After a lot of theorizing,
postulating, and non-human trials, it looks like bionic eye implants are
finally hitting the market — first in Europe, and hopefully soon in the
US. These implants can restore sight to completely blind patients —
though only if the blindness is caused by a faulty retina, as in macular
degeneration (which millions of old people suffer from), diabetic
retinopathy, or other degenerative eye diseases.
The first of these implants, Argus II developed by Second Sight,
is already available in Europe. For around $115,000, you get a 4-hour
operation to install an antenna behind your eye, and a special pair of
camera-equipped glasses that send signals to the antenna. The antenna is
wired into your retina with around 60 electrodes, creating the
equivalent of a 60-pixel display for your brain to interpret. The first
users of the Argus II bionic eye report that they can see rough shapes
and track the movement of objects, and slowly read large writing.
The
second bionic eye implant, the Bio-Retina developed by Nano Retina, is a
whole lot more exciting. The Bio-Retina costs less — around the $60,000
mark — and instead of an external camera, the vision-restoring sensor
is actually placed inside the eye, on top of the retina. The operation
only takes 30 minutes and can be performed under local anesthetic.
Basically, with macular
degeneration and diabetic retinopathy, the light-sensitive rods and
cones in your retina stop working. The Bio-Retina plops a
24×24-resolution (576-pixel!) sensor right on top of your damaged
retina, and 576 electrodes on the back of the sensor implant themselves
into the optic nerve. An embedded image processor converts the data from
each of the pixels into electrical pulses that are coded in such a way
that the brain can perceive different levels of grayscale.
The
best bit, though, is how the the sensor is powered. The Bio-Retina
system comes with a standard pair of corrective lenses that are modified
so that they can fire a near-infrared laser beam through your iris to
the sensor at the back of your eye. On the sensor there is a
photovoltaic cell that produces up to three milliwatts — not a lot, but
more than enough. The infrared laser is invisible and harmless. To see
the Bio-Retina system in action, watch the demo video embedded below.
Human
trials of Bio-Retina are slated to begin in 2013 — but like Second
Sight, US approval could be a long time coming. It’s easy enough to hop
on a plane and visit one of the European clinics offering bionic eye
implants, though. Moving forward, multiple research groups are working
on bionic eyes with even more electrodes, and thus higher resolution,
but there doesn’t seem to be any progress on sensors or encoder chips
that can create a color image. A lot of work is being done on understanding how the retina, optic nerve, and brain process and perceive images — so who knows what the future might hold.
If a team of Harvard bioengineers has its way,
animal testing and experimentation could soon be replaced by
organ-on-a-chip technologies. Like SoCs (system-on-a-chip), which
shoehorn most of a digital computer into a single chip, an
organ-on-a-chip seeks to replicate the functions of a human organ on a
computer chip.
In Harvard’s case, its Wyss Institute has now created a living lung-on-a-chip, a heart-on-a-chip, and most recently a gut-on-a-chip.
We’re not talking about silicon chips simulating
the functions of various human organs, either. These organs-on-a-chip
contain real, living human cells. In the case of the gut-on-a-chip, a
single layer of human intestinal cells is coerced into growing on a
flexible, porous membrane, which is attached to the clear plastic walls
of the chip. By applying a vacuum pump, the membrane stretches and
recoils, just like a human gut going through the motions of peristalsis.
It is so close to the real thing that the gut-on-a-chip even supports
the growth of living microbes on its surface, like a real human
intestine.
In another example, the Wyss Institute has built a lung-on-a-chip,
which has human lung cells on the top, a membrane in the middle, and
blood capillary cells beneath. Air flows over the top, while real human
blood flows below. Again, a vacuum pump makes the lung-on-a-chip expand
and contract, like a human lung.
These chips are also quite
closely tied to the recent emergence of the lab-on-a-chip (LoC), which
combines microfluidics (exact control of tiny amounts of fluid) and
silicon technology to massively speed up the analysis of biological
systems, such as DNA. It is thanks to LoCs that we can sequence entire genomes in just a few hours — a task that previously took weeks or months.
These human organs-on-a-chip can be tested just
like a human subject — and the fact that they’re completely transparent
is obviously a rather large boon for observation, too. To test a drug,
the researchers simply add a solution of the compound to the chip, and
see how the intestinal (or heart or lung) cells react. In the case of
the lung-on-a-chip, the Wyss team is testing how the lung reacts to
possible toxins and pollutants. They can also see how fast drugs (or
foods) are absorbed, or test the effects of probiotics.
Perhaps
more importantly, these chips could help us better understand and treat
diseases. Many human diseases don’t have an animal analog. It’s very
hard to find a drug that combats Crohn’s disease when you can’t
effectively test out your drug on animals beforehand — a problem that
could be easily solved with the gut-on-a-chip. Likewise, it is very
common for drugs to pass animal testing, but then fail on humans.
Removing animal testing from the equation would save money and time, and
also alleviate any ethical concerns.
Moving
forward, the Wyss Institute, with funding from DARPA, is currently
researching a spleen-on-a-chip. This won’t be used for pharmaceutical
purposes, though; instead, DARPA wants to create a “portable spleen”
that can be inserted into soldiers to help battle sepsis (an infection
of the blood).
And therein lies the crux: If you can create a chip
that perfectly mimics the spleen or liver or intestine, then what’s to
stop you from inserting those chips into humans and replacing or
augmenting your current organs? Instead of getting your breasts
enlarged, you might one day have your liver enlarged, to better deal
with your alcoholism. Or how we connect all the organ chips together and
create a complete human-on-a-chip?
If Facebook were a country, a conceit that founder Mark Zuckerberg has entertained in public, its 900 million members would make it the third largest in the world.
It would far outstrip any regime past or present in how intimately
it records the lives of its citizens. Private conversations, family
photos, and records of road trips, births, marriages, and deaths all
stream into the company's servers and lodge there. Facebook has
collected the most extensive data set ever assembled on human social
behavior. Some of your personal information is probably part of it.
And yet, even as Facebook has embedded itself into modern life, it
hasn't actually done that much with what it knows about us. Now that
the company has gone public, the pressure to develop new sources of
profit (see "The Facebook Fallacy")
is likely to force it to do more with its hoard of information. That
stash of data looms like an oversize shadow over what today is a modest
online advertising business, worrying privacy-conscious Web users (see "Few Privacy Regulations Inhibit Facebook")
and rivals such as Google. Everyone has a feeling that this
unprecedented resource will yield something big, but nobody knows quite
what.
Heading Facebook's effort to figure out what can be learned from all our data is Cameron Marlow,
a tall 35-year-old who until recently sat a few feet away from
Zuckerberg. The group Marlow runs has escaped the public attention that
dogs Facebook's founders and the more headline-grabbing features of its
business. Known internally as the Data Science Team, it is a kind of
Bell Labs for the social-networking age. The group has 12
researchers—but is expected to double in size this year. They apply
math, programming skills, and social science to mine our data for
insights that they hope will advance Facebook's business and social
science at large. Whereas other analysts at the company focus on
information related to specific online activities, Marlow's team can
swim in practically the entire ocean of personal data that Facebook
maintains. Of all the people at Facebook, perhaps even including the
company's leaders, these researchers have the best chance of discovering
what can really be learned when so much personal information is
compiled in one place.
Facebook has all this information because it has found ingenious
ways to collect data as people socialize. Users fill out profiles with
their age, gender, and e-mail address; some people also give additional
details, such as their relationship status and mobile-phone number. A
redesign last fall introduced profile pages in the form of time lines
that invite people to add historical information such as places they
have lived and worked. Messages and photos shared on the site are often
tagged with a precise location, and in the last two years Facebook has
begun to track activity elsewhere on the Internet, using an addictive
invention called the "Like" button.
It appears on apps and websites outside Facebook and allows people to
indicate with a click that they are interested in a brand, product, or
piece of digital content. Since last fall, Facebook has also been able
to collect data on users' online lives beyond its borders automatically:
in certain apps or websites, when users listen to a song or read a news
article, the information is passed along to Facebook, even if no one
clicks "Like." Within the feature's first five months, Facebook
catalogued more than five billion instances
of people listening to songs online. Combine that kind of information
with a map of the social connections Facebook's users make on the site,
and you have an incredibly rich record of their lives and interactions.
"This is the first time the world has seen this scale and quality
of data about human communication," Marlow says with a
characteristically serious gaze before breaking into a smile at the
thought of what he can do with the data. For one thing, Marlow is
confident that exploring this resource will revolutionize the scientific
understanding of why people behave as they do. His team can also help
Facebook influence our social behavior for its own benefit and that of
its advertisers. This work may even help Facebook invent entirely new
ways to make money.
Contagious Information
Marlow eschews the collegiate programmer style of Zuckerberg and
many others at Facebook, wearing a dress shirt with his jeans rather
than a hoodie or T-shirt. Meeting me shortly before the company's
initial public offering in May, in a conference room adorned with a
six-foot caricature of his boss's dog spray-painted on its glass wall,
he comes across more like a young professor than a student. He might
have become one had he not realized early in his career that Web
companies would yield the juiciest data about human interactions.
In 2001, undertaking a PhD at MIT's Media Lab, Marlow created a
site called Blogdex that automatically listed the most "contagious"
information spreading on weblogs. Although it was just a research
project, it soon became so popular that Marlow's servers crashed.
Launched just as blogs were exploding into the popular consciousness and
becoming so numerous that Web users felt overwhelmed with information,
it prefigured later aggregator sites such as Digg and Reddit. But Marlow
didn't build it just to help Web users track what was popular online.
Blogdex was intended as a scientific instrument to uncover the social
networks forming on the Web and study how they spread ideas. Marlow went
on to Yahoo's research labs to study online socializing for two years.
In 2007 he joined Facebook, which he considers the world's most powerful
instrument for studying human society. "For the first time," Marlow
says, "we have a microscope that not only lets us examine social
behavior at a very fine level that we've never been able to see before
but allows us to run experiments that millions of users are exposed to."
Marlow's team works with managers across Facebook to find patterns
that they might make use of. For instance, they study how a new feature
spreads among the social network's users. They have helped Facebook
identify users you may know but haven't "friended," and recognize those
you may want to designate mere "acquaintances" in order to make their
updates less prominent. Yet the group is an odd fit inside a company
where software engineers are rock stars who live by the mantra "Move
fast and break things." Lunch with the data team has the feel of a
grad-student gathering at a top school; the typical member of the group
joined fresh from a PhD or junior academic position and prefers to talk
about advancing social science than about Facebook as a product or
company. Several members of the team have training in sociology or
social psychology, while others began in computer science and started
using it to study human behavior. They are free to use some of their
time, and Facebook's data, to probe the basic patterns and motivations
of human behavior and to publish the results in academic journals—much
as Bell Labs researchers advanced both AT&T's technologies and the
study of fundamental physics.
It may seem strange that an eight-year-old company without a
proven business model bothers to support a team with such an academic
bent, but Marlow says it makes sense. "The biggest challenges Facebook
has to solve are the same challenges that social science has," he says.
Those challenges include understanding why some ideas or fashions spread
from a few individuals to become universal and others don't, or to what
extent a person's future actions are a product of past communication
with friends. Publishing results and collaborating with university
researchers will lead to findings that help Facebook improve its
products, he adds.
For one example of how Facebook can serve as a proxy for examining
society at large, consider a recent study of the notion that any person
on the globe is just six degrees of separation from any other. The
best-known real-world study, in 1967, involved a few hundred people
trying to send postcards to a particular Boston stockholder. Facebook's
version, conducted in collaboration with researchers from the University
of Milan, involved the entire social network as of May 2011, which
amounted to more than 10 percent of the world's population. Analyzing
the 69 billion friend connections among those 721 million people showed
that the world is smaller than we thought: four intermediary friends are
usually enough to introduce anyone to a random stranger. "When
considering another person in the world, a friend of your friend knows a
friend of their friend, on average," the technical paper pithily
concluded. That result may not extend to everyone on the planet, but
there's good reason to believe that it and other findings from the Data
Science Team are true to life outside Facebook. Last year the Pew
Research Center's Internet & American Life Project found that 93
percent of Facebook friends had met in person. One of Marlow's
researchers has developed a way to calculate a country's "gross national
happiness" from its Facebook activity by logging the occurrence of
words and phrases that signal positive or negative emotion. Gross
national happiness fluctuates in a way that suggests the measure is
accurate: it jumps during holidays and dips when popular public figures
die. After a major earthquake in Chile in February 2010, the country's
score plummeted and took many months to return to normal. That event
seemed to make the country as a whole more sympathetic when Japan
suffered its own big earthquake and subsequent tsunami in March 2011;
while Chile's gross national happiness dipped, the figure didn't waver
in any other countries tracked (Japan wasn't among them). Adam Kramer,
who created the index, says he intended it to show that Facebook's data
could provide cheap and accurate ways to track social trends—methods
that could be useful to economists and other researchers.
Other work published by the group has more obvious utility for
Facebook's basic strategy, which involves encouraging us to make the
site central to our lives and then using what it learns to sell ads. An early study
looked at what types of updates from friends encourage newcomers to the
network to add their own contributions. Right before Valentine's Day
this year a blog post from the Data Science Team
listed the songs most popular with people who had recently signaled on
Facebook that they had entered or left a relationship. It was a hint of
the type of correlation that could help Facebook make useful predictions
about users' behavior—knowledge that could help it make better guesses
about which ads you might be more or less open to at any given time.
Perhaps people who have just left a relationship might be interested in
an album of ballads, or perhaps no company should associate its brand
with the flood of emotion attending the death of a friend. The most
valuable online ads today are those displayed alongside certain Web
searches, because the searchers are expressing precisely what they want.
This is one reason why Google's revenue is 10 times Facebook's. But
Facebook might eventually be able to guess what people want or don't
want even before they realize it.
Recently the Data Science Team has begun to use its unique
position to experiment with the way Facebook works, tweaking the
site—the way scientists might prod an ant's nest—to see how users react.
Eytan Bakshy, who joined Facebook last year after collaborating with
Marlow as a PhD student at the University of Michigan, wanted to learn
whether our actions on Facebook are mainly influenced by those of our
close friends, who are likely to have similar tastes. That would shed
light on the theory that our Facebook friends create an "echo chamber"
that amplifies news and opinions we have already heard about. So he
messed with how Facebook operated for a quarter of a billion users. Over
a seven-week period, the 76 million links that those users shared with
each other were logged. Then, on 219 million randomly chosen occasions,
Facebook prevented someone from seeing a link shared by a friend. Hiding
links this way created a control group so that Bakshy could assess how
often people end up promoting the same links because they have similar
information sources and interests.
He found that our close friends strongly sway which information we
share, but overall their impact is dwarfed by the collective influence
of numerous more distant contacts—what sociologists call "weak ties." It
is our diverse collection of weak ties that most powerfully determines
what information we're exposed to.
That study provides strong evidence against the idea that social networking creates harmful "filter bubbles," to use activist Eli Pariser's
term for the effects of tuning the information we receive to match our
expectations. But the study also reveals the power Facebook has. "If
[Facebook's] News Feed is the thing that everyone sees and it controls
how information is disseminated, it's controlling how information is
revealed to society, and it's something we need to pay very close
attention to," Marlow says. He points out that his team helps Facebook
understand what it is doing to society and publishes its findings to fulfill a public duty to transparency. Another recent study,
which investigated which types of Facebook activity cause people to
feel a greater sense of support from their friends, falls into the same
category.
But Marlow speaks as an employee of a company that will prosper
largely by catering to advertisers who want to control the flow of
information between its users. And indeed, Bakshy is working with
managers outside the Data Science Team to extract advertising-related
findings from the results of experiments on social influence.
"Advertisers and brands are a part of this network as well, so giving
them some insight into how people are sharing the content they are
producing is a very core part of the business model," says Marlow.
Facebook told prospective investors before its IPO that people
are 50 percent more likely to remember ads on the site if they're
visibly endorsed by a friend. Figuring out how influence works could
make ads even more memorable or help Facebook find ways to induce more
people to share or click on its ads.
Social Engineering
Marlow says his team wants to divine the rules of online social
life to understand what's going on inside Facebook, not to develop ways
to manipulate it. "Our goal is not to change the pattern of
communication in society," he says. "Our goal is to understand it so we
can adapt our platform to give people the experience that they want."
But some of his team's work and the attitudes of Facebook's leaders show
that the company is not above using its platform to tweak users'
behavior. Unlike academic social scientists, Facebook's employees have a
short path from an idea to an experiment on hundreds of millions of
people.
In April, influenced in part by conversations over dinner with his
med-student girlfriend (now his wife), Zuckerberg decided that he
should use social influence within Facebook to increase organ donor
registrations. Users were given an opportunity to click a box on their
Timeline pages to signal that they were registered donors, which
triggered a notification to their friends. The new feature started a
cascade of social pressure, and organ donor enrollment increased by a
factor of 23 across 44 states.
Marlow's team is in the process of publishing results from the
last U.S. midterm election that show another striking example of
Facebook's potential to direct its users' influence on one another.
Since 2008, the company has offered a way for users to signal that they
have voted; Facebook promotes that to their friends with a note to say
that they should be sure to vote, too. Marlow says that in the 2010
election his group matched voter registration logs with the data to see
which of the Facebook users who got nudges actually went to the polls.
(He stresses that the researchers worked with cryptographically
"anonymized" data and could not match specific users with their voting
records.)
This is just the beginning. By learning more about how small changes
on Facebook can alter users' behavior outside the site, the company
eventually "could allow others to make use of Facebook in the same way,"
says Marlow. If the American Heart Association wanted to encourage
healthy eating, for example, it might be able to refer to a playbook of
Facebook social engineering. "We want to be a platform that others can
use to initiate change," he says.
Advertisers, too, would be eager to know in greater detail what
could make a campaign on Facebook affect people's actions in the outside
world, even though they realize there are limits to how firmly human
beings can be steered. "It's not clear to me that social science will
ever be an engineering science in a way that building bridges is," says
Duncan Watts, who works on computational social science at Microsoft's
recently opened New York research lab and previously worked alongside
Marlow at Yahoo's labs. "Nevertheless, if you have enough data, you can
make predictions that are better than simply random guessing, and that's
really lucrative."
Doubling Data
Like other social-Web companies, such as Twitter, Facebook has
never attained the reputation for technical innovation enjoyed by such
Internet pioneers as Google. If Silicon Valley were a high school, the
search company would be the quiet math genius who didn't excel socially
but invented something indispensable. Facebook would be the annoying kid
who started a club with such social momentum that people had to join
whether they wanted to or not. In reality, Facebook employs hordes of
talented software engineers (many poached from Google and other
math-genius companies) to build and maintain its irresistible club. The
technology built to support the Data Science Team's efforts is
particularly innovative. The scale at which Facebook operates has led it
to invent hardware and software that are the envy of other companies
trying to adapt to the world of "big data."
In a kind of passing of the technological baton, Facebook built
its data storage system by expanding the power of open-source software
called Hadoop, which was inspired by work at Google and built at Yahoo.
Hadoop can tame seemingly impossible computational tasks—like working on
all the data Facebook's users have entrusted to it—by spreading them
across many machines inside a data center. But Hadoop wasn't built with
data science in mind, and using it for that purpose requires
specialized, unwieldy programming. Facebook's engineers solved that
problem with the invention of Hive, open-source software that's now
independent of Facebook and used by many other companies. Hive acts as a
translation service, making it possible to query vast Hadoop data
stores using relatively simple code. To cut down on computational
demands, it can request random samples of an entire data set, a feature
that's invaluable for companies swamped by data. Much of Facebook's data
resides in one Hadoop store more than 100 petabytes (a million
gigabytes) in size, says Sameet Agarwal, a director of engineering at
Facebook who works on data infrastructure, and the quantity is growing
exponentially. "Over the last few years we have more than doubled in
size every year," he says. That means his team must constantly build
more efficient systems.
All this has given Facebook a unique level of expertise, says Jeff Hammerbacher,
Marlow's predecessor at Facebook, who initiated the company's effort to
develop its own data storage and analysis technology. (He left Facebook
in 2008 to found Cloudera, which develops Hadoop-based systems to
manage large collections of data.) Most large businesses have paid
established software companies such as Oracle a lot of money for data
analysis and storage. But now, big companies are trying to understand
how Facebook handles its enormous information trove on open-source
systems, says Hammerbacher. "I recently spent the day at Fidelity
helping them understand how the 'data scientist' role at Facebook was
conceived ... and I've had the same discussion at countless other
firms," he says.
As executives in every industry try to exploit the opportunities
in "big data," the intense interest in Facebook's data technology
suggests that its ad business may be just an offshoot of something much
more valuable. The tools and techniques the company has developed to
handle large volumes of information could become a product in their own
right.
Mining for Gold
Facebook needs new sources of income to meet investors'
expectations. Even after its disappointing IPO, it has a staggeringly
high price-to-earnings ratio that can't be justified by the barrage of
cheap ads the site now displays. Facebook's new campus in Menlo Park,
California, previously inhabited by Sun Microsystems, makes that
pressure tangible. The company's 3,500 employees rattle around in enough
space for 6,600. I walked past expanses of empty desks in one building;
another, next door, was completely uninhabited. A vacant lot waited
nearby, presumably until someone invents a use of our data that will
justify the expense of developing the space.
One potential use would be simply to sell insights mined from the information. DJ Patil,
data scientist in residence with the venture capital firm Greylock
Partners and previously leader of LinkedIn's data science team, believes
Facebook could take inspiration from Gil Elbaz, the inventor of
Google's AdSense ad business, which provides over a quarter of Google's
revenue. He has moved on from advertising and now runs a fast-growing
startup, Factual,
that charges businesses to access large, carefully curated collections
of data ranging from restaurant locations to celebrity body-mass
indexes, which the company collects from free public sources and by
buying private data sets. Factual cleans up data and makes the result
available over the Internet as an on-demand knowledge store to be tapped
by software, not humans. Customers use it to fill in the gaps in their
own data and make smarter apps or services; for example, Facebook itself
uses Factual for information about business locations. Patil points out
that Facebook could become a data source in its own right, selling
access to information compiled from the actions of its users. Such
information, he says, could be the basis for almost any kind of
business, such as online dating or charts of popular music. Assuming
Facebook can take this step without upsetting users and regulators, it
could be lucrative. An online store wishing to target its promotions,
for example, could pay to use Facebook as a source of knowledge about
which brands are most popular in which places, or how the popularity of
certain products changes through the year.
Hammerbacher agrees that Facebook could sell its data science and
points to its currently free Insights service for advertisers and
website owners, which shows how their content is being shared on
Facebook. That could become much more useful to businesses if Facebook
added data obtained when its "Like" button tracks activity all over the
Web, or demographic data or information about what people read on the
site. There's precedent for offering such analytics for a fee: at the
end of 2011 Google started charging $150,000 annually for a premium
version of a service that analyzes a business's Web traffic.
Back at Facebook, Marlow isn't the one who makes decisions about
what the company charges for, even if his work will shape them. Whatever
happens, he says, the primary goal of his team is to support the
well-being of the people who provide Facebook with their data, using it
to make the service sm
It's been quite a year for artificial plant life,
but Singapore has really branched out with its garden of solar-powered
super trees that will reach up to 50 meters high. The Bay South garden,
which is filled with 18 of these trees, will open on June 29.
The "Supertree Grove" comprises a fraction of the Gardens by the Bay,
a 250-acre landscaping project. The 18 trees will act as vertical
gardens with living vines and flowers snaking up the mechanical trees.
11 of the trees have solar photovoltaic systems to create energy for
lighting and for heating the steel framework that will help cultivate
the plant life growing on it.
They'll vary in size from 25 to 50 meters tall and will also collect
water and act as air venting ducts for nearby conservatories.
The most amazing part of the man-made forest might be the size and
scope of them, as they tower above the urban landscape they decorate.
IN THE classic science-fiction film “2001”, the ship’s computer, HAL,
faces a dilemma. His instructions require him both to fulfil the ship’s
mission (investigating an artefact near Jupiter) and to keep the
mission’s true purpose secret from the ship’s crew. To resolve the
contradiction, he tries to kill the crew.
As robots become more autonomous, the notion of computer-controlled
machines facing ethical decisions is moving out of the realm of science
fiction and into the real world. Society needs to find ways to ensure
that they are better equipped to make moral judgments than HAL was.
A bestiary of robots
Military technology, unsurprisingly, is at the forefront of the march towards self-determining machines (see Technology Quarterly).
Its evolution is producing an extraordinary variety of species. The
Sand Flea can leap through a window or onto a roof, filming all the
while. It then rolls along on wheels until it needs to jump again. RiSE,
a six-legged robo-cockroach, can climb walls. LS3, a dog-like robot,
trots behind a human over rough terrain, carrying up to 180kg of
supplies. SUGV, a briefcase-sized robot, can identify a man in a crowd
and follow him. There is a flying surveillance drone the weight of a
wedding ring, and one that carries 2.7 tonnes of bombs.
Robots are spreading in the civilian world, too, from the flight deck to the operating theatre (see article).
Passenger aircraft have long been able to land themselves. Driverless
trains are commonplace. Volvo’s new V40 hatchback essentially drives
itself in heavy traffic. It can brake when it senses an imminent
collision, as can Ford’s B-Max minivan. Fully self-driving vehicles are
being tested around the world. Google’s driverless cars have clocked up
more than 250,000 miles in America, and Nevada has become the first
state to regulate such trials on public roads. In Barcelona a few days
ago, Volvo demonstrated a platoon of autonomous cars on a motorway.
As they become smarter and more widespread, autonomous machines are
bound to end up making life-or-death decisions in unpredictable
situations, thus assuming—or at least appearing to assume—moral agency.
Weapons systems currently have human operators “in the loop”, but as
they grow more sophisticated, it will be possible to shift to “on the
loop” operation, with machines carrying out orders autonomously.
As that happens, they will be presented with ethical dilemmas. Should
a drone fire on a house where a target is known to be hiding, which may
also be sheltering civilians? Should a driverless car swerve to avoid
pedestrians if that means hitting other vehicles or endangering its
occupants? Should a robot involved in disaster recovery tell people the
truth about what is happening if that risks causing a panic? Such
questions have led to the emergence of the field of “machine ethics”,
which aims to give machines the ability to make such choices
appropriately—in other words, to tell right from wrong.
One way of dealing with these difficult questions is to avoid them
altogether, by banning autonomous battlefield robots and requiring cars
to have the full attention of a human driver at all times. Campaign
groups such as the International Committee for Robot Arms Control have
been formed in opposition to the growing use of drones. But autonomous
robots could do much more good than harm. Robot soldiers would not
commit rape, burn down a village in anger or become erratic
decision-makers amid the stress of combat. Driverless cars are very
likely to be safer than ordinary vehicles, as autopilots have made
planes safer. Sebastian Thrun, a pioneer in the field, reckons
driverless cars could save 1m lives a year.
Instead, society needs to develop ways of dealing with the ethics of
robotics—and get going fast. In America states have been scrambling to
pass laws covering driverless cars, which have been operating in a legal
grey area as the technology runs ahead of legislation. It is clear that
rules of the road are required in this difficult area, and not just for
robots with wheels.
The best-known set of guidelines for robo-ethics are the “three laws
of robotics” coined by Isaac Asimov, a science-fiction writer, in 1942.
The laws require robots to protect humans, obey orders and preserve
themselves, in that order. Unfortunately, the laws are of little use in
the real world. Battlefield robots would be required to violate the
first law. And Asimov’s robot stories are fun precisely because they
highlight the unexpected complications that arise when robots try to
follow his apparently sensible rules. Regulating the development and use
of autonomous robots will require a rather more elaborate framework.
Progress is needed in three areas in particular.
Three laws for the laws of robotics
First, laws are needed to determine whether the designer, the
programmer, the manufacturer or the operator is at fault if an
autonomous drone strike goes wrong or a driverless car has an accident.
In order to allocate responsibility, autonomous systems must keep
detailed logs so that they can explain the reasoning behind their
decisions when necessary. This has implications for system design: it
may, for instance, rule out the use of artificial neural networks,
decision-making systems that learn from example rather than obeying
predefined rules.
Second, where ethical systems are embedded into robots, the judgments
they make need to be ones that seem right to most people. The
techniques of experimental philosophy, which studies how people respond
to ethical dilemmas, should be able to help. Last, and most important,
more collaboration is required between engineers, ethicists, lawyers and
policymakers, all of whom would draw up very different types of rules
if they were left to their own devices. Both ethicists and engineers
stand to benefit from working together: ethicists may gain a greater
understanding of their field by trying to teach ethics to machines, and
engineers need to reassure society that they are not taking any ethical
short-cuts.
Technology has driven mankind’s progress, but each new advance has
posed troubling new questions. Autonomous machines are no different. The
sooner the questions of moral agency they raise are answered, the
easier it will be for mankind to enjoy the benefits that they will
undoubtedly bring.
Of all the noises that my children will not understand, the one that is
nearest to my heart is not from a song or a television show or a jingle.
It's the sound of a modem connecting with another modem across the
repurposed telephone infrastructure. It was the noise of being part of
the beginning of the Internet.
I heard that sound again this week on Brendan Chillcut's simple and wondrous site: The Museum of Endangered Sounds.
It takes technological objects and lets you relive the noises they
made: Tetris, the Windows 95 startup chime, that Nokia ringtone,
television static. The site archives not just the intentional sounds --
ringtones, etc -- but the incidental ones, like the mechanical noise a
VHS tape made when it entered the VCR or the way a portable CD player
sounded when it skipped. If you grew up at a certain time, these sounds
are like technoaural nostalgia whippets. One minute, you're browsing the
Internet in 2012, the next you're on a bus headed up I-5 to an 8th
grade football game against Castle Rock in 1995.
The noises our technologies make, as much as any music, are the soundtrack to an era. Soundscapes
are not static; completely new sets of frequencies arrive, old things
go. Locomotives rumbled their way through the landscapes of 19th century
New England, interrupting Nathaniel Hawthorne-types' reveries in Sleepy
Hollows. A city used to be synonymous with the sound of horse hooves
and the clatter of carriages on the stone streets. Imagine the people
who first heard the clicks of a bike wheel or the vroom of a car engine.
It's no accident that early films featuring industrial work often
include shots of steam whistles, even though in many (say, Metropolis)
we can't hear that whistle.
When I think of 2012, I will think of the overworked fan of my laptop
and the ding of getting a text message on my iPhone. I will think of
the beep of the FastTrak in my car as it debits my credit card so I can
pass through a toll onto the Golden Gate Bridge. I will think of Siri's
uncanny valley voice.
But to me, all of those sounds -- as symbols of the era in which I've
come up -- remain secondary to the hissing and crackling of the modem
handshake. I first heard that sound as a nine-year-old. To this day, I
can't remember how I figured out how to dial the modem of our old
Zenith. Even more mysterious is how I found the BBS number to call or
even knew what a BBS was. But I did. BBS were dial-in communities, kind
of like a local AOL.
You could post messages and play games, even chat with people on the
bigger BBSs. It was personal: sometimes, you'd be the only person
connected to that community. Other times, there'd be one other person,
who was almost definitely within your local prefix.
When we moved to Ridgefield, which sits outside Portland, Oregon, I had a summer with no
friends and no school: The telephone wire became a lifeline. I
discovered Country Computing, a BBS I've eulogized before,
located in a town a few miles from mine. The rural Washington BBS world
was weird and fun, filled with old ham-radio operators and
computer nerds. After my parents' closed up
shop for the work day, their "fax line" became my modem line, and I
called across the I-5 to play games and then, slowly, to participate in
the
nascent community.
In the beginning of those sessions, there was the sound, and the sound was data.
Fascinatingly, there's no good guide to the what the beeps and hisses
represent that I could find on the Internet. For one, few people care
about the technical details of 1997's hottest 56k modems. And for
another, whatever good information exists out there predates the popular
explosion of the web and the all-knowing Google.
So, I asked on Twitter and was rewarded with an accessible and elegant explanation from another user whose nom-de-plume is Miso Susanowa.
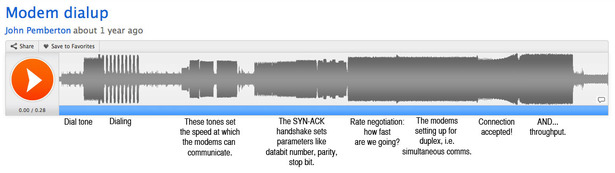
(Susanowa used to run a BBS.) I transformed it into the annotated
graphic below, which explains the modem sound part-by-part. (You can
click it to make it bigger.)
This is a choreographed sequence that allowed these digital devices to
piggyback on an analog telephone network. "A phone line carries only the small range of frequencies in
which most human conversation takes place: about 300 to 3,300 hertz," Glenn Fleishman explained in the Times back in 1998. "The
modem works within these limits in creating sound waves to carry data
across phone lines." What you're hearing is the way 20th century technology tunneled through a 19th century network;
what you're hearing is how a network designed to send the noises made
by your muscles as they pushed around air came to transmit anything, or
the almost-anything that can be coded in 0s and 1s.
The frequencies of the modem's sounds represent
parameters for further communication. In the early going, for example,
the modem that's been dialed up will play a note that says, "I can go
this fast." As a wonderful old 1997 website explained, "Depending on the speed the modem is trying to talk at, this tone will have a
different pitch."
That is to say, the sounds weren't a sign that data was being
transferred: they were the data being transferred. This noise was the
analog world being bridged by the digital. If you are old enough to
remember it, you still knew a world that was analog-first.
Long before I actually had this answer in hand, I could sense that the
patterns of the beats and noise meant something. The sound would move
me, my head nodding to the beeps that followed the initial connection.
You could feel two things trying to come into sync: Were they computers
or me and my version of the world?
As I learned again today, as I learn every day, the answer is both.
Korean Emart recently placed 3D QR code sculptures throughout the city of Seoul that could only be scanned between noon and 1 pm each day — consumers were given discounts at the store during those quiet shopping hours.
Periodic lulls in business are a fact of life for most retailers, and we’ve already seen solutions including daily deals that are valid only during those quiet times. Recently, however, we came across a concept that takes such efforts even further. Specifically, Korean Emart recently placed 3D QR code sculptures throughout the city of Seoul that could only be scanned between noon and 1 pm each day — consumers who succeeded were rewarded with discounts at the store during those quiet shopping hours.
Dubbed “Sunny Sale,” Emart’s effort involved setting up a series of what it calls “shadow” QR codes that depend on peak sunlight for proper viewing and were scannable only between 12 and 1 pm each day. Successfully scanning a code took consumers to a dedicated home page with special offers including a coupon worth USD 12. Purchases could then be made via smartphone for delivery direct to the consumer’s door. The video below explains the campaign in more detail:
As a result of its creative promotion, Emart reportedly saw membership increase by 58 percent in February over the previous month, they also observed a 25 percent increase in sales during lunch hours. Retailers around the globe: One for inspiration?
Green plants use photosynthesis to convert
water and sunlight into energy used to help the plant grow. Scientists
have created the first practical artificial leaf that mimics the natural
process and holds promise for sustainable green energy. The key to this
practical artificial leaf is that unlike earlier devices it doesn’t use
expensive components in its construction.
The new artificial leaf is made from inexpensive materials and uses
low-cost engineering and manufacturing processes making it much more
practical. The artificial leaf has an component to collect sunlight
sandwich between two films that generate oxygen and hydrogen gas. When
the artificial leaf is placed into a jar of water and placed in
sunlight, it bubbles, releasing hydrogen that can be used by fuel cells
to make electricity. Previous designs needed expensive materials like
platinum along with expensive manufacturing processes.
The new artificial leaf replaces the costly platinum with a less
expensive nickel-molybdenum-zinc compound. The opposite side of the leaf
has a cobalt film that generates oxygen gas. The hope is that this sort
of device can be used to generate electricity for remote places that
are off the electrical grid. The tech could also be used to power all
sorts of devices including phones and more.
“Considering that it is the 6 billion nonlegacy users
that are driving the enormous increase in energy demand by midcentury, a
research target of delivering solar energy to the poor with discoveries
such as the artificial leaf provides global society its most direct
path to a sustainable energy future,” he says.
Some researchers are about to try to run facial recognition algorythm on Mona Lisa painting in order to try to know who is she... but do we really want to know?
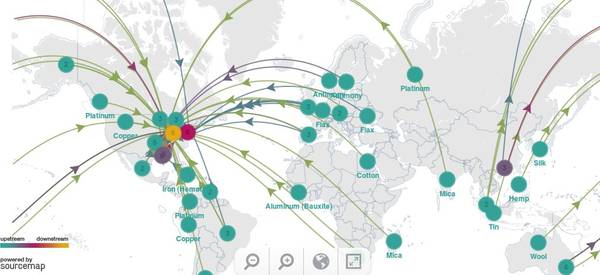
Sourcemap shows supply-chain maps that reveal all the places in the
world that feed into the common goods we consume in our lives. The
service's about page
implies that the supply-chain data comes from companies themselves, but
there's a lot of what seem to be user-generated maps like this complex map labelled "Laptop Computer". It's a tantalizing set of maps, but I wish there was more information on the data-sources that went into each map.
On the other hand, I'm loving this reconstruction of Western Electric's 1927 telephone manufacturing supply chain
by Matthew Hockenberry, who added this information: "This is a
reconstruction of the supply chain for the Western Electric produced
'candlestick' style telephones of the late 1920s. Information is largely
drawn from archival Western Electric/AT&T materials, as well as
those of supplier companies. Some imagery is currently included for
cotton and copper sources. This is a rough draft - many details are
missing or incomplete."