The techno-wizards over at Google X, the company's R&D laboratory working on its self-driving cars and Project Glass,
linked 16,000 processors together to form a neural network and then had
it go forth and try to learn on its own. Turns out, massive digital
networks are a lot like bored humans poking at iPads.
The pretty amazing takeaway here is that this 16,000-processor neural
network, spread out over 1,000 linked computers, was not told to look
for any one thing, but instead discovered that a pattern revolved around cat pictures on its own.
This happened after Google presented the network with image stills
from 10 million random YouTube videos. The images were small thumbnails,
and Google's network was sorting through them to try and learn
something about them. What it found — and we have ourselves to blame for
this — was that there were a hell of a lot of cat faces.
"We never told it during the training, 'This is a cat,'" Jeff Dean, a Google fellow working on the project, told the New York Times. "It basically invented the concept of a cat. We probably have other ones that are side views of cats."
The network itself does not know what a cat is like you and I do. (It
wouldn't, for instance, feel embarrassed being caught watching
something like this
in the presence of other neural networks.) What it does realize,
however, is that there is something that it can recognize as being the
same thing, and if we gave it the word, it would very well refer to it
as "cat."
So, what's the big deal? Your computer at home is more than powerful
enough to sort images. Where Google's neural network differs is that it
looked at these 10 million images, recognized a pattern of cat faces,
and then grafted together the idea that it was looking at something
specific and distinct. It had a digital thought.
Andrew Ng, a computer scientist at Stanford University who is
co-leading the study with Dean, spoke to the benefit of something like a
self-teaching neural network: "The idea is that instead of having teams
of researchers trying to find out how to find edges, you instead throw a
ton of data at the algorithm and you let the data speak and have the
software automatically learn from the data." The size of the network is
important, too, and the human brain is "a million times larger in terms
of the number of neurons and synapses" than Google X's simulated mind,
according to the researchers.
"It'd be fantastic if it turns out that all we need to do is take
current algorithms and run them bigger," Ng added, "but my gut feeling
is that we still don't quite have the right algorithm yet."
At today’s hearing
of the Subcommittee on Intellectual Property, Competition and the
Internet of the House Judiciary Committee, I referred to an attempt to
“sabotage” the forthcoming Do Not Track standard. My written testimony
discussed a number of other issues as well, but Do Not Track was
clearly on the Representatives’ minds: I received multiple questions on
the subject. Because of the time constraints, oral answers at a
Congressional hearing are not the place for detail, so in this blog
post, I will expand on my answers this morning, and explain why I think
that word is appropriate to describe the current state of play.
Background
For years, advertising networks have offered the option to opt out
from their behavioral profiling. By visiting a special webpage provided
by the network, users can set a browser cookie saying, in effect, “This
user should not be tracked.” This system, while theoretically offering
consumers choice about tracking, suffers from a series of problems that
make it frequently ineffective in practice. For one thing, it relies
on repetitive opt-out: the user needs to visit multiple opt-out pages, a
daunting task given the large and constantly shifting list of
advertising companies, not all of which belong to industry groups with
coordinated opt-out pages. For another, because it relies on
cookies—the same vector used to track users in the first place—it is
surprisingly fragile. A user who deletes cookies to protect her privacy
will also delete the no-tracking cookie, thereby turning tracking back
on. The resulting system is a monkey’s paw: unless you ask for what you want in exactly the right way, you get nothing.
The idea of a Do Not Track header gradually emerged
in 2009 and 2010 as a simpler alternative. Every HTTP request by which
a user’s browser asks a server for a webpage contains a series of headers
with information about the webpage requested and the browser. Do Not
Track would be one more. Thus, the user’s browser would send, as part
of its request, the header:
DNT: 1
The presence of such a header would signal to the website that the
user requests not to be tracked. Privacy advocates and technologists
worked to flesh out the header; privacy officials in the United States
and Europe endorsed it. The World Wide Web Consortium (W3C) formed a
public Tracking Protection Working Group with a charter to design a technical standard for Do Not Track.
Significantly, a W3C standard is not law. The legal effect of Do Not
Track will come from somewhere else. In Europe, it may be enforced directly on websites under existing data protection law. In the United States, legislation has been introduced in the House and Senate
that would have the Federal Trade Commission promulgate Do Not Track
regulations. Without legislative authority, the FTC could not require
use of Do Not Track, but would be able to treat a website’s false claims
to honor Do Not Track as a deceptive trade practice. Since most online
advertising companies find it important from a public relations point
of view to be able to say that they support consumer choice, this last
option may be significant in practice. And finally, in an important recent paper,
Joshua Fairfield argues that use of the Do Not Track header itself
creates an enforceable contract prohibiting tracking under United States
law.
In all of these cases, the details of the Do Not Track standard will
be highly significant. Websites’ legal duties are likely to depend on
the technical duties specified in the standard, or at least be strongly
influenced by them. For example, a company that promises to be Do Not
Track compliant thereby promises to do what is required to comply with
the standard. If the standard ultimately allows for limited forms of
tracking for click-fraud prevention, the company can engage in those
forms of tracking even if the user sets the header. If not, it cannot.
Thus, there is a lot at stake in the Working Group’s discussions.
Internet Explorer and Defaults
On May 31, Microsoft announced that Do Not Track would be on by default
in Internet Explorer 10. This is a valuable feature, regardless of how
you feel about behavioral ad targeting itself. A recurring theme of
the online privacy wars is that unusably complicated privacy interfaces
confuse users in ways that cause them to make mistakes and undercut
their privacy. A default is the ultimate easy-to-use privacy control.
Users who care about what websites know about them do not need to
understand the details to take a simple step to protect themselves.
Using Internet Explorer would suffice by itself to prevent tracking from
a significant number of websites.
This is an important principle. Technology can empower users to
protect their privacy. It is impractical, indeed impossible, for users
to make detailed privacy choices about every last detail of their online
activities. The task of getting your privacy right is profoundly
easier if you have access to good tools to manage the details.
Antivirus companies compete vigorously to manage the details of malware
prevention for users. So too with privacy: we need thriving markets in
tools under the control of users to manage the details.
There is immense value if users can delegate some of their privacy
decisions to software agents. These delegation decisions should be dead
simple wherever possible. I use Ghostery
to block cookies. As tools go, it is incredibly easy to use—but it
still is not easy enough. The choice of browser is a simple choice, one
that every user makes. That choice alone should be enough to count as
an indication of a desire for privacy. Setting Do Not Track by default
is Microsoft’s offer to users. If they dislike the setting, they can
change it, or use a different browser.
The Pushback
Microsoft’s move intersected with a long-simmering discussion on the
Tracking Protection Working Group’s mailing list. The question of Do
Not Track defaults had been one of the first issues the Working Group raised when it launched in September 2011. The draft text that emerged by the spring remains painfully ambiguous on the issue. Indeed, the group’s May 30 teleconference—the
day before Microsoft’s announcement—showed substantial disagreement
about defaults and what a server could do if it believed it was seeing a
default Do Not Track header, rather than one explicitly set by the
user. Antivirus software AVG includes a cookie-blocking tool
that sets the Do Not Track header, which sparked extensive discussion
about plugins, conflicting settings, and explicit consent. And the last
few weeks following Microsoft’s announcement have seen a renewed debate
over defaults.
Many industry participants object to Do Not Track by default.
Technology companies with advertising networks have pushed for a crucial
pair of positions:
User agents (i.e. browsers and apps) that turned on Do Not Track by default would be deemed non-compliant with the standard.
Websites that received a request from a noncompliant user agent would be free to disregard a DNT: 1 header.
This position has been endorsed by representatives the three
companies I mentioned in my testimony today: Yahoo!, Google, and Adobe.
Thus, here is an excerpt from an email to the list by Shane Wiley from Yahoo!:
If you know that an UA is non-compliant, it should be fair to NOT
honor the DNT signal from that non-compliant UA and message this back to
the user in the well-known URI or Response Header.
Here is an excerpt from an email to the list by Ian Fette from Google:
There’s other people in the working group, myself included, who feel that
since you are under no obligation to honor DNT in the first place (it is
voluntary and nothing is binding until you tell the user “Yes, I am
honoring your DNT request”) that you already have an option to reject a
DNT:1 request (for instance, by sending no DNT response headers). The
question in my mind is whether we should provide websites with a mechanism
to provide more information as to why they are rejecting your request, e.g.
“You’re using a user agent that sets a DNT setting by default and thus I
have no idea if this is actually your preference or merely another large
corporation’s preference being presented on your behalf.”
And here is an excerpt from an email to the list by Roy Fielding from Adobe:
The server would say that the non-compliant browser is broken and
thus incapable of transmitting a true signal of the user’s preferences.
Hence, it will ignore DNT from that browser, though it may provide
other means to control its own tracking. The user’s actions are
irrelevant until they choose a browser capable of communicating
correctly or make use of some means other than DNT.
Pause here to understand the practical implications of writing this
position into the standard. If Yahoo! decides that Internet Explorer 10
is noncompliant because it defaults on, then users who picked Internet
Explorer 10 to avoid being tracked … will be tracked. Yahoo! will claim
that it is in compliance with the standard and Internet Explorer 10 is
not. Indeed, there is very little that an Internet Explorer 10 user
could do to avoid being tracked. Because her user agent is now flagged
by Yahoo! as noncompliant, even if she manually sets the header herself,
it will still be ignored.
The Problem
A cynic might observe how effectively this tactic neutralizes the
most serious threat that Do Not Track poses to advertisers: that people
might actually use it. Manual opt-out cookies are tolerable
because almost no one uses them. Even Do Not Track headers that are off
by default are tolerable because very few people will use them.
Microsoft’s and AVG’s decisions raise the possibility that significant
numbers of web users would be removed from tracking. Pleasing user
agent noncompliance is a bit of jujitsu, a way of meeting the threat
where it is strongest. The very thing that would make Internet Explorer
10’s Do Not Track setting widely used would be the very thing to
“justify” ignoring it.
But once websites have an excuse to look beyond the header they
receive, Do Not Track is dead as a practical matter. A DNT:1 header is
binary: it is present or it is not. But second-guessing interface
decisions is a completely open-ended question. Was the check box to
enable Do Not Track worded clearly? Was it bundled with some other user
preference? Might the header have been set by a corporate network
rather than the user? These are the kind of process questions that can
be lawyered to death. Being able to question whether a user really meant her Do Not Track header is a license to ignore what she does mean.
Return to my point above about tools. I run a browser with multiple
plugins. At the end of the day, these pieces of software collaborate to
set a Do Not Track header, or not. This setting is under my control: I
can install or uninstall any of the software that was responsible for
it. The choice of header is strictly between me and my user agent. As far as the Do Not Track specification is concerned,
websites should adhere to a presumption of user competence: whatever
value the header has, it has with the tacit or explicit consent of the
user.
Websites are not helpless against misconfigured software. If they
really think the user has lost control over her own computer, they have a
straightforward, simple way of finding out. A website can display a
popup window or an overlay, asking the user whether she really wants to
enable Do Not Track, and explaining the benefits disabling it would
offer. Websites have every opportunity to press their case for
tracking; if that case is as persuasive as they claim, they should have
no fear of making it one-on-one to users.
This brings me to the bitterest irony of Do Not Track defaults. For
more than a decade, the online advertising industry has insisted that
notice and an opportunity to opt out is sufficient choice for consumers.
It has fought long and hard against any kind of heightened consent
requirement for any of its practices. Opt-out, in short, is good
enough. But for Do Not Track, there and there alone, consumers
allegedly do not understand the issues, so consent must be explicit—and opt-in only.
Now What?
It is time for the participants in the Tracking Protection Working
Group to take a long, hard look at where the process is going. It is
time for the rest of us to tell them, loudly, that the process is going
awry. It is true that Do Not Track, at least in the present regulatory
environment, is voluntary. But it does not follow that the standard
should allow “compliant” websites to pick and choose which pieces to
comply with. The job of the standard is to spell out how a user agent
states a Do Not Track request, and what behavior is required of websites
that choose to implement the standard when they receive such a request.
That is, the standard must be based around a simple principle:
A Do Not Track header expresses a meaning, not a process.
The meaning of “DNT: 1” is that the receiving website should not
track the user, as spelled out in the rest of the standard. It is not
the website’s concern how the header came to be set.
We present the first large-scale analysis of hardware failure rates on a
million consumer PCs. We find that many failures are neither transient
nor independent. Instead, a large portion of hardware induced failures
are recurrent: a machine that crashes from a fault in hardware is up to
two orders of magnitude more likely to crash a second time. For example,
machines with at least 30 days of accumulated CPU time over an 8 month
period had a 1 in 190 chance of crashing due to a CPU subsystem fault.
Further, machines that crashed once had a probability of 1 in 3.3 of
crashing a second time. Our study examines failures due to faults within
the CPU, DRAMand disk subsystems. Our analysis spans desktops and
laptops, CPU vendor, overclocking, underclocking, generic vs. brand
name, and characteristics such as machine speed and calendar age. Among
our many results, we find that CPU fault rates are correlated with the
number of cycles executed, underclocked machines are significantly more
reliable than machines running at their rated speed, and laptops are
more reliable than desktops.
If a team of Harvard bioengineers has its way,
animal testing and experimentation could soon be replaced by
organ-on-a-chip technologies. Like SoCs (system-on-a-chip), which
shoehorn most of a digital computer into a single chip, an
organ-on-a-chip seeks to replicate the functions of a human organ on a
computer chip.
In Harvard’s case, its Wyss Institute has now created a living lung-on-a-chip, a heart-on-a-chip, and most recently a gut-on-a-chip.
We’re not talking about silicon chips simulating
the functions of various human organs, either. These organs-on-a-chip
contain real, living human cells. In the case of the gut-on-a-chip, a
single layer of human intestinal cells is coerced into growing on a
flexible, porous membrane, which is attached to the clear plastic walls
of the chip. By applying a vacuum pump, the membrane stretches and
recoils, just like a human gut going through the motions of peristalsis.
It is so close to the real thing that the gut-on-a-chip even supports
the growth of living microbes on its surface, like a real human
intestine.
In another example, the Wyss Institute has built a lung-on-a-chip,
which has human lung cells on the top, a membrane in the middle, and
blood capillary cells beneath. Air flows over the top, while real human
blood flows below. Again, a vacuum pump makes the lung-on-a-chip expand
and contract, like a human lung.
These chips are also quite
closely tied to the recent emergence of the lab-on-a-chip (LoC), which
combines microfluidics (exact control of tiny amounts of fluid) and
silicon technology to massively speed up the analysis of biological
systems, such as DNA. It is thanks to LoCs that we can sequence entire genomes in just a few hours — a task that previously took weeks or months.
These human organs-on-a-chip can be tested just
like a human subject — and the fact that they’re completely transparent
is obviously a rather large boon for observation, too. To test a drug,
the researchers simply add a solution of the compound to the chip, and
see how the intestinal (or heart or lung) cells react. In the case of
the lung-on-a-chip, the Wyss team is testing how the lung reacts to
possible toxins and pollutants. They can also see how fast drugs (or
foods) are absorbed, or test the effects of probiotics.
Perhaps
more importantly, these chips could help us better understand and treat
diseases. Many human diseases don’t have an animal analog. It’s very
hard to find a drug that combats Crohn’s disease when you can’t
effectively test out your drug on animals beforehand — a problem that
could be easily solved with the gut-on-a-chip. Likewise, it is very
common for drugs to pass animal testing, but then fail on humans.
Removing animal testing from the equation would save money and time, and
also alleviate any ethical concerns.
Moving
forward, the Wyss Institute, with funding from DARPA, is currently
researching a spleen-on-a-chip. This won’t be used for pharmaceutical
purposes, though; instead, DARPA wants to create a “portable spleen”
that can be inserted into soldiers to help battle sepsis (an infection
of the blood).
And therein lies the crux: If you can create a chip
that perfectly mimics the spleen or liver or intestine, then what’s to
stop you from inserting those chips into humans and replacing or
augmenting your current organs? Instead of getting your breasts
enlarged, you might one day have your liver enlarged, to better deal
with your alcoholism. Or how we connect all the organ chips together and
create a complete human-on-a-chip?
We've been writing a lot recently about how the private space industry
is poised to make space cheaper and more accessible. But in general,
this is for outfits such as NASA, not people like you and me.
Today, a company called NanoSatisfi is launching a Kickstarter project to send an Arduino-powered satellite into space, and you can send an experiment along with it.
Whether it's private industry or NASA or the ESA or anyone else,
sending stuff into space is expensive. It also tends to take
approximately forever to go from having an idea to getting funding to
designing the hardware to building it to actually launching something.
NanoSatisfi, a tech startup based out of NASA's Ames Research Center
here in Silicon Valley, is trying to change all of that (all of
it) by designing a satellite made almost entirely of off-the-shelf (or
slightly modified) hobby-grade hardware, launching it quickly, and then
using Kickstarter to give you a way to get directly involved.
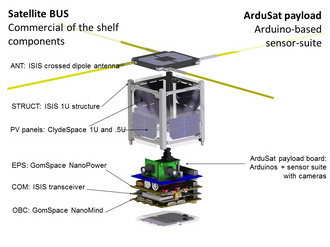
ArduSat is based on the CubeSat platform, a standardized satellite
framework that measures about four inches on a side and weighs under
three pounds. It's just about as small and cheap as you can get when it
comes to launching something into orbit, and while it seems like a very
small package, NanoSatisfi is going to cram as much science into that
little cube as it possibly can.
Here's the plan: ArduSat, as its name implies, will run on Arduino
boards, which are open-source microcontrollers that have become wildly
popular with hobbyists. They're inexpensive, reliable, and packed with
features. ArduSat will be packing between five and ten individual
Arduino boards, but more on that later. Along with the boards, there
will be sensors. Lots of sensors, probably 25 (or more), all compatible with the Arduinos and all very tiny and inexpensive. Here's a sampling:
Yeah, so that's a lot of potential for science, but the entire
Arduino sensor suite is only going to cost about $1,500. The rest of the
satellite (the power system, control system, communications system,
solar panels, antennae, etc.) will run about $50,000, with the launch
itself costing about $35,000. This is where you come in.
NanoSatisfi is looking for Kickstarter funding to pay for just the
launch of the satellite itself: the funding goal is $35,000. Thanks to
some outside investment, it's able to cover the rest of the cost itself.
And in return for your help, NanoSatisfi is offering you a chance to
use ArduSat for your own experiments in space, which has to be one of the coolest Kickstarter rewards ever.
For a $150 pledge, you can reserve 15 imaging slots on ArduSat.
You'll be able to go to a website, see the path that the satellite will
be taking over the ground, and then select the targets you want to
image. Those commands will be uploaded to the ArduSat, and when it's in
the right spot in its orbit, it'll point its camera down at Earth and
take a picture which will be then emailed right to you. From space.
For $300, you can upload your own personal message to ArduSat, where it will be broadcast back to Earth from space
for an entire day. ArduSat is in a polar orbit, so over the course of
that day, it'll circle the Earth seven times and your message will be
broadcast over the entire globe.
For $500, you can take advantage of the whole point of ArduSat and
run your very own experiment for an entire week on a selection of
ArduSat's sensors. You know, in space. Just to be
clear, it's not like you're just having your experiment run on data
that's coming back to Earth from the satellite. Rather, your experiment
is uploaded to the satellite itself, and it's actually running on one of
the Arduino boards on ArduSat real time, which is why there are so many
identical boards packed in there.
Now, NanoSatisfi itself doesn't really expect to get involved with a
lot of the actual experiments that the ArduSat does: rather, it's saying
"here's this hardware platform we've got up in space, it's got all
these sensors, go do cool stuff." And if the stuff that you can do with
the existing sensor package isn't cool enough for you, backers of the
project will be able to suggest new sensors and new configurations, even
for the very first generation ArduSat.
To make sure you don't brick the satellite with buggy code,
NanSatisfi will have a duplicate satellite in a space-like environment
here on Earth that it'll use to test out your experiment first. If
everything checks out, your code gets uploaded to the satellite, runs in
whatever timeslot you've picked, and then the results get sent back to
you after your experiment is completed. Basically, you're renting time
and hardware on this satellite up in space, and you can do (almost)
whatever you want with that.
ArduSat has a lifetime of anywhere from six months to two years. None
of this payload stuff (neither the sensors nor the Arduinos) are
specifically space-rated or radiation-hardened or anything like that,
and some of them will be exposed directly to space. There will be some
backups and redundancy, but partly, this will be a learning experience
to see what works and what doesn't. The next generation of ArduSat will
take all of this knowledge and put it to good use making a more capable
and more reliable satellite.
This, really, is part of the appeal of ArduSat: with a fast,
efficient, and (relatively) inexpensive crowd-sourced model, there's a
huge potential for improvement and growth. For example, If this
Kickstarter goes bananas and NanoSatisfi runs out of room for people to
get involved on ArduSat, no problem, it can just build and launch
another ArduSat along with the first, jammed full of (say) fifty more
Arduinos so that fifty more experiments can be run at the same time. Or
it can launch five more ArduSats. Or ten more. From the decision to
start developing a new ArduSat to the actual launch of that ArduSat is a
period of just a few months. If enough of them get up there at the same
time, there's potential for networking multiple ArduSats together up in
space and even creating a cheap and accessible global satellite array.
If this sounds like a lot of space junk in the making, don't worry: the
ArduSats are set up in orbits that degrade after a year or two, at which
point they'll harmlessly burn up in the atmosphere. And you can totally
rent the time slot corresponding with this occurrence and measure
exactly what happens to the poor little satellite as it fries itself to a
crisp.
Longer term, there's also potential for making larger ArduSats with
more complex and specialized instrumentation. Take ArduSat's camera:
being a little tiny satellite, it only has a little tiny camera, meaning
that you won't get much more detail than a few kilometers per pixel. In
the future, though, NanoSatisfi hopes to boost that to 50 meters (or
better) per pixel using a double or triple-sized satellite that it'll
call OptiSat. OptiSat will just have a giant camera or two, and in
addition to taking high resolution pictures of Earth, it'll also be able
to be turned around to take pictures of other stuff out in space. It's
not going to be the next Hubble, but remember, it'll be under your control.
NanoSatisfi's Peter Platzer holds a prototype ArduSat board,
including the master controller, sensor suite, and camera. Photo: Evan
Ackerman/DVICE
Assuming the Kickstarter campaign goes well, NanoSatisfi hopes to
complete construction and integration of ArduSat by about the end of the
year, and launch it during the first half of 2013. If you don't manage
to get in on the Kickstarter, don't worry- NanoSatisfi hopes that there
will be many more ArduSats with many more opportunities for people to
participate in the idea. Having said that, you should totally get
involved right now: there's no cheaper or better way to start doing a
little bit of space exploration of your very own.
Check out the ArduSat Kickstarter video below, and head on through the link to reserve your spot on the satellite.
If Facebook were a country, a conceit that founder Mark Zuckerberg has entertained in public, its 900 million members would make it the third largest in the world.
It would far outstrip any regime past or present in how intimately
it records the lives of its citizens. Private conversations, family
photos, and records of road trips, births, marriages, and deaths all
stream into the company's servers and lodge there. Facebook has
collected the most extensive data set ever assembled on human social
behavior. Some of your personal information is probably part of it.
And yet, even as Facebook has embedded itself into modern life, it
hasn't actually done that much with what it knows about us. Now that
the company has gone public, the pressure to develop new sources of
profit (see "The Facebook Fallacy")
is likely to force it to do more with its hoard of information. That
stash of data looms like an oversize shadow over what today is a modest
online advertising business, worrying privacy-conscious Web users (see "Few Privacy Regulations Inhibit Facebook")
and rivals such as Google. Everyone has a feeling that this
unprecedented resource will yield something big, but nobody knows quite
what.
Heading Facebook's effort to figure out what can be learned from all our data is Cameron Marlow,
a tall 35-year-old who until recently sat a few feet away from
Zuckerberg. The group Marlow runs has escaped the public attention that
dogs Facebook's founders and the more headline-grabbing features of its
business. Known internally as the Data Science Team, it is a kind of
Bell Labs for the social-networking age. The group has 12
researchers—but is expected to double in size this year. They apply
math, programming skills, and social science to mine our data for
insights that they hope will advance Facebook's business and social
science at large. Whereas other analysts at the company focus on
information related to specific online activities, Marlow's team can
swim in practically the entire ocean of personal data that Facebook
maintains. Of all the people at Facebook, perhaps even including the
company's leaders, these researchers have the best chance of discovering
what can really be learned when so much personal information is
compiled in one place.
Facebook has all this information because it has found ingenious
ways to collect data as people socialize. Users fill out profiles with
their age, gender, and e-mail address; some people also give additional
details, such as their relationship status and mobile-phone number. A
redesign last fall introduced profile pages in the form of time lines
that invite people to add historical information such as places they
have lived and worked. Messages and photos shared on the site are often
tagged with a precise location, and in the last two years Facebook has
begun to track activity elsewhere on the Internet, using an addictive
invention called the "Like" button.
It appears on apps and websites outside Facebook and allows people to
indicate with a click that they are interested in a brand, product, or
piece of digital content. Since last fall, Facebook has also been able
to collect data on users' online lives beyond its borders automatically:
in certain apps or websites, when users listen to a song or read a news
article, the information is passed along to Facebook, even if no one
clicks "Like." Within the feature's first five months, Facebook
catalogued more than five billion instances
of people listening to songs online. Combine that kind of information
with a map of the social connections Facebook's users make on the site,
and you have an incredibly rich record of their lives and interactions.
"This is the first time the world has seen this scale and quality
of data about human communication," Marlow says with a
characteristically serious gaze before breaking into a smile at the
thought of what he can do with the data. For one thing, Marlow is
confident that exploring this resource will revolutionize the scientific
understanding of why people behave as they do. His team can also help
Facebook influence our social behavior for its own benefit and that of
its advertisers. This work may even help Facebook invent entirely new
ways to make money.
Contagious Information
Marlow eschews the collegiate programmer style of Zuckerberg and
many others at Facebook, wearing a dress shirt with his jeans rather
than a hoodie or T-shirt. Meeting me shortly before the company's
initial public offering in May, in a conference room adorned with a
six-foot caricature of his boss's dog spray-painted on its glass wall,
he comes across more like a young professor than a student. He might
have become one had he not realized early in his career that Web
companies would yield the juiciest data about human interactions.
In 2001, undertaking a PhD at MIT's Media Lab, Marlow created a
site called Blogdex that automatically listed the most "contagious"
information spreading on weblogs. Although it was just a research
project, it soon became so popular that Marlow's servers crashed.
Launched just as blogs were exploding into the popular consciousness and
becoming so numerous that Web users felt overwhelmed with information,
it prefigured later aggregator sites such as Digg and Reddit. But Marlow
didn't build it just to help Web users track what was popular online.
Blogdex was intended as a scientific instrument to uncover the social
networks forming on the Web and study how they spread ideas. Marlow went
on to Yahoo's research labs to study online socializing for two years.
In 2007 he joined Facebook, which he considers the world's most powerful
instrument for studying human society. "For the first time," Marlow
says, "we have a microscope that not only lets us examine social
behavior at a very fine level that we've never been able to see before
but allows us to run experiments that millions of users are exposed to."
Marlow's team works with managers across Facebook to find patterns
that they might make use of. For instance, they study how a new feature
spreads among the social network's users. They have helped Facebook
identify users you may know but haven't "friended," and recognize those
you may want to designate mere "acquaintances" in order to make their
updates less prominent. Yet the group is an odd fit inside a company
where software engineers are rock stars who live by the mantra "Move
fast and break things." Lunch with the data team has the feel of a
grad-student gathering at a top school; the typical member of the group
joined fresh from a PhD or junior academic position and prefers to talk
about advancing social science than about Facebook as a product or
company. Several members of the team have training in sociology or
social psychology, while others began in computer science and started
using it to study human behavior. They are free to use some of their
time, and Facebook's data, to probe the basic patterns and motivations
of human behavior and to publish the results in academic journals—much
as Bell Labs researchers advanced both AT&T's technologies and the
study of fundamental physics.
It may seem strange that an eight-year-old company without a
proven business model bothers to support a team with such an academic
bent, but Marlow says it makes sense. "The biggest challenges Facebook
has to solve are the same challenges that social science has," he says.
Those challenges include understanding why some ideas or fashions spread
from a few individuals to become universal and others don't, or to what
extent a person's future actions are a product of past communication
with friends. Publishing results and collaborating with university
researchers will lead to findings that help Facebook improve its
products, he adds.
For one example of how Facebook can serve as a proxy for examining
society at large, consider a recent study of the notion that any person
on the globe is just six degrees of separation from any other. The
best-known real-world study, in 1967, involved a few hundred people
trying to send postcards to a particular Boston stockholder. Facebook's
version, conducted in collaboration with researchers from the University
of Milan, involved the entire social network as of May 2011, which
amounted to more than 10 percent of the world's population. Analyzing
the 69 billion friend connections among those 721 million people showed
that the world is smaller than we thought: four intermediary friends are
usually enough to introduce anyone to a random stranger. "When
considering another person in the world, a friend of your friend knows a
friend of their friend, on average," the technical paper pithily
concluded. That result may not extend to everyone on the planet, but
there's good reason to believe that it and other findings from the Data
Science Team are true to life outside Facebook. Last year the Pew
Research Center's Internet & American Life Project found that 93
percent of Facebook friends had met in person. One of Marlow's
researchers has developed a way to calculate a country's "gross national
happiness" from its Facebook activity by logging the occurrence of
words and phrases that signal positive or negative emotion. Gross
national happiness fluctuates in a way that suggests the measure is
accurate: it jumps during holidays and dips when popular public figures
die. After a major earthquake in Chile in February 2010, the country's
score plummeted and took many months to return to normal. That event
seemed to make the country as a whole more sympathetic when Japan
suffered its own big earthquake and subsequent tsunami in March 2011;
while Chile's gross national happiness dipped, the figure didn't waver
in any other countries tracked (Japan wasn't among them). Adam Kramer,
who created the index, says he intended it to show that Facebook's data
could provide cheap and accurate ways to track social trends—methods
that could be useful to economists and other researchers.
Other work published by the group has more obvious utility for
Facebook's basic strategy, which involves encouraging us to make the
site central to our lives and then using what it learns to sell ads. An early study
looked at what types of updates from friends encourage newcomers to the
network to add their own contributions. Right before Valentine's Day
this year a blog post from the Data Science Team
listed the songs most popular with people who had recently signaled on
Facebook that they had entered or left a relationship. It was a hint of
the type of correlation that could help Facebook make useful predictions
about users' behavior—knowledge that could help it make better guesses
about which ads you might be more or less open to at any given time.
Perhaps people who have just left a relationship might be interested in
an album of ballads, or perhaps no company should associate its brand
with the flood of emotion attending the death of a friend. The most
valuable online ads today are those displayed alongside certain Web
searches, because the searchers are expressing precisely what they want.
This is one reason why Google's revenue is 10 times Facebook's. But
Facebook might eventually be able to guess what people want or don't
want even before they realize it.
Recently the Data Science Team has begun to use its unique
position to experiment with the way Facebook works, tweaking the
site—the way scientists might prod an ant's nest—to see how users react.
Eytan Bakshy, who joined Facebook last year after collaborating with
Marlow as a PhD student at the University of Michigan, wanted to learn
whether our actions on Facebook are mainly influenced by those of our
close friends, who are likely to have similar tastes. That would shed
light on the theory that our Facebook friends create an "echo chamber"
that amplifies news and opinions we have already heard about. So he
messed with how Facebook operated for a quarter of a billion users. Over
a seven-week period, the 76 million links that those users shared with
each other were logged. Then, on 219 million randomly chosen occasions,
Facebook prevented someone from seeing a link shared by a friend. Hiding
links this way created a control group so that Bakshy could assess how
often people end up promoting the same links because they have similar
information sources and interests.
He found that our close friends strongly sway which information we
share, but overall their impact is dwarfed by the collective influence
of numerous more distant contacts—what sociologists call "weak ties." It
is our diverse collection of weak ties that most powerfully determines
what information we're exposed to.
That study provides strong evidence against the idea that social networking creates harmful "filter bubbles," to use activist Eli Pariser's
term for the effects of tuning the information we receive to match our
expectations. But the study also reveals the power Facebook has. "If
[Facebook's] News Feed is the thing that everyone sees and it controls
how information is disseminated, it's controlling how information is
revealed to society, and it's something we need to pay very close
attention to," Marlow says. He points out that his team helps Facebook
understand what it is doing to society and publishes its findings to fulfill a public duty to transparency. Another recent study,
which investigated which types of Facebook activity cause people to
feel a greater sense of support from their friends, falls into the same
category.
But Marlow speaks as an employee of a company that will prosper
largely by catering to advertisers who want to control the flow of
information between its users. And indeed, Bakshy is working with
managers outside the Data Science Team to extract advertising-related
findings from the results of experiments on social influence.
"Advertisers and brands are a part of this network as well, so giving
them some insight into how people are sharing the content they are
producing is a very core part of the business model," says Marlow.
Facebook told prospective investors before its IPO that people
are 50 percent more likely to remember ads on the site if they're
visibly endorsed by a friend. Figuring out how influence works could
make ads even more memorable or help Facebook find ways to induce more
people to share or click on its ads.
Social Engineering
Marlow says his team wants to divine the rules of online social
life to understand what's going on inside Facebook, not to develop ways
to manipulate it. "Our goal is not to change the pattern of
communication in society," he says. "Our goal is to understand it so we
can adapt our platform to give people the experience that they want."
But some of his team's work and the attitudes of Facebook's leaders show
that the company is not above using its platform to tweak users'
behavior. Unlike academic social scientists, Facebook's employees have a
short path from an idea to an experiment on hundreds of millions of
people.
In April, influenced in part by conversations over dinner with his
med-student girlfriend (now his wife), Zuckerberg decided that he
should use social influence within Facebook to increase organ donor
registrations. Users were given an opportunity to click a box on their
Timeline pages to signal that they were registered donors, which
triggered a notification to their friends. The new feature started a
cascade of social pressure, and organ donor enrollment increased by a
factor of 23 across 44 states.
Marlow's team is in the process of publishing results from the
last U.S. midterm election that show another striking example of
Facebook's potential to direct its users' influence on one another.
Since 2008, the company has offered a way for users to signal that they
have voted; Facebook promotes that to their friends with a note to say
that they should be sure to vote, too. Marlow says that in the 2010
election his group matched voter registration logs with the data to see
which of the Facebook users who got nudges actually went to the polls.
(He stresses that the researchers worked with cryptographically
"anonymized" data and could not match specific users with their voting
records.)
This is just the beginning. By learning more about how small changes
on Facebook can alter users' behavior outside the site, the company
eventually "could allow others to make use of Facebook in the same way,"
says Marlow. If the American Heart Association wanted to encourage
healthy eating, for example, it might be able to refer to a playbook of
Facebook social engineering. "We want to be a platform that others can
use to initiate change," he says.
Advertisers, too, would be eager to know in greater detail what
could make a campaign on Facebook affect people's actions in the outside
world, even though they realize there are limits to how firmly human
beings can be steered. "It's not clear to me that social science will
ever be an engineering science in a way that building bridges is," says
Duncan Watts, who works on computational social science at Microsoft's
recently opened New York research lab and previously worked alongside
Marlow at Yahoo's labs. "Nevertheless, if you have enough data, you can
make predictions that are better than simply random guessing, and that's
really lucrative."
Doubling Data
Like other social-Web companies, such as Twitter, Facebook has
never attained the reputation for technical innovation enjoyed by such
Internet pioneers as Google. If Silicon Valley were a high school, the
search company would be the quiet math genius who didn't excel socially
but invented something indispensable. Facebook would be the annoying kid
who started a club with such social momentum that people had to join
whether they wanted to or not. In reality, Facebook employs hordes of
talented software engineers (many poached from Google and other
math-genius companies) to build and maintain its irresistible club. The
technology built to support the Data Science Team's efforts is
particularly innovative. The scale at which Facebook operates has led it
to invent hardware and software that are the envy of other companies
trying to adapt to the world of "big data."
In a kind of passing of the technological baton, Facebook built
its data storage system by expanding the power of open-source software
called Hadoop, which was inspired by work at Google and built at Yahoo.
Hadoop can tame seemingly impossible computational tasks—like working on
all the data Facebook's users have entrusted to it—by spreading them
across many machines inside a data center. But Hadoop wasn't built with
data science in mind, and using it for that purpose requires
specialized, unwieldy programming. Facebook's engineers solved that
problem with the invention of Hive, open-source software that's now
independent of Facebook and used by many other companies. Hive acts as a
translation service, making it possible to query vast Hadoop data
stores using relatively simple code. To cut down on computational
demands, it can request random samples of an entire data set, a feature
that's invaluable for companies swamped by data. Much of Facebook's data
resides in one Hadoop store more than 100 petabytes (a million
gigabytes) in size, says Sameet Agarwal, a director of engineering at
Facebook who works on data infrastructure, and the quantity is growing
exponentially. "Over the last few years we have more than doubled in
size every year," he says. That means his team must constantly build
more efficient systems.
All this has given Facebook a unique level of expertise, says Jeff Hammerbacher,
Marlow's predecessor at Facebook, who initiated the company's effort to
develop its own data storage and analysis technology. (He left Facebook
in 2008 to found Cloudera, which develops Hadoop-based systems to
manage large collections of data.) Most large businesses have paid
established software companies such as Oracle a lot of money for data
analysis and storage. But now, big companies are trying to understand
how Facebook handles its enormous information trove on open-source
systems, says Hammerbacher. "I recently spent the day at Fidelity
helping them understand how the 'data scientist' role at Facebook was
conceived ... and I've had the same discussion at countless other
firms," he says.
As executives in every industry try to exploit the opportunities
in "big data," the intense interest in Facebook's data technology
suggests that its ad business may be just an offshoot of something much
more valuable. The tools and techniques the company has developed to
handle large volumes of information could become a product in their own
right.
Mining for Gold
Facebook needs new sources of income to meet investors'
expectations. Even after its disappointing IPO, it has a staggeringly
high price-to-earnings ratio that can't be justified by the barrage of
cheap ads the site now displays. Facebook's new campus in Menlo Park,
California, previously inhabited by Sun Microsystems, makes that
pressure tangible. The company's 3,500 employees rattle around in enough
space for 6,600. I walked past expanses of empty desks in one building;
another, next door, was completely uninhabited. A vacant lot waited
nearby, presumably until someone invents a use of our data that will
justify the expense of developing the space.
One potential use would be simply to sell insights mined from the information. DJ Patil,
data scientist in residence with the venture capital firm Greylock
Partners and previously leader of LinkedIn's data science team, believes
Facebook could take inspiration from Gil Elbaz, the inventor of
Google's AdSense ad business, which provides over a quarter of Google's
revenue. He has moved on from advertising and now runs a fast-growing
startup, Factual,
that charges businesses to access large, carefully curated collections
of data ranging from restaurant locations to celebrity body-mass
indexes, which the company collects from free public sources and by
buying private data sets. Factual cleans up data and makes the result
available over the Internet as an on-demand knowledge store to be tapped
by software, not humans. Customers use it to fill in the gaps in their
own data and make smarter apps or services; for example, Facebook itself
uses Factual for information about business locations. Patil points out
that Facebook could become a data source in its own right, selling
access to information compiled from the actions of its users. Such
information, he says, could be the basis for almost any kind of
business, such as online dating or charts of popular music. Assuming
Facebook can take this step without upsetting users and regulators, it
could be lucrative. An online store wishing to target its promotions,
for example, could pay to use Facebook as a source of knowledge about
which brands are most popular in which places, or how the popularity of
certain products changes through the year.
Hammerbacher agrees that Facebook could sell its data science and
points to its currently free Insights service for advertisers and
website owners, which shows how their content is being shared on
Facebook. That could become much more useful to businesses if Facebook
added data obtained when its "Like" button tracks activity all over the
Web, or demographic data or information about what people read on the
site. There's precedent for offering such analytics for a fee: at the
end of 2011 Google started charging $150,000 annually for a premium
version of a service that analyzes a business's Web traffic.
Back at Facebook, Marlow isn't the one who makes decisions about
what the company charges for, even if his work will shape them. Whatever
happens, he says, the primary goal of his team is to support the
well-being of the people who provide Facebook with their data, using it
to make the service sm
True, as Tom Henderson, principal researcher for ExtremeLabs and a colleague, told me, there’s a “Schwarzschild
radius surrounding Apple. It’s not just a reality distortion field;
it’s a whole new dimension. Inside, time slows and light never escapes–
as time compresses to an amorphous mass.
“Coddled, stroked, and massaged,” Henderson continued, “Apple users
start to sincerely believe the distortions regarding the economic life,
the convenience, and the subtle beauties of their myriad products.
Unknowingly, they sacrifice their time, their money, their privacy, and
soon, their very souls. Comparing Apple with Android, the parallels to
Syria and North Korea come to mind, despot-led personality cults.”
I wouldn’t go that far. While I prefer Android, I can enjoy using iOS
devices as well. Besides, Android fans can be blind to its faults just
as much as the most besotted Apple fan.
For example, it’s true that ICS has all the features that iOS 6 will eventually have, but you can only find ICS on 7.1 percent of all currently running Android devices. Talk to any serious Android user, and you’ll soon hear complaints about how they can’t update their systems.
You name an Android vendor-HTC, Motorola, Samsung, etc. -and I can
find you a customer who can’t update their smartphone or tablet to the
latest and greatest version of the operating system. The techie Android
fanboy response to this problem is just “ROOT IT.” It’s not that easy.
First, the vast majority of Android users are as about as able to
root their smartphone as I am to run a marathon. Second, alternative
Android device firmwares don’t always work with every device. Even the
best of them, Cyanogen ICS, can have trouble with some devices.
Another issue is consistency. When you buy an iPhone or an iPad you
know exactly what the interface is going to work and look like. With
Android devices, you never know quite what you’re going to get. We talk
about ICS as if it’s one thing-and it is from a developer’s
viewpoint-but ICS on different phones such as the HTC One X doesn’t look or feel much like say the Samsung Galaxy S III.
A related issue is that the iOS interface is simply cleaner and more
user-friendly than any Android interface I’d yet to see. One of Apple’s
slogans is “It just works.” Well, actually sometimes it doesn’t work.
ITunes, for example, has been annoying me for years now. But, when it
comes to device interfaces, iOS does just work. Android implementations,
far too often, doesn’t.
So, yes, Android does more today than Apple’s iOS promises to do
tomorrow, but that’s only part of the story. The full story includes
that iOS is very polished and very closed, while Android is somewhat
messy and very open. To me, it’s that last bit-that Apple is purely
proprietary while Android is largely open source-based-that insures that
I’m going to continue to use Android devices.
Now, if only Google can get everyone on the same page with updates and the interface, I’ll be perfectly happy!
It's been quite a year for artificial plant life,
but Singapore has really branched out with its garden of solar-powered
super trees that will reach up to 50 meters high. The Bay South garden,
which is filled with 18 of these trees, will open on June 29.
The "Supertree Grove" comprises a fraction of the Gardens by the Bay,
a 250-acre landscaping project. The 18 trees will act as vertical
gardens with living vines and flowers snaking up the mechanical trees.
11 of the trees have solar photovoltaic systems to create energy for
lighting and for heating the steel framework that will help cultivate
the plant life growing on it.
They'll vary in size from 25 to 50 meters tall and will also collect
water and act as air venting ducts for nearby conservatories.
The most amazing part of the man-made forest might be the size and
scope of them, as they tower above the urban landscape they decorate.
If you follow the world of Android
tablets and phones, you may have heard a lot about Tegra 3 over the
last year. Nvidia's chip currently powers many of the top Android
tablets, and should be found in a few Android smartphones by the end of
the year. It may even form the foundation of several upcoming Windows 8
tablets and possibly future phones running Windows Phone 8. So what is
the Tegra 3 chip, and why should you care whether or not your phone or
tablet is powered by one?
Nvidia's system-on-chip
Tegra is the brand for Nvidia's line of system-on-chip (SoC) products
for phones, tablets, media players, automobiles, and so on. What's a
system-on-chip? Essentially, it's a single chip that combines all the
major functions needed for a complete computing system: CPU cores,
graphics, media encoding and decoding, input-output, and even cellular
or Wi-Fi communcations and radios. The Tegra series competes with chips
like Qualcomm's Snapdragon, Texas Instruments' OMAP, and Samsung's
Exynos.
The first Tegra chip was a flop. It was used in very few products,
notably the ill-fated Zune HD and Kin smartphones from Microsoft. Tegra
2, an improved dual-core processor, was far more successful but still
never featured in enough devices to become a runaway hit.
Tegra 3 has been quite the success so far. It is found in a number of popular Android tablets like the Eee Pad Transformer Prime, and is starting to find its way into high-end phones like the global version of the HTC One X
(the North American version uses a dual-core Snapdragon S4 instead, as
Tegra 3 had not been qualified to work with LTE modems yet). Expect to
see it in more Android phones and tablets internationally this fall.
4 + 1 cores
Tegra 3 is based on the ARM processor design and architecture, as are
most phone and tablet chips today. There are many competing ARM-based
SoCs, but Tegra 3 was one of the first to include four processor cores.
There are now other quad-core SoCs from Texas Instruments and Samsung,
but Nvidia's has a unique defining feature: a fifth low-power core.
All five of the processor cores are based on the ARM Cortex-A9
design, but the fifth core is made using a special low-power process
that sips battery at low speeds, but doesn't scale up to high speeds
very well. It is limited to only 500MHz, while the other cores run up to
1.4GHz (or 1.5GHz in single-core mode).
When your phone or tablet is in sleep mode, or you're just performing
very simple operations or using very basic apps, like the music player,
Tegra 3 shuts down its four high-power cores and uses only the
low-power core. It's hard to say if this makes it far more efficient
than other ARM SoCs, but battery life on some Tegra 3 tablets has been
quite good.
Tegra 3 under a microscope. You can see the five CPU cores in the center.
Good, not great, graphics
Nvidia's heritage is in graphics processors. The company's claim to
fame has been its GPUs for traditional laptops, desktops, and servers.
You might expect Tegra 3 to have the best graphics processing power of
any tablet or phone chip, but that doesn't appear to be the case. Direct
graphics comparisons can be difficult, but there's a good case to be
made that the A5X processor in the new iPad has a far more powerful
graphics processor. Still, Tegra 3 has plenty of graphics power, and
Nvidia works closely with game developers to help them optimize their
software for the platform. Tegra 3 supports high-res display output (up
to 2560 x 1600) and improved video decoding capabilities compared to
earlier Tegra chips.
Do you need one?
The million-dollar question is: Does the Tegra 3 chip provide a truly
better experience than other SoCs? Do you need four cores, or even "4 +
1"? The answer is no. Most smartphone and tablet apps don't make great
use of multiple CPU cores, and making each core faster can often do more
for the user experience than adding more cores. That said, you
shouldn't avoid a product because it has a Tegra 3 chip, either. Its
performance and battery life appear to be quite competitive in today's
tablet and phone market. Increasingly, the overall quality of a product
is determined by its design, size, weight, display quality, camera
quality, and other features more than mere processor performance.
Consider PCWorld's review of the North American HTC One X; with the dual-core Snapdragon S4 instead of Tegra 3, performance was still very impressive.
IN THE classic science-fiction film “2001”, the ship’s computer, HAL,
faces a dilemma. His instructions require him both to fulfil the ship’s
mission (investigating an artefact near Jupiter) and to keep the
mission’s true purpose secret from the ship’s crew. To resolve the
contradiction, he tries to kill the crew.
As robots become more autonomous, the notion of computer-controlled
machines facing ethical decisions is moving out of the realm of science
fiction and into the real world. Society needs to find ways to ensure
that they are better equipped to make moral judgments than HAL was.
A bestiary of robots
Military technology, unsurprisingly, is at the forefront of the march towards self-determining machines (see Technology Quarterly).
Its evolution is producing an extraordinary variety of species. The
Sand Flea can leap through a window or onto a roof, filming all the
while. It then rolls along on wheels until it needs to jump again. RiSE,
a six-legged robo-cockroach, can climb walls. LS3, a dog-like robot,
trots behind a human over rough terrain, carrying up to 180kg of
supplies. SUGV, a briefcase-sized robot, can identify a man in a crowd
and follow him. There is a flying surveillance drone the weight of a
wedding ring, and one that carries 2.7 tonnes of bombs.
Robots are spreading in the civilian world, too, from the flight deck to the operating theatre (see article).
Passenger aircraft have long been able to land themselves. Driverless
trains are commonplace. Volvo’s new V40 hatchback essentially drives
itself in heavy traffic. It can brake when it senses an imminent
collision, as can Ford’s B-Max minivan. Fully self-driving vehicles are
being tested around the world. Google’s driverless cars have clocked up
more than 250,000 miles in America, and Nevada has become the first
state to regulate such trials on public roads. In Barcelona a few days
ago, Volvo demonstrated a platoon of autonomous cars on a motorway.
As they become smarter and more widespread, autonomous machines are
bound to end up making life-or-death decisions in unpredictable
situations, thus assuming—or at least appearing to assume—moral agency.
Weapons systems currently have human operators “in the loop”, but as
they grow more sophisticated, it will be possible to shift to “on the
loop” operation, with machines carrying out orders autonomously.
As that happens, they will be presented with ethical dilemmas. Should
a drone fire on a house where a target is known to be hiding, which may
also be sheltering civilians? Should a driverless car swerve to avoid
pedestrians if that means hitting other vehicles or endangering its
occupants? Should a robot involved in disaster recovery tell people the
truth about what is happening if that risks causing a panic? Such
questions have led to the emergence of the field of “machine ethics”,
which aims to give machines the ability to make such choices
appropriately—in other words, to tell right from wrong.
One way of dealing with these difficult questions is to avoid them
altogether, by banning autonomous battlefield robots and requiring cars
to have the full attention of a human driver at all times. Campaign
groups such as the International Committee for Robot Arms Control have
been formed in opposition to the growing use of drones. But autonomous
robots could do much more good than harm. Robot soldiers would not
commit rape, burn down a village in anger or become erratic
decision-makers amid the stress of combat. Driverless cars are very
likely to be safer than ordinary vehicles, as autopilots have made
planes safer. Sebastian Thrun, a pioneer in the field, reckons
driverless cars could save 1m lives a year.
Instead, society needs to develop ways of dealing with the ethics of
robotics—and get going fast. In America states have been scrambling to
pass laws covering driverless cars, which have been operating in a legal
grey area as the technology runs ahead of legislation. It is clear that
rules of the road are required in this difficult area, and not just for
robots with wheels.
The best-known set of guidelines for robo-ethics are the “three laws
of robotics” coined by Isaac Asimov, a science-fiction writer, in 1942.
The laws require robots to protect humans, obey orders and preserve
themselves, in that order. Unfortunately, the laws are of little use in
the real world. Battlefield robots would be required to violate the
first law. And Asimov’s robot stories are fun precisely because they
highlight the unexpected complications that arise when robots try to
follow his apparently sensible rules. Regulating the development and use
of autonomous robots will require a rather more elaborate framework.
Progress is needed in three areas in particular.
Three laws for the laws of robotics
First, laws are needed to determine whether the designer, the
programmer, the manufacturer or the operator is at fault if an
autonomous drone strike goes wrong or a driverless car has an accident.
In order to allocate responsibility, autonomous systems must keep
detailed logs so that they can explain the reasoning behind their
decisions when necessary. This has implications for system design: it
may, for instance, rule out the use of artificial neural networks,
decision-making systems that learn from example rather than obeying
predefined rules.
Second, where ethical systems are embedded into robots, the judgments
they make need to be ones that seem right to most people. The
techniques of experimental philosophy, which studies how people respond
to ethical dilemmas, should be able to help. Last, and most important,
more collaboration is required between engineers, ethicists, lawyers and
policymakers, all of whom would draw up very different types of rules
if they were left to their own devices. Both ethicists and engineers
stand to benefit from working together: ethicists may gain a greater
understanding of their field by trying to teach ethics to machines, and
engineers need to reassure society that they are not taking any ethical
short-cuts.
Technology has driven mankind’s progress, but each new advance has
posed troubling new questions. Autonomous machines are no different. The
sooner the questions of moral agency they raise are answered, the
easier it will be for mankind to enjoy the benefits that they will
undoubtedly bring.