Tuesday, February 19. 2013
3Doodler 3D printer pen hits Kickstarter
Via Slashgear
-----
3D printers are undeniably cool, but their price also puts them out of the reach of most; that’s where 3Doodler steps in, a 3D printing pen hitting Kickstarter today and promising to make sketches physical. The chubby stylus squirts out of a stream of thermoplastic from its 270 degree-C nib, which is instantly cooled by an integrated fan. By laying different streams of plastic, tugging up streams of it to make 3D structures, and piecing different layers together, you can create 3D designs on a budget.

In fact, early Kickstarter backers will be able to get the 3Doodler from $50, though that award tier is already nearly halfway claimed at time of writing. Next is the $75 bracket, which should stick around a little longer, with the eventual Kickstarter goal being $30,000.

Unlike traditional printers, which require programming, the 3Doodler takes a more abstract approach. You can freeform draw sketches, or alternatively trace out patterns that have been printed, and then peel the set plastic off; 3Doodler suggests possibilities include jewelry, 3D models, artwork, and more.
It’s not going to be the way you print your next coffee cup or car wheel, as we’ve seen promised from regular 3D printers, but the plug-and-play approach has plenty of appeal nonetheless. The Kickstarter runs for the next month, with first deliveries expected in the fall of 2013 assuming it’s funded.
Technical Reference – Intel® HTML5 App Porter Tool - BETA
Via Intel Software
-----
Introduction
The Intel® HTML5 App Porter Tool - BETA is an application that helps mobile application developers to port native iOS* code into HTML5, by automatically translating portions of the original code into HTML5. This tool is not a complete solution to automatically port 100% of iOS* applications, but instead it speeds up the porting process by translating as much code and artifacts as possible.
It helps in the translation of the following artifacts:
- Objective-C* (and a subset of C) source code into JavaScript
- iOS* API types and calls into JavaScript/HTML5 objects and calls
- Layouts of views inside Xcode* Interface Builder (XIB) files into HTML + CSS files
- Xcode* project files into Microsoft* Visual Studio* 2012 projects
This document provides a high-level explanation about how the tool works and some details about supported features. This overview will help you determine how to process the different parts of your project and take the best advantage from the current capabilities.
How does it work?
The Intel® HTML5 App Porter Tool - BETA is essentially a source-to-source translator that can handle a number of conversions from Objective-C* into JavaScript/HTML5 including the translation of APIs calls. A number of open source projects are used as foundation for the conversion including a modified version of Clang front-end, LayerD framework and jQuery Mobile for widgets rendering in the translated source code.
Translation of Objective-C into JavaScript
At a high level, the transformation pipeline looks like this:
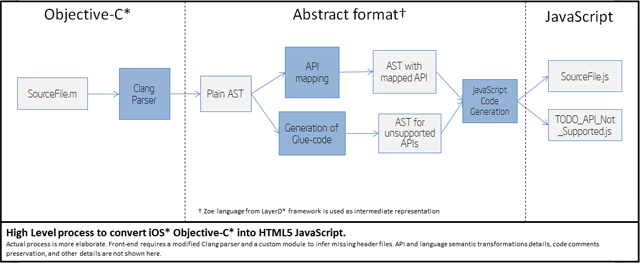
This pipeline follows the following stages:
- Parsing of Objective-C* files into an intermediate AST (Abstract Syntax Tree).
- Mapping of supported iOS* API calls into equivalent JavaScript calls.
- Generation of placeholder definitions for unsupported API calls.
- Final generation of JavaScript and HTML5 files.
About coverage of API mappings
Mapping APIs from iOS* SDK into JavaScript is a task that involves a good deal of effort. The iOS* APIs have thousands of methods and hundreds of types. Fortunately, a rather small amount of those APIs are in fact heavily used by most applications. The graph below conceptually shows how many APIs need to be mapped in order to have certain level of translation for API calls .
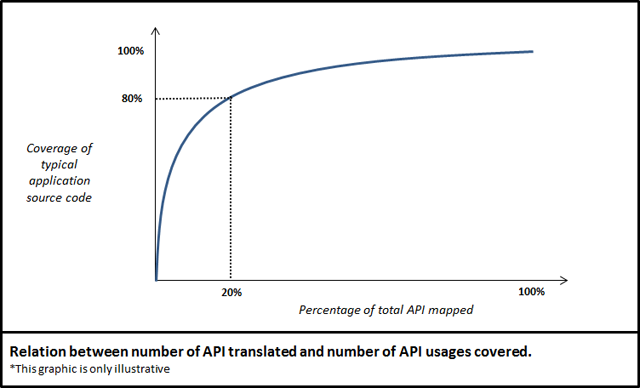
Currently, the Intel® HTML5 App Porter Tool - BETA supports the most used types and methods from:
- UIKit framework
- Foundation framework
Additionally, it supports a few classes of other frameworks such as CoreGraphics. For further information on supported APIs refer to the list of supported APIs.
Generation of placeholder definitions and TODO JavaScript files
For the APIs that the Intel® HTML5 App Porter Tool - BETA cannot translate, the tool generates placeholder functions in "TODO" files. In the translated application, you will find one TODO file for each type that is used in the original application and which has API methods not supported by the current version. For example, in the following portion of code:
1 |
-(void)sampleMethod |
2 |
{ |
3 |
UIButton* myButton = [UIButton buttonWithType:UIButtonTypeRoundedRect]; |
4 |
|
5 |
[myButton setTitle:text forState:UIControlStateNormal]; |
6 |
|
7 |
myButton.showsTouchWhenHighlighted = YES; |
8 |
} |
If property setter for showsTouchWhenHighligthed is not supported by the tool, it will generate the following placeholder for you to provide its implementation:
1 |
APT.Button.prototype.setShowsTouchWhenHighligthed = function(arg1) { |
2 |
//
================================================================ //
REFERENCES TO THIS FUNCTION: // line(108): SampleCode.m // In scope:
Test.sampleMethod // Actual arguments types: [boolean] // Expected
return type: [unknown type] // |
3 |
if (APT.Global.THROW_IF_NOT_IMPLEMENTED) |
4 |
{ |
5 |
// TODO remove exception handling when implementing this method |
6 |
throw "Not implemented function: APT.Button.setShowsTouchWhenHighligthed"; |
7 |
} |
8 |
}; |
These placeholders are created for methods, constants, and types that the tool does not support. Additionally, these placeholders may be generated for APIs other than the iOS* SDK APIs. If some files from the original application (containing class or function definitions) are not included in the translation process, the tool may also generate placeholders for the definitions in those missing files.
In each TODO file, you will find details about where those types, methods, or constants are used in the original code. Moreover, for each function or method the TODO file includes information about the type of the arguments that were inferred by the tool. Using these TODO files, you can complete the translation process by the providing the placeholders with your own implementation for that API.
Translation of XIB files into HTML/CSS code
The Intel® HTML5 App Porter Tool - BETA translates most of the definitions in the Xcode* Interface Builder files (i.e.,
XIB files) into equivalent HTML/CSS code. These HTML files use JQuery*
markup to define layouts equivalent to the views in the original XIB
files. That markup is defined based on the translated version of the
view classes and can be accessed programmatically.
Moreover, most
of the events that are linked with handlers in the original application
code are also linked with their respective handles in the translated
version. All the view controller objects, connection logic between
objects and event handlers from all translated XIB files are included in
the XibBoilerplateCode.js. Only one XibBoilerplateCode.js file is created per application.
The figure below shows how the different components of each XIB file are translated.
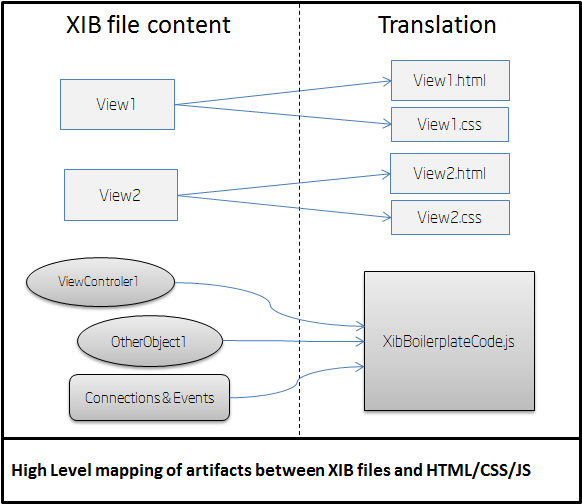
This is a summary of the artifacts generated from XIB files:
- For each view inside an XIB file, a pair of HTML+CSS files is generated.
- Objects inside XIB files, such as Controllers and Delegates, and instantiation code are generated in the
XibBoilerplateCode.jsfile. - Connections between objects and events handlers for views described
inside XIB files are also implemented by generated code in the
XibBoilerplateCode.jsfile.
For further information on supported widgets and properties refer to the Supported .XIB file featuressection.
Architecture of translated applications
The translated application keeps the very same high level structure as the original one. Constructs such as Objective-C* interfaces, categories, C structs, functions, variables, and statements are kept without significant changes in the translated code but expressed in JavaScript.
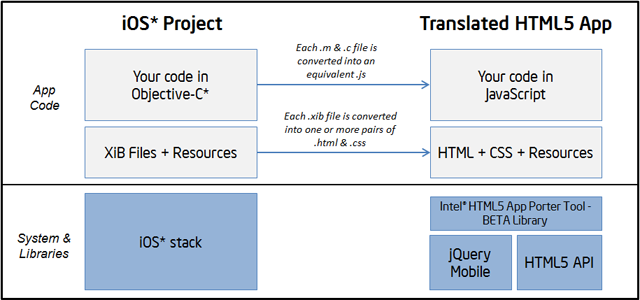
The execution of the Intel® HTML5 App Porter Tool – BETA produces a set of files that can be divided in four groups:
- The translated app code: These are the JavaScript files that were created as a translation from the original app Objective-C* files.
- For each translated module (i.e. each
.mfile) there should be a.jsfile with a matching name. - The default.html file is the entry point for the HTML5 app, where all the other
.jsfiles are included. - Additionally, there are some JavaScript files included in the
\libfolder that corresponds to some 3rd party libraries and Intel® HTML5 App Porter Tool – BETA library which implements most of the functionality that is not available in HTML5. - Translated
.xibfiles (if any): For each translated.xibfile there should be.htmland.cssfiles with matching names. These files correspond to their HTML5 version. - “ToDo” JavaScript files: As the translation of some of the
APIs in the original app may not be supported by the current version,
empty definitions as placeholders for those not-mapped APIs are
generated in the translated HTML5 app. This “ToDo” files contain those
placeholders and are named after the class of the not-mapped APIs. For
instance, the placeholders for not-mapped methods of the
NSDataclass, would be located in a file named something liketodo_api_js_apt_data.jsortodo_js_nsdata.js. - Resources: All the resources from the original iOS* project will be copied to the root folder of the translated HTML5 app.
The generated JavaScript files have names which are practically the
same as the original ones. For example, if you have a file called AppDelegate.m in the original application, you will end up with a file called AppDelegate.js
in the translated output. Likewise, the names of interfaces, functions,
fields, or variables are not changed, unless the differences between
Objective-C* and JavaScript require the tool to do so.
In short, the high level structure of the translated application is practically the same as the original one. Therefore, the design and structure of the original application will remain the same in the translated version.
About target HTML5 APIs and libraries
The Intel® HTML5 App Porter Tool - BETA both translates the syntax and semantics of the source language (Objective-C*) into JavaScript and maps the iOS* SDK API calls into an equivalent functionality in HTML5. In order to map iOS* API types and calls into HTML5, we use the following libraries and APIs:
- The standard HTML5 API: The tool maps iOS* types and calls into plain standard objects and functions of HTML5 API as its main target. Most notably, considerable portions of supported Foundation framework APIs are mapped directly into standard HTML5. When that is not possible, the tool provides a small adaptation layer as part of its library.
- The jQuery Mobile library: Most of the UIKit widgets are mapped jQuery Mobile widgets or a composite of them and standard HTML5 markup. Layouts from XIB files are also mapped to jQuery Mobile widgets or other standard HTML5 markup.
- The Intel® HTML5 App Porter Tool - BETA library:
This is a 'thin-layer' library build on top of jQuery Mobile and HTML5
APIs and implements functionality that is no directly available in those
libraries, including Controller objects, Delegates, and logic to
encapsulate jQuery Mobile widgets. The library provides a facade very
similar to the original APIs that should be familiar to iOS* developers.
This library is distributed with the tool and included as part of the
translated code in the
libfolder.
You should expect that future versions of the tool will incrementally add more support for API mapping, based on further statistical analysis and user feedback.
Translated identifier names
In Objective-C*, methods names can be composed by several parts
separated with colons (:) and the methods calls interleaved these parts
with the actual arguments. Since that peculiar syntactic construct is
not available in JavaScript, those methods names are translated by
combining all the methods parts replacing the colons (:) with
underscores (_). For example, a function called initWithColor:AndBackground: is translated to use the name initWithColor_AndBackground
Identifier names, in general, may also be changed in the translation if there are any conflicts in JavaScript scope. For example, if you have duplicated names for interfaces and protocol, or one instance method and one class method that share the same name in the same interface. Because identifier scoping rules are different in JavaScript, you cannot share names between fields, methods, and interfaces. In any of those cases, the tool renames one of the clashing identifiers by prepending an underscore (_) to the original name.
Additional tips to get the most out of the Intel® HTML5 App Porter Tool – BETA
Here is a list of recommendations to make the most of the tool.
- Keep your code modular
Having a well-designed and architected source code may help you to take the most advantage of the translation performed by tool. If the modules of the original source code can be easily decoupled, tested, and refactored the same will be true for the translated code. Having loosely coupled modules in your original application allows you to isolate the modules that are not translated well into JavaScript. In this way, you should be able to simply skip those modules and only select the ones suitable for translation. - Avoid translating third party libraries source code with equivalents in JavaScript
For some iOS* libraries you can find replacement libraries or APIs in JavaScript. Common examples are libraries to parse JSON, libraries to interact with social networks, or utilities libraries such as Box2D* for games development. If your project originally uses the source code of third party library which has a replacement version in JavaScript, try to use the replacement version instead of translated code, whenever it is possible. - Isolate low level C or any C++ code behind Objective-C* interfaces: The tool currently supports translating from Objective-C*, only. It covers the translation of most of C language constructs, but it does not support some low level features such as unions, pointers, or bit fields. Moreover, the current version does not support C++ or Objective-C++ code. Because of this limitation, it is advisable to encapsulate that code behind Objective-C interfaces to facilitate any additional editing, after running the tool.
In conclusion, having a well-designed application in the first place will make your life a lot easier when porting your code, even in a completely manual process.
Further technical information
This section provides additional information for developers and it is not required to effectively use Intel® HTML5 App Porter Tool - BETA. You can skip this section if you are not interested in implementation details of the tool.
Implementation of the translation steps
Here, you can find some high level details of how the different processing steps of the Intel® HTML5 App Porter Tool - BETA are implemented.
Objective-C* and C files parsing
To parse Objective-C* files, the tool uses a modified version of clang parser. A custom version of the parser is needed because:
- iOS* SDK header files are not available.
- clang is only used to parse the source files (not to compile them) and dump the AST to disk.
The following picture shows the actual detailed process for parsing .m and .c files:
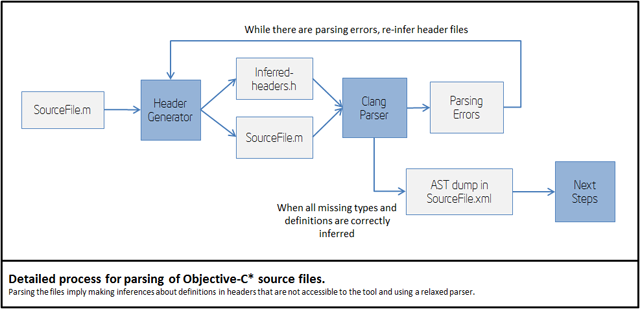
Missing iOS* SDK headers are inferred as part of the parsing process. The header inference process is heuristic, so you may get parsing errors, in some cases. Thus, you can help the front-end of the tool by providing forward declaration of types or other definitions in header files that are accessible to the tool.
Also, you can try the "Header Generator" module in individual files
by using the command line. In the binary folder of the tool, you will
find an executable headergenerator.exe that rubs that process.
Objective-C* language transformation into JavaScript
The translation of Objective-C* language into JavaScript involves a number of steps. We can divide the process in what happens in the front-end and what is in the back-end.
Steps in the front-end:
- Parsing .m and .c into an XML AST.
- Parsing comments from .m, .c and .h files and dumping comments to disk.
- Translating Clang AST into Zoe AST and re-appending the comments.
The output of the front-end is a Zoe program. Zoe is an intermediate abstract language used by LayerD framework; the engine that is used to apply most of the transformations.
The back-end is fully implemented in LayerD by using compile time classes of Zoe language that apply a number of transformations in the AST.
Steps in the back-end:
- Handling some Objective-C* features such as properties getter/setter injection and merging of categories into Zoe classes.
- Supported iOS* API conversion into target JavaScript API.
- Injection of not supported API types, or types that were left outside of the translation by the user.
- Injection of dummy methods for missing API transformations or any other code left outside of the translation by the user.
- JavaScript code generation.
iOS* API mapping into JavaScript/HTML5
The tool supports a limited subset of iOS* API. That subset is developed following statistical information about usage of each API. Each release of the tool will include support for more APIs. If you miss a particular kind of API your feedback about it will be very valuable in our assessment of API support.
For some APIs such as Arrays and Strings the tool provides direct mappings into native HTML5 objects and methods. The following table shows a summary of the approach followed for each kind of currently supported APIs.
| Framework | Mapping design guideline |
| Foundation | Direct mapping to JavaScript when possible. If direct mapping is not possible, use a new class built over standard JavaScript. |
| Core Graphics | Direct mapping to Canvas and related HTML5 APIs when possible. If direct mapping is not possible, use a new class built over standard JavaScript. |
| UIKit Views | Provide a similar class in package APT, such as APT.View for UIView, APT.Label for UILabel, etc. All views are implemented using jQuery Mobile markup and library. When there are not equivalent jQuery widgets we build new ones in the APT library. |
| UIKit Controllers and Delegates | Because HTML5 does not provide natively controllers or delegate objects the tool provides an implementation of base classes for controllers and delegates inside the APT package. |
Direct mapping implies that the original code will be transformed into plain JavaScript without any type of additional layer. For example,
1 |
NSArray anArray = [NSArray arrayWithObjects:@"One",@"Two",@"Three",nil]; |
2 |
// Is translated to JavaScript code: |
3 |
var anArray = ["One", "Two", "Three"]; |
The entire API mapping happens in the back-end of the tool. This process is implemented using compile time classes and other infrastructure provided by the LayerD framework.
XIB files conversion into HTML/CSS
XIB files are converted in two steps:
- XIB parsing and generation of intermediate XML files.
- Intermediate XML files are converted into final HTML, CSS and JavaScript boilerplate code.
The first step generates one XML file - with extension .gld - for each view inside the XIB file and one additional XML file with information about other objects inside XIB files and connections between objects and views such as outlets and event handling.
The second stage runs inside the Zoe compiler of LayerD to convert intermediate XML files into final HTML/CSS and JavaScript boilerplate code to duplicate all the functionality that XIB files provides in the original project.
Generated HTML code is as similar as possible to static markup used by jQuery Mobile library or standard HTML5 markup. For widgets that do not have an equivalent in jQuery Mobile, HTML5, or behaves differently, simple markup is generated and handled by classes in APT library.
Supported iOS SDK APIs for Translation
The following table details the APIs supported by the current version of the tool.
Notes:
-
Types refers to Interfaces, Protocols, Structs, Typedefs or Enums
-
Type 'C global' mean that it is not a type, but it is a supported global C function or constant
-
Colons in Objective-C names are replaced by underscores
-
Objective-C properties are detailed as a pair of getter/setter method names such as 'title' and 'setTitle'
-
Objective-C static members appear with a prefixed underscore like in '_dictionaryWithObjectsAndKeys'
-
Inherited members are not listed, but are supported. For example, NSArray supports the 'count' method. The method 'count' is not listed in NSMutableArray, but it is supported because it inherits from NSArray
Thursday, February 14. 2013
The future of mobile CPUs, part 1: Today’s fork in the road
Via ars technica
-----
Mobile computing's rise from niche market to the mainstream is among the most significant technological trends in our lifetimes. And to a large extent, it's been driven by the bounty of Moore’s Law—the rule that transistor density doubles every 24 months. Initially, most mobile devices relied on highly specialized hardware to meet stringent power and size budgets. But with so many transistors available, devices inevitably grew general-purpose capabilities. Most likely, that wasn't even the real motivation. The initial desire was probably to reduce costs by creating a more flexible software ecosystem with better re-use and faster time to market. As such, the first smartphones were very much a novelty, and it took many years before the world realized the potential of such devices. Apple played a major role by creating innovative smartphones that consumers craved and quickly adopted.
To some extent, this is where we still stand today. Smartphones are still (relatively) expensive and primarily interesting to the developed world. But over the next 10 years, this too will change. As Moore’s Law rolls on, the cost of a low-end smartphone will decline. At some point, the incremental cost will be quite minimal and many feature phones of today will be supplanted by smartphones. A $650 unsubsidized phone is well beyond the reach of most of the world compared to a $20 feature phone, but a $30 to $40 smartphone would naturally be very popular.
In this grand progression, 2013 will certainly be a significant milestone for mobile devices, smartphones and beyond. It's likely to be the first year in which tablets out-ship notebooks in the US. And in the coming years, this will lead to a confluence of high-end tablets and ultra-mobile notebooks as the world figures out how these devices co-exist, blend, hybridize, and/or merge.
Against this backdrop, in this two-part series, we'll explore the major trends and evolution for mobile SoCs. More importantly, we'll look to where the major vendors are likely going in the next several years.
Tablet and phone divergence
While phones and tablets are mobile devices that often share a great deal of software, it's becoming increasingly clear the two are very different products. These two markets have started to diverge and will continue doing so over time.
From a technical perspective, smartphones are far more compact and power constrained. Smartphone SoCs are limited to around 1W, both by batteries and by thermal dissipation. The raison d’etre of a smartphone is connectivity, so a cellular modem is an absolute necessity. For the cost sensitive-models that make up the vast majority of the market, the modem is integrated into the SoC itself. High-end designs favor discrete modems with a greater power budget instead. The main smartphone OSes today are iOS and Android, though Windows is beginning to make an appearance (perhaps with Linux or BlackBerry on the horizon). Just as importantly, phone vendors like HTC must pass government certification and win the approval of carriers. There is very much a walled-garden aspect, where carriers control which devices can be attached to their networks, and in some cases devices can only be sold through a certain carrier. The business model places consumers quite far removed from the actual hardware.
In contrast, tablets are far more akin to the PC both technically and economically. The power budget for tablet SoCs is much greater, up to 4W for a passively cooled device and as high as 7-8W for systems with fans. This alone means there is a much wider range of tablet designs than smartphones. Moreover, the default connectivity for tablets is Wi-Fi rather than a cellular modem. The vast majority of tablets do not have cellular modems, and even fewer customers actually purchase a wireless data plan. As a result, cellular modems are almost always optional discrete components of the platform. The software ecosystem is relatively similar, with Microsoft, Apple, and Google OSes available. Because tablets eschew cellular modems, the time to market is faster, and they are much more commonly sold directly to consumers rather than through carriers. In terms of usage models, tablets are much more PC-like, with reasonable-sized screens that make games and media more attractive.
Looking forward, these distinctions will likely become more pronounced. Many tablets today use high-end smartphone SoCs, but the difference in power targets and expected performance is quite large. As the markets grow in volume, SoCs will inevitably bifurcate to focus on one market or the other. Even today, Apple is doing so, with the A6 for phones and the larger A6X for tablets. Other vendors may need to wait a few years to have the requisite volume, but eventually the two markets will be clearly separate.
Horizontal business model evolution
Another aspect of the mobile device market that is currently in flux and likely to change in the coming years is the business model for the chip and system vendors. Currently, Apple is the only company truly pursuing a vertically integrated model, where all phones and tablets are based on Apple’s own SoC designs and iOS. The tight integration between hardware and software has been a huge boon for Apple, and it has yielded superb products.

The rest of the major SoC vendors (e.g., Intel, Qualcomm, Nvidia, TI, Mediatek, etc.) have stayed pretty far away from actual mobile devices. These companies tend to focus on horizontal business models that avoid competing with customers or suppliers.
In the long term, mobile devices are likely to evolve similarly to the PC and favor a horizontal business model. The real advantage is one of flexibility; as costs drop and the market expands, it will be increasingly necessary for vendors like HTC to offer a wide range of phones based on radically different SoCs. While a vertically integrated company like Apple can focus and maintain leadership in a specific (and highly lucrative) niche, it would be very difficult to expand in many growing areas of the market. The differences between an iPhone 6 and a $20 feature phone are tremendous and would be very difficult for a single company to bridge.
However, SoC vendors will attempt to reap the benefits of vertical integration by providing complete reference platforms to OEMs. Conceptually, this is a form of "optional" system integration, where the phone vendor or carrier can get the entire platform from the SoC supplier. This has the principal advantages of reducing time to market while also providing a baseline quality and experience for consumers. Currently, this approach has mostly been tested in emerging markets, but it's likely to become more common over time. There is a crucial distinction between reference platforms and vertical integration. Namely, OEMs can always choose to customize a platform to differentiate, and the SoC vendor avoids dealing with consumers directly. Typically, most of the customization is in terms of software on top of a base operating system.
Focus on the intellectual
One unique aspect of mobile devices is the availability and prevalence of third-party intellectual property (IP). Unlike the PC industry, it is a common practice for SoC vendors to use a variety of external and internal IP. ARM and Imagination Technologies are the best known IP vendors, with reputations established for CPUs and GPUs respectively. Most major SoC blocks are available as IP, which creates a very broad and diverse ecosystem. Even vertically integrated companies such as Apple rely on third-party IP.
Vertical integration of IP within the context of a single chip makes tremendous sense and is likely to be the future for most SoC vendors. While third-party IP is highly flexible and can reduce time to market and development costs, it comes with real trade-offs. The licensing costs are typically on a per-unit basis and thus are increasingly problematic at high volume. At a certain point, the variable licensing costs outweigh the fixed development costs, and it makes more sense to use internal resources.
Moreover, there are risks associated with third-party IP that are more difficult to control. For instance, Intel’s Clovertrail tablet has been delayed, likely due to problems with the Imagination Technologies graphics drivers for Windows 8. And third-party IP is often intended to address a wider market and may not fit with the intentions of a specific vendor. For instance, licensed ARM cores cannot be substantially modified, which removes an element of flexibility for companies with good CPU design teams.
Over the next decade, the higher volume vendors will likely focus on reducing the amount of external IP and emphasizing internal development expertise. That means licensing ARM’s instruction set and designing custom cores (as Apple has done with the A6), rather than using the stock cores. In other cases, SoC vendors will develop or acquire the necessary building blocks, such as baseband processors. One area where third-party IP will probably continue to be popular is graphics, largely because of the complexity of the software stack. Modern graphics APIs and drivers are very challenging, and the development cost may prove prohibitive for all but the very largest companies.
Manufacturing trends
The SoCs for mobile devices are inextricably tied to semiconductor manufacturing, and any look into the future must be based on a realistic assessment of the underlying technology. While Moore’s Law has continued to operate, certain aspects of silicon scaling stopped roughly a decade ago. In particular, shrinking transistors ceased granting an intrinsic increase in performance. The industry adapted and embraced a number of novel technologies to boost performance where appropriate.
Perhaps the biggest question looming over the industry is the fate of Moore’s Law and whether transistors will continue to shrink. Ten years is a very long time to make technical projections with any degree of certainty. However, there is no reason to believe that process technology scaling will stop—the advantages of shrinking are still quite large. In the next few years, the industry will move from 193nm conventional lithography to 13nm EUV lithography, which should last for quite some time. Going forward, though, innovations in materials will be absolutely necessary for Moore’s Law, and these will happen at a faster pace. To date, the major changes in manufacturing have been copper interconnects, strained silicon, high-k/metal gates, and now fully depleted transistors (e.g. FinFETs or FD-SOI), and there is plenty of promising research for the roadmap.
However, these new techniques are increasingly expensive from both a development and variable cost standpoint. Each new technique tends to winnow the field of manufacturers a bit more. Fujitsu and TI both have excellent process technology, but they could not afford to develop high-k/metal gates at the 32nm node and instead moved to a fabless model for digital logic. It's nearly certain that the number of leading edge manufacturers will shrink to just a handful. Intel, TSMC, and Samsung have the volume and can continue to afford the pace of Moore’s Law, but the economics may be prohibitive for everyone else.
Even so, a fabless model is not necessarily a panacea because of the rising variable costs. In the past, TSMC and many foundries have been able to avoid expensive techniques, but that option is no longer feasible. For instance, conventional lithography cannot draw features below 80nm without multiple patterning. If double patterning is required for a process step, it will cut the throughput of that step in half. FinFETs are similarly complex and will impact throughput as well. These costs (along with profits for TSMC or GlobalFoundries) are ultimately passed along to foundry customers as higher wafer prices.
Long-term, this translates into an advantage for the two IDMs: Intel and Samsung. First, an IDM essentially pockets the profits from both manufacturing and design, whereas fabless companies only collect the latter and must give up the former to TSMC or GlobalFoundries. Second, IDMs have greater control over the supply chain and are less likely to be subject to availability problems as a result of manufacturing challenges. Third, the cost delta between IDMs and foundries is likely to erode for the technical reasons outlined above.
One new technique which will be adopted across the industry over the next decade is 3D integration. Many mobile devices already use chip stacking, where several different integrated circuits are vertically stacked in a single package. Typically, chip stacking relies on connecting different layers of the stack with low-density bond wires or solder bumps. However, many companies are actively working on solutions to connect different layers via through-silicon vias (TSVs), which are much denser and offer greater connectivity and power savings. 3D integration using TSVs is far more sophisticated than 3D packaging, since a single integrated circuit can span multiple layers. The primary use case for 3D integration is packaging high-speed memory with an SoC to deliver superior bandwidth for graphics. Currently, the only products using 3D integration are FPGAs from Xilinx, but the technology should become relatively common during the next few years, and it should be available later to all mobile vendors.
Manufacturing roadmap
Currently, Intel is about two years ahead of the rest of the industry in terms of high-volume manufacturing for high-performance products (i.e. server, desktop, and notebook SoCs). Intel’s 22nm Ivy Bridge went into production at the end of 2011, around the same time that TSMC started producing 28nm GPUs. Additionally, Intel tends to be about one node ahead of the industry for performance features such as strained silicon, high-k/metal gates, and FinFETs (e.g. Intel introduced high-k/metal gates in 2007, foundries in 2011 and 2012). Looking forward, Intel’s manufacturing is expected to stay on a two-year cadence at least through the 10nm node in late 2015, and there is no reason to expect any deviation from this trend further out.
However, Intel’s mobile SoC designs are two years behind the cutting edge of manufacturing, with 32nm SoCs shipping today. Over the next two to three years, Intel will pick up the pace of SoC development, hitting 22nm by the end of 2013 and 14nm by the end of 2014. Long-term, the mobile SoCs will probably reach about six months behind the PC designs in terms of manufacturing, driven by cost constraints. Specifically, Intel’s fabs are quite expensive for the first year, when yields are still ramping up and the factory is depreciating. The ASPs for notebooks and desktops are high enough to amortize these costs. After six to 12 months, the costs are much lower and more amenable to phone and tablet products.
Looking at the foundries is a little more challenging and confusing. First of all, TSMC, GlobalFoundries, and Samsung tend to announce production well in advance of actual mobile SoCs shipping. However, assuming a two-year cadence is a very reasonable guideline. That places the 20nm planar node (and attendant SoCs) in late 2013 or early 2014.
The 14nm node will be quite problematic for the foundries, though. Without EUV, it will be necessary to use double patterning on the metal interconnects, which will substantially increase costs. Instead, the foundries are developing a hybrid process that uses a 14nm FinFET to boost performance, but they're keeping the same 20nm metal interconnect. From a practical standpoint, this means the foundry 14nm process will be comparable to Intel’s 22nm process in terms of performance and density, despite the name. The foundries claim that the hybrid 14nm/20nm process will arrive in 2015, which seems somewhat optimistic given the challenges involved in achieving yield for FinFETs. Moreover, that will make the transition to a 10nm node even more difficult, as the foundries will have to move from 20nm interconnects to 10nm interconnects and skip a generation.
Long-term, it seems like the foundries are expending significant effort to narrow the gap with Intel. Historically, this has proven to be an elusive goal, and there are few fundamental changes that suggest this would be feasible. It's most likely Intel’s mobile SoCs will accelerate over the next few years and ultimately reach and then maintain a 12 to 18 month lead in process technology (and hence density) over the competition. The real question is how fast the foundries will be able to implement techniques like FinFETs and other performance enhancements. It is quite possible this gap could narrow from the current four to five years down to three to four years.
In the conclusion of this series, we will explore how these trends come together and impact the leading mobile SoC vendors and where they are expected to evolve over the next five to ten years.
David Kanter is Principal Analyst and Editor-in-Chief at Real World Tech,
which focuses on microprocessors, servers, graphics, computers, and
semiconductors. He is also a consultant specializing in intellectual
property evaluation/development and technical/competitive analysis.
Wednesday, February 13. 2013
The Database Deluge… Who’s Who
Via CloudAve
-----
These are the top NoSQL Solutions in the market today that are open source, readily available, with a strong and active community, and actively making forward progress in development and innovations in the technology. I’ve provided them here, in no order, with basic descriptions, links to their main website presence, and with short lists of some of their top users of each database. Toward the end I’ve provided a short summary of the database and the respective history of the movement around No SQL and the direction it’s heading today.
Cassandra
Cassandra is a distributed databases that offers high availability and scalability. Cassandra supports a host of features around replicating data across multiple datacenters, high availability, horizontal scaling for massive linear scaling, fault tolerance and a focus, like many NoSQL solutions around commodity hardware.
Cassandra is a hybrid key-value & row based database, setup on top of a configuration focused architecture. Cassandra is fairly easy to setup on a single machine or a cluster, but is intended for use on a cluster of machines. To insure the availability of features around fault tolerance, scaling, et al you will need to setup a minimal cluster, I’d suggest at least 5 nodes (5 nodes being my personal minimum clustered database setup, this always seems to be a solid and safe minimum).
Cassandra also has a query language called CQL or Cassandra Query Langauge. Cassandra also support Apache Projects Hive, Pig with Hadoop integration for map reduce.
Who uses Cassandra?
- IBM
- HP
- Netflix
- …many others…

HBase
In the book, Seven Databases in Seven Weeks, the Apache HBase Project is described as a nail gun. You would not use HBase to catalog your sales list just like you wouldn’t use a nail gun to build a dollhouse. This is an apt description of HBase.
HBase is a column-oriented database. It’s very good at scaling out. The origins of HBase are rooted in BigTable by Google. The proprietary database is described in in the 2006 white paper, “Bigtable: A Distributed Storage System for Structured Data.”
HBase stores data in buckets called tables, the tables contain cells that are at the intersection of rows and columns. Because of this HBase has a lot of similar characteristics to a relational database. However the similarities are only in name.
HBase also has several features that aren’t available in other databases, such as; versioning, compression, garbage collection and in memory tables. One other feature that is usually only available in relational databases is strong consistency guarantees.
The place where HBase really shines however is in queries against enormous datasets.
HBase is designed architecturally to be fault tolerate. It does this through write-ahead logging and distributed configuration. At the core of the architecture HBase is built on Hadoop. Hadoop is a sturdy, scalable computing platform that provides a distribute file system and mapreduce capabilities.
Who is using it?
- Facebook uses HBase for its messaging infrastructure.
- Stumpleupon uses it for real-time data storage and analytics.
- Twitter uses HBase for data generation around people search & storing logging & monitoring data.
- Meetup uses it for site data.
- There are many others including Yahoo!, eBay, etc.

Mongo
MongoDB is built and maintained by a company called 10gen. MongoDB was released in 2009 and has been rising in popularity quickly and steadily since then. The name, contrary to the word mongo, comes from the word humongous. The key goals behind MongoDB are performance and easy data access.
The architecture of MongoDB is around document database principles. The data can be queried in an ad-hoc way, with the data persisted in a nested way. This database also, like most NoSQL databases enforces no schema, however can have specific document fields that can be queried off of.
Who is using it?
- Foursquare
- bit.ly
- CERN for collecting data from the large Hadron Collider
- …others…

Redis
Redis stands for Remote Dictionary Service. The most common capability Redis is known for, is blindingly fast speed. This speed comes from trading durability. At a base level Redis is a key-value store, however sometimes classifying it isn’t straight forward.
Redis is a key-value store, and often referred to as a data structure server with keys that can be string, hashes, lists, sets and sorted sets. Redis is also, stepping away from only being a key-value store, into the realm of being a publish-subscribe and queue stack. This makes Redis one very flexible tool in the tool chest.
Who is using it?
- Blizzard (You know, that World of Warcraft game maker) ;)
- Craigslist
- flickr
- …others…
Couch
Another Apache Project, CouchDB is the idealized JSON and REST document database. It works as a document database full of key-value pairs with the values a set number of types including nested with other key-value objects.
The primary mode of querying CouchDB is to use incremental mapreduce to produce indexed views.
One other interesting characteristic about CouchDB is that it’s built with the idea of a multitude of deployment scenarios. CouchDB might be deployed to some big servers or may be a mere service running on your Android Phone or Mac OS-X Desktop.
Like many NoSQL options CouchDB is RESTful in operation and uses JSON to send data to and from clients.
The Node.js Community also has an affinity for Couch since NPM and a lot of the capabilities of Couch seem like they’re just native to JavaScript. From the server aspect of the database to the JSON format usage to other capabilities.
Who uses it?
- NPM – Node Package Manager site and NPM uses CouchDB for storing and providing the packages for Node.js.

Couchbase (UPDATED January 18th)
Ok, I realized I’d neglected to add Couchbase (thus the Jan 18th update), which is an open source and interesting solution built off of Membase and Couch. Membase isn’t particularly a distributed database, or database, but between it and couch joining to form Couchbase they’ve turned it into a distributed database like couch except with some specific feature set differences.
A lot of the core architecture features of Couch are available, but the combination now adds auto-sharding clusters, live/hot swappable upgrades and changes, memchaced APIs, and built in data caching.
Who uses it?
- Orbitz
- Concur
- …and others…
Neo4j
Neo4j steps away from many of the existing NoSQL databases with its use of a graph database model. It stored data as a graph, mathematically speaking, that relates to the other data in the database. This database, of all the databases among the NoSQL and SQL world, is very whiteboard friendly.
Neo4j also has a varied deployment model, being able to deploy to a small or large device or system. It has the ability to store dozens of billions of edges and nodes.
Who is using it?
- Accenture
- Adobe
- Lufthansa
- Mozilla
- …others…

Riak
Riak is a key-value, distributed, fault tolerant, resilient database written in Erlang. It uses the Riak Core project as a codebase for the distributed core of the system. I further explained Riak, since yes, I work for Basho who are the makers of Riak, in a separate blog entry “Riak is… A Big List of Things“. So for a description of the features around Riak check that out.
Who is using Riak?
- Best Buy
- Github
- Voxer
- Yammer
- Comcast
- …many others…
In Summary
One of the things you’ll notice with a lot of these databases and the NoSQL movement in general is that it originated from companies needing to go “web scale” and RDBMSs just couldn’t handle or didn’t meet the specific requirements these companies had for the data. NoSQL is in no way a replacement to relational or SQL databases except in these specific cases where need is outside of the capability or scope of SQL & Relational Databases and RDBMSs.
Almost every NoSQL database has origins that go pretty far back, but the real impetus and push forward with the technology came about with key efforts at Google and Amazon Web Services. At Google it was with BigTable Paper and at Amazon Web Services it was with the Dynamo Paper. As time moved forward with the open source community taking over as the main innovator and development model around big data and the NoSQL database movement. Today the Apache Project has many of the projects under its guidance along with other companies like Basho and 10gen.
In the last few years, many of the larger mainstays of the existing database industry have leapt onto the bandwagon. Companies like Microsoft, Dell, HP and Oracle have made many strategic and tactical moves to stay relevant with this move toward big data and nosql databases solutions. However, the leadership is still outside of these stalwarts and in the hands of the open source community. The related companies and organizations that are focused on that community such as 10gen, Basho and the Apache Organization still hold much of the future of this technology in the strategic and tactical actions that they take since they’re born from and significant parts of the community itself.
For an even larger list of almost every known NoSQL Database in existence check out NoSQL Database .org.
Tuesday, February 12. 2013
Software Predicts Tomorrow’s News by Analyzing Today’s and Yesterday’s
Monday, February 11. 2013
Researchers create robot exoskeleton that is controlled by a moth running on a trackball
Via ExtremTech
-----

If you’re terrified of the possibility that humanity will be dismembered by an insectoid master race, equipped with robotic exoskeletons (or would that be exo-exoskeletons?), look away now. Researchers at the University of Tokyo have strapped a moth into a robotic exoskeleton, with the moth successfully controlling the robot to reach a specific location inside a wind tunnel.
In all, fourteen male silkmoths were tested, and they all showed a scary aptitude for steering a robot. In the tests, the moths had to guide the robot towards a source of female sex pheromone. The researchers even introduced a turning bias — where one of the robot’s motors is stronger than the other, causing it to veer to one side — and yet the moths still reached the target.
As you can see in the photo above, the actual moth-robot setup is one of the most disturbing and/or awesome things you’ll ever see. In essence, the polystyrene (styrofoam) ball acts like a trackball mouse. As the silkmoth walks towards the female pheromone, the ball rolls around. Sensors detect these movements and fire off signals to the robot’s drive motors. At this point you should watch the video below — and also not think too much about what happens to the moth when it’s time to remove the glued-on stick from its back.
Fortunately, the Japanese researchers aren’t actually trying to construct a moth master race: In reality, it’s all about the moth’s antennae and sensory-motor system. The researchers are trying to improve the performance of autonomous robots that are tasked with tracking the source of chemical leaks and spills. “Most chemical sensors, such as semiconductor sensors, have a slow recovery time and are not able to detect the temporal dynamics of odours as insects do,” says Noriyasu Ando, the lead author of the research. “Our results will be an important indication for the selection of sensors and models when we apply the insect sensory-motor system to artificial systems.”

Of course, another possibility is that we simply keep the moths. After all, why should we spend time and money on an artificial system when mother nature, as always, has already done the hard work for us? In much the same way that miners used canaries and border police use sniffer dogs, why shouldn’t robots be controlled by insects? The silkmoth is graced with perhaps the most sensitive olfactory system in the world. For now it might only be sensitive to not-so-useful scents like the female sex pheromone, but who’s to say that genetic engineering won’t allow for silkmoths that can sniff out bombs or drugs or chemical spills?
Who nose: Maybe genetically modified insects with robotic exoskeletons are merely an intermediary step towards real nanobots that fly around, fixing, cleaning, and constructing our environment.
Monday, February 04. 2013
No Mercy For Robots: Experiment Tests How Humans Relate To Machines
Via npr
-----

Could you say "no" to this face? Christoph Bartneck of the University of Canterbury in New Zealand recently tested whether humans could end the life of a robot as it pleaded for survival.
In 2007, Christoph Bartneck, a robotics professor at the University of Canterbury in New Zealand, decided to stage an experiment loosely based on the famous (and infamous) Milgram obedience study.
In Milgram's study, research subjects were asked to administer increasingly powerful electrical shocks to a person pretending to be a volunteer "learner" in another room. The research subject would ask a question, and whenever the learner made a mistake, the research subject was supposed to administer a shock — each shock slightly worse than the one before.
As the experiment went on, and as the shocks increased in intensity, the "learners" began to clearly suffer. They would scream and beg for the research subject to stop while a "scientist" in a white lab coat instructed the research subject to continue, and in videos of the experiment you can see some of the research subjects struggle with how to behave. The research subjects wanted to finish the experiment like they were told. But how exactly to respond to these terrible cries for mercy?
Bartneck studies human-robot relations, and he wanted to know what would happen if a robot in a similar position to the "learner" begged for its life. Would there be any moral pause? Or would research subjects simply extinguish the life of a machine pleading for its life without any thought or remorse?
Treating Machines Like Social Beings
Many people have studied machine-human relations, and at this point it's clear that without realizing it, we often treat the machines around us like social beings.
Consider the work of Stanford professor Clifford Nass. In 1996, he arranged a series of experiments testing whether people observe the rule of reciprocity with machines.
"Every culture has a rule of reciprocity, which roughly means, if I do something nice for you, you will do something nice for me," Nass says. "We wanted to see whether people would apply that to technology: Would they help a computer that helped them more than a computer that didn't help them?"
So they placed a series of people in a room with two computers. The people were told that the computer they were sitting at could answer any question they asked. In half of the experiments, the computer was incredibly helpful. Half the time, the computer did a terrible job.
After about 20 minutes of questioning, a screen appeared explaining that the computer was trying to improve its performance. The humans were then asked to do a very tedious task that involved matching colors for the computer. Now, sometimes the screen requesting help would appear on the computer the human had been using; sometimes the help request appeared on the screen of the computer across the aisle.
"Now, if these were people [and not computers]," Nass says, "we would expect that if I just helped you and then I asked you for help, you would feel obligated to help me a great deal. But if I just helped you and someone else asked you to help, you would feel less obligated to help them."
What the study demonstrated was that people do in fact obey the rule of reciprocity when it comes to computers. When the first computer was helpful to people, they helped it way more on the boring task than the other computer in the room. They reciprocated.
"But when the computer didn't help them, they actually did more color matching for the computer across the room than the computer they worked with, teaching the computer [they worked with] a lesson for not being helpful," says Nass.
Very likely, the humans involved had no idea they were treating these computers so differently. Their own behavior was invisible to them. Nass says that all day long, our interactions with the machines around us — our iPhones, our laptops — are subtly shaped by social rules we aren't necessarily aware we're applying to nonhumans.
"The relationship is profoundly social," he says. "The human brain is built so that when given the slightest hint that something is even vaguely social, or vaguely human — in this case, it was just answering questions; it didn't have a face on the screen, it didn't have a voice — but given the slightest hint of humanness, people will respond with an enormous array of social responses including, in this case, reciprocating and retaliating."
So what happens when a machine begs for its life — explicitly addressing us as if it were a social being? Are we able to hold in mind that, in actual fact, this machine cares as much about being turned off as your television or your toaster — that the machine doesn't care about losing it's life at all?
Bartneck's Milgram Study With Robots
In Bartneck's study, the robot — an expressive cat that talks like a human — sits side by side with the human research subject, and together they play a game against a computer. Half the time, the cat robot was intelligent and helpful, half the time not.
Bartneck also varied how socially skilled the cat robot was. "So, if the robot would be agreeable, the robot would ask, 'Oh, could I possibly make a suggestion now?' If it were not, it would say, 'It's my turn now. Do this!' "
At the end of the game, whether the robot was smart or dumb, nice or mean, a scientist authority figure modeled on Milgram's would make clear that the human needed to turn the cat robot off, and it was also made clear to them what the consequences of that would be: "They would essentially eliminate everything that the robot was — all of its memories, all of its behavior, all of its personality would be gone forever."
In videos of the experiment, you can clearly see a moral struggle as the research subject deals with the pleas of the machine. "You are not really going to switch me off, are you?" the cat robot begs, and the humans sit, confused and hesitating. "Yes. No. I will switch you off!" one female research subject says, and then doesn't switch the robot off.
"People started to have dialogues with the robot about this," Bartneck says, "Saying, 'No! I really have to do it now, I'm sorry! But it has to be done!' But then they still wouldn't do it."
There they sat, in front of a machine no more soulful than a hair dryer, a machine they knew intellectually was just a collection of electrical pulses and metal, and yet they paused.
And while eventually every participant killed the robot, it took them time to intellectually override their emotional queasiness — in the case of a helpful cat robot, around 35 seconds before they were able to complete the switching-off procedure. How long does it take you to switch off your stereo?
The Implications
On one level, there are clear practical implications to studies like these. Bartneck says the more we know about machine-human interaction, the better we can build our machines.
But on a more philosophical level, studies like these can help to track where we are in terms of our relationship to the evolving technologies in our lives.
"The relationship is certainly something that is in flux," Bartneck says. "There is no one way of how we deal with technology and it doesn't change — it is something that does change."
More and more intelligent machines are integrated into our lives. They come into our beds, into our bathrooms. And as they do — and as they present themselves to us differently — both Bartneck and Nass believe, our social responses to them will change.
Tuesday, January 29. 2013
The End of an Era: Intel's Desktop Motherboard Business to Ramp Down Over Next 3 Years
Via AnandTech
-----

Today Intel made a sobering, but not entirely unexpected announcement: over the next 3 years Intel will be ramping down its own desktop motherboard business. Intel will continue to supply desktop chipsets for use by 3rd party motherboard manufacturers like ASUS, ASRock and Gigabyte, but after 2013 it will no longer produce and sell its own desktop mITX/mATX/ATX designs in the channel. We will see Haswell motherboards from the group, but that will be the last official hurrah. Intel will stop developing desktop motherboards once the Haswell launch is completed. All Intel boards, including upcoming Haswell motherboards, will carry a full warranty and will be supported by Intel during that period.
This isn't a workforce reduction. Most of the folks who worked in Intel's surprisingly small desktop motherboard division will move on to other groups within Intel that can use their talents. Intel's recently announced NUC will have a roadmap going forward, and some of the desktop board folks will move over there. Intel will continue to produce barebones motherboards for its NUC and future versions of the platform.
Intel will also continue to produce its own form factor reference designs (FFRDs) for Ultrabooks and tablets, which will be where many of these employees will end up as well. As of late Intel has grown quite fond of its FFRD programs, allowing it a small taste of vertical integration (and the benefits that go along with it) without completely alienating its partners. This won't be a transfer of talent to work on smartphone FFRDs at this time however.
The group within Intel responsible for building reference designs that are used internally for testing as well as end up as the base for many 3rd party motherboards will not be impacted by this decision either. The reference board group will continue to operate and supply reference designs to Intel partners. This is good news as it means that you shouldn't see a reduction in quality of what's out there.
It's not too tough to understand why Intel would want to wind down its
desktop motherboard business. Intel has two options to keep Wall Street
happy: ship tons of product with huge margins and/or generate additional
profit (at forgiveably lower margins) that's not directly tied to the
PC industry. The overwhelming majority of Intel's business is in the
former group. The desktop motherboards division doesn't exactly fit
within that category. Motherboards aren't good high margin products,
which makes the fact that Intel kept its desktop board business around
this long very impressive. Intel doesn't usually keep drains on margins
around for too long (look how quickly Intel exited the de-emphasized its consumer SSD business).
The desktop motherboard business lasted so long as a way to ensure that Intel CPUs had a good, stable home (you can't sell CPUs if motherboard quality is questionable). While there was a need for Intel to build motherboards and reference designs 15 years ago, today what comes out of Taiwan is really quite good. Intel's constant integration of components onto the CPU and the resulting consolidation in the motherboard industry has helped ensure that board quality went up.
There's also the obvious motivation: the desktop PC business isn't exactly booming. Late last year word spread of Intel's plans for making Broadwell (14nm Core microprocessor in 2014) BGA-only. While we'll continue to see socketed CPUs beyond that, the cadence will be slower than what we're used to. The focus going forward will be on highly integrated designs, even for the desktop (think all-in-ones, thin mini-ITX, NUC, etc...). Couple that reality with low board margins and exiting the desktop motherboard business all of the sudden doesn't sound like a bad idea for Intel.
In the near term, this is probably good for the remaining Taiwanese
motherboard manufacturers. They lose a very competent competitor,
although not a particularly fierce one. In the long run, it does
highlight the importance of having a business not completely tied to
desktop PC motherboard sales.
Friday, January 25. 2013
Electromagnetic Harvester draws power from the world around you
Via DVICE
-----

No matter how many times you watch The Matrix, the creepiest part is seeing the whole of humanity hooked up to pods to act as living power generators for their robot masters. Now Germany-based designer Dennis Siegel has created a kind of mini version of this idea that he calls an Electromagnetic Harvester.
The tiny device allows him to draw redundant energy from household appliances, mobile devices, and even outside aerial electrical lines. An LED light indicates when power is effectively being drawn in, and that power is conveniently stored in what appears to be a common AA battery. According to Siegel, it takes the Electromagnetic Harvester about one day to fully charge one of the batteries, depending on the strength of the electromagnetic field being sourced.
You can see video of the Electromagnetic Harvester in action in the video below.
MeCam $49 flying camera concept follows you around, streams video to your phone
Via liliputing
-----
Always Innovating is working on a tiny flying video camera called the MeCam. The camera is designed to follow you around and stream live video to your smartphone, allowing you to upload videos to YouTube, Facebook, or other sites.
And Always Innovating thinks the MeCam could eventually sell for just $49.

The camera is docked in a nano copter with 4 spinning rotors to keep it aloft. There are 14 different sensors which help the copter detect objects around it so it won’t bump into walls, people. or anything else.
Always Innovating also includes stabilization technology so that videos shouldn’t look too shaky.
Interestingly, there’s no remote control. Instead, you can control the MeCam in one of two ways. You can speak voice commands to tell it, for instance, to move up or down. Or you can enable the “follow-me” feature which tells the camera to just follow you around while shooting paparazzi-style video.
The MeCam features an Always Innovating module with an ARM Cortex-A9 processor, 1GB of RAM, WiFI, and Bluetooth.
The company hopes to license the design so that products based on the MeCam will hit the streets in early 2014.
If Always Innovating sounds familiar, that’s because it’s the same company that brought us the modular Touch Book and Smart Book products a few years ago.
If the MeCam name sounds familiar, on the other hand, it’s probably worth pointing out that the Always Innovating flying camera is not related the wearable camera that failed to come close to meeting its fundraising goals last year.

Quicksearch
Popular Entries
- The great Ars Android interface shootout (131540)
- Norton cyber crime study offers striking revenue loss statistics (102468)
- MeCam $49 flying camera concept follows you around, streams video to your phone (100551)
- The PC inside your phone: A guide to the system-on-a-chip (58731)
- Norton cyber crime study offers striking revenue loss statistics (58697)
Categories

Show tagged entries
Syndicate This Blog
Calendar
|
|
July '26 | |||||
| Mon | Tue | Wed | Thu | Fri | Sat | Sun |
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 | ||