Tuesday, March 27. 2012
TI Demos OMAP5 WiFi Display Mirroring on Development Platform
Via AnandTech
-----

On our last day at MWC 2012, TI pulled me aside for a private demonstration of WiFi Display functionality they had only just recently finalized working on their OMAP 5 development platform. The demo showed WiFi Display mirroring working between the development device’s 720p display and an adjacent notebook which was being used as the WiFi Display sink.

TI emphasized that what’s different about their WiFi Display implementation is that it works using the display framebuffer natively and not a memory copy which would introduce delay and take up space. In addition, the encoder being used is the IVA-HD accelerator doing the WiFi Display specification’s mandatory H.264 baseline Level 3.1 encode, not a software encoder running on the application processor. The demo was running mirroring the development tablet’s 720p display, but TI says they could easily do 1080p as well, but would require a 1080p framebuffer to snoop on the host device. Latency between the development platform and display sink was just 15ms - essentially one frame at 60 Hz.
The demonstration worked live over the air at TI’s MWC booth and also used a WiLink 8 series WLAN combo chip. There was some stuttering, however this is understandable given the fact that this demo was using TCP (live implementations will use UDP) and of course just how crowded 2.4 and 5 GHz spectrum is at these conferences. In addition, TI collaborated with Screenovate for their application development and WiFi Display optimization secret sauce, which I’m guessing has to do with adaptive bitrate or possibly more.
Enabling higher than 480p software encoded WiFi Display is just one more obvious piece of the puzzle which will eventually enable smartphones and tablets to obviate standalone streaming devices.
-----
Personal Comment:
Kind of obvious and interesting step forward as it is more and more requested by mobile devices users to be able to beam or 'to TV' mobile device's screens... which should lead to transform any (mobile) device in a full-duplex video broadcasting enabled device (user interaction included!) ... and one may then succeed in getting rid of some cables in the same sitting?!
Wednesday, March 21. 2012
World’s First Flying File-Sharing Drones in Action
Via TorrentFreak
-----
A few days ago The Pirate Bay announced that in future parts of its site could be hosted on GPS controlled drones. To many this may have sounded like a joke, but in fact these pirate drones already exist. Project “Electronic Countermeasures” has built a swarm of five fully operational drones which prove that an “aerial Napster” or an “airborne Pirate Bay” is not as futuristic as it sounds.
 In an ever-continuing effort to thwart censorship, The Pirate Bay plans to turn flying drones into mobile hosting locations.
In an ever-continuing effort to thwart censorship, The Pirate Bay plans to turn flying drones into mobile hosting locations.
“Everyone knows WHAT TPB is. Now they’re going to have to think about WHERE TPB is,” The Pirate Bay team told TorrentFreak last Sunday, announcing their drone project.
Liam Young, co-founder of Tomorrow’s Thoughts Today, was amazed to read the announcement, not so much because of the technology, because his group has already built a swarm of file-sharing drones.
“I thought hold on, we are already doing that,” Young told TorrentFreak.
Their starting point for project “Electronic Countermeasures” was to create something akin to an ‘aerial Napster’ or ‘airborne Pirate Bay’, but it became much more than that.
“Part nomadic infrastructure and part robotic swarm, we have rebuilt and programmed the drones to broadcast their own local Wi-Fi network as a form of aerial Napster. They swarm into formation, broadcasting their pirate network, and then disperse, escaping detection, only to reform elsewhere,” says the group describing their creation.
File-Sharing Drone in Action (photo by Claus Langer)

In short the system allows the public to share data with the help of flying drones. Much like the Pirate Box, but one that flies autonomously over the city.
“The public can upload files, photos and share data with one another as the drones float above the significant public spaces of the city. The swarm becomes a pirate broadcast network, a mobile infrastructure that passers-by can interact with,” the creators explain.
One major difference compared to more traditional file-sharing hubs is that it requires a hefty investment. Each of the drones costs 1500 euros to build. Not a big surprise, considering the hardware that’s needed to keep these pirate hubs in the air.
“Each one is powered by 2x 2200mAh LiPo batteries. The lift is provided by 4x Roxxy Brushless Motors that run off a GPS flight control board. Also on deck are altitude sensors and gyros that keep the flight stable. They all talk to a master control system through XBee wireless modules,” Young told TorrentFreak.
“These all sit on a 10mm x 10mm aluminum frame and are wrapped in a vacuum formed aerodynamic cowling. The network is broadcast using various different hardware setups ranging from Linux gumstick modules, wireless routers and USB sticks for file storage.”
For Young and his crew this is just the beginning. With proper financial support they hope to build more drones and increase the range they can cover.
“We are planning on scaling up the system by increasing broadcast range and building more drones for the flock. We are also building in other systems like autonomous battery change bases. We are looking for funding and backers to assist us in scaling up the system,” he told us.
Those who see the drones in action (video below) will notice that they’re not just practical. The creative and artistic background of the group shines through, with the choreography performed by the drones perhaps even more stunning than the sharing component.
“When the audience interacts with the drones they glow with vibrant colors, they break formation, they are called over and their flight pattern becomes more dramatic and expressive,” the group explains.
Besides the artistic value, the drones can also have other use cases than being a “pirate hub.” For example, they can serve as peer-to-peer communications support for protesters and activists in regions where Internet access is censored.
Either way, whether it’s Hollywood or a dictator, there will always be groups that have a reason to shoot the machines down. But let’s be honest, who would dare to destroy such a beautiful piece of art?
Electronic Countermeasures @ GLOW Festival NL 2011 from liam young on Vimeo.
Monday, February 27. 2012
Everyone’s Trying to Track What You Do on the Web: Here’s How to Stop Them
Via Life Hacker
-----
It's no secret that there's big money to be made in violating your privacy. Companies will pay big bucks to learn more about you, and service providers on the web are eager to get their hands on as much information about you as possible.
So what do you do? How do you keep your information out of everyone else's hands? Here's a guide to surfing the web while keeping your privacy intact.
The adage goes, "If you're not paying for a service, you're the product, not the customer," and it's never been more true. Every day more news breaks about a new company that uploads your address book to their servers, skirts in-browser privacy protection, and tracks your every move on the web to learn as much about your browsing habits and activities as possible. In this post, we'll explain why you should care, and help you lock down your surfing so you can browse in peace.

Why You Should Care
Your personal information is valuable. More valuable than you might think. When we originally published our guide to stop Facebook from tracking you around the web, some people cried "So what if they track me? I'm not that important/I have nothing to hide/they just want to target ads to me and I'd rather have targeted ads over useless ones!" To help explain why this is short-sighted and a bit naive, let me share a personal story.
Before I joined the Lifehacker team, I worked at a company that traded in information. Our clients were huge companies and one of the services we offered was to collect information about people, their demographics, income, and habits, and then roll it up so they could get a complete picture about who you are and how to convince you to buy their products. In some cases, we designed web sites and campaigns to convince you to provide even more information in exchange for a coupon, discount, or the simple promise of other of those. It works very, very well.
The real money is in taking your data and shacking up with third parties to help them come up with new ways to convince you to spend money, sign up for services, and give up more information. Relevant ads are nice, but the real value in your data exists where you won't see it until you're too tempted by the offer to know where it came from, whether it's a coupon in your mailbox or a new daily deal site with incredible bargains tailored to your desires. It all sounds good until you realize the only thing you have to trade for such "exciting" bargains is everything personal about you: your age, income, family's ages and income, medical history, dietary habits, favorite web sites, your birthday...the list goes on. It would be fine if you decided to give up this information for a tangible benefit, but you may never see a benefit aside from an ad, and no one's including you in the decision. Here's how to take back that control.
Click for instructions for your browser of choice:



How to Stop Trackers from Following Where You're Browsing with Chrome
If you're a Chrome user, there are tons of great add-ons and tools designed to help you uncover which sites transmit data to third parties without your knowledge, which third parties are talking about you, and which third parties are tracking your activity across sites. This list isn't targeted to a specific social network or company—instead, these extensions can help you with multiple offenders.

- Adblock Plus - We've discussed AdBlock plus several times, but there's never been a better time to install it than now. For extra protection, one-click installs the Antisocial subscription for AdBlock. With it, you can banish social networks like Facebook, Twitter, and Google+ from transmitting data about you after you leave those sites, even if the page you visit has a social plugin on it.
- Ghostery - Ghostery does an excellent job at blocking the invisible tracking cookies and plug-ins on many web sites, showing it all to you, and then giving you the choice whether you want to block them one-by-one, or all together so you'll never worry about them again. The best part about Ghostery is that it's not just limited to social networks, but will also catch and show you ad-networks and web publishers as well.
- ScriptNo for Chrome - ScriptNo is much like Ghostery in that any scripts running on any site you visit will sound its alarms. The difference is that while Ghostery is a bit more exclusive about the types of information it alerts you to, ScriptNo will sound the alarm at just about everything, which will break a ton of websites. You'll visit the site, half of it won't load or work, and you'll have to selectively enable scripts until it's usable. Still, its intuitive interface will help you choose which scripts on a page you'd like to allow and which you'd like to block without sacrificing the actual content on the page you'd like to read.

- Do Not Track Plus - The "Do Not Track" feature that most browsers have is useful, but if you want to beef them up, the previously mentioned Do Not Track Plus extension puts a stop to third-party data exchanges, like when you visit a site like ours that has Facebook and Google+ buttons on it. By default, your browser will tell the network that you're on a site with those buttons—with the extension installed, no information is sent until you choose to click one. Think of it as opt-in social sharing, instead of all-in.
Ghostery, AdBlock Plus, and Do Not Track are the ones you'll need the most. ScriptNo is a bit more advanced, and may take some getting used to. In addition to installing extensions, make sure you practice basic browser maintenance that keeps your browser running smoothly and protects your privacy at the same time. Head into Chrome's Advanced Content Settings, and make sure you have third-party cookies blocked and all cookies set to clear after browsing sessions. Log out of social networks and web services when you're finished using them instead of just leaving them perpetually logged in, and use Chrome's "Incognito Mode" whenever you're concerned about privacy.

Mobile Browsing
Mobile browsing is a new frontier. There are dozens of mobile browsers, and even though most people use the one included on their device, there are few tools to protect your privacy by comparison to the desktop. Check to see if your preferred browser has a "privacy mode" that you can use while browsing, or when you're logged in to social networks and other web services. Try to keep your social network use inside the apps developed for it, and—as always—make sure to clear your private data regularly.
Some mobile browsers have private modes and the ability to automatically clear your private data built in, like Firefox for Android, Atomic Web Browser, and Dolphin Browser for both iOS and Android. Considering Dolphin is our pick for the best Android browser and Atomic is our favorite for iOS, they're worth downloading.
Extreme Measures
If none of these extensions make you feel any better, or you want to take protecting your privacy and personal data to the next level, it's time to break out the big guns. One tip that came up during our last discussion about Facebook was to use a completely separate web browser just for logged-in social networks and web services, and another browser for potentially sensitive browsing, like your internet shopping, banking, and other personal activities. If you have some time to put into it, check out our guide to browsing without leaving a trace, which was written for Firefox, but can easily be adapted to any browser you use.

If you're really tired of companies tracking you and trading in your personal information, you always have the option to just provide false information. The same way you might give a fake phone number or address to a supermarket card sign-up sheet, you can scrub or change personal details about yourself from your social network profiles, Google accounts, Windows Live account, and others.
Change your birthdate, or your first name. Set your phone number a digit off, or omit your apartment number when asked for your street address. We've talked about how to disappear before, and carefully examine the privacy and account settings for the web services you use. Keep in mind that some of this goes against the terms of service for those companies and services—they have a vested interest in knowing the real you, after all, so tread carefully and tread lightly if you want to go the "make yourself anonymous" route. Worst case, start closing accounts with offending services, and migrate to other, more privacy-friendly options.
These are just a few tips that won't significantly change your browsing experience, but can go a long way toward protecting your privacy. This issue isn't going anywhere, and as your personal information becomes more valuable and there are more ways to keep it away from prying eyes, you'll see more news of companies finding ways to eke out every bit of data from you and the sites you use. Some of these methods are more intrusive than others, and some of them may turn you off entirely, but the important thing is that they all give you control over how you experience the web. When you embrace your privacy, you become engaged with the services you use. With a little effort and the right tools, you can make the web more opt-in than it is opt-out.
Thursday, February 23. 2012
MOTHER artificial intelligence forces nerds to do the chores… or else
Via Slash Gear
-----
If you’ve ever been inside a dormitory full of computer science undergraduates, you know what horrors come of young men free of responsibility. To help combat the lack of homemaking skills in nerds everywhere, a group of them banded together to create MOTHER, a combination of home automation, basic artificial intelligence and gentle nagging designed to keep a domicile running at peak efficiency. And also possibly kill an entire crew of space truckers if they should come in contact with a xenomorphic alien – but that code module hasn’t been installed yet.

The project comes from the LVL1 Hackerspace, a group of like-minded
programmers and engineers. The aim is to create an AI suited for a home
environment that detect issues and gets its users (i.e. the people living in
the home) to fix it. Through an array of digital sensors, MOTHER knows
when the trash needs to be taken out, when the door is left unlocked, et
cetera. If something isn’t done soon enough, she it can even
disable the Internet connection for individual computers. MOTHER can
notify users of tasks that need to be completed through a standard
computer, phones or email, or stock ticker-like displays. In addition,
MOTHER can use video and audio tools to recognize individual users,
adjust the lighting, video or audio to their tastes, and generally keep
users informed and creeped out at the same time.
MOTHER’s abilities are technically limitless – since it’s all based on open source software, those with the skill, inclination and hardware components can add functions at any time. Some of the more humorous additions already in the project include an instant dubstep command. You can build your own MOTHER (boy, there’s a sentence I never thought I’d be writing) by reading through the official Wiki and assembling the right software, sensors, servers and the like. Or you could just invite your mom over and take your lumps. Your choice.
Monday, February 06. 2012
The Great Disk Drive in the Sky: How Web giants store big—and we mean big—data
Via Ars Technica
-----

Google technicians test hard drives at their data center in Moncks Corner, South Carolina -- Image courtesy of Google Datacenter Video
Consider the tech it takes to back the search box on Google's home page: behind the algorithms, the cached search terms, and the other features that spring to life as you type in a query sits a data store that essentially contains a full-text snapshot of most of the Web. While you and thousands of other people are simultaneously submitting searches, that snapshot is constantly being updated with a firehose of changes. At the same time, the data is being processed by thousands of individual server processes, each doing everything from figuring out which contextual ads you will be served to determining in what order to cough up search results.
The storage system backing Google's search engine has to be able to serve millions of data reads and writes daily from thousands of individual processes running on thousands of servers, can almost never be down for a backup or maintenance, and has to perpetually grow to accommodate the ever-expanding number of pages added by Google's Web-crawling robots. In total, Google processes over 20 petabytes of data per day.
That's not something that Google could pull off with an off-the-shelf storage architecture. And the same goes for other Web and cloud computing giants running hyper-scale data centers, such as Amazon and Facebook. While most data centers have addressed scaling up storage by adding more disk capacity on a storage area network, more storage servers, and often more database servers, these approaches fail to scale because of performance constraints in a cloud environment. In the cloud, there can be potentially thousands of active users of data at any moment, and the data being read and written at any given moment reaches into the thousands of terabytes.
The problem isn't simply an issue of disk read and write speeds. With data flows at these volumes, the main problem is storage network throughput; even with the best of switches and storage servers, traditional SAN architectures can become a performance bottleneck for data processing.
Then there's the cost of scaling up storage conventionally. Given the rate that hyper-scale web companies add capacity (Amazon, for example, adds as much capacity to its data centers each day as the whole company ran on in 2001, according to Amazon Vice President James Hamilton), the cost required to properly roll out needed storage in the same way most data centers do would be huge in terms of required management, hardware, and software costs. That cost goes up even higher when relational databases are added to the mix, depending on how an organization approaches segmenting and replicating them.
The need for this kind of perpetually scalable, durable storage has driven the giants of the Web—Google, Amazon, Facebook, Microsoft, and others—to adopt a different sort of storage solution: distributed file systems based on object-based storage. These systems were at least in part inspired by other distributed and clustered filesystems such as Red Hat's Global File System and IBM's General Parallel Filesystem.
The architecture of the cloud giants' distributed file systems separates the metadata (the data about the content) from the stored data itself. That allows for high volumes of parallel reading and writing of data across multiple replicas, and the tossing of concepts like "file locking" out the window.
The impact of these distributed file systems extends far beyond the walls of the hyper-scale data centers they were built for— they have a direct impact on how those who use public cloud services such as Amazon's EC2, Google's AppEngine, and Microsoft's Azure develop and deploy applications. And companies, universities, and government agencies looking for a way to rapidly store and provide access to huge volumes of data are increasingly turning to a whole new class of data storage systems inspired by the systems built by cloud giants. So it's worth understanding the history of their development, and the engineering compromises that were made in the process.
Google File System
Google was among the first of the major Web players to face the storage scalability problem head-on. And the answer arrived at by Google's engineers in 2003 was to build a distributed file system custom-fit to Google's data center strategy—Google File System (GFS).
GFS is the basis for nearly all of the company's cloud services. It handles data storage, including the company's BigTable database and the data store for Google's AppEngine platform-as-a-service, and it provides the data feed for Google's search engine and other applications. The design decisions Google made in creating GFS have driven much of the software engineering behind its cloud architecture, and vice-versa. Google tends to store data for applications in enormous files, and it uses files as "producer-consumer queues," where hundreds of machines collecting data may all be writing to the same file. That file might be processed by another application that merges or analyzes the data—perhaps even while the data is still being written.
Google keeps most technical details of GFS to itself, for obvious reasons. But as described by Google research fellow Sanjay Ghemawat, principal engineer Howard Gobioff, and senior staff engineer Shun-Tak Leung in a paper first published in 2003, GFS was designed with some very specific priorities in mind: Google wanted to turn large numbers of cheap servers and hard drives into a reliable data store for hundreds of terabytes of data that could manage itself around failures and errors. And it needed to be designed for Google's way of gathering and reading data, allowing multiple applications to append data to the system simultaneously in large volumes and to access it at high speeds.
Much in the way that a RAID 5 storage array "stripes" data across multiple disks to gain protection from failures, GFS distributes files in fixed-size chunks which are replicated across a cluster of servers. Because they're cheap computers using cheap hard drives, some of those servers are bound to fail at one point or another—so GFS is designed to be tolerant of that without losing (too much) data.
But the similarities between RAID and GFS end there, because those servers can be distributed across the network—either within a single physical data center or spread over different data centers, depending on the purpose of the data. GFS is designed primarily for bulk processing of lots of data. Reading data at high speed is what's important, not the speed of access to a particular section of a file, or the speed at which data is written to the file system. GFS provides that high output at the expense of more fine-grained reads and writes to files and more rapid writing of data to disk. As Ghemawat and company put it in their paper, "small writes at arbitrary positions in a file are supported, but do not have to be efficient."
This distributed nature, along with the sheer volume of data GFS handles—millions of files, most of them larger than 100 megabytes and generally ranging into gigabytes—requires some trade-offs that make GFS very much unlike the sort of file system you'd normally mount on a single server. Because hundreds of individual processes might be writing to or reading from a file simultaneously, GFS needs to supports "atomicity" of data—rolling back writes that fail without impacting other applications. And it needs to maintain data integrity with a very low synchronization overhead to avoid dragging down performance.
GFS consists of three layers: a GFS client, which handles requests for data from applications; a master, which uses an in-memory index to track the names of data files and the location of their chunks; and the "chunk servers" themselves. Originally, for the sake of simplicity, GFS used a single master for each cluster, so the system was designed to get the master out of the way of data access as much as possible. Google has since developed a distributed master system that can handle hundreds of masters, each of which can handle about 100 million files.
When the GFS client gets a request for a specific data file, it requests the location of the data from the master server. The master server provides the location of one of the replicas, and the client then communicates directly with that chunk server for reads and writes during the rest of that particular session. The master doesn't get involved again unless there's a failure.
To ensure that the data firehose is highly available, GFS trades off some other things—like consistency across replicas. GFS does enforce data's atomicity—it will return an error if a write fails, then rolls the write back in metadata and promotes a replica of the old data, for example. But the master's lack of involvement in data writes means that as data gets written to the system, it doesn't immediately get replicated across the whole GFS cluster. The system follows what Google calls a "relaxed consistency model" out of the necessities of dealing with simultaneous access to data and the limits of the network.
This means that GFS is entirely okay with serving up stale data from an old replica if that's what's the most available at the moment—so long as the data eventually gets updated. The master tracks changes, or "mutations," of data within chunks using version numbers to indicate when the changes happened. As some of the replicas get left behind (or grow "stale"), the GFS master makes sure those chunks aren't served up to clients until they're first brought up-to-date.
But that doesn't necessarily happen with sessions already connected to those chunks. The metadata about changes doesn't become visible until the master has processed changes and reflected them in its metadata. That metadata also needs to be replicated in multiple locations in case the master fails—because otherwise the whole file system is lost. And if there's a failure at the master in the middle of a write, the changes are effectively lost as well. This isn't a big problem because of the way that Google deals with data: the vast majority of data used by its applications rarely changes, and when it does data is usually appended rather than modified in place.
While GFS was designed for the apps Google ran in 2003, it wasn't long before Google started running into scalability issues. Even before the company bought YouTube, GFS was starting to hit the wall—largely because the new applications Google was adding didn't work well with the ideal 64-megabyte file size. To get around that, Google turned to Bigtable, a table-based data store that vaguely resembles a database and sits atop GFS. Like GFS below it, Bigtable is mostly write-once, so changes are stored as appends to the table—which Google uses in applications like Google Docs to handle versioning, for example.
The foregoing is mostly academic if you don't work at Google (though it may help users of AppEngine, Google Cloud Storage and other Google services to understand what's going on under the hood a bit better). While Google Cloud Storage provides a public way to store and access objects stored in GFS through a Web interface, the exact interfaces and tools used to drive GFS within Google haven't been made public. But the paper describing GFS led to the development of a more widely used distributed file system that behaves a lot like it: the Hadoop Distributed File System.
Hadoop DFS
Developed in Java and open-sourced as a project of the Apache Foundation, Hadoop has developed such a following among Web companies and others coping with "big data" problems that it has been described as the "Swiss army knife of the 21st Century." All the hype means that sooner or later, you're more likely to find yourself dealing with Hadoop in some form than with other distributed file systems—especially when Microsoft starts shipping it as an Windows Server add-on.
Named by developer Doug Cutting after his son's stuffed elephant, Hadoop was "inspired" by GFS and Google's MapReduce distributed computing environment. In 2004, as Cutting and others working on the Apache Nutch search engine project sought a way to bring the crawler and indexer up to "Web scale," Cutting read Google's papers on GFS and MapReduce and started to work on his own implementation. While most of the enthusiasm for Hadoop comes from Hadoop's distributed data processing capability, derived from its MapReduce-inspired distributed processing management, the Hadoop Distributed File System is what handles the massive data sets it works with.
Hadoop is developed under the Apache license, and there are a number of commercial and free distributions available. The distribution I worked with was from Cloudera (Doug Cutting's current employer)—the Cloudera Distribution Including Apache Hadoop (CDH), the open-source version of Cloudera's enterprise platform, and Cloudera Service and Configuration Express Edition, which is free for up to 50 nodes.
HortonWorks, the company with which Microsoft has aligned to help move Hadoop to Azure and Windows Server (and home to much of the original Yahoo team that worked on Hadoop), has its own Hadoop-based HortonWorks Data Platform in a limited "technology preview" release. There's also a Debian package of the Apache Core, and a number of other open-source and commercial products that are based on Hadoop in some form.
HDFS can be used to support a wide range of applications where high volumes of cheap hardware and big data collide. But because of its architecture, it's not exactly well-suited to general purpose data storage, and it gives up a certain amount of flexibility. HDFS has to do away with certain things usually associated with file systems in order to make sure it can perform well with massive amounts of data spread out over hundreds, or even thousands, of physical machines—things like interactive access to data.
While Hadoop runs in Java, there are a number of ways to interact with HDFS besides its Java API. There's a C-wrapped version of the API, a command line interface through Hadoop, and files can be browsed through HTTP requests. There's also MountableHDFS, an add-on based on FUSE that allows HDFS to be mounted as a file system by most operating systems. Developers are working on a WebDAV interface as well to allow Web-based writing of data to the system.
HDFS follows the architectural path laid out by Google's GFS fairly closely, following its three-tiered, single master model. Each Hadoop cluster has a master server called the "NameNode" which tracks the metadata about the location and replication state of each 64-megabyte "block" of storage. Data is replicated across the "DataNodes" in the cluster—the slave systems that handle data reads and writes. Each block is replicated three times by default, though the number of replicas can be increased by changing the configuration of the cluster.
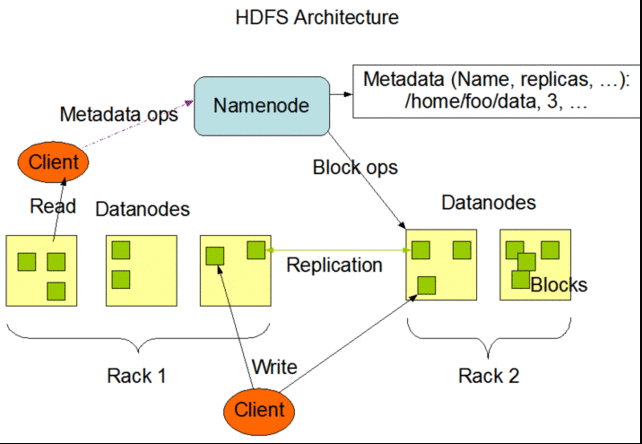
As in GFS, HDFS gets the master server out of the read-write loop as quickly as possible to avoid creating a performance bottleneck. When a request is made to access data from HDFS, the NameNode sends back the location information for the block on the DataNode that is closest to where the request originated. The NameNode also tracks the health of each DataNode through a "heartbeat" protocol and stops sending requests to DataNodes that don't respond, marking them "dead."
After the handoff, the NameNode doesn't handle any further interactions. Edits to data on the DataNodes are reported back to the NameNode and recorded in a log, which then guides replication across the other DataNodes with replicas of the changed data. As with GFS, this results in a relatively lazy form of consistency, and while the NameNode will steer new requests to the most recently modified block of data, jobs in progress will still hit stale data on the DataNodes they've been assigned to.
That's not supposed to happen much, however, as HDFS data is supposed to be "write once"—changes are usually appended to the data, rather than overwriting existing data, making for simpler consistency. And because of the nature of Hadoop applications, data tends to get written to HDFS in big batches.
When a client sends data to be written to HDFS, it first gets staged in a temporary local file by the client application until the data written reaches the size of a data block—64 megabytes, by default. Then the client contacts the NameNode and gets back a datanode and block location to write the data to. The process is repeated for each block of data committed, one block at a time. This reduces the amount of network traffic created, and it slows down the write process as well. But HDFS is all about the reads, not the writes.
Another way HDFS can minimize the amount of write traffic over the network is in how it handles replication. By activating an HDFS feature called "rack awareness" to manage distribution of replicas, an administrator can specify a rack ID for each node, designating where it is physically located through a variable in the network configuration script. By default, all nodes are in the same "rack." But when rack awareness is configured, HDFS places one replica of each block on another node within the same data center rack, and another in a different rack to minimize the amount of data-writing traffic across the network—based on the reasoning that the chance of a whole rack failure is less likely than the failure of a single node. In theory, this improves overall write performance to HDFS without sacrificing reliability.
As with the early version of GFS, HDFS's NameNode potentially creates a single point of failure for what's supposed to be a highly available and distributed system. If the metadata in the NameNode is lost, the whole HDFS environment becomes essentially unreadable—like a hard disk that has lost its file allocation table. HDFS supports using a "backup node," which keeps a synchronized version of the NameNode's metadata in-memory, and stores snap-shots of previous states of the system so that it can be rolled back if necessary. Snapshots can also be stored separately on what's called a "checkpoint node." However, according to the HDFS documentation, there's currently no support within HDFS for automatically restarting a crashed NameNode, and the backup node doesn't automatically kick in and replace the master.
HDFS and GFS were both engineered with search-engine style tasks in mind. But for cloud services targeted at more general types of computing, the "write once" approach and other compromises made to ensure big data query performance are less than ideal—which is why Amazon developed its own distributed storage platform, called Dynamo.
Amazon's S3 and Dynamo
As Amazon began to build its Web services platform, the company had much different application issues than Google.
Until recently, like GFS, Dynamo hasn't been directly exposed to customers. As Amazon CTO Werner Vogels explained in his blog in 2007, it is the underpinning of storage services and other parts of Amazon Web Services that are highly exposed to Amazon customers, including Amazon's Simple Storage Service (S3) and SimpleDB. But on January 18 of this year, Amazon launched a database service called DynamoDB, based on the latest improvements to Dynamo. It gave customers a direct interface as a "NoSQL" database.
Dynamo has a few things in common with GFS and HDFS: it's also designed with less concern for consistency of data across the system in exchange for high availability, and to run on Amazon's massive collection of commodity hardware. But that's where the similarities start to fade away, because Amazon's requirements for Dynamo were totally different.
Amazon needed a file system that could deal with much more general purpose data access—things like Amazon's own e-commerce capabilities, including customer shopping carts, and other very transactional systems. And the company needed much more granular and dynamic access to data. Rather than being optimized for big streams of data, the need was for more random access to smaller components, like the sort of access used to serve up webpages.
According to the paper presented by Vogels and his team at the Symposium on Operating Systems Principles conference in October 2007, "Dynamo targets applications that need to store objects that are relatively small (usually less than 1 MB)." And rather than being optimized for reads, Dynamo is designed to be "always writeable," being highly available for data input—precisely the opposite of Google's model.
"For a number of Amazon services," the Amazon Dynamo team wrote in their paper, "rejecting customer updates could result in a poor customer experience. For instance, the shopping cart service must allow customers to add and remove items from their shopping cart even amidst network and server failures." At the same time, the services based on Dynamo can be applied to much larger data sets—in fact, Amazon offers the Hadoop-based Elastic MapReduce service based on S3 atop of Dynamo.
In order to meet those requirements, Dynamo's architecture is almost the polar opposite of GFS—it more closely resembles a peer-to-peer system than the master-slave approach. Dynamo also flips how consistency is handled, moving away from having the system resolve replication after data is written, and instead doing conflict resolution on data when executing reads. That way, Dynamo never rejects a data write, regardless of whether it's new data or a change to existing data, and the replication catches up later.
Because of concerns about the pitfalls of a central master server failure (based on previous experiences with service outages), and the pace at which Amazon adds new infrastructure to its cloud, Vogel's team chose a decentralized approach to replication. It was based on a self-governing data partitioning scheme that used the concept of consistent hashing. The resources within each Dynamo cluster are mapped as a continuous circle of address spaces, and each storage node in the system is given a random value as it is added to the cluster—a value that represents its "position" on the Dynamo ring. Based on the number of storage nodes in the cluster, each node takes responsibility for a chunk of address spaces based on its position. As storage nodes are added to the ring, they take over chunks of address space and the nodes on either side of them in the ring adjust their responsibility. Since Amazon was concerned about unbalanced loads on storage systems as newer, better hardware was added to clusters, Dynamo allows multiple virtual nodes to be assigned to each physical node, giving bigger systems a bigger share of the address space in the cluster.
When data gets written to Dynamo—through a "put" request—the systems assigns a key to the data object being written. That key gets run through a 128-bit MD5 hash; the value of the hash is used as an address within the ring for the data. The data node responsible for that address becomes the "coordinator node" for that data and is responsible for handling requests for it and prompting replication of the data to other nodes in the ring, as shown in the Amazon diagram below:

This spreads requests out across all the nodes in the system. In the event of a failure of one of the nodes, its virtual neighbors on the ring start picking up requests and fill in the vacant space with their replicas.
Then there's Dynamo's consistency-checking scheme. When a "get" request comes in from a client application, Dynamo polls its nodes to see who has a copy of the requested data. Each node with a replica responds, providing information about when its last change was made, based on a vector clock—a versioning system that tracks the dependencies of changes to data. Depending on how the polling is configured, the request handler can wait to get just the first response back and return it (if the application is in a hurry for any data and there's low risk of a conflict—like in a Hadoop application) or it can wait for two, three, or more responses. For multiple responses from the storage nodes, the handler checks to see which is most up-to-date and alerts the nodes that are stale to copy the data from the most current, or it merges versions that have non-conflicting edits. This scheme works well for resiliency under most circumstances—if nodes die, and new ones are brought online, the latest data gets replicated to the new node.
The most recent improvements in Dynamo, and the creation of DynamoDB, were the result of looking at why Amazon's internal developers had not adopted Dynamo itself as the base for their applications, and instead relied on the services built atop it—S3, SimpleDB, and Elastic Block Storage. The problems that Amazon faced in its April 2011 outage were the result of replication set up between clusters higher in the application stack—in Amazon's Elastic Block Storage, where replication overloaded the available additional capacity, rather than because of problems with Dynamo itself.
The overall stability of Dynamo has made it the inspiration for open-source copycats just as GFS did. Facebook relies on Cassandra, now an Apache project, which is based on Dynamo. Basho's Riak "NoSQL" database also is derived from the Dynamo architecture.
Microsoft's Azure DFS
When Microsoft launched the Azure platform-as-a-service, it faced a similar set of requirements to those of Amazon—including massive amounts of general-purpose storage. But because it's a PaaS, Azure doesn't expose as much of the infrastructure to its customers as Amazon does with EC2. And the service has the benefit of being purpose-built as a platform to serve cloud customers instead of being built to serve a specific internal mission first.
So in some respects, Azure's storage architecture resembles Amazon's—it's designed to handle a variety of sizes of "blobs," tables, and other types of data, and to provide quick access at a granular level. But instead of handling the logical and physical mapping of data at the storage nodes themselves, Azure's storage architecture separates the logical and physical partitioning of data into separate layers of the system. While incoming data requests are routed based on a logical address, or "partition," the distributed file system itself is broken into gigabyte-sized chunks, or "extents." The result is a sort of hybrid of Amazon's and Google's approaches, illustrated in this diagram from Microsoft:
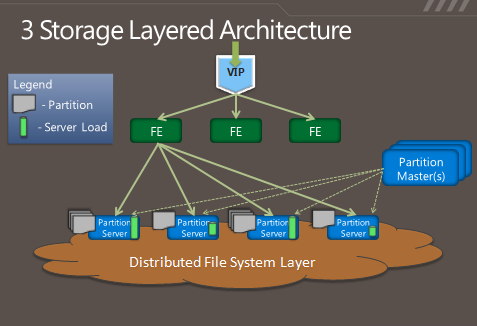
As Microsoft's Brad Calder describes in his overview of Azure's storage architecture, Azure uses a key system similar to that used in Dynamo to identify the location of data. But rather than having the application or service contact storage nodes directly, the request is routed through a front-end layer that keeps a map of data partitions in a role similar to that of HDFS's NameNode. Unlike HDFS, Azure uses multiple front-end servers, load balancing requests across them. The front-end server handles all of the requests from the client application authenticating the request, and handles communicating with the next layer down—the partition layer.
Each logical chunk of Azure's storage space is managed by a partition server, which tracks which extents within the underlying DFS hold the data. The partition server handles the reads and writes for its particular set of storage objects. The physical storage of those objects is spread across the DFS' extents, so all partition servers each have access to all of the extents in the DFS. In addition to buffering the DFS from the front-end servers's read and write requests, the partition servers also cache requested data in memory, so repeated requests can be responded to without having to hit the underlying file system. That boosts performance for small, frequent requests like those used to render a webpage.
All of the metadata for each partition is replicated back to a set of "partition master" servers, providing a backup of the information if a partition server fails—if one goes down, its partitions are passed off to other partition servers dynamically. The partition masters also monitor the workload on each partition server in the Azure storage cluster; if a particular partition server is becoming overloaded, the partition master can dynamically re-assign partitions.
Azure is unlike the other big DFS systems in that it more tightly enforces consistency of data writes. Replication of data happens when writes are sent to the DFS, but it's not the lazy sort of replication that is characteristic of GFS and HDFS. Each extent of storage is managed by a primary DFS server and replicated to multiple secondaries; one DFS server may be a primary for a subset of extents and a secondary server for others. When a partition server passes a write request to DFS, it contacts the primary server for the extent the data is being written to, and the primary passes the write to its secondaries. The write is only reported as successful when the data has been replicated successfully to three secondary servers.
As with the partition layer, Azure DFS uses load balancing on the physical layer in an attempt to prevent systems from getting jammed with too much I/O. Each partition server monitors the workload on the primary extent servers it accesses; when a primary DFS server starts to red-line, the partition server starts redirecting read requests to secondary servers, and redirecting writes to extents on other servers.
The next level of "distributed"
Distributed file systems are hardly a guarantee of perpetual uptime. In most cases, DFS's only replicate within the same data center because of the amount of bandwidth required to keep replicas in sync. But replication within the data center, for example doesn't help when the whole data center gets taken offline or a backup network switch fails to kick in when the primary fails. In August, Microsoft and Amazon both had data centers in Dublin taken offline by a transformer explosion—which created a spike that kept backup generators from starting.
Systems that are lazier about replication, such as GFS and Hadoop, can asynchronously handle replication between two data centers; for example, using "rack awareness," Hadoop clusters can be configured to point to a DataNode offsite, and metadata can be passed to a remote checkpoint or backup node (at least in theory). But for more dynamic data, that sort of replication can be difficult to manage.
That's one of the reasons Microsoft released a feature called "geo-replication" in September. Geo-replication is a feature that will sync customers' data between two data center locations hundred of miles apart. Rather than using the tightly coupled replication Microsoft uses within the data center, geo-replication happens asynchronously. Both of the Azure data centers have to be in the same region; for example, data for an application set up through the Azure Portal at the North Central US data center can be replicated to the South Central US.
In Amazon's case, the company does replication across availability zones at a service level rather than down in the Dynamo architecture. While Amazon hasn't published how it handles its own geo-replication, it provides customers with the ability to "snap shot" their EBS storage to a remote S3 data "bucket."
And that's the approach Amazon and Google have generally taken in evolving their distributed file systems: making the fixes in the services based on them, rather than in the underlying architecture. While Google has added a distributed master system to GFS and made other tweaks to accommodate its ever-growing data flows, the fundamental architecture of Google's system is still very much like it was in 2003.
But in the long term, the file systems themselves may become more focused on being an archive of data than something applications touch directly. In an interview with Ars, database pioneer (and founder of VoltDB) Michael Stonebraker said that as data volumes continue to go up for "big data" applications, server memory is becoming "the new disk" and file systems are becoming where the log for application activity gets stored—"the new tape." As the cloud giants push for more power efficiency and performance from their data centers, they have already moved increasingly toward solid-state drives and larger amounts of system memory.
Tuesday, January 10. 2012
Microsoft Reinvents Wi-Fi for White Spaces
Friday, December 23. 2011
Why Silent Updates Work: Chrome 16 Passes IE9 in 2 Days
Via TomsGuide
-----
Microsoft announced that it will be launching silent updates for IE9 in January.
 Despite
the controversy of user control, Microsoft especially has a reason to
make this move to react to browser "update fatigue" that has resulted in
virtually "stale" IE users who won't upgrade their browsers unless they
upgrade their operating system as well.
Despite
the controversy of user control, Microsoft especially has a reason to
make this move to react to browser "update fatigue" that has resulted in
virtually "stale" IE users who won't upgrade their browsers unless they
upgrade their operating system as well.
The most recent upgrade of Google's Chrome browser shows just how well the silent update feature works. Within five days of introduction, Chrome 15 market share fell from 24.06 percent to just 6.38 percent, while the share of Chrome 16 climbed from 0.35 percent to 19.81 percent, according to StatCounter. Within five days, Google moved about 75 percent of its user base - more than 150 million users - from one browser to another. Within three days, Chrome 16 market share surpassed the market share of IE9 (currently at about 10.52 percent for this month), in four days it surpassed Firefox 8 (currently at about 15.60 percent) and will be passing IE8 today, StatCounter data indicates.
What makes this data so important is the fact that Google is dominating HTML5 capability across all operating system platforms and not just Windows 7, where IE9 has a slight advantage, according to Microsoft (StatCounter does not break out data for browser share on individual operating systems). IE9 was introduced on March 14 of 2011, has captured only 10.52 percent market share and has followed a similar slow upgrade pattern as its predecessors. For example, IE, which was introduced in March 2009, reached its market share peak in the month IE9 was introduced - at 30.24 percent. Since then, the browser has declined to only 22.17 percent and 57.52 percent of the IE user base still uses IE8 today.
With the silent updates becoming available for IE8 and IE9, Microsoft is likely to avoid another IE6 disaster with IE8. Even more important for Microsoft is that those users who update to IE9 may be less likely to switch to Chrome.
Tuesday, December 20. 2011
OwnCloud: An open-source cloud to call your own
Via ZDNet
-----

Everyone likes personal cloud services, like Apple’s iCloud, Google Music, and Dropbox. But, many of aren’t crazy about the fact that our files, music, and whatever are sitting on someone else’s servers without our control. That’s where ownCloud comes in.
OwnCloud is an open-source cloud program. You use it to set up your own cloud server for file-sharing, music-streaming, and calendar, contact, and bookmark sharing project. As a server program it’s not that easy to set up. OpenSUSE, with its Mirall installation program and desktop client makes it easier to set up your own personal ownCloud, but it’s still not a simple operation. That’s going to change.
According to ownCloud’s business crew, “OwnCloud offers the ease-of-use and cost effectiveness of Dropbox and box.net with a more secure, better managed offering that, because it’s open source, offers greater flexibility and no vendor lock in. This makes it perfect for business use. OwnCloud users can run file sync and share services on their own hardware and storage or use popular public hosting and storage offerings.” I’ve tried it myself and while setting it up is still mildly painful, once up ownCloud works well.
OwnCloud enables universal access to files through a Web browser or WebDAV. It also provides a platform to easily view and sync contacts, calendars and bookmarks across all devices and enables basic editing right on the Web. Programmers will be able to add features to it via its open application programming interface (API).
OwnCloud is going to become an easy to run and use personal, private cloud thanks to a new commercial company that’s going to take ownCloud from interesting open-source project to end-user friendly program. This new company will be headed by former SUSE/Novell executive Markus Rex. Rex, who I’ve known for years and is both a business and technology wizard, will serve as both CEO and CTO. Frank Karlitschek, founder of the ownCloud project, will be staying.
To make this happen, this popular–350,000 users-program’s commercial side is being funded by Boston-based General Catalyst, a high-tech. venture capital firm. In the past, General Catalyst has helped fund such companies as online travel company Kayak and online video platform leader Brightcove.
General Catalyst came on board, said John Simon, Managing Director at General Catalyst in a statement, because, “With the explosion of unstructured data in the enterprise and increasingly mobile (and insecure) ways to access it, many companies have been forced to lock down their data–sometimes forcing employees to find less than secure means of access, or, if security is too restrictive, risk having all that unavailable When we saw the ease-of-use, security and flexibility of ownCloud, we were sold.”
“In a cloud-oriented world, ownCloud is the only tool based on a ubiquitous open-source platform,” said Rex, in a statement. “This differentiator enables businesses complete, transparent, compliant control over their data and data storage costs, while also allowing employees simple and easy data access from anywhere.”
As a Linux geek, I already liked ownCloud. At the company releases
mass-market ownCloud products and service in 2012, I think many of you
are going to like it as well. I’m really looking forward to seeing where
this program goes from here.
Wednesday, November 16. 2011
Artist Prints Out 24 Hours of Flickr Uploads, Over One Million Photos
Via GeekOSystem
-----

A new installation at the Amsterdam Foam gallery by Erik Kessels takes a literal look at the digital deluge of photos online by printing out 24 hours worth of uploads to Flickr. The result is rooms filled with over 1,000,000 printed photos, piled up against the walls.
There’s a sense of waste and a maddening disorganization to it all, both of which are apparently intentional. According to Creative Review, Kessels said of his own project:
“We’re exposed to an overload of images nowadays,” says Kessels. “This glut is in large part the result of image-sharing sites like Flickr, networking sites like Facebook, and picture-based search engines. Their content mingles public and private, with the very personal being openly and un-selfconsciously displayed. By printing all the images uploaded in a 24-hour period, I visualise the feeling of drowning in representations of other peoples’ experiences.”
Humbling, and certainly thought provoking, Kessel’s work challenges the notion that everything can and should be shared, which has become fundamental to the modern web. Then again, perhaps it’s only wasteful and overwhelming when you print all the pictures and divorce them from their original context.



")
Tuesday, November 08. 2011
The Big Picture: True Machine Intelligence & Predictive Power
Quicksearch
Popular Entries
- The great Ars Android interface shootout (131491)
- Norton cyber crime study offers striking revenue loss statistics (102340)
- MeCam $49 flying camera concept follows you around, streams video to your phone (100502)
- The PC inside your phone: A guide to the system-on-a-chip (58677)
- Norton cyber crime study offers striking revenue loss statistics (58569)
Categories

Show tagged entries
Syndicate This Blog
Calendar
|
|
July '26 | |||||
| Mon | Tue | Wed | Thu | Fri | Sat | Sun |
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 | ||