Tuesday, February 07. 2012
It's Kinect day! The Kinect For Windows SDK v1 is out!
Monday, February 06. 2012
The Great Disk Drive in the Sky: How Web giants store big—and we mean big—data
Via Ars Technica
-----

Google technicians test hard drives at their data center in Moncks Corner, South Carolina -- Image courtesy of Google Datacenter Video
Consider the tech it takes to back the search box on Google's home page: behind the algorithms, the cached search terms, and the other features that spring to life as you type in a query sits a data store that essentially contains a full-text snapshot of most of the Web. While you and thousands of other people are simultaneously submitting searches, that snapshot is constantly being updated with a firehose of changes. At the same time, the data is being processed by thousands of individual server processes, each doing everything from figuring out which contextual ads you will be served to determining in what order to cough up search results.
The storage system backing Google's search engine has to be able to serve millions of data reads and writes daily from thousands of individual processes running on thousands of servers, can almost never be down for a backup or maintenance, and has to perpetually grow to accommodate the ever-expanding number of pages added by Google's Web-crawling robots. In total, Google processes over 20 petabytes of data per day.
That's not something that Google could pull off with an off-the-shelf storage architecture. And the same goes for other Web and cloud computing giants running hyper-scale data centers, such as Amazon and Facebook. While most data centers have addressed scaling up storage by adding more disk capacity on a storage area network, more storage servers, and often more database servers, these approaches fail to scale because of performance constraints in a cloud environment. In the cloud, there can be potentially thousands of active users of data at any moment, and the data being read and written at any given moment reaches into the thousands of terabytes.
The problem isn't simply an issue of disk read and write speeds. With data flows at these volumes, the main problem is storage network throughput; even with the best of switches and storage servers, traditional SAN architectures can become a performance bottleneck for data processing.
Then there's the cost of scaling up storage conventionally. Given the rate that hyper-scale web companies add capacity (Amazon, for example, adds as much capacity to its data centers each day as the whole company ran on in 2001, according to Amazon Vice President James Hamilton), the cost required to properly roll out needed storage in the same way most data centers do would be huge in terms of required management, hardware, and software costs. That cost goes up even higher when relational databases are added to the mix, depending on how an organization approaches segmenting and replicating them.
The need for this kind of perpetually scalable, durable storage has driven the giants of the Web—Google, Amazon, Facebook, Microsoft, and others—to adopt a different sort of storage solution: distributed file systems based on object-based storage. These systems were at least in part inspired by other distributed and clustered filesystems such as Red Hat's Global File System and IBM's General Parallel Filesystem.
The architecture of the cloud giants' distributed file systems separates the metadata (the data about the content) from the stored data itself. That allows for high volumes of parallel reading and writing of data across multiple replicas, and the tossing of concepts like "file locking" out the window.
The impact of these distributed file systems extends far beyond the walls of the hyper-scale data centers they were built for— they have a direct impact on how those who use public cloud services such as Amazon's EC2, Google's AppEngine, and Microsoft's Azure develop and deploy applications. And companies, universities, and government agencies looking for a way to rapidly store and provide access to huge volumes of data are increasingly turning to a whole new class of data storage systems inspired by the systems built by cloud giants. So it's worth understanding the history of their development, and the engineering compromises that were made in the process.
Google File System
Google was among the first of the major Web players to face the storage scalability problem head-on. And the answer arrived at by Google's engineers in 2003 was to build a distributed file system custom-fit to Google's data center strategy—Google File System (GFS).
GFS is the basis for nearly all of the company's cloud services. It handles data storage, including the company's BigTable database and the data store for Google's AppEngine platform-as-a-service, and it provides the data feed for Google's search engine and other applications. The design decisions Google made in creating GFS have driven much of the software engineering behind its cloud architecture, and vice-versa. Google tends to store data for applications in enormous files, and it uses files as "producer-consumer queues," where hundreds of machines collecting data may all be writing to the same file. That file might be processed by another application that merges or analyzes the data—perhaps even while the data is still being written.
Google keeps most technical details of GFS to itself, for obvious reasons. But as described by Google research fellow Sanjay Ghemawat, principal engineer Howard Gobioff, and senior staff engineer Shun-Tak Leung in a paper first published in 2003, GFS was designed with some very specific priorities in mind: Google wanted to turn large numbers of cheap servers and hard drives into a reliable data store for hundreds of terabytes of data that could manage itself around failures and errors. And it needed to be designed for Google's way of gathering and reading data, allowing multiple applications to append data to the system simultaneously in large volumes and to access it at high speeds.
Much in the way that a RAID 5 storage array "stripes" data across multiple disks to gain protection from failures, GFS distributes files in fixed-size chunks which are replicated across a cluster of servers. Because they're cheap computers using cheap hard drives, some of those servers are bound to fail at one point or another—so GFS is designed to be tolerant of that without losing (too much) data.
But the similarities between RAID and GFS end there, because those servers can be distributed across the network—either within a single physical data center or spread over different data centers, depending on the purpose of the data. GFS is designed primarily for bulk processing of lots of data. Reading data at high speed is what's important, not the speed of access to a particular section of a file, or the speed at which data is written to the file system. GFS provides that high output at the expense of more fine-grained reads and writes to files and more rapid writing of data to disk. As Ghemawat and company put it in their paper, "small writes at arbitrary positions in a file are supported, but do not have to be efficient."
This distributed nature, along with the sheer volume of data GFS handles—millions of files, most of them larger than 100 megabytes and generally ranging into gigabytes—requires some trade-offs that make GFS very much unlike the sort of file system you'd normally mount on a single server. Because hundreds of individual processes might be writing to or reading from a file simultaneously, GFS needs to supports "atomicity" of data—rolling back writes that fail without impacting other applications. And it needs to maintain data integrity with a very low synchronization overhead to avoid dragging down performance.
GFS consists of three layers: a GFS client, which handles requests for data from applications; a master, which uses an in-memory index to track the names of data files and the location of their chunks; and the "chunk servers" themselves. Originally, for the sake of simplicity, GFS used a single master for each cluster, so the system was designed to get the master out of the way of data access as much as possible. Google has since developed a distributed master system that can handle hundreds of masters, each of which can handle about 100 million files.
When the GFS client gets a request for a specific data file, it requests the location of the data from the master server. The master server provides the location of one of the replicas, and the client then communicates directly with that chunk server for reads and writes during the rest of that particular session. The master doesn't get involved again unless there's a failure.
To ensure that the data firehose is highly available, GFS trades off some other things—like consistency across replicas. GFS does enforce data's atomicity—it will return an error if a write fails, then rolls the write back in metadata and promotes a replica of the old data, for example. But the master's lack of involvement in data writes means that as data gets written to the system, it doesn't immediately get replicated across the whole GFS cluster. The system follows what Google calls a "relaxed consistency model" out of the necessities of dealing with simultaneous access to data and the limits of the network.
This means that GFS is entirely okay with serving up stale data from an old replica if that's what's the most available at the moment—so long as the data eventually gets updated. The master tracks changes, or "mutations," of data within chunks using version numbers to indicate when the changes happened. As some of the replicas get left behind (or grow "stale"), the GFS master makes sure those chunks aren't served up to clients until they're first brought up-to-date.
But that doesn't necessarily happen with sessions already connected to those chunks. The metadata about changes doesn't become visible until the master has processed changes and reflected them in its metadata. That metadata also needs to be replicated in multiple locations in case the master fails—because otherwise the whole file system is lost. And if there's a failure at the master in the middle of a write, the changes are effectively lost as well. This isn't a big problem because of the way that Google deals with data: the vast majority of data used by its applications rarely changes, and when it does data is usually appended rather than modified in place.
While GFS was designed for the apps Google ran in 2003, it wasn't long before Google started running into scalability issues. Even before the company bought YouTube, GFS was starting to hit the wall—largely because the new applications Google was adding didn't work well with the ideal 64-megabyte file size. To get around that, Google turned to Bigtable, a table-based data store that vaguely resembles a database and sits atop GFS. Like GFS below it, Bigtable is mostly write-once, so changes are stored as appends to the table—which Google uses in applications like Google Docs to handle versioning, for example.
The foregoing is mostly academic if you don't work at Google (though it may help users of AppEngine, Google Cloud Storage and other Google services to understand what's going on under the hood a bit better). While Google Cloud Storage provides a public way to store and access objects stored in GFS through a Web interface, the exact interfaces and tools used to drive GFS within Google haven't been made public. But the paper describing GFS led to the development of a more widely used distributed file system that behaves a lot like it: the Hadoop Distributed File System.
Hadoop DFS
Developed in Java and open-sourced as a project of the Apache Foundation, Hadoop has developed such a following among Web companies and others coping with "big data" problems that it has been described as the "Swiss army knife of the 21st Century." All the hype means that sooner or later, you're more likely to find yourself dealing with Hadoop in some form than with other distributed file systems—especially when Microsoft starts shipping it as an Windows Server add-on.
Named by developer Doug Cutting after his son's stuffed elephant, Hadoop was "inspired" by GFS and Google's MapReduce distributed computing environment. In 2004, as Cutting and others working on the Apache Nutch search engine project sought a way to bring the crawler and indexer up to "Web scale," Cutting read Google's papers on GFS and MapReduce and started to work on his own implementation. While most of the enthusiasm for Hadoop comes from Hadoop's distributed data processing capability, derived from its MapReduce-inspired distributed processing management, the Hadoop Distributed File System is what handles the massive data sets it works with.
Hadoop is developed under the Apache license, and there are a number of commercial and free distributions available. The distribution I worked with was from Cloudera (Doug Cutting's current employer)—the Cloudera Distribution Including Apache Hadoop (CDH), the open-source version of Cloudera's enterprise platform, and Cloudera Service and Configuration Express Edition, which is free for up to 50 nodes.
HortonWorks, the company with which Microsoft has aligned to help move Hadoop to Azure and Windows Server (and home to much of the original Yahoo team that worked on Hadoop), has its own Hadoop-based HortonWorks Data Platform in a limited "technology preview" release. There's also a Debian package of the Apache Core, and a number of other open-source and commercial products that are based on Hadoop in some form.
HDFS can be used to support a wide range of applications where high volumes of cheap hardware and big data collide. But because of its architecture, it's not exactly well-suited to general purpose data storage, and it gives up a certain amount of flexibility. HDFS has to do away with certain things usually associated with file systems in order to make sure it can perform well with massive amounts of data spread out over hundreds, or even thousands, of physical machines—things like interactive access to data.
While Hadoop runs in Java, there are a number of ways to interact with HDFS besides its Java API. There's a C-wrapped version of the API, a command line interface through Hadoop, and files can be browsed through HTTP requests. There's also MountableHDFS, an add-on based on FUSE that allows HDFS to be mounted as a file system by most operating systems. Developers are working on a WebDAV interface as well to allow Web-based writing of data to the system.
HDFS follows the architectural path laid out by Google's GFS fairly closely, following its three-tiered, single master model. Each Hadoop cluster has a master server called the "NameNode" which tracks the metadata about the location and replication state of each 64-megabyte "block" of storage. Data is replicated across the "DataNodes" in the cluster—the slave systems that handle data reads and writes. Each block is replicated three times by default, though the number of replicas can be increased by changing the configuration of the cluster.
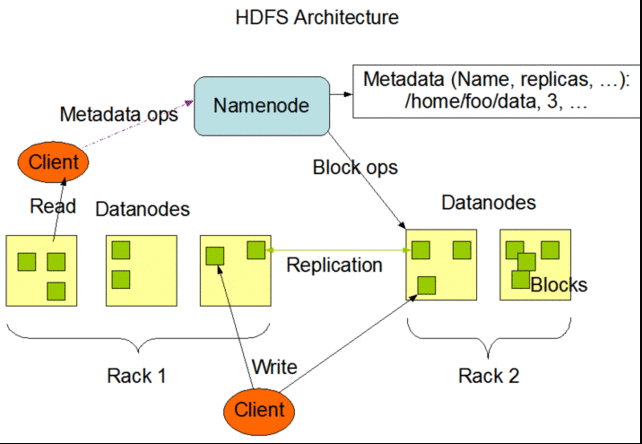
As in GFS, HDFS gets the master server out of the read-write loop as quickly as possible to avoid creating a performance bottleneck. When a request is made to access data from HDFS, the NameNode sends back the location information for the block on the DataNode that is closest to where the request originated. The NameNode also tracks the health of each DataNode through a "heartbeat" protocol and stops sending requests to DataNodes that don't respond, marking them "dead."
After the handoff, the NameNode doesn't handle any further interactions. Edits to data on the DataNodes are reported back to the NameNode and recorded in a log, which then guides replication across the other DataNodes with replicas of the changed data. As with GFS, this results in a relatively lazy form of consistency, and while the NameNode will steer new requests to the most recently modified block of data, jobs in progress will still hit stale data on the DataNodes they've been assigned to.
That's not supposed to happen much, however, as HDFS data is supposed to be "write once"—changes are usually appended to the data, rather than overwriting existing data, making for simpler consistency. And because of the nature of Hadoop applications, data tends to get written to HDFS in big batches.
When a client sends data to be written to HDFS, it first gets staged in a temporary local file by the client application until the data written reaches the size of a data block—64 megabytes, by default. Then the client contacts the NameNode and gets back a datanode and block location to write the data to. The process is repeated for each block of data committed, one block at a time. This reduces the amount of network traffic created, and it slows down the write process as well. But HDFS is all about the reads, not the writes.
Another way HDFS can minimize the amount of write traffic over the network is in how it handles replication. By activating an HDFS feature called "rack awareness" to manage distribution of replicas, an administrator can specify a rack ID for each node, designating where it is physically located through a variable in the network configuration script. By default, all nodes are in the same "rack." But when rack awareness is configured, HDFS places one replica of each block on another node within the same data center rack, and another in a different rack to minimize the amount of data-writing traffic across the network—based on the reasoning that the chance of a whole rack failure is less likely than the failure of a single node. In theory, this improves overall write performance to HDFS without sacrificing reliability.
As with the early version of GFS, HDFS's NameNode potentially creates a single point of failure for what's supposed to be a highly available and distributed system. If the metadata in the NameNode is lost, the whole HDFS environment becomes essentially unreadable—like a hard disk that has lost its file allocation table. HDFS supports using a "backup node," which keeps a synchronized version of the NameNode's metadata in-memory, and stores snap-shots of previous states of the system so that it can be rolled back if necessary. Snapshots can also be stored separately on what's called a "checkpoint node." However, according to the HDFS documentation, there's currently no support within HDFS for automatically restarting a crashed NameNode, and the backup node doesn't automatically kick in and replace the master.
HDFS and GFS were both engineered with search-engine style tasks in mind. But for cloud services targeted at more general types of computing, the "write once" approach and other compromises made to ensure big data query performance are less than ideal—which is why Amazon developed its own distributed storage platform, called Dynamo.
Amazon's S3 and Dynamo
As Amazon began to build its Web services platform, the company had much different application issues than Google.
Until recently, like GFS, Dynamo hasn't been directly exposed to customers. As Amazon CTO Werner Vogels explained in his blog in 2007, it is the underpinning of storage services and other parts of Amazon Web Services that are highly exposed to Amazon customers, including Amazon's Simple Storage Service (S3) and SimpleDB. But on January 18 of this year, Amazon launched a database service called DynamoDB, based on the latest improvements to Dynamo. It gave customers a direct interface as a "NoSQL" database.
Dynamo has a few things in common with GFS and HDFS: it's also designed with less concern for consistency of data across the system in exchange for high availability, and to run on Amazon's massive collection of commodity hardware. But that's where the similarities start to fade away, because Amazon's requirements for Dynamo were totally different.
Amazon needed a file system that could deal with much more general purpose data access—things like Amazon's own e-commerce capabilities, including customer shopping carts, and other very transactional systems. And the company needed much more granular and dynamic access to data. Rather than being optimized for big streams of data, the need was for more random access to smaller components, like the sort of access used to serve up webpages.
According to the paper presented by Vogels and his team at the Symposium on Operating Systems Principles conference in October 2007, "Dynamo targets applications that need to store objects that are relatively small (usually less than 1 MB)." And rather than being optimized for reads, Dynamo is designed to be "always writeable," being highly available for data input—precisely the opposite of Google's model.
"For a number of Amazon services," the Amazon Dynamo team wrote in their paper, "rejecting customer updates could result in a poor customer experience. For instance, the shopping cart service must allow customers to add and remove items from their shopping cart even amidst network and server failures." At the same time, the services based on Dynamo can be applied to much larger data sets—in fact, Amazon offers the Hadoop-based Elastic MapReduce service based on S3 atop of Dynamo.
In order to meet those requirements, Dynamo's architecture is almost the polar opposite of GFS—it more closely resembles a peer-to-peer system than the master-slave approach. Dynamo also flips how consistency is handled, moving away from having the system resolve replication after data is written, and instead doing conflict resolution on data when executing reads. That way, Dynamo never rejects a data write, regardless of whether it's new data or a change to existing data, and the replication catches up later.
Because of concerns about the pitfalls of a central master server failure (based on previous experiences with service outages), and the pace at which Amazon adds new infrastructure to its cloud, Vogel's team chose a decentralized approach to replication. It was based on a self-governing data partitioning scheme that used the concept of consistent hashing. The resources within each Dynamo cluster are mapped as a continuous circle of address spaces, and each storage node in the system is given a random value as it is added to the cluster—a value that represents its "position" on the Dynamo ring. Based on the number of storage nodes in the cluster, each node takes responsibility for a chunk of address spaces based on its position. As storage nodes are added to the ring, they take over chunks of address space and the nodes on either side of them in the ring adjust their responsibility. Since Amazon was concerned about unbalanced loads on storage systems as newer, better hardware was added to clusters, Dynamo allows multiple virtual nodes to be assigned to each physical node, giving bigger systems a bigger share of the address space in the cluster.
When data gets written to Dynamo—through a "put" request—the systems assigns a key to the data object being written. That key gets run through a 128-bit MD5 hash; the value of the hash is used as an address within the ring for the data. The data node responsible for that address becomes the "coordinator node" for that data and is responsible for handling requests for it and prompting replication of the data to other nodes in the ring, as shown in the Amazon diagram below:

This spreads requests out across all the nodes in the system. In the event of a failure of one of the nodes, its virtual neighbors on the ring start picking up requests and fill in the vacant space with their replicas.
Then there's Dynamo's consistency-checking scheme. When a "get" request comes in from a client application, Dynamo polls its nodes to see who has a copy of the requested data. Each node with a replica responds, providing information about when its last change was made, based on a vector clock—a versioning system that tracks the dependencies of changes to data. Depending on how the polling is configured, the request handler can wait to get just the first response back and return it (if the application is in a hurry for any data and there's low risk of a conflict—like in a Hadoop application) or it can wait for two, three, or more responses. For multiple responses from the storage nodes, the handler checks to see which is most up-to-date and alerts the nodes that are stale to copy the data from the most current, or it merges versions that have non-conflicting edits. This scheme works well for resiliency under most circumstances—if nodes die, and new ones are brought online, the latest data gets replicated to the new node.
The most recent improvements in Dynamo, and the creation of DynamoDB, were the result of looking at why Amazon's internal developers had not adopted Dynamo itself as the base for their applications, and instead relied on the services built atop it—S3, SimpleDB, and Elastic Block Storage. The problems that Amazon faced in its April 2011 outage were the result of replication set up between clusters higher in the application stack—in Amazon's Elastic Block Storage, where replication overloaded the available additional capacity, rather than because of problems with Dynamo itself.
The overall stability of Dynamo has made it the inspiration for open-source copycats just as GFS did. Facebook relies on Cassandra, now an Apache project, which is based on Dynamo. Basho's Riak "NoSQL" database also is derived from the Dynamo architecture.
Microsoft's Azure DFS
When Microsoft launched the Azure platform-as-a-service, it faced a similar set of requirements to those of Amazon—including massive amounts of general-purpose storage. But because it's a PaaS, Azure doesn't expose as much of the infrastructure to its customers as Amazon does with EC2. And the service has the benefit of being purpose-built as a platform to serve cloud customers instead of being built to serve a specific internal mission first.
So in some respects, Azure's storage architecture resembles Amazon's—it's designed to handle a variety of sizes of "blobs," tables, and other types of data, and to provide quick access at a granular level. But instead of handling the logical and physical mapping of data at the storage nodes themselves, Azure's storage architecture separates the logical and physical partitioning of data into separate layers of the system. While incoming data requests are routed based on a logical address, or "partition," the distributed file system itself is broken into gigabyte-sized chunks, or "extents." The result is a sort of hybrid of Amazon's and Google's approaches, illustrated in this diagram from Microsoft:
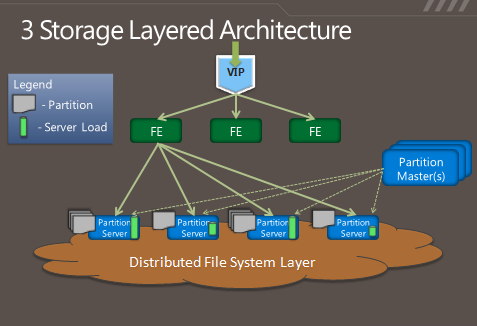
As Microsoft's Brad Calder describes in his overview of Azure's storage architecture, Azure uses a key system similar to that used in Dynamo to identify the location of data. But rather than having the application or service contact storage nodes directly, the request is routed through a front-end layer that keeps a map of data partitions in a role similar to that of HDFS's NameNode. Unlike HDFS, Azure uses multiple front-end servers, load balancing requests across them. The front-end server handles all of the requests from the client application authenticating the request, and handles communicating with the next layer down—the partition layer.
Each logical chunk of Azure's storage space is managed by a partition server, which tracks which extents within the underlying DFS hold the data. The partition server handles the reads and writes for its particular set of storage objects. The physical storage of those objects is spread across the DFS' extents, so all partition servers each have access to all of the extents in the DFS. In addition to buffering the DFS from the front-end servers's read and write requests, the partition servers also cache requested data in memory, so repeated requests can be responded to without having to hit the underlying file system. That boosts performance for small, frequent requests like those used to render a webpage.
All of the metadata for each partition is replicated back to a set of "partition master" servers, providing a backup of the information if a partition server fails—if one goes down, its partitions are passed off to other partition servers dynamically. The partition masters also monitor the workload on each partition server in the Azure storage cluster; if a particular partition server is becoming overloaded, the partition master can dynamically re-assign partitions.
Azure is unlike the other big DFS systems in that it more tightly enforces consistency of data writes. Replication of data happens when writes are sent to the DFS, but it's not the lazy sort of replication that is characteristic of GFS and HDFS. Each extent of storage is managed by a primary DFS server and replicated to multiple secondaries; one DFS server may be a primary for a subset of extents and a secondary server for others. When a partition server passes a write request to DFS, it contacts the primary server for the extent the data is being written to, and the primary passes the write to its secondaries. The write is only reported as successful when the data has been replicated successfully to three secondary servers.
As with the partition layer, Azure DFS uses load balancing on the physical layer in an attempt to prevent systems from getting jammed with too much I/O. Each partition server monitors the workload on the primary extent servers it accesses; when a primary DFS server starts to red-line, the partition server starts redirecting read requests to secondary servers, and redirecting writes to extents on other servers.
The next level of "distributed"
Distributed file systems are hardly a guarantee of perpetual uptime. In most cases, DFS's only replicate within the same data center because of the amount of bandwidth required to keep replicas in sync. But replication within the data center, for example doesn't help when the whole data center gets taken offline or a backup network switch fails to kick in when the primary fails. In August, Microsoft and Amazon both had data centers in Dublin taken offline by a transformer explosion—which created a spike that kept backup generators from starting.
Systems that are lazier about replication, such as GFS and Hadoop, can asynchronously handle replication between two data centers; for example, using "rack awareness," Hadoop clusters can be configured to point to a DataNode offsite, and metadata can be passed to a remote checkpoint or backup node (at least in theory). But for more dynamic data, that sort of replication can be difficult to manage.
That's one of the reasons Microsoft released a feature called "geo-replication" in September. Geo-replication is a feature that will sync customers' data between two data center locations hundred of miles apart. Rather than using the tightly coupled replication Microsoft uses within the data center, geo-replication happens asynchronously. Both of the Azure data centers have to be in the same region; for example, data for an application set up through the Azure Portal at the North Central US data center can be replicated to the South Central US.
In Amazon's case, the company does replication across availability zones at a service level rather than down in the Dynamo architecture. While Amazon hasn't published how it handles its own geo-replication, it provides customers with the ability to "snap shot" their EBS storage to a remote S3 data "bucket."
And that's the approach Amazon and Google have generally taken in evolving their distributed file systems: making the fixes in the services based on them, rather than in the underlying architecture. While Google has added a distributed master system to GFS and made other tweaks to accommodate its ever-growing data flows, the fundamental architecture of Google's system is still very much like it was in 2003.
But in the long term, the file systems themselves may become more focused on being an archive of data than something applications touch directly. In an interview with Ars, database pioneer (and founder of VoltDB) Michael Stonebraker said that as data volumes continue to go up for "big data" applications, server memory is becoming "the new disk" and file systems are becoming where the log for application activity gets stored—"the new tape." As the cloud giants push for more power efficiency and performance from their data centers, they have already moved increasingly toward solid-state drives and larger amounts of system memory.
Thursday, February 02. 2012
Introducing the HUD. Say hello to the future of the menu.
-----
The desktop remains central to our everyday work and play, despite all the excitement around tablets, TV’s and phones. So it’s exciting for us to innovate in the desktop too, especially when we find ways to enhance the experience of both heavy “power” users and casual users at the same time. The desktop will be with us for a long time, and for those of us who spend hours every day using a wide diversity of applications, here is some very good news: 12.04 LTS will include the first step in a major new approach to application interfaces.
This work grows out of observations of new and established / sophisticated users making extensive use of the broader set of capabilities in their applications. We noticed that both groups of users spent a lot of time, relatively speaking, navigating the menus of their applications, either to learn about the capabilities of the app, or to take a specific action. We were also conscious of the broader theme in Unity design of leading from user intent. And that set us on a course which lead to today’s first public milestone on what we expect will be a long, fruitful and exciting journey.
The menu has been a central part of the GUI since Xerox PARC invented ‘em in the 70?s. It’s the M in WIMP and has been there, essentially unchanged, for 30 years.

The original Macintosh desktop, circa 1984, courtesy of Wikipedia
We can do much better!
Say hello to the Head-Up Display, or HUD, which will ultimately replace menus in Unity applications. Here’s what we hope you’ll see in 12.04 when you invoke the HUD from any standard Ubuntu app that supports the global menu:

Snapshot of the HUD in Ubuntu 12.04
The intenterface – it maps your intent to the interface
This is the HUD. It’s a way for you to express your intent and have the application respond appropriately. We think of it as “beyond interface”, it’s the “intenterface”. This concept of “intent-driven interface” has been a primary theme of our work in the Unity shell, with dash search as a first class experience pioneered in Unity. Now we are bringing the same vision to the application, in a way which is completely compatible with existing applications and menus.
The HUD concept has been the driver for all the work we’ve done in unifying menu systems across Gtk, Qt and other toolkit apps in the past two years. So far, that’s shown up as the global menu. In 12.04, it also gives us the first cut of the HUD.
Menus serve two purposes. They act as a standard way to invoke commands which are too infrequently used to warrant a dedicated piece of UI real-estate, like a toolbar button, and they serve as a map of the app’s functionality, almost like a table of contents that one can scan to get a feel for ‘what the app does’. It’s command invocation that we think can be improved upon, and that’s where we are focusing our design exploration.
As a means of invoking commands, menus have some advantages. They are always in the same place (top of the window or screen). They are organised in a way that’s quite easy to describe over the phone, or in a text book (“click the Edit->Preferences menu”), they are pretty fast to read since they are generally arranged in tight vertical columns. They also have some disadvantages: when they get nested, navigating the tree can become fragile. They require you to read a lot when you probably already know what you want. They are more difficult to use from the keyboard than they should be, since they generally require you to remember something special (hotkeys) or use a very limited subset of the keyboard (arrow navigation). They force developers to make often arbitrary choices about the menu tree (“should Preferences be in Edit or in Tools or in Options?”), and then they force users to make equally arbitrary effort to memorise and navigate that tree.
The HUD solves many of these issues, by connecting users directly to what they want. Check out the video, based on a current prototype. It’s a “vocabulary UI”, or VUI, and closer to the way users think. “I told the application to…” is common user paraphrasing for “I clicked the menu to…”. The tree is no longer important, what’s important is the efficiency of the match between what the user says, and the commands we offer up for invocation.
In 12.04 LTS, the HUD is a smart look-ahead search through the app and system (indicator) menus. The image is showing Inkscape, but of course it works everywhere the global menu works. No app modifications are needed to get this level of experience. And you don’t have to adopt the HUD immediately, it’s there if you want it, supplementing the existing menu mechanism.
It’s smart, because it can do things like fuzzy matching, and it can learn what you usually do so it can prioritise the things you use often. It covers the focused app (because that’s where you probably want to act) as well as system functionality; you can change IM state, or go offline in Skype, all through the HUD, without changing focus, because those apps all talk to the indicator system. When you’ve been using it for a little while it seems like it’s reading your mind, in a good way.
We’ll resurrect the (boring) old ways of displaying the menu in 12.04, in the app and in the panel. In the past few releases of Ubuntu, we’ve actively diminished the visual presence of menus in anticipation of this landing. That proved controversial. In our defence, in user testing, every user finds the menu in the panel, every time, and it’s obviously a cleaner presentation of the interface. But hiding the menu before we had the replacement was overly aggressive. If the HUD lands in 12.04 LTS, we hope you’ll find yourself using the menu less and less, and be glad to have it hidden when you are not using it. You’ll definitely have that option, alongside more traditional menu styles.
Voice is the natural next step
Searching is fast and familiar, especially once we integrate voice recognition, gesture and touch. We want to make it easy to talk to any application, and for any application to respond to your voice. The full integration of voice into applications will take some time. We can start by mapping voice onto the existing menu structures of your apps. And it will only get better from there.
But even without voice input, the HUD is faster than mousing through a menu, and easier to use than hotkeys since you just have to know what you want, not remember a specific key combination. We can search through everything we know about the menu, including descriptive help text, so pretty soon you will be able to find a menu entry using only vaguely related text (imagine finding an entry called Preferences when you search for “settings”).
There is lots to discover, refine and implement. I have a feeling this will be a lot of fun in the next two years 
Even better for the power user
The results so far are rather interesting: power users say things
like “every GUI app now feels as powerful as VIM”. EMACS users just
grunt and… nevermind  . Another comment was “it works so well that the rare occasions when it
can’t read my mind are annoying!”. We’re doing a lot of user testing on
heavy multitaskers, developers and all-day-at-the-workstation personas
for Unity in 12.04, polishing off loose ends in the experience that
frustrated some in this audience in 11.04-10. If that describes you, the
results should be delightful. And the HUD should be particularly
empowering.
. Another comment was “it works so well that the rare occasions when it
can’t read my mind are annoying!”. We’re doing a lot of user testing on
heavy multitaskers, developers and all-day-at-the-workstation personas
for Unity in 12.04, polishing off loose ends in the experience that
frustrated some in this audience in 11.04-10. If that describes you, the
results should be delightful. And the HUD should be particularly
empowering.
Even casual users find typing faster than mousing. So while there are modes of interaction where it’s nice to sit back and drive around with the mouse, we observe people staying more engaged and more focused on their task when they can keep their hands on the keyboard all the time. Hotkeys are a sort of mental gymnastics, the HUD is a continuation of mental flow.
Ahead of the competition
There are other teams interested in a similar problem space. Perhaps the best-known new alternative to the traditional menu is Microsoft’s Ribbon. Introduced first as part of a series of changes called Fluent UX in Office, the ribbon is now making its way to a wider set of Windows components and applications. It looks like this:

You can read about the ribbon from a supporter (like any UX change, it has its supporters and detractors
) and if you’ve used it yourself, you will have your own opinion about
it. The ribbon is highly visual, making options and commands very
visible. It is however also a hog of space (I’m told it can be
minimised). Our goal in much of the Unity design has been to return
screen real estate to the content with which the user is working; the
HUD meets that goal by appearing only when invoked.
Instead of cluttering up the interface ALL the time, let’s clear out the chrome, and show users just what they want, when they want it.
Time will tell whether users prefer the ribbon, or the HUD, but we think it’s exciting enough to pursue and invest in, both in R&D and in supporting developers who want to take advantage of it.
Other relevant efforts include Enso and Ubiquity from the original Humanized team (hi Aza &co), then at Mozilla.
Our thinking is inspired by many works of science, art and entertainment; from Minority Report to Modern Warfare and Jef Raskin’s Humane Interface. We hope others will join us and accelerate the shift from pointy-clicky interfaces to natural and efficient ones.
Roadmap for the HUD
There’s still a lot of design and code still to do. For a start, we haven’t addressed the secondary aspect of the menu, as a visible map of the functionality in an app. That discoverability is of course entirely absent from the HUD; the old menu is still there for now, but we’d like to replace it altogether not just supplement it. And all the other patterns of interaction we expect in the HUD remain to be explored. Regardless, there is a great team working on this, including folk who understand Gtk and Qt such as Ted Gould, Ryan Lortie, Gord Allott and Aurelien Gateau, as well as designers Xi Zhu, Otto Greenslade, Oren Horev and John Lea. Thanks to all of them for getting this initial work to the point where we are confident it’s worthwhile for others to invest time in.
We’ll make sure it’s easy for developers working in any toolkit to take advantage of this and give their users a better experience. And we’ll promote the apps which do it best – it makes apps easier to use, it saves time and screen real-estate for users, and it creates a better impression of the free software platform when it’s done well.
From a code quality and testing perspective, even though we consider this first cut a prototype-grown-up, folk will be glad to see this:
Overall coverage rate: lines......: 87.1% (948 of 1089 lines) functions..: 97.7% (84 of 86 functions) branches...: 63.0% (407 of 646 branches)
Landing in 12.04 LTS is gated on more widespread testing. You can of course try this out from a PPA or branch the code in Launchpad (you will need these two branches). Or dig deeper with blogs on the topic from Ted Gould, Olli Ries and Gord Allott. Welcome to 2012 everybody!
Wednesday, February 01. 2012
Killed by Code: Software Transparency in Implantable Medical Devices
Via Software Freedom Law Center
-----
Copyright © 2010, Software Freedom Law Center. Verbatim copying of this document is permitted in any medium; this notice must be preserved on all copies. †
I Abstract
Software is an integral component of a range of devices that perform critical, lifesaving functions and basic daily tasks. As patients grow more reliant on computerized devices, the dependability of software is a life-or-death issue. The need to address software vulnerability is especially pressing for Implantable Medical Devices (IMDs), which are commonly used by millions of patients to treat chronic heart conditions, epilepsy, diabetes, obesity, and even depression.
The software on these devices performs life-sustaining functions such as cardiac pacing and defibrillation, drug delivery, and insulin administration. It is also responsible for monitoring, recording and storing private patient information, communicating wirelessly with other computers, and responding to changes in doctors’ orders.
The Food and Drug Administration (FDA) is responsible for evaluating the risks of new devices and monitoring the safety and efficacy of those currently on market. However, the agency is unlikely to scrutinize the software operating on devices during any phase of the regulatory process unless a model that has already been surgically implanted repeatedly malfunctions or is recalled.
The FDA has issued 23 recalls of defective devices during the first half of 2010, all of which are categorized as “Class I,” meaning there is “reasonable probability that use of these products will cause serious adverse health consequences or death.” At least six of the recalls were likely caused by software defects.1 Physio-Control, Inc., a wholly owned subsidiary of Medtronic and the manufacturer of one defibrillator that was probably recalled due to software-related failures, admitted in a press release that it had received reports of similar failures from patients “over the eight year life of the product,” including one “unconfirmed adverse patient event.”2
Despite the crucial importance of these devices and the absence of comprehensive federal oversight, medical device software is considered the exclusive property of its manufacturers, meaning neither patients nor their doctors are permitted to access their IMD’s source code or test its security.3
In 2008, the Supreme Court of the United States’ ruling in Riegel v. Medtronic, Inc. made people with IMDs even more vulnerable to negligence on the part of device manufacturers.4 Following a wave of high-profile recalls of defective IMDs in 2005, the Court’s decision prohibited patients harmed by defects in FDA-approved devices from seeking damages against manufacturers in state court and eliminated the only consumer safeguard protecting patients from potentially fatal IMD malfunctions: product liability lawsuits. Prevented from recovering compensation from IMD-manufacturers for injuries, lost wages, or health expenses in the wake of device failures, people with chronic medical conditions are now faced with a stark choice: trust manufacturers entirely or risk their lives by opting against life-saving treatment.
We at the Software Freedom Law Center (SFLC) propose an unexplored solution to the software liability issues that are increasingly pressing as the population of IMD-users grows--requiring medical device manufacturers to make IMD source-code publicly auditable. As a non-profit legal services organization for Free and Open Source (FOSS) software developers, part of the SFLC’s mission is to promote the use of open, auditable source code5 in all computerized technology. This paper demonstrates why increased transparency in the field of medical device software is in the public’s interest. It unifies various research into the privacy and security risks of medical device software and the benefits of published systems over closed, proprietary alternatives. Our intention is to demonstrate that auditable medical device software would mitigate the privacy and security risks in IMDs by reducing the occurrence of source code bugs and the potential for malicious device hacking in the long-term. Although there is no way to eliminate software vulnerabilities entirely, this paper demonstrates that free and open source medical device software would improve the safety of patients with IMDs, increase the accountability of device manufacturers, and address some of the legal and regulatory constraints of the current regime.
We focus specifically on the security and privacy risks of implantable medical devices, specifically pacemakers and implantable cardioverter defibrillators, but they are a microcosm of the wider software liability issues which must be addressed as we become more dependent on embedded systems and devices. The broader objective of our research is to debunk the “security through obscurity” misconception by showing that vulnerabilities are spotted and fixed faster in FOSS programs compared to proprietary alternatives. The argument for public access to source code of IMDs can, and should be, extended to all the software people interact with everyday. The well-documented recent incidents of software malfunctions in voting booths, cars, commercial airlines, and financial markets are just the beginning of a problem that can only be addressed by requiring the use of open, auditable source code in safety-critical computerized devices.6
In section one, we give an overview of research related to potentially fatal software vulnerabilities in IMDs and cases of confirmed device failures linked to source code vulnerabilities. In section two, we summarize research on the security benefits of FOSS compared to closed-source, proprietary programs. In section three, we assess the technical and legal limitations of the existing medical device review process and evaluate the FDA’s capacity to assess software security. We conclude with our recommendations on how to promote the use of FOSS in IMDs. The research suggests that the occurrence of privacy and security breaches linked to software vulnerabilities is likely to increase in the future as embedded devices become more common.
II Software Vulnerabilities in IMDs
A variety of wirelessly reprogrammable IMDs are surgically implanted directly into the body to detect and treat chronic health conditions. For example, an implantable cardioverter defibrillator, roughly the size of a small mobile phone, connects to a patient’s heart, monitors rhythm, and delivers an electric shock when it detects abnormal patterns. Once an IMD has been implanted, health care practitioners extract data, such as electrocardiogram readings, and modify device settings remotely, without invasive surgery. New generation ICDs can be contacted and reprogrammed via wireless radio signals using an external device called a “programmer.”
In 2008, approximately 350,000 pacemakers and 140,000 ICDs were implanted in the United States, according to a forecast on the implantable medical device market published earlier this year.7 Nation-wide demand for all IMDs is projected to increase 8.3 percent annually to $48 billion by 2014, the report says, as “improvements in safety and performance properties …enable ICDs to recapture growth opportunities lost over the past year to product recall.”8 Cardiac implants in the U.S. will increase 7.3 percent annually, the article predicts, to $16.7 billion in 2014, and pacing devices will remain the top-selling group in this category.9
Though the surge in IMD treatment over the past decade has had undeniable health benefits, device failures have also had fatal consequences. From 1997 to 2003, an estimated 400,000 to 450,000 ICDs were implanted world-wide and the majority of the procedures took place in the United States. At least 212 deaths from device failures in five different brands of ICD occurred during this period, according to a study of the adverse events reported to the FDA conducted by cardiologists from the Minneapolis Heart Institute Foundation.10
Research indicates that as IMD usage grows, the frequency of potentially fatal software glitches, accidental device malfunctions, and the possibility of malicious attacks will grow. While there has yet to be a documented incident in which the source code of a medical device was breached for malicious purposes, a 2008-study led by software engineer and security expert Kevin Fu proved that it is possible to interfere with an ICD that had passed the FDA’s premarket approval process and been implanted in hundreds of thousands of patients. A team of researchers from three universities partially reverse-engineered the communications protocol of a 2003-model ICD and launched several radio-based software attacks from a short distance. Using low-cost, commercially available equipment to bypass the device programmer, the researchers were able to extract private data stored inside the ICD such as patients’ vital signs and medical history; “eavesdrop” on wireless communication with the device programmer; reprogram the therapy settings that detect and treat abnormal heart rhythms; and keep the device in “awake” mode in order to deplete its battery, which can only be replaced with invasive surgery.
In one experimental attack conducted in the study, researchers were able to first disable the ICD to prevent it from delivering a life-saving shock and then direct the same device to deliver multiple shocks averaging 137.7 volts that would induce ventricular fibrillation in a patient. The study concluded that there were no “technological mechanisms in place to ensure that programmers can only be operated by authorized personnel.” Fu’s findings show that almost anyone could use store-bought tools to build a device that could “be easily miniaturized to the size of an iPhone and carried through a crowded mall or subway, sending its heart-attack command to random victims.”11
The vulnerabilities Fu’s lab exploited are the result of the very same features that enable the ICD to save lives. The model breached in the experiment was designed to immediately respond to reprogramming instructions from health-care practitioners, but is not equipped to distinguish whether treatment requests originate from a doctor or an adversary. An earlier paper co-authored by Fu proposed a solution to the communication-security paradox. The paper recommends the development of a wearable “cloaker” for IMD-patients that would prevent anyone but pre-specified, authorized commercial programmers to interact with the device. In an emergency situation, a doctor with a previously unauthorized commercial programmer would be able to enable emergency access to the IMD by physically removing the cloaker from the patient.12
Though the adversarial conditions demonstrated in Fu’s studies were hypothetical, two early incidents of malicious hacking underscore the need to address the threat software liabilities pose to the security of IMDs. In November 2007, a group of attackers infiltrated the Coping with Epilepsy website and planted flashing computer animations that triggered migraine headaches and seizures in photosensitive site visitors.13 A year later, malicious hackers mounted a similar attack on the Epilepsy Foundation website.14
Ample evidence of software vulnerabilities in other common IMD treatments also indicates that the worst-case scenario envisioned by Fu’s research is not unfounded. From 1983 to 1997 there were 2,792 quality problems that resulted in recalls of medical devices, 383 of which were related to computer software, according to a 2001 study analyzing FDA reports of the medical devices that were voluntarily recalled by manufacturers over a 15-year period.15 Cardiology devices accounted for 21 percent of the IMDs that were recalled. Authors Dolores R. Wallace and D. Richard Kuhn discovered that 98 percent of the software failures they analyzed would have been detected through basic scientific testing methods. While none of the failures they researched caused serious personal injury or death, the paper notes that there was not enough information to determine the potential health consequences had the IMDs remained in service.
Nearly 30 percent of the software-related recalls investigated in the report occurred between 1994 and 1996. “One possibility for this higher percentage in later years may be the rapid increase of software in medical devices. The amount of software in general consumer products is doubling every two to three years,” the report said.
As more individual IMDs are designed to automatically communicate wirelessly with physician’s offices, hospitals, and manufacturers, routine tasks like reprogramming, data extraction, and software updates may spur even more accidental software glitches that could compromise the security of IMDs.
The FDA launched an “Infusion Pump Improvement Initiative” in April 2010, after receiving thousands of reports of problems associated with the use of infusion pumps that deliver fluids such as insulin and chemotherapy medication to patients electronically and mechanically.16 Between 2005 and 2009, the FDA received approximately 56,000 reports of adverse events related to infusion pumps, including numerous cases of injury and death. The agency analyzed the reports it received during the period in a white paper published in the spring of 2010 and found that the most common types of problems reported were associated with software defects or malfunctions, user interface issues, and mechanical or electrical failures. (The FDA said most of the pumps covered in the report are operated by a trained user, who programs the rate and duration of fluid delivery through a built-in software interface). During the period, 87 infusion pumps were recalled due to safety concerns, 14 of which were characterized as “Class I” – situations in which there is a reasonable probability that use of the recalled device will cause serious adverse health consequences or death. Software defects lead to over-and-under infusion and caused pre-programmed alarms on pumps to fail in emergencies or activate in absence of a problem. In one instance a “key bounce” caused an infusion pump to occasionally register one keystroke (e.g., a single zero, “0”) as multiple keystrokes (e.g., a double zero, “00”), causing an inappropriate dosage to be delivered to a patient. Though the report does not apply to implantable infusion pumps, it demonstrates the prevalence of software-related malfunctions in medical device software and the flexibility of the FDA’s pre-market approval process.
In order to facilitate the early detection and correction of any design defects, the FDA has begun offering manufacturers “the option of submitting the software code used in their infusion pumps for analysis by agency experts prior to premarket review of new or modified devices.” It is also working with third-party researchers to develop “an open-source software safety model and reference specifications that infusion pump manufacturers can use or adapt to verify the software in their devices.”
Though the voluntary initiative appears to be an endorsement of the safety benefits of FOSS and a step in the right direction, it does not address the overall problem of software insecurity since it is not mandatory.
III Why Free Software is More Secure
“Continuous and broad peer-review, enabled by publicly available source code, improves software reliability and security through the identification and elimination of defects that might otherwise go unrecognized by the core development team. Conversely, where source code is hidden from the public, attackers can attack the software anyway …. Hiding source code does inhibit the ability of third parties to respond to vulnerabilities (because changing software is more difficult without the source code), but this is obviously not a security advantage. In general, ‘Security by Obscurity’ is widely denigrated.” — Department of Defense (DoD) FAQ’s response to question: “Doesn’t Hiding Source Code Automatically Make Software More Secure?”17
The DoD indicates that FOSS has been central to its Information Technology (IT) operations since the mid-1990’s, and, according to some estimates, one-third to one-half of the software currently used by the agency is open source.18 The U.S. Office of Management and Budget issued a memorandum in 2004, which recommends that all federal agencies use the same procurement procedures for FOSS as they would for proprietary software.19 Other public sector agencies, such as the U.S. Navy, the Federal Aviation Administration, the U.S. Census Bureau and the U.S. Patent and Trademark Office have been identified as recognizing the security benefits of publicly auditable source code.20
To understand why free and open source software has become a common component in the IT systems of so many businesses and organizations that perform life-critical or mission-critical functions, one must first accept that software bugs are a fact of life. The Software Engineering Institute estimates that an experienced software engineer produces approximately one defect for every 100 lines of code.21 Based on this estimate, even if most of the bugs in a modest, one million-line code base are fixed over the course of a typical program life cycle, approximately 1,000 bugs would remain.
In its first “State of Software Security” report released in March 2010, the private software security analysis firm Veracode reviewed the source code of 1,591 software applications voluntarily submitted by commercial vendors, businesses, and government agencies.22 Regardless of program origins, Veracode found that 58 percent of all software submitted for review did not meet the security assessment criteria the report established.23 Based on its findings, Veracode concluded that “most software is indeed very insecure …[and] more than half of the software deployed in enterprises today is potentially susceptible to an application layer attack similar to that used in the recent …Google security breaches.”24
Though open source applications had almost as many source code vulnerabilities upon first submission as proprietary programs, researchers found that they contained fewer potential backdoors than commercial or outsourced software and that open source project teams remediated security vulnerabilities within an average of 36 days of the first submission, compared to 48 days for internally developed applications and 82 days for commercial applications.25 Not only were bugs patched the fastest in open source programs, but the quality of remediation was also higher than commercial programs.26
Veracode’s study confirms the research and anecdotal evidence into the security benefits of open source software published over the past decade. According to the web-security analysis site SecurityPortal, vulnerabilities took an average of 11.2 days to be spotted in Red Hat/Linux systems with a standard deviation of 17.5 compared to an average of 16.1 days with a standard deviation of 27.7 in Microsoft programs.27
Sun Microsystems’ COO Bill Vass summed up the most common case for FOSS in a blog post published in April 2009: “By making the code open source, nothing can be hidden in the code,” Vass wrote. “If the Trojan Horse was made of glass, would the Trojans have rolled it into their city? NO.”28
Vass’ logic is backed up by numerous research papers and academic studies that have debunked the myth of security through obscurity and advanced the “more eyes, fewer bugs” thesis. Though it might seem counterintuitive, making source code publicly available for users, security analysts, and even potential adversaries does not make systems more vulnerable to attack in the long-run. To the contrary, keeping source code under lock-and-key is more likely to hamstring “defenders” by preventing them from finding and patching bugs that could be exploited by potential attackers to gain entry into a given code base, whether or not access is restricted by the supplier.29 “In a world of rapid communications among attackers where exploits are spread on the Internet, a vulnerability known to one attacker is rapidly learned by others,” reads a 2006 article comparing open source and proprietary software use in government systems.30 “For Open Source, the next assumption is that disclosure of a flaw will prompt other programmers to improve the design of defenses. In addition, disclosure will prompt many third parties — all of those using the software or the system — to install patches or otherwise protect themselves against the newly announced vulnerability. In sum, disclosure does not help attackers much but is highly valuable to the defenders who create new code and install it.”
Academia and internet security professionals appear to have reached a consensus that open, auditable source code gives users the ability to independently assess the exposure of a system and the risks associated with using it; enables bugs to be patched more easily and quickly; and removes dependence on a single party, forcing software suppliers and developers to spend more effort on the quality of their code, as authors Jaap-Henk Hoepman and Bart Jacobs also conclude in their 2007 article, Increased Security Through Open Source.31
By contrast, vulnerabilities often go unnoticed, unannounced, and unfixed in closed source programs because the vendor, rather than users who have a higher stake in maintaining the quality of software, is the only party allowed to evaluate the security of the code base.32 Some studies have argued that commercial software suppliers have less of an incentive to fix defects after a program is initially released so users do not become aware of vulnerabilities until after they have caused a problem. “Once the initial version of [a proprietary software product] has saturated its market, the producer’s interest tends to shift to generating upgrades …Security is difficult to market in this process because, although features are visible, security functions tend to be invisible during normal operations and only visible when security trouble occurs.”33
The consequences of manufacturers’ failure to disclose malfunctions to patients and physicians have proven fatal in the past. In 2005, a 21-year-old man died from cardiac arrest after the ICD he wore short-circuited and failed to deliver a life-saving shock. The fatal incident prompted Guidant, the manufacturer of the flawed ICD, to recall four different device models they sold. In total 70,000 Guidant ICDs were recalled in one of the biggest regulatory actions of the past 25 years.34
Guidant came under intense public scrutiny when the patient’s physician Dr. Robert Hauser discovered that the company first observed the flaw that caused his patient’s device to malfunction in 2002, and even went so far as to implement manufacturing changes to correct it, but failed to disclose it to the public or health-care industry.
The body of research analyzed for this paper points to the same conclusion: security is not achieved through obscurity and closed source programs force users to forfeit their ability to evaluate and improve a system’s security. Though there is lingering debate over the degree to which end-users contribute to the maintenance of FOSS programs and how to ensure the quality of the patches submitted, most of the evidence supports our paper’s central assumption that auditable, peer-reviewed software is comparatively more secure than proprietary programs.
Programs have different standards to ensure the quality of the patches submitted to open source programs, but even the most open, transparent systems have established methods of quality control. Well-established open source software, such as the kind favored by the DoD and the other agencies mentioned above, cannot be infiltrated by “just anyone.” To protect the code base from potential adversaries and malicious patch submissions, large open source systems have a “trusted repository” that only certain, “trusted,” developers can directly modify. As an additional safeguard, the source code is publicly released, meaning not only are there more people policing it for defects, but more copies of each version of the software exist making it easier to compare new code.
IV The FDA Review Process and Legal Obstacles to Device Manufacturer Accountability
“Implanted medical devices have enriched and extended the lives of countless people, but device malfunctions and software glitches have become modern ‘diseases’ that will continue to occur. The failure of manufacturers and the FDA to provide the public with timely, critical information about device performance, malfunctions, and ’fixes’ enables potentially defective devices to reach unwary consumers.” — Capitol Hill Hearing Testimony of William H. Maisel, Director of Beth Israel Deaconess Medical Center, May 12, 2009.
The FDA’s Center for Devices and Radiological Health (CDRH) is responsible for regulating medical devices, but since the Medical Device Modernization Act (MDMA) was passed in 1997 the agency has increasingly ceded control over the pre-market evaluation and post-market surveillance of IMDs to their manufacturers.35 While the agency has been making strides towards the MDMA’s stated objective of streamlining the device approval process, the expedient regulatory process appears to have come at the expense of the CDRH’s broader mandate to “protect the public health in the fields of medical devices” by developing and implementing programs “intended to assure the safety, effectiveness, and proper labeling of medical devices.”36
Since the MDMA was passed, the FDA has largely deferred these responsibilities to the companies that sell these devices.37 The legislation effectively allowed the businesses selling critical devices to establish their own set of pre-market safety evaluation standards and determine the testing conducted during the review process. Manufacturers also maintain a large degree of discretion over post-market IMD surveillance. Though IMD-manufacturers are obligated to inform the FDA if they alert physicians to a product defect or if the device is recalled, they determine whether a particular defect constitutes a public safety risk.
“Manufacturers should use good judgment when developing their quality system and apply those sections of the QS regulation that are applicable to their specific products and operations,” reads section 21 of Quality Standards regulation outlined on the FDA’s website. “Operating within this flexibility, it is the responsibility of each manufacturer to establish requirements for each type or family of devices that will result in devices that are safe and effective, and to establish methods and procedures to design, produce, distribute, etc. devices that meet the quality system requirements. The responsibility for meeting these requirements and for having objective evidence of meeting these requirements may not be delegated even though the actual work may be delegated.”
By implementing guidelines such as these, the FDA has refocused regulation from developing and implementing programs in the field of medical devices that protect the public health to auditing manufacturers’ compliance with their own standards.
“To the FDA, you are the experts in your device and your quality programs,” Jeff Geisler wrote in a 2010 book chapter, Software for Medical Systems.38 “Writing down the procedures is necessary — it is assumed that you know best what the procedures should be — but it is essential that you comply with your written procedures.”
The elastic regulatory standards are a product of the 1976 amendment to the Food, Drug, and Cosmetics Act.39The Amendment established three different device classes and outlined broad pre-market requirements that each category of IMD must meet depending on the risk it poses to a patient. Class I devices, whose failure would have no adverse health consequences, are not subject to a pre-market approval process. Class III devices that “support or sustain human life, are of substantial importance in preventing impairment of human health, or which present a potential, unreasonable risk of illness or injury,” such as IMDs, are subject to the most stringent FDA review process, Premarket Approval (PMA).40
By the FDA’s own admission, the original legislation did not account for technological complexity of IMDs, but neither has subsequent regulation.41
In 2002, an amendment to the MDMA was passed that was intended to help the FDA “focus its limited inspection resources on higher-risk inspections and give medical device firms that operate in global markets an opportunity to more efficiently schedule multiple inspections,” the agency’s website reads.42
The legislation further eroded the CDRH’s control over pre-market approval data, along with the FDA’s capacity to respond to rapid changes in medical treatment and the introduction of increasingly complex devices for a broader range of diseases. The new provisions allowed manufacturers to pay certain FDA-accredited inspectors to conduct reviews during the PMA process in lieu of government regulators. It did not outline specific software review procedures for the agency to conduct or precise requirements that medical device manufacturers must meet before introducing a new product. “The regulation …provides some guidance [on how to ensure the reliability of medical device software],” Joe Bremner wrote of the FDA’s guidance on software validation.43 “Written in broad terms, it can apply to all medical device manufacturers. However, while it identifies problems to be solved or an end point to be achieved, it does not specify how to do so to meet the intent of the regulatory requirement.”
The death of 21-year-old Joshua Oukrop in 2005 due to the failure of a Guidant device has increased calls for regulatory reform at the FDA.44 In a paper published shortly after Oukrop’s death, his physician, Dr. Hauser concluded that the FDA’s post-market ICD device surveillance system is broken.45
After returning the failed Prizm 2 DR pacemaker to Guidant, Dr. Hauser learned that the company had known the model was prone to the same defect that killed Oukrop for at least three years. Since 2002, Guidant received 25 different reports of failures in the Prizm model, three of which required rescue defibrillation. Though the company was sufficiently concerned about the problem to make manufacturing changes, Guidant continued to sell earlier models and failed to make patients and physicians aware that the Prizm was prone to electronic defects. They claimed that disclosing the defect was inadvisable because the risk of infection during de-implantation surgery posed a greater threat to public safety than device failure. “Guidant’s statistical argument ignored the basic tenet that patients have a fundamental right to be fully informed when they are exposed to the risk of death no matter how low that risk may be perceived,” Dr. Hauser argued. “Furthermore, by withholding vital information, Guidant had in effect assumed the primary role of managing high-risk patients, a responsibility that belongs to physicians. The prognosis of our young, otherwise healthy patient for a long, productive life was favorable if sudden death could have been prevented.”
The FDA was also guilty of violating the principle of informed consent. In 2004, Guidant had reported two different adverse events to the FDA that described the same defect in the Prizm 2 DR models, but the agency also withheld the information from the public. “The present experience suggests that the FDA is currently unable to satisfy its legal responsibility to monitor the safety of market released medical devices like the Prizm 2 DR,” he wrote, referring to the device whose failure resulted in his patient’s death. “The explanation for the FDA’s inaction is unknown, but it may be that the agency was not prepared for the extraordinary upsurge in ICD technology and the extraordinary growth in the number of implantations that has occurred in the past five years.”
While the Guidant recalls prompted increased scrutiny on the FDA’s medical device review process, it remains difficult to gauge the precise process of regulating IMD software or the public health risk posed by source code bugs since neither doctors, nor IMD users, are permitted to access it. Nonetheless, the information that does exist suggests that the pre-market approval process alone is not a sufficient consumer safeguard since medical devices are less likely than drugs to have demonstrated clinical safety before they are marketed.46
An article published in the Journal of the American Medical Association (JAMA) studied the safety and effectiveness data in every PMA application the FDA reviewed from January 2000 to December 2007 and concluded that “premarket approval of cardiovascular devices by the FDA is often based on studies that lack strength and may be prone to bias.”47 Of the 78 high-risk device approvals analyzed in the paper, 51 were based on a single study.48
The JAMA study noted that the need to address the inadequacies of the FDA’s device regulation process has become particularly urgent since the Supreme Court changed the landscape of medical liability law with its ruling in Riegel v. Medtronic in February 2008. The Court held that the plaintiff Charles Riegel could not seek damages in state court from the manufacturer of a catheter that exploded in his leg during an angioplasty. “Riegel v. Medtronic means that FDA approval of a device preempts consumers from suing because of problems with the safety or effectiveness of the device, making this approval a vital consumer protection safeguard.”49
Since the FDA is a federal agency, its authority supersedes state law. Based on the concept of preemption, the Supreme Court held that damages actions permitted under state tort law could not be filed against device manufacturers deemed to be in compliance with the FDA, even in the event of gross negligence. The decision eroded one of the last legal recourses to protect consumers and hold IMD manufacturers accountable for catastrophic, failure of an IMD. Not only are the millions of people who rely on IMD’s for their most life-sustaining bodily functions more vulnerable to software malfunctions than ever before, but they have little choice but to trust its manufacturers.
“It is clear that medical device manufacturers have responsibilities that extend far beyond FDA approval and that many companies have failed to meet their obligations,” William H. Maisel said in recent congressional testimony on the Medical Device Reform bill.50 “Yet, the U.S. Supreme Court ruled in their February 2008 decision, Riegel v. Medtronic, that manufacturers could not be sued under state law by patients harmed by product defects from FDA-approved medical devices …. [C]onsumers are unable to seek compensation from manufacturers for their injuries, lost wages, or health expenses. Most importantly, the Riegel decision eliminates an important consumer safeguard — the threat of manufacturer liability — and will lead to less safe medical devices and an increased number of patient injuries.”
In light of our research and the existing legal and regulatory limitations that prevent IMD users from holding medical device manufacturers accountable for critical software vulnerabilities, auditable source code is critical to minimize the harm caused by inevitable medical device software bugs.
V Conclusion
The Supreme Court’s decision in favor of Medtronic in 2008, increasingly flexible regulation of medical device software on the part of the FDA, and a spike in the level and scope of IMD usage over the past decade suggest a software liability nightmare on the horizon. We urge the FDA to introduce more stringent, mandatory standards to protect IMD-wearers from the potential adverse consequences of software malfunctions discussed in this paper. Specifically, we call on the FDA to require manufacturers of life-critical IMDs to publish the source code of medical device software so the public and regulators can examine and evaluate it. At the very least, we urge the FDA to establish a repository of medical device software running on implanted IMDs in order to ensure continued access to source code in the event of a catastrophic failure, such as the bankruptcy of a device manufacturer. While we hope regulators will require that the software of all medical devices, regardless of risk, be auditable, it is particularly urgent that these standards be included in the pre-market approval process of Class III IMDs. We hope this paper will also prompt IMD users, their physicians, and the public to demand greater transparency in the field of medical device software.
Notes
1Though software defects are never explicitly mentioned as the “Reason for Recall” in the alerts posted on the FDA’s website, the descriptions of device failures match those associated with souce-code errors. List of Device Recalls, U.S. Food & Drug Admin., http://www.fda.gov/MedicalDevices/Safety/RecallsCorrectionsRemovals/ListofRecalls/default.htm (last visited Jul. 19, 2010).
2Medtronic recalled its Lifepak 15 Monitor/Defibrillator in March 4, 2010 due to failures that were almost certainly caused by software defects that caused the device to unexpectedly shut-down and regain power on its own. The company admitted in a press release that it first learned that the recalled model was prone to defects eight years earlier and had submitted one “adverse event” report to the FDA. Medtronic, Physio-Control Field Correction to LIFEPAK 20/20e Defibrillator/ Monitors, BusinessWire (Jul. 02, 2010, 9:00 AM), http://www.businesswire.com/news/home/20100702005034/en/Physio-Control-Field-Correction-LIFEPAK%C2%AE-2020e-Defibrillator-Monitors.html
20/20e Defibrillator/ Monitors, BusinessWire (Jul. 02, 2010, 9:00 AM), http://www.businesswire.com/news/home/20100702005034/en/Physio-Control-Field-Correction-LIFEPAK%C2%AE-2020e-Defibrillator-Monitors.html
3Quality Systems Regulation, U.S. Food & Drug Admin., http://www.fda.gov/MedicalDevices/default.htm (follow “Device Advice: Device Regulation and Guidance” hyperlink; then follow “Postmarket Requirements (Devices)” hyperlink; then follow “Quality Systems Regulation” hyperlink) (last visited Jul. 2010)
4Riegel v. Medtronic, Inc., 552 U.S. 312 (2008).
5The Software Freedom Law Center (SFLC) prefers the term Free and Open Source Software (FOSS) to describe software that can be freely viewed, used, and modified by anyone. In this paper, we sometimes use mixed terminology, including the term “open source” to maintain consistency with the articles cited.
6See Josie Garthwaite, Hacking the Car: Cyber Security Risks Hit the Road, Earth2Tech (Mar. 19, 2010, 12:00 AM), http://earth2tech.com.
7Sanket S. Dhruva et al., Strength of Study Evidence Examined by the FDA in Premarket Approval of Cardiovascular Devices, 302 J. Am. Med. Ass’n 2679 (2009).
8Freedonia Group, Cardiac Implants, Rep. Buyer, Sept. 2008, available at
http://www.reportbuyer.com/pharma_healthcare/medical_devices/cardiac_implants.html.
9Id.
10Robert G. Hauser & Linda Kallinen, Deaths Associated With Implantable Cardioverter Defibrillator Failure and Deactivation Reported in the United States Food and Drug Administration Manufacturer and User Facility Device Experience Database, 1 HeartRhythm 399, available at http://www.heartrhythmjournal.com/article/S1547-5271%2804%2900286-3/.
11Charles Graeber, Profile of Kevin Fu, 33, TR35 2009 Innovator, Tech. Rev.,
http://www.technologyreview.com/TR35/Profile.aspx?trid=760 (last visited Jul. 9, 2010).
12See Tamara Denning, et al., Absence Makes the Heart Grow Fonder: New Directions for Implantable Medical Device Security, Proceedings of the 3rd Conference on Hot Topics in Security(2008), available at
http://www.cs.washington.edu/homes/yoshi/papers/HotSec2008/cloaker-hotsec08.pdf.
13Kevin Poulsen, Hackers Assault Epilepsy Patients via Computer, Wired News (Mar. 28, 2008),
http://www.wired.com/politics/security/news/2008/03/epilepsy.
14Id.
15Dolores R. Wallace & D. Richard Kuhn, Failure Modes in Medical Device Software: An Analysis of 15 Years of Recall Data, 8 Int’l J. Reliability Quality Safety Eng’g 351 (2001), available at http://csrc.nist.gov/groups/SNS/acts/documents/final-rqse.pdf.
Quicksearch
Popular Entries
- The great Ars Android interface shootout (131491)
- Norton cyber crime study offers striking revenue loss statistics (102342)
- MeCam $49 flying camera concept follows you around, streams video to your phone (100502)
- The PC inside your phone: A guide to the system-on-a-chip (58677)
- Norton cyber crime study offers striking revenue loss statistics (58571)
