Monday, January 18. 2016
MIT Researchers Train An Algorithm To Predict How Boring Your Selfie Is
Via TechCrunch
-----

Researchers at MIT’s Computer Science and Artificial Intelligence Lab (CSAIL) have created an algorithm they claim can predict how memorable or forgettable an image is almost as accurately as a human — which is to say that their tech can predict how likely a person would be to remember or forget a particular photo.
The algorithm performed 30 per cent better than existing algorithms and was within a few percentage points of the average human performance, according to the researchers.
The team has put a demo of their tool online here, where you can upload your selfie to get a memorability score and view a heat map showing areas the algorithm considers more or less memorable. They have also published a paper on the research which can be found here.
Here are some examples of images I ran through their MemNet algorithm, with resulting memorability scores and most and least forgettable areas depicted via heat map:
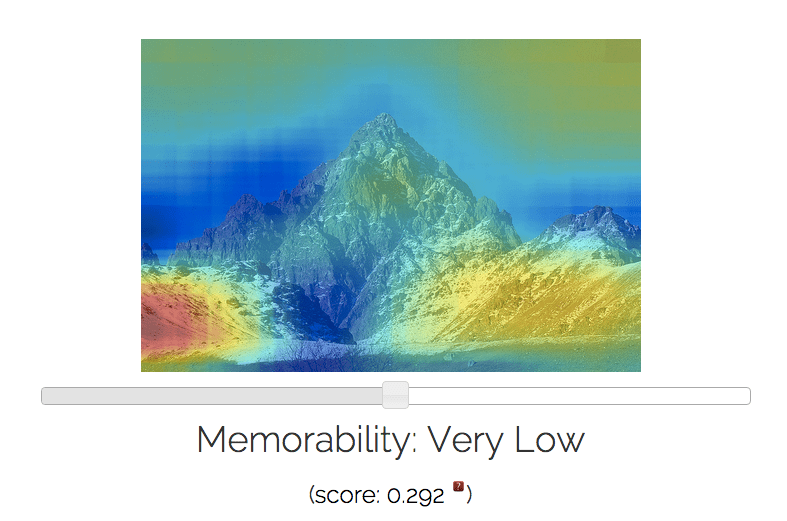
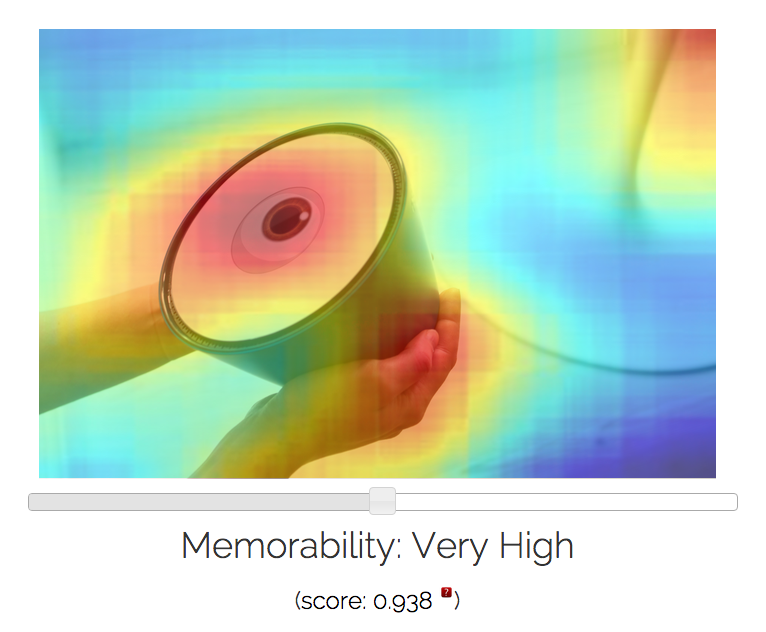
Potential applications for the algorithm are very broad indeed when you consider how photos and photo-sharing remains the currency of the social web. Anything that helps improve understanding of how people process visual information and the impact of that information on memory has clear utility.
The team says it plans to release an app in future to allow users to tweak images to improve their impact. So the research could be used to underpin future photo filters that do more than airbrush facial features to make a shot more photogenic — but maybe tweak some of the elements to make the image more memorable too.
Beyond helping people create a more lasting impression with their selfies, the team envisages applications for the algorithm to enhance ad/marketing content, improve teaching resources and even power health-related applications aimed at improving a person’s capacity to remember or even as a way to diagnose errors in memory and perhaps identify particular medical conditions.
The MemNet algorithm was created using deep learning AI techniques, and specifically trained on tens of thousands of tagged images from several different datasets all developed at CSAIL — including LaMem, which contains 60,000 images each annotated with detailed metadata about qualities such as popularity and emotional impact.
Publishing the LaMem database alongside their paper is part of the team’s effort to encourage further research into what they say has often been an under-studied topic in computer vision.
Asked to explain what kind of patterns the deep-learning algorithm is trying to identify in order to predict memorability/forgettability, PhD candidate at MIT CSAIL, Aditya Khosla, who was lead author on a related paper, tells TechCrunch: “This is a very difficult question and active area of research. While the deep learning algorithms are extremely powerful and are able to identify patterns in images that make them more or less memorable, it is rather challenging to look under the hood to identify the precise characteristics the algorithm is identifying.
“In general, the algorithm makes use of the objects and scenes in the image but exactly how it does so is difficult to explain. Some initial analysis shows that (exposed) body parts and faces tend to be highly memorable while images showing outdoor scenes such as beaches or the horizon tend to be rather forgettable.”
The research involved showing people images, one after another, and asking them to press a key when they encounter an image they had seen before to create a memorability score for images used to train the algorithm. The team had about 5,000 people from the Amazon Mechanical Turk crowdsourcing platform view a subset of its images, with each image in their LaMem dataset viewed on average by 80 unique individuals, according to Khosla.
In terms of shortcomings, the algorithm does less well on types of images it has not been trained on so far, as you’d expect — so it’s better on natural images and less good on logos or line drawings right now.
“It has not seen how variations in colors, fonts, etc affect the memorability of logos, so it would have a limited understanding of these,” says Khosla. “But addressing this is a matter of capturing such data, and this is something we hope to explore in the near future — capturing specialized data for specific domains in order to better understand them and potentially allow for commercial applications there. One of those domains we’re focusing on at the moment is faces.”
The team has previously developed a similar algorithm for face memorability.
Discussing how the planned MemNet app might work, Khosla says there are various options for how images could be tweaked based on algorithmic input, although ensuring a pleasing end photo is part of the challenge here. “The simple approach would be to use the heat map to blur out regions that are not memorable to emphasize the regions of high memorability, or simply applying an Instagram-like filter or cropping the image a particular way,” he notes.
“The complex approach would involve adding or removing objects from images automatically to change the memorability of the image — but as you can imagine, this is pretty hard — we would have to ensure that the object size, shape, pose and so on match the scene they are being added to, to avoid looking like a photoshop job gone bad.”
Looking ahead, the next step for the researchers will be to try to update their system to be able to predict the memory of a specific person. They also want to be able to better tailor it for individual “expert industries” such as retail clothing and logo-design.
How many training images they’d need to show an individual person before being able to algorithmically predict their capacity to remember images in future is not yet clear. “This is something we are still investigating,” says Khosla.
Wednesday, January 06. 2016
New internet error code identifies censored websites
Via Slash Gear

Everyone on the internet has come across at least couple error codes, the most well-known being 404, for page not found, while other common ones include 500, for internal server error, or 403, for a "forbidden" page. However, with latter, there's the growing issue of why a certain webpage has become forbidden, or who made it so. In an effort to address things like censorship or "legal obstacles," a new code has been published, to be used when legal demands require access to a page be blocked: error 451.
The number is a knowing reference Fahrenheit 451, the novel by Ray Bradbury that depicted a dystopian future where books are banned for spreading dissenting ideas, and in burned as a way censor the spread of information. The code itself was approved for use by the Internet Engineering Steering Group (IESG), which helps maintain internet standards.
The idea for code 451 originally came about around 3 years ago, when a UK court ruling required some websites to block The Pirate Bay. Most sites in turn used the 403 "forbidden" code, making it unclear to users about what the issue was. The goal of 451 is to eliminate some of the confusion around why sites may be blocked.
The use of the code is completely voluntary, however, and requires developers to begin adopting it. But if widely implemented, it should be able to communicate to users that some information has been taken down because of a legal demand, or is being censored by a national government.
Monday, January 04. 2016
Your Algorithmic Self Meets Super-Intelligent AI
Via Tech Crunch

As humanity debates the threats and opportunities of advanced artificial intelligence, we are simultaneously enabling that technology through the increasing use of personalization that is understanding and anticipating our needs through sophisticated machine learning solutions.
In effect, while using personalization technologies in our everyday lives, we are contributing in a real way to the development of the intelligent systems we purport to fear.
Perhaps uncovering the currently inaccessible personalization systems is crucial for creating a sustainable relationship between humans and super–intelligent machines?
From Machines Learning About You…
Industry giants are currently racing to develop more intelligent and lucrative AI solutions. Google is extending the ways machine learning can be applied in search, and beyond. Facebook’s messenger assistant M is combining deep learning and human curators to achieve the next level in personalization.
With your iPhone you’re carrying Apple’s digital assistant Siri with you everywhere; Microsoft’s counterpart Cortana can live in your smartphone, too. IBM’s Watson has highlighted its diverse features, varying from computer vision and natural language processing to cooking skills and business analytics.
At the same time, your data and personalized experiences are used to develop and train the machine learning systems that are powering the Siris, Watsons, Ms and Cortanas. Be it a speech recognition solution or a recommendation algorithm, your actions and personal data affect how these sophisticated systems learn more about you and the world around you.
The less explicit fact is that your diverse interactions — your likes, photos, locations, tags, videos, comments, route selections, recommendations and ratings — feed learning systems that could someday transform into super–intelligent AIs with unpredictable consequences.
As of today, you can’t directly affect how your personal data is used in these systems.
In these times, when we’re starting to use serious resources to contemplate the creation of ethical frameworks for super–intelligent AIs-to-be, we also should focus on creating ethical terms for the use of personal data and the personalization technologies that are powering the development of such systems.
To make sure that you as an individual continue to have a meaningful agency in the emerging algorithmic reality, we need learning algorithms that are on your side and solutions that augment and extend your abilities. How could this happen?
…To Machines That Learn For You
Smart devices extend and augment your memory (no forgotten birthdays) and brain processing power (no calculating in your head anymore). And they augment your senses by letting you experience things beyond your immediate environment (think AR and VR).
The web itself gives you access to a huge amount of diverse information and collective knowledge. The next step would be that smart devices and systems enhance and expand your abilities even more. What is required for that to happen in a human-centric way?
Data Awareness And Algorithmic Accountability
Algorithmic systems and personal data are too often seen as something abstract, incomprehensible and uncontrollable. Concretely, how many really stopped using Facebook or Google after PRISM came out in the open? Or after we learned that we are exposed to continuous A/B testing that is used to develop even more powerful algorithms?
More and more people are getting interested in data ethics and algorithmic accountability. Academics are already analyzing the effects of current data policies and algorithmic systems. Educational organizations are starting to emphasize the importance of coding and digital literacy.
Initiatives such as VRM, Indie Web and MyData are raising awareness on alternative data ecosystems and data management practices. Big companies like Apple and various upcoming startups are bringing personal data issues to the mainstream discussion.
Yet we still need new tools and techniques to become more data aware and to see how algorithms can be more beneficial for us as unique individuals. We need apps and data visualizations with great user experience to illuminate the possibilities of more human-centric personalization.
It’s time to create systems that evaluate algorithmic biases and keep them in check. More accessible algorithms and transparent data policies are created only through wider collaboration that brings together companies, developers, designers, users and scientists alike.
Personal Machine Learning Systems
Personalization technologies are already augmenting your decision making and future thinking by learning from you and recommending to you what to see and do next. However, not on your own terms. Rather than letting someone else and their motives and values dictate how the algorithms work and affect your life, it’s time to create solutions, such as algorithmic angels, that let you develop and customize your own algorithms and choose how they use your data.
When you’re in control, you can let your personal learning system access previously hidden data and surface intimate insights about your own behavior, thus increasing your self-awareness in an actionable way.
Personal learners could help you develop skills related to work or personal life, augmenting and expanding your abilities. For example, learning languages, writing or playing new games. Fitness or mediation apps powered by your personal algorithms would know you better than any personal trainer.
Google’s experiments with deep learning and image manipulation showed us how machine learning could be used to augment creative output. Systems capable of combining your data with different materials like images, text, sound and video could expand your abilities to see and utilize new and unexpected connections around you.
In effect, your personal algorithm can take a mind-expanding “trip” on your behalf, letting you see music or sense other dimensions beyond normal human abilities. By knowing you, personal algorithms can expose you to new diverse information, thus breaking your existing filter bubbles.
Additionally, people tinkering with their personal algorithms would create more “citizen algorithm experts,” like “citizen scientists,” coming up with new ideas, solutions and observations, stemming from real live situations and experiences.
However, personally adjustable algorithms for the general public are not happening overnight, even though Google recently open-sourced parts of its machine learning framework. But it’s possible to see how today’s personalization experiences can someday evolve into customizable algorithms that strengthen your agency and capacity to deal with other algorithmic systems.
Algorithmic Self
The next step is that your personal algorithms become a more concrete part of you, continuously evolving with you by learning from your interactions both in digital and physical environments. Your algorithmic self combines your personal abilities and knowledge with machine learning systems that adapt to you and work for you. Be it your smartwatch, self-driving car or an intelligent home system, they can all be spirited by your algorithmic self.
Your algorithmic self also can connect with other algorithmic selves, thus empowering you with the accumulating collective knowledge and intelligence. To expand your existing skills and faculties, your algorithmic self also starts to learn and act on its own, filtering information, making online transactions and comparing best options on your behalf. It makes you more resourceful, and even a better person, when you can concentrate on things that really require your human presence and attention.
Partly algorithmic humans are not bound by existing human capabilities; new skills and abilities emerge when human intelligence is extended with algorithmic selves. For example, your algorithmic self can multiply to execute different actions simultaneously. Algorithmic selves could also create simple simulations by playing out different scenarios involving your real-life choices and their consequences, helping you to make better decisions in the future.
Algorithmic selves — tuned by your data and personal learners — also could be the key when creating invasive human-computer interfaces that connect digital systems directly to your brain, expanding human brain concretely beyond the “wetware.”
But to ensure that your algorithmic self works for your benefit, could you trust someone building that for you without you participating in the process?
Machine learning expert Pedro Domingos says in his new book “The Master Algorithm” that “[m]achine learning will not single-handedly determine the future… it’s what we decide to do with it that counts.”
Machines are still far from human intelligence. No one knows exactly when super–intelligent AIs will become concrete reality. But developing personal machine learning systems could enable us to interact with any algorithmic entities, be it an obtrusive recommendation algorithm or a super–intelligent AI.
In general, being more transparent on how learning algorithms work and use our data could be crucial for creating ethical and sustainable artificial intelligence. And potentially, maybe we wouldn’t need to fear being overpowered by our own creations.
Friday, January 01. 2016
what3words - a new way to communicate location

what3words is a geocoding system for the simple communication of precise locations. what3words encodes geographic co-ordinates into 3 dictionary words (for example, the Statue of Liberty is located at planet.inches.most). what3words is different from other alphanumeric location systems and GPS coordinates in that it displays 3 words rather than long strings of numbers or random letters or numbers. what3words has an iOS App, Android App, a website and an API that enables bi-directional conversion of what3words address and latitude/longitude co-ordinates.
Quicksearch
Popular Entries
- The great Ars Android interface shootout (131491)
- Norton cyber crime study offers striking revenue loss statistics (102342)
- MeCam $49 flying camera concept follows you around, streams video to your phone (100503)
- The PC inside your phone: A guide to the system-on-a-chip (58677)
- Norton cyber crime study offers striking revenue loss statistics (58571)
Categories

Show tagged entries
Syndicate This Blog
Calendar
|
|
January '16 |
|
||||
| Mon | Tue | Wed | Thu | Fri | Sat | Sun |
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |