
this kind of work will start to have an influence on how things go for
people.” Horvitz did the research in collaboration with Kira Radinsky, a PhD researcher at the Technion-Israel Institute.
The system provides striking results when tested on historical data.
For example, reports of droughts in Angola in 2006 triggered a warning
about possible cholera outbreaks in the country, because previous events
had taught the system that cholera outbreaks were more likely in years
following droughts. A second warning about cholera in Angola was
triggered by news reports of large storms in Africa in early 2007; less
than a week later, reports appeared that cholera had become established.
In similar tests involving forecasts of disease, violence, and a
significant numbers of deaths, the system’s warnings were correct
between 70 to 90 percent of the time.
Horvitz says the performance is good enough to suggest that a more
refined version could be used in real settings, to assist experts at,
for example, government aid agencies involved in planning humanitarian
response and readiness. “We’ve done some reaching out and plan to do
some follow-up work with such people,” says Horvitz.
The system was built using 22 years of New York Times archives, from 1986 to 2007, but it also draws on data from the Web to learn about what leads up to major news events.
“One source we found useful was DBpedia,
which is a structured form of the information inside Wikipedia
constructed using crowdsourcing,” says Radinsky. “We can understand, or
see, the location of the places in the news articles, how much money
people earn there, and even information about politics.” Other sources
included WordNet, which helps software understand the meaning of words, and OpenCyc, a database of common knowledge.
All this information provides valuable context that’s not available
in news article, and which is necessary to figure out general rules for
what events precede others. For example, the system could infer
connections between events in Rwandan and Angolan cities based on the
fact that they are both in Africa, have similar GDPs, and other factors.
That approach led the software to conclude that, in predicting cholera
outbreaks, it should consider a country or city’s location, proportion
of land covered by water, population density, GDP, and whether there had
been a drought the year before.
Horvitz and Radinsky are not the first to consider using online news
and other data to forecast future events, but they say they make use of
more data sources—over 90 in total—which allows their system to be more
general-purpose.
There’s already a small market for predictive tools. For example, a startup called Recorded Future
makes predictions about future events harvested from forward-looking
statements online and other sources, and it includes government
intelligence agencies among its customers (see “See the Future With a Search”).
Christopher Ahlberg, the company’s CEO and cofounder, says that the new
research is “good work” that shows how predictions can be made using
hard data, but also notes that turning the prototype system into a
product would require further development.
Microsoft doesn’t have plans to commercialize Horvitz and Radinsky’s
research as yet, but the project will continue, says Horvitz, who wants
to mine more newspaper archives as well as digitized books.
Many things about the world have changed in recent decades, but human
nature and many aspects of the environment have stayed the same,
Horvitz says, so software may be able to learn patterns from even very
old data that can suggest what’s ahead. “I’m personally interested in
getting data further back in time,” he says.
Miss your Amiga? Now you can play Prince of Persia, Pinball Dreams and other Amiga hits right in your web browser thanks to the Scripted Amiga Emulator, an Amiga emulator written entirely in JavaScript and HTML5.
To view the emulator, which was written by developer Rupert
Hausberger, you’ll need a browser with support for WebGL and WebAudio,
as well as a few other HTML5 APIs. I tested the emulator in the latest
version of both Chrome and Firefox and it worked just fine.
If you’d like to see the code behind the Scripted Amiga Emulator, head on over to GitHub.
At Velocity 2011, Nicole Sullivan and I introduced CSS Lint,
the first code-quality tool for CSS. We had spent the previous two
weeks coding like crazy, trying to create an application that was both
useful for end users and easy to modify. Neither of us had any
experience launching an open-source project like this, and we learned a
lot through the process.
After some initial missteps, the project finally hit a groove, and it
now regularly get compliments from people using and contributing to CSS
Lint. It’s actually not that hard to create a successful open-source
project when you stop to think about your goals.
(Smashing’s note: Subscribe to the Smashing eBook Library and get immediate unlimited access
to all Smashing eBooks, released in the past and in the future,
including digital versions of our printed books. At least 24 quality
eBooks a year, 60 eBooks during the first year. Subscribe today!)
What Are Your Goals?
These days, it seems that anybody who writes a piece of code ends up
pushing it to GitHub with an open-source license and says, “I’ve
open-sourced it.” Creating an open-source project isn’t just about
making your code freely available to others. So, before announcing to
the world that you have open-sourced something that hasn’t been used by
anyone other than you in your spare time, stop to ask yourself what your
goals are for the project.
The first goal is always to create something useful.
For CSS Lint, our goal was to create an extensible tool for CSS code
quality that could easily fit into a developer’s workflow, whether the
workflow is automated or not. Make sure that what you’re offering is
useful by looking for others who are doing similar projects and figuring
out how large of a user base you’re looking at.
After that, decide why you are open-sourcing the project in the first
place. Is it because you just want to share what you’ve done? Do you
intend to continue developing the code, or is this just
a snapshot that you’re putting out into the world? If you have no
intention of continuing to develop the code, then the rest of this
article doesn’t apply to you. Make sure that the readme file in your
repository states this clearly so that anyone who finds your project
isn’t confused.
If you are going to continue developing the code, do you want to accept contributions
from others? If not, then, once again, this article doesn’t apply to
you. If yes, then you have some work to do. Creating an open-source
project that’s conducive to outside contributions is more work than it
seems. You have to create environments in which those who are unfamiliar
with the project can get up to speed and be productive reasonably
quickly, and that takes some planning.
This article is about starting an open-source project with these goals:
Create something useful for the world.
Continue to develop the code for the foreseeable future.
Accept outside contributions.
Choosing A License
Before you share your code, the most important decision to make is
what license to apply. The open-source license that you choose could
greatly help or hurt your chances of attracting contributors. All
licenses allow you to retain the copyright of the code you produce.
While the concept of licensing is quite complex, there are a few common
licenses and a few basic things you should know about each. (If you are
open-sourcing a project on behalf of a company, please speak to your
legal counsel before choosing a license.)
GPL
The GNU Public License was created for the GNU project and has been
credited with the rise of Linux as a viable operating system. The GPL
license requires that any project using a GPL-licensed component must
also be made available under the GPL. To put it simply, any project
using a GPL-licensed component in any way must also be open-sourced
under the GPL. There is no restriction on the use of GPL-licensed
applications; the restriction only has to do with the modification and
distribution of derived works.
LGPL
The Lesser GPL is a slightly more permissive version of GPL. An
LGPL-licensed component may be linked to from an application without the
application itself needing to be open-sourced under GPL or LGPL. In all
other ways, LGPL is the same as GPL, so any derived works must also be
open-sourced under GPL or LGPL.
MIT
Also called X11, this licence is permissive, allowing for the use and
redistribution of code so long as the license and copyright are included
along with it. MIT-licensed code may be included in proprietary code
without any additional restrictions. Additionally, MIT-licensed code is
GPL-compatible and can be combined with such code to create new
GPL-licensed applications.
BSD3
This is also a permissive license that allows for the use and
redistribution of code as long as the license and copyright are included
with it. In addition, any redistribution of the code in binary form
must include a license and copyright in its available documentation. The
clause that sets BSD3 apart from MIT is the prohibition of using the
copyright holder’s name to promote a product that uses the code. For
example, if I wrote some code and licensed it under BSD3, then an
application that uses that code couldn’t use my name to promote the
product without my permission. BSD3-licensed code is also compatible
with GPL.
There are many other open-source licenses, but these tend to be the most commonly discussed and used.
One thing to keep in mind is that Creative Commons licenses are not
designed to be used with software. All of the Creative Commons licenses
are intended for “creative work,” including audio, images, video and
text. The Creative Commons organization itself recommends
not using Creative Commons licenses for software and instead to use
licenses that have been specifically formulated to cover software, as is
the case with the four options discussed above.
So, which license should you choose? It largely
depends on how you intend your code to be used. Because LGPL, MIT and
BSD3 are all compatible with GPL, that’s not a major concern. If you
want any modified versions of your code to be used only in open-source
software, then GPL is the way to go. If your code is designed to be a
standalone component that may be included in other applications without
modification, then you might want to consider LGPL. Otherwise, the MIT
or BSD3 licenses are popular choices. Individuals tend to favor the MIT
license, while businesses tend to favor BSD3 to ensure that their
company name can’t be used without permission.
To help you decide, look at how some popular open-source projects are licensed:
Another option is to release your code into the public domain.
Public-domain code has no copyright owner and may be used in absolutely
any way. If you have no intention of maintaining control over your code
or you just want to share your code with the world and not continue to
develop it, then consider releasing it into the public domain.
To learn more about licenses, their associated legal issues and how licensing actually works, please read David Bushell’s “Understanding Copyright and Licenses.”
Code Organization
After deciding how to license your open-source project, it’s almost
time to push your code out into the world. But before doing that, look
at how the code is organized. Not all code invites contributions.
If a potential contributor can’t figure out how to read through the
code, then it’s highly unlikely any contribution will emerge. The way
you lay out the code, in terms of file and directory structure as well
as coding style, is a key aspect to consider before sharing it publicly.
Don’t just throw out whatever code you have been writing into the wild;
spend some time figuring out how others will view your code and what
questions they might have.
For CSS Lint, we decided on a basic top-level directory structure of src for source code, lib for external dependencies, and tests for all test code. The src directory is further subdivided into directories that group together related files. All CSS Lint rules are in the rules subdirectory; all output formatters are in the formatters directory; etc. The tests directory is split up into the same subdirectories as src,
thereby indicating the relationship between the test code and the
source code. Over time, we’ve added top-level directories as needed, but
the same basic structure has been in place since the beginning.
Documentation
One of the biggest complaints about open-source projects is the lack
of documentation. Documentation isn’t as fun or exciting as writing
executable code, but it is critical to the success of an open-source
project. The best way to discourage use of and contributions to your
software is to have no documentation. This was an early mistake we made
with CSS Lint. When the project launched, we had no documentation, and
everyone was confused about how to use it. Don’t make the same mistake:
get some documentation ready before pushing the project live.
The documentation should be easy to update and shouldn’t require a
code push, because it will need to be changed very quickly in response
to user feedback. This means that the best place for documentation isn’t
in the same repository as the code. If your code is hosted on GitHub,
then make use of the built-in wiki for each project. All of the CSS Lint documentation
is in a GitHub wiki. If your code is hosted elsewhere, consider setting
up your own wiki or a similar system that enables you to update the
documentation in real time. A good documentation system must be easy to
update, or else you will never update it.
End-User Documentation
Whether you’re creating a command-line program, an application
framework, a utility library or anything else, keep the end user in
mind. The end user is not the person who will be modifying the code;
it’s the one who will be using the code. People were initially confused
about CSS Lint’s purpose and how to use it effectively because of the
lack of documentation. Your project will never gain contributors without
first gaining end users. Satisfied end users are the ones who will end
up becoming contributors because they see the value in what you’ve
created.
Developer Guide
Even if you’ve laid out the code in a logical manner and have decent
end-user documentation, contributions are not guaranteed to start
flowing. You’ll need a developer guide to help get contributors up and
running as quickly as possible. A good developer guide covers the
following:
How to get the source code
Yes, you would hope that contributors would be familiar with how to
check out and clone a repository, but that’s not always the case. A
gentle introduction to getting the source code is always appreciated.
How the code is laid out
Even though the code and directory structures should be fairly
self-explanatory, writing down a description for posterity always helps.
How to set up the build system
If you are using a build system, then you’ll need to include
instructions on how to set it up. These instructions should include
where to get build-time dependencies that aren’t already included in the
repository.
How to run a build
These are the steps necessary to run a development build and to execute unit tests.
How to contribute
Spell out the criteria for contributing to the project. If you require
unit tests, then state that. If you require documentation, mention that
as well. Give people a checklist of things to go over before submitting a
contribution.
I spent a lot of time refining the “CSS Lint Developer Guide”
based on conversations I had had with contributors and questions that
others would ask. As with all documentation, the developer guide should
be a living document that continues to grow as the project grows.
Use A Mailing List
All good open-source projects give people a place to go to ask
questions, and the easiest way to achieve that is by setting up a
mailing list. When we first launched CSS Lint, Nicole and I were
inundated with questions. The problem is that those questions were
coming in through many different channels. People were asking questions
on Twitter as well as emailing each of us directly. That’s exactly the
situation you don’t want.
Setting up a mailing list with Yahoo Groups or Google Groups
is easy and free. Make sure to do that before announcing the project’s
availability, and actively encourage people to use the mailing list to
ask questions. Link to the mailing list prominently on the website (if
you have one) or in the documentation.
The other important part of running a mailing list is to actively
monitor it. Nothing is more frustrating for end users or contributors
than being ignored. If you’ve set up a mailing list, take the time to
monitor it and respond to people who ask questions.
This is the best way to foster a community of developers around the
project. Getting a decent amount of traffic onto the mailing list can
take some time, but it’s worth the effort. Offer advice to people who
want to contribute; suggest to people to file tickets when appropriate
(don’t let the mailing list turn into a bug tracker!); and use the
feedback you get from the mailing list to improve documentation.
Use Version Numbers
One common mistake made with open-source projects is neglecting to
use version numbers. Version numbers are incredibly important for the
long-term stability and maintenance of your project. CSS Lint didn’t use
version numbers when it was first released, and I quickly realized the
mistake. When bugs came in, I had no idea whether people were using the
most recent version because there was no way for them to tell when the
code was released. Bugs were being reported that had already been fixed,
but there was no way for the end user to figure that out.
Stamping each release with an official version number puts a stake in
the ground. When somebody files a bug, you can ask what version they
are using and then check whether that bug has already been fixed. This
greatly reduced the amount of time I spent with bug reports because I
was able to quickly determine whether someone was using the most recent
version.
Unless your project has been previously used and vetted, start the
version number at 0.1.0 and go up incrementally with each release. With
CSS Lint, we increased the second number for planned releases; so, 0.2.0
was the second planned release, 0.3.0 was the third and so on. If we
needed to release a version in between planned releases in order to fix
bugs, then we increased the third number. So, the second unplanned
release after 0.2.0 was 0.2.2. Don’t get me wrong: there are no set
rules on how to increase version numbers in a project, though there are a
couple of resources worth looking at: Apache APR Versioning and Semantic Versioning. Just pick something and stick with it.
In addition to helping with tracking, version numbers do a number of other great things for your project.
Tag Versions in Source Control
When you decide on a new release, use a source-control tag to mark
the state of the code for that release. I started doing this for CSS
Lint as soon as we started using version numbers. I didn’t think much of
it until the first time I forgot to tag a release and a bug was filed
by someone looking for that tag. It turns out that developers like to
check out particular versions of code.
Tie the tag obviously to the version number by including the version
number directly in the tag’s name. With CSS Lint, our tags are in the
format of “v0.9.9.” This will make it very easy for anyone looking
through tags to figure out what those tags mean — including you, because
you’ll be able to better keep track of what changes have been made in
each release.
Change Logs
Another benefit of versioning is in producing change logs. Change
logs are important for communicating version differences to both end
users and contributors. The added benefit of tagging versions and source
control is that you can automatically generate change logs based on
those tags. CSS Lint’s build system automatically creates a change log
for each release that includes not just the commit message but also the
contributor. In this way, the change log becomes a record not only of
code changes, but also of contributions from the community.
Availability Announcements
Whenever a new version of the project is available, announce its
availability somewhere. Whether you do this on a blog or on the mailing
list (or in both places), formally announcing that a new version is
available is very important. The announcement should include any major
changes made in the code, as well as who has contributed those changes.
Contributors tend to contribute more if they get some recognition for
their work, so reward the people who have taken the time to contribute
to your project by acknowledging their contribution.
Managing Contributions
Once you have everything set up, the next step is to figure out how
you will accept contributions. Your contribution model can be as
informal or formal as you’d like, depending on your goals. For a
personal project, you might not have any formal contribution process.
The developer guide would lay out what is necessary in order for the
code to be merged into the repository and would state that as long as a
submission follows that format, then the contribution will be accepted.
For a larger project, you might want to have a more formal policy.
The first thing to look into is whether you will require a
contributor license agreement (CLA). CLAs are used in many large
open-source projects to protect the legal rights of the project. Every
person who submits code to the project would need to fill out a CLA
certifying that any contributed code is original work and that the
copyright for that work is being turned over to the project. CLAs also
give the project owner license to use the contribution as part of the
project, and it warrants that the contributor isn’t knowingly including
code to which someone else has a copyright, patent or other right. jQuery, YUI and Dojo
all require CLAs for code submissions. If you are considering requiring
a CLA from contributors, then getting legal advice regarding it and
your licensing structure would be worthwhile.
Next, you may want to establish a hierarchy of people working on the
project. Open-source projects typically have three primary designations:
Contributor
Anyone who has had source code merged into the repository is considered a
contributor. The contributor cannot access the repository directly but
has submitted patches that have been accepted.
Committer
People who have direct access to the repository are committers. These
people work on features and fix bugs regularly, and they submit code
directly to the repository.
Reviewer
The highest level of contributor, reviewers are commanders who also have
directional impact on the project. Reviewers fulfill their title by
reviewing submissions from contributors and committers, approving or
denying patches, promoting or demoting committers, and generally running
the project.
If you’re going to have a formal hierarchy such as this, you’ll need
to draft a document that describes the role of each type of contributor
and how one may be promoted through the ranks. YUI has just created a
formal “Contributor Model,” along with excellent documentation on roles and responsibilities.
At the moment, CSS Lint doesn’t require a CLA and doesn’t have a
formal contribution model in place, but everyone should consider it as
their open-source project grows.
The Proof
It probably took us about six months from its initial release to get
CSS Lint to the point of being a fully functioning open-source project.
Since then, over a dozen contributors have submitted code that is now
included in the project. While that number might seem small by the
standard of a large open-source project, we take great pride in it.
Getting one external contribution is easy; getting contributions over an
extended period of time is difficult.
And we know that we’ve been doing something right because of the
feedback we receive. Jonathan Klein recently took to the mailing list to
ask some questions and ended up submitting a pull request that was
accepted into the project. He then emailed me this feedback:
I just wanted to say that I think CSS Lint is a model open-source
project — great documentation, easy to extend, clean code, fast replies
on the mailing list and to pull requests, and easily customizable to fit
any environment. Starting to do development on CSS Lint was as easy as
reading a couple of wiki pages, and the fact that you explicitly called
out the typical workflow of a change made the barrier to entry extremely
low. I wish more open-source projects would follow suit and make it
easy to contribute.
Getting emails like this has become commonplace for CSS Lint, and it
can become the norm for your project, too, if you take the time to set
up a sustainable eco-system. We all want our projects to succeed, and we
want people to want to contribute to them. As Jonathan said, make the
barrier to entry as low as possible and developers will find ways to
help out.
The team behind the project -
University of Bath, Root6 Technology, Smoke & Mirrors and Ovation
Data Services - are now looking for industry buy-in to the research to
expand its potential applications.
The codec has been launched at this week's CVMP 9th European Conference on
Visual Media Production held at Vue Cinema in Leicester Square, London.
Digital pictures are built from a rectangular grid of coloured cells,
or pixels. The smaller and closer the pixels are together, the better
the quality of the image. Pixel-based movies need huge amounts of
data and have to be compressed, losing quality.
They are also difficult and time consuming to process.
The alternative, a vector-based format, presents the image using
contoured colours. Until now there has not been a way to
choose and fill between the contours at professional quality. The Bath team
has finally solved these problems.
A codec is a computer programme capable of encoding or decoding
a digital video stream. The researchers at Bath have developed
a new, highly sophisticated codec which is able to create and fill between
contours, overcoming the problems preventing their widespread use.
The result is a resolution-independent form of movie or image,
capable of the highest visual quality but without a pixel in sight.
Professor Phil Willis from the University of Bath said: "This is
a significant breakthrough which will revolutionise the way visual
media are produced.
"We already have some great company partners.
To accelerate the project we'll need more companies
from around the world to get involved. At the moment we're
focusing on applications in post-production and we are working
directly with leading companies in this area. However there
are clear applications in web, tablets and mobile which we
haven't explored in detail yet.
"Involvement of a greater variety of companies with
different interests will extend the project in many ways
and increase the potential applications of this
game-changing research."
Contact Details
Phil Willis
Department of Computer Science
University of Bath
Bath BA2 7AY
UK
We describe a novel algorithm for extracting a resolution-independent vector representation from pixel art
images, which enables magnifying the results by an arbitrary amount
without image degradation. Our algorithm resolves pixel-scale features
in the input and converts them into regions with smoothly varying
shading that are crisply separated by piecewise-smooth contour curves.
In the original image, pixels are represented on a square pixel lattice,
where diagonal neighbors are only connected through a single point.
This causes thin features to become visually disconnected under
magnification by conventional means, and it causes connectedness and
separation of diagonal neighbors to be ambiguous. The key to our
algorithm is in resolving these ambiguities. This enables us to reshape
the pixel cells so that neighboring pixels belonging to the same feature
are connected through edges, thereby preserving the feature
connectivity under magnification. We reduce pixel aliasing artifacts and
improve smoothness by fitting spline curves to contours in the image
and optimizing their control points.
The Museum of Modern Art in New York (MoMA) last week announced that
it is bolstering its collection of work with 14 videogames, and plans to
acquire a further 26 over the next few years. And that’s just for
starters. The games will join the likes of Hector Guimard’s Paris Metro
entrances, the Rubik’s Cube, M&Ms and Apple’s first iPod in the
museum’s Architecture & Design department.
The move recognises the design achievements behind each creation, of
course, but despite MoMA’s savvy curatorial decision, the institution
risks becoming a catalyst for yet another wave of awkward ‘are games
art?’ blog posts. And it doesn’t exactly go out of its way to avoid that
particular quagmire in the official announcement.
“Are video games art? They sure are,” it begins, worryingly, before
switching to a more considered tack, “but they are also design, and a
design approach is what we chose for this new foray into this universe.
The games are selected as outstanding examples of interaction design — a
field that MoMA has already explored and collected extensively, and one
of the most important and oft-discussed expressions of contemporary
design creativity.”
Jason Rohrer
MoMA worked with scholars, digital conservation and legal experts,
historians and critics to come up with its criteria and final list of
games, and among the yardsticks the museum looked at for inclusion are
the visual quality and aesthetic experience of each game, the ways in
which the game manipulates or stimulates player behaviour, and even the
elegance of its code.
That initial list of 14 games makes for convincing reading, too:
Pac-Man, Tetris, Another World, Myst, SimCity 2000, Vib-Ribbon, The
Sims, Katamari Damacy, Eve Online, Dwarf Fortress, Portal, flOw, Passage
and Canabalt.
But the wishlist also extends to Spacewar!, a selection of Magnavox
Odyssey games, Pong, Snake, Space Invaders, Asteroids, Zork, Tempest,
Donkey Kong, Yars’ Revenge, M.U.L.E, Core War, Marble Madness, Super
Mario Bros, The Legend Of Zelda, NetHack, Street Fighter II, Chrono
Trigger, Super Mario 64, Grim Fandango, Animal Crossing, and, of course,
Minecraft.
Art, design or otherwise, MoMA’s focused collection is an uncommonly
informed and well-considered list. And their inclusion within MoMA’s
hallowed walls, and the recognition of their cultural and historical
relevance that is implied, is certainly a boon for videogames on the
whole. But reactions to the move have been mixed. The Guardian’s
Jonathan Jones posted a blog
last week titled Sorry MoMA, Videogames Are Not Art, in which he
suggests that exhibiting Pac-Man and Tetris alongside work by Picasso
and Van Gogh will mean “game over for any real understanding of art”.
Canabalt
“The worlds created by electronic games are more like playgrounds
where experience is created by the interaction between a player and a
programme,” he writes. “The player cannot claim to impose a personal
vision of life on the game, while the creator of the game has ceded that
responsibility. No one ‘owns’ the game, so there is no artist, and
therefore no work of art.”
While he clearly misunderstands the capacity of a game to manifest
the personal – and singular – vision of its creator, he nonetheless
raises valid fears that the creative motivations behind many videogames’
– predominantly commercially-driven entertainment – are incompatible
with those of serious art and that their inclusion in established
museums risks muddying its definition. But while many commentators have
fallen into the same trap of invoking comparisons with cubist and
impressionist painters, MoMA has drawn no such parallels.
“We have to keep in mind it’s the design collection that is
snapping up video games,” Passage creator Jason Rorher tells us when we
put the question to him. “This is the same collection that houses Lego,
teapots, and barstools. I’m happy with that, because I primarily think
of myself as a designer. But sadly, even the mightiest games in this
acquisition look silly when stood up next to serious works of art. I
mean what’s the artistic payload of, Passage? ‘You’re gonna die someday.’ You can’t find a sentiment that’s more artistically worn out than that.”
Adam Saltsman
But while he doesn’t see these games’ inclusion as a significant
landmark – in fact, he even raises concerns over bandwagon-hopping –
he’s still elated to have been included.
“I’m shocked to see my little game standing there next to landmarks
like Pac-Man, Tetris, Another World, and… all of them really, all the
way up to Canabalt,” he says. “The most pleasing aspect of it, for me,
is that something I have made will be preserved and maintained into the
future, after I croak. The ephemeral nature of digital-download video
games has always worried me. Heck, the Mac version of Passage has
already been broken by Apple’s updates, and it’s only been five years!”
Talking of Canabalt, creator Adam Saltsman echoes Rohrer’s sentiment:
“Obviously it is a pretty huge honour, but I think it’s also important
to note that these selections are part of the design wing of the museum,
so Tetris won’t exactly be right next to Dali or Picasso! That doesn’t
really diminish the excitement for me though. The MoMA is an incredible
institution, and to have my work selected for archival alongside obvious
masterpieces like Tetris is pretty overwhelming. “
MoMA’s not the only art institution with an interest in videogames,
of course. The Smithsonian American Art Museum ran an exhibition titled
The Art of Video Games earlier this year, while the Barbican has put its
weight behind all manner of events, including 2002?s The History,
Culture and Future of Computer Games, Ear Candy: Video Game Music, and
the touring Game On exhibition.
Eve Online
Chris Melissinos, who was one of the guest curators who put the
Smithsonian exhibition together and subsequently acted as an adviser to
MoMA as it selected its list, doesn’t think such interest is damaging to
art, or indeed a sign of out-of-step institutions jumping on the
bandwagon. It’s simply, he believes, a reaction to today’s culture.
“This decision indicates that videogames have become an important cultural, artistic form of expression in society,” he told the Independent.
“It could become one of the most important forms of artistic
expression. People who apply themselves to the craft view themselves as
[artists], because they absolutely are. This is an amalgam of many
traditional forms of art.”
Of the initial selection, Eve is arguably the most ambitious, and
potentially divisive, selection, but perhaps also the best placed to
challenge Jones’ predispositions on experiential ownership and creative
limitation. It is, after all, renowned for its vociferous,
self-governing player community.
“Eve’s been around for close to a decade, is still growing, and
through its lifetime has won several awards and achievements, but being
acquired into the permanent collection of a world leading contemporary
art and design museum is a tremendous honour for us,” Eve Online
creative director Torfi Frans Ólafsson tells us. “Eve is born out of a
strong ideology of player empowerment and sandbox openness, which
especially in our earlier days was often at the cost of accessibility
and mainstream appeal.
Torfi Frans Ólafsson
“Sitting up there along with industrial design like the original
iPod, and fancy, unergonomic lemon presses tells us that we were right
to stand by our convictions, so in that sense, it’s somewhat of a
vindication of our efforts.”
But how do you present an entire universe to an audience that is
likely to spend a few short minutes looking at each exhibit? Developer
CCP is turning to its many players for help.
“We’ve decided to capture a single day of Eve: Sunday the 9th of
December,” explains Ólafsson. “Through a variety of player made videos,
CCP videos, massive data analysis and info graphics.”
In presenting Eve in this way, CCP and the games players are
collaborating on a strong, coherent vision of the alternative reality
they’ve collectively helped to build, and more importantly, reinforcing
and redefining the notion of authorship. It doesn’t matter whether
you’re an apologist for videogames’ entitlement to the status of art, or
someone who appreciates the aesthetics of their design, the important
thing here is that their cultural importance is recognised. Sure, the
notion of a game exhibit that doesn’t include gameplay might stick in
the craw of some, but MoMA’s interest is clearly broader. Ólafsson isn’t
too worried, either.
“Even if we don’t fully succeed in making the 3.5 million people that
visit the MoMA every year visually grok the entire universe in those
few minutes they might spend checking Eve out, I can promise you it sure
will look pretty there on the wall.”
Personal Comments:
Passage is still available here, a game developed during Gamma256.
Canabalt is available here, while mobile versions are available for few bucks (android, iOS).
Internet-connected devices are clearly the future of controlling everything from your home to your car, but actually getting "the Internet of things" rolling has been slow going. Now a new project looks to brighten those prospects, quite literally, with a smart light socket.
Created by Zach Supalla (who was inspired by his father, who is deaf and uses lights for notifications), the Spark Socket
lets you to connect the light sockets in your home to the Internet,
allowing them to be controlled via PC, smartphone and tablet (iOS and Android
are both supported) through a Wi-Fi connection. What makes this device
so compelling is its simplicity. By simply screwing a normal light bulb
into the Spark Socket, connected to a standard light fixture, you can
quickly begin controlling and programming the lights in your home.
Some of the uses for the Spark Socket include allowing you to have
your house lights flash when you receive a text or email, programming
lights to turn on with certain alarms, and having lights dim during
certain times of the day. A very cool demonstration of how the device
works can be tested by simply visiting this live Ustream page and tweeting #hellospark. We tested it and the light flashed on instantly as soon as we tweeted the hashtag.
The device is currently on Kickstarter, inching closer toward
its $250,000 goal, and if successful will retail for $60 per unit. You
can watch Supalla offer a more detailed description of the product and
how it came to be in the video below.
I believe the day-to-day practice of writing JavaScript is going to
change dramatically for the better when ECMAScript.next arrives. The
coming year is going to be an exciting time for developers as features
proposed or finalised for the next versions of the language start to
become more widely available.
In this post, I will review some of the features I'm personally looking forward to landing and being used in 2013 and beyond.
In Canary, remember that to enable all of the latest JavaScript experiments you should navigate to chrome:flags and use the 'Enable Experimental JavaScript' option.
Alternatively, many ES.next features can be experimented with using Google's Traceur transpiler (useful unit tests with examples here) and there are shims available for other features via projects such as ES6-Shim and Harmony Collections.
Finally, in Node.js (V8), the --harmony flag activates a number of experimental ES.next features including block scoping, WeakMaps and more.
Modules
We're
used to separating our code into manageable blocks of functionality. In
ES.next, A module is a unit of code contained within a module
declaration. It can either be defined inline or within an externally
loaded module file. A skeleton inline module for a Car could be written:
A module instance
is a module which has been evaluated, is linked to other modules or has
lexically encapsulated data. An example of a module instance is:
An export
declaration declares that a local function or variable binding is
visible externally to other modules. If familiar with the module
pattern, think of this concept as being parallel to the idea of exposing
functionality publicly.
Modules import what they wish to use from other modules. Other modules may read the module exports (e.g drive(), miles etc. above) but they cannot modify them. Exports can be renamed as well so their names are different from local names.
Revisiting the export example above, we can now selectively choose what we wish to import when in another module.
Earlier,
we mentioned the concept of a Module Loader API. The module loader
allows us to dynamically load in scripts for consumption. Similar to import, we are able to consume anything defined as an export from such modules.
moduleURL: The string representing a module URL (e.g "car.js")
callback: A callback function which receives the output result of attempting to load, compile and then execute the module
errorCallback: A callback triggered if an error occurs during loading or compilation
Whilst
the above example seems fairly trivial to use, the Loader API is there
to provide a way to load modules in controlled contexts and actually
supports a number of different configuration options. Loader itself is a system provided instance of the API, but it's possible to create custom loaders using the Loader constructor.
What about classes?
I'm not going to be covering ES.next classes in this post in more, but for those wondering how they relate to modules, Alex Russell has previously shared a pretty readable example of how the two fit in – it's not at all about turning JavaScript into Java.
Classes
in ES.next are there to provide a declarative surface for the semantics
we're used to (e.g functions, prototypes) so that developer intent is
expressed instead of the underlying imperative mechanics.
Followed
by today's de-sugared approach that ignores the semantic improvements
brought by ES.next modules over the module pattern and instead
emphasises our reliance of function variants:
All the ES.next version does it makes the code more easy to read. What class means here is function,
or at least, one of the things we currently do with functions. If you
enjoy JavaScript and like using functions and prototypes, such sugar is
nothing to fear in the next version of JavaScript.
Where do these modules fit in with AMD?
If
anything, the landscape for modularization and loading of code on the
front-end has seen a wealth of hacks, abuse and experimentation, but
we've been able to get by so far.
Are ES.next modules a step in
the right direction? Perhaps. My own take on them is that reading their
specs is one thing and actually using them is another. Playing with the
newer module syntax in Harmonizr, Require HM and Traceur,
you actually get used to the syntax and semantics very quickly – it
feels like using a cleaner module pattern but with access to native
loader API for any dynamic module loading required at runtime. That
said, the syntax might feel a little too much like Python for some
peoples tastes (e.g the import statements).
I'm part
of the camp that believe if there's functionality developers are using
broadly enough (e.g better modules), the platform (i.e the browser)
should be trying to offer some of this natively and I'm not alone in
feeling this way. James Burke, who was instrumental in bringing us AMD
and RequireJS has previously said:
I want AMD and
RequireJS to go away. They solve a real problem, but ideally the
language and runtime should have similar capabilities built in. Native
support should be able to cover the 80% case of RequireJS usage, to the
point that no userland "module loader" library should be needed for
those use cases, at least in the browser.
James has
however questioned whether ES.next modules are a sufficient solution. He
covered some more of his thoughts on ES.next modules back in June in ES6 Modules: Suggestions for improvement and later in Why not AMD? for anyone interested in reading more about how these modules fit in with RequireJS and AMD.
Isaac Schlueter has also previously written up thoughts on where ES6 modules fall short that are worth noting. Try them out yourself using some of the options below and see what you think.
The idea behind Object.observe
is that we gain the ability to observe and notify applications of
changes made to specific JavaScript objects. Such changes include
properties being added, updated, removed or reconfigured.
Property
observing is behaviour we commonly find in JavaScript MVC frameworks at
at the moment and is an important component of data-binding, found in
solutions like AngularJS and Ember.
This is a fundamentally
important addition to JS as it could both offer performance improvements
over a framework's custom implementations and allow easier observation
of plain native objects.
Whats the current value? change.object[change.name]
*/
});
});
// Examples
todoModel.label = 'Buy some more milk';
/*
label changed
It was changed by being updated
Its current value is 'Buy some more milk'
*/
todoModel.completeBy = '01/01/2013';
/*
completeBy changed
It was changed by being new
Its current value is '01/01/2013'
*/
delete todoModel.completed;
/*
completed changed
It was changed by being deleted
Its current value is undefined
*/
Availability:
Object.observe will be available in Chrome Canary behind the "Enable
Experimental JS APIs" flag. If you don't feel like getting that setup,
you can also checkout this video by Rafael Weinstein discussing the proposal.
Default
parameter values allow us to initialize parameters if they are not
explicitly supplied. This means that we no longer have to write options = options || {};.
The syntax is modified by allowing an (optional) initialiser after the parameter names:
Block scoping introduces new declaration forms for defining variables scoped to a single block. This includes:
let: which syntactically is quite similar to var, but defines a variable in the current block function, allowing function declarations in nested blocks
const: like let, but is for read-only constant declarations
Using let in place of var
makes it easier to define block-local variables without worrying about
them clashing with variables elsewhere in the same function body. The
scope of a variable that's been declared inside a let statement using var is the same as if it had been declared outside the let statement. These types of variables will still have function scoping.
const availability: FF18, Chrome 24+, SF6, WebKit, Opera 12
Maps and sets
Maps
Many
of you will already be familiar with the concept of maps as we've been
using plain JavaScript objects as them for quite some time. Maps allow
us to map a value to a unique key such that we can retrieve the value
using the key without the pains of prototype-based inheritance.
With the Maps set() method, new name-value pairs are stored in the map and using get(), the values can be retrieved. Maps also have the following three methods:
has(key) : a boolean check to test if a key exists
delete(key) : deletes the key specified from the map
size() : returns the number of stored name-value pairs
As
Nicholas has pointed out before, sets won't be new to developers coming
from Ruby or Python, but it's a feature thats been missing from
JavaScript. Data of any type can be stored in a set, although values can
be set only once. They are an effective means of creating ordered list
of values that cannot contain duplicates.
add(value) – adds the value to the set.
delete(value) – sets the value for the key in the set.
has(value) – returns a boolean asserting whether the value has been added to the set
This
results in O(n) for filtering uniques in an array. Almost all methods
of array unique with objects are O(n^2) (credit goes to Brandon Benvie
for this suggestion).
The
Proxy API will allow us to create objects whose properties may be
computed at run-time dynamically. It will also support hooking into
other objects for tasks such as logging or auditing.
WeakMaps
help developers avoid memory leaks by holding references to their
properties weakly, meaning that if a WeakMap is the only object with a
reference to another object, the garbage collector may collect the
referenced object. This behavior differs from all variable references in
ES5.
A key property of Weak Maps is the inability to enumerate their keys.
Introduces a function for comparison called Object.is. The main difference between === and Object.is are the way NaNs and (negative) zeroes are treated. A NaN is equal to another NaN and negative zeroes are not equal from other positive zeroes.
Array.from:
Converts a single argument that is an array-like object or list (eg.
arguments, NodeList, DOMTokenList (used by classList), NamedNodeMap
(used by attributes property)) into a new Array() and returns it;
ES.next
is shaping up to potentially include solutions for what many of us
consider are missing from JavaScript at the moment. Whilst ES6 is
targeting a 2013 spec release, browsers are already implementing
individual features and it's only a matter of time before their
availability is widespread.
In the meantime, we can use (some)
modern browsers, transpilers, shims and in some cases custom builds to
experiment with features before ES6 is fully here.
For more examples and up to date information, feel free to checkout the TC39 Codex Wiki
(which was a great reference when putting together this post)
maintained by Dave Herman and others. It contains summaries of all
features currently being targeted for the next version of JavaScript.
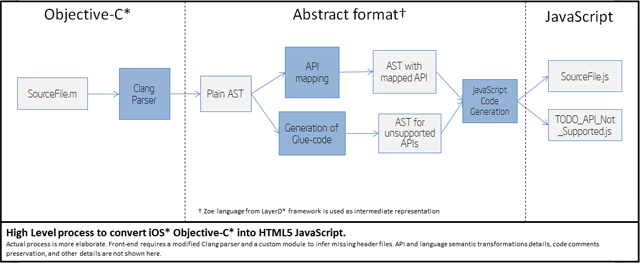
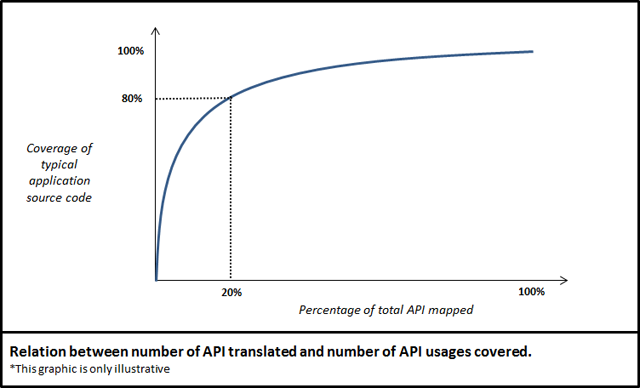
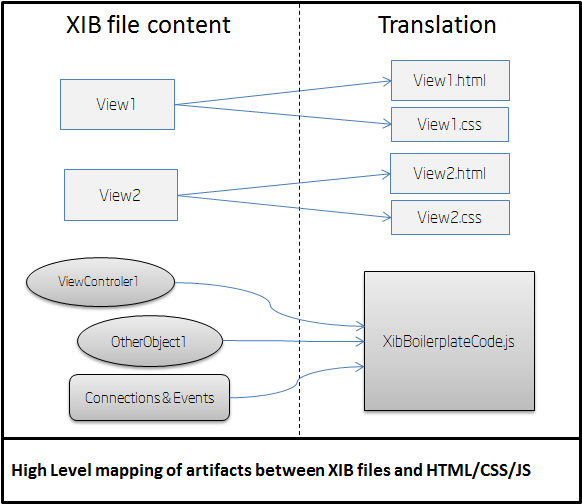
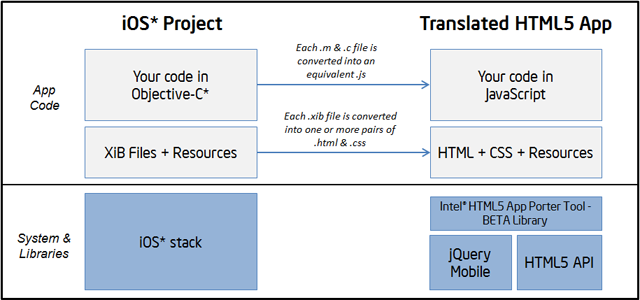
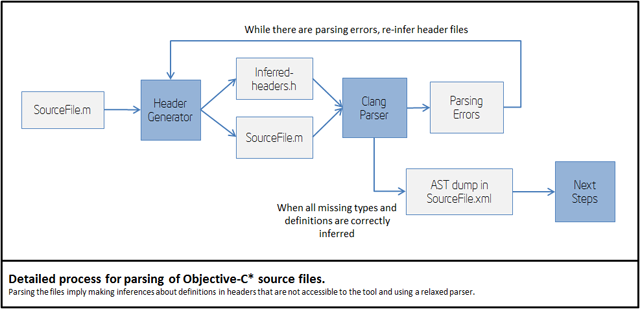






 Researchers launching a new vector-based
video codec this week are claiming their work will lead to the death of the
pixel within the next five years
Researchers launching a new vector-based
video codec this week are claiming their work will lead to the death of the
pixel within the next five years










