If Facebook were a country, a conceit that founder Mark Zuckerberg has entertained in public, its 900 million members would make it the third largest in the world.
It would far outstrip any regime past or present in how intimately
it records the lives of its citizens. Private conversations, family
photos, and records of road trips, births, marriages, and deaths all
stream into the company's servers and lodge there. Facebook has
collected the most extensive data set ever assembled on human social
behavior. Some of your personal information is probably part of it.
And yet, even as Facebook has embedded itself into modern life, it
hasn't actually done that much with what it knows about us. Now that
the company has gone public, the pressure to develop new sources of
profit (see "The Facebook Fallacy")
is likely to force it to do more with its hoard of information. That
stash of data looms like an oversize shadow over what today is a modest
online advertising business, worrying privacy-conscious Web users (see "Few Privacy Regulations Inhibit Facebook")
and rivals such as Google. Everyone has a feeling that this
unprecedented resource will yield something big, but nobody knows quite
what.
Heading Facebook's effort to figure out what can be learned from all our data is Cameron Marlow,
a tall 35-year-old who until recently sat a few feet away from
Zuckerberg. The group Marlow runs has escaped the public attention that
dogs Facebook's founders and the more headline-grabbing features of its
business. Known internally as the Data Science Team, it is a kind of
Bell Labs for the social-networking age. The group has 12
researchers—but is expected to double in size this year. They apply
math, programming skills, and social science to mine our data for
insights that they hope will advance Facebook's business and social
science at large. Whereas other analysts at the company focus on
information related to specific online activities, Marlow's team can
swim in practically the entire ocean of personal data that Facebook
maintains. Of all the people at Facebook, perhaps even including the
company's leaders, these researchers have the best chance of discovering
what can really be learned when so much personal information is
compiled in one place.
Facebook has all this information because it has found ingenious
ways to collect data as people socialize. Users fill out profiles with
their age, gender, and e-mail address; some people also give additional
details, such as their relationship status and mobile-phone number. A
redesign last fall introduced profile pages in the form of time lines
that invite people to add historical information such as places they
have lived and worked. Messages and photos shared on the site are often
tagged with a precise location, and in the last two years Facebook has
begun to track activity elsewhere on the Internet, using an addictive
invention called the "Like" button.
It appears on apps and websites outside Facebook and allows people to
indicate with a click that they are interested in a brand, product, or
piece of digital content. Since last fall, Facebook has also been able
to collect data on users' online lives beyond its borders automatically:
in certain apps or websites, when users listen to a song or read a news
article, the information is passed along to Facebook, even if no one
clicks "Like." Within the feature's first five months, Facebook
catalogued more than five billion instances
of people listening to songs online. Combine that kind of information
with a map of the social connections Facebook's users make on the site,
and you have an incredibly rich record of their lives and interactions.
"This is the first time the world has seen this scale and quality
of data about human communication," Marlow says with a
characteristically serious gaze before breaking into a smile at the
thought of what he can do with the data. For one thing, Marlow is
confident that exploring this resource will revolutionize the scientific
understanding of why people behave as they do. His team can also help
Facebook influence our social behavior for its own benefit and that of
its advertisers. This work may even help Facebook invent entirely new
ways to make money.
Contagious Information
Marlow eschews the collegiate programmer style of Zuckerberg and
many others at Facebook, wearing a dress shirt with his jeans rather
than a hoodie or T-shirt. Meeting me shortly before the company's
initial public offering in May, in a conference room adorned with a
six-foot caricature of his boss's dog spray-painted on its glass wall,
he comes across more like a young professor than a student. He might
have become one had he not realized early in his career that Web
companies would yield the juiciest data about human interactions.
In 2001, undertaking a PhD at MIT's Media Lab, Marlow created a
site called Blogdex that automatically listed the most "contagious"
information spreading on weblogs. Although it was just a research
project, it soon became so popular that Marlow's servers crashed.
Launched just as blogs were exploding into the popular consciousness and
becoming so numerous that Web users felt overwhelmed with information,
it prefigured later aggregator sites such as Digg and Reddit. But Marlow
didn't build it just to help Web users track what was popular online.
Blogdex was intended as a scientific instrument to uncover the social
networks forming on the Web and study how they spread ideas. Marlow went
on to Yahoo's research labs to study online socializing for two years.
In 2007 he joined Facebook, which he considers the world's most powerful
instrument for studying human society. "For the first time," Marlow
says, "we have a microscope that not only lets us examine social
behavior at a very fine level that we've never been able to see before
but allows us to run experiments that millions of users are exposed to."
Marlow's team works with managers across Facebook to find patterns
that they might make use of. For instance, they study how a new feature
spreads among the social network's users. They have helped Facebook
identify users you may know but haven't "friended," and recognize those
you may want to designate mere "acquaintances" in order to make their
updates less prominent. Yet the group is an odd fit inside a company
where software engineers are rock stars who live by the mantra "Move
fast and break things." Lunch with the data team has the feel of a
grad-student gathering at a top school; the typical member of the group
joined fresh from a PhD or junior academic position and prefers to talk
about advancing social science than about Facebook as a product or
company. Several members of the team have training in sociology or
social psychology, while others began in computer science and started
using it to study human behavior. They are free to use some of their
time, and Facebook's data, to probe the basic patterns and motivations
of human behavior and to publish the results in academic journals—much
as Bell Labs researchers advanced both AT&T's technologies and the
study of fundamental physics.
It may seem strange that an eight-year-old company without a
proven business model bothers to support a team with such an academic
bent, but Marlow says it makes sense. "The biggest challenges Facebook
has to solve are the same challenges that social science has," he says.
Those challenges include understanding why some ideas or fashions spread
from a few individuals to become universal and others don't, or to what
extent a person's future actions are a product of past communication
with friends. Publishing results and collaborating with university
researchers will lead to findings that help Facebook improve its
products, he adds.
For one example of how Facebook can serve as a proxy for examining
society at large, consider a recent study of the notion that any person
on the globe is just six degrees of separation from any other. The
best-known real-world study, in 1967, involved a few hundred people
trying to send postcards to a particular Boston stockholder. Facebook's
version, conducted in collaboration with researchers from the University
of Milan, involved the entire social network as of May 2011, which
amounted to more than 10 percent of the world's population. Analyzing
the 69 billion friend connections among those 721 million people showed
that the world is smaller than we thought: four intermediary friends are
usually enough to introduce anyone to a random stranger. "When
considering another person in the world, a friend of your friend knows a
friend of their friend, on average," the technical paper pithily
concluded. That result may not extend to everyone on the planet, but
there's good reason to believe that it and other findings from the Data
Science Team are true to life outside Facebook. Last year the Pew
Research Center's Internet & American Life Project found that 93
percent of Facebook friends had met in person. One of Marlow's
researchers has developed a way to calculate a country's "gross national
happiness" from its Facebook activity by logging the occurrence of
words and phrases that signal positive or negative emotion. Gross
national happiness fluctuates in a way that suggests the measure is
accurate: it jumps during holidays and dips when popular public figures
die. After a major earthquake in Chile in February 2010, the country's
score plummeted and took many months to return to normal. That event
seemed to make the country as a whole more sympathetic when Japan
suffered its own big earthquake and subsequent tsunami in March 2011;
while Chile's gross national happiness dipped, the figure didn't waver
in any other countries tracked (Japan wasn't among them). Adam Kramer,
who created the index, says he intended it to show that Facebook's data
could provide cheap and accurate ways to track social trends—methods
that could be useful to economists and other researchers.
Other work published by the group has more obvious utility for
Facebook's basic strategy, which involves encouraging us to make the
site central to our lives and then using what it learns to sell ads. An early study
looked at what types of updates from friends encourage newcomers to the
network to add their own contributions. Right before Valentine's Day
this year a blog post from the Data Science Team
listed the songs most popular with people who had recently signaled on
Facebook that they had entered or left a relationship. It was a hint of
the type of correlation that could help Facebook make useful predictions
about users' behavior—knowledge that could help it make better guesses
about which ads you might be more or less open to at any given time.
Perhaps people who have just left a relationship might be interested in
an album of ballads, or perhaps no company should associate its brand
with the flood of emotion attending the death of a friend. The most
valuable online ads today are those displayed alongside certain Web
searches, because the searchers are expressing precisely what they want.
This is one reason why Google's revenue is 10 times Facebook's. But
Facebook might eventually be able to guess what people want or don't
want even before they realize it.
Recently the Data Science Team has begun to use its unique
position to experiment with the way Facebook works, tweaking the
site—the way scientists might prod an ant's nest—to see how users react.
Eytan Bakshy, who joined Facebook last year after collaborating with
Marlow as a PhD student at the University of Michigan, wanted to learn
whether our actions on Facebook are mainly influenced by those of our
close friends, who are likely to have similar tastes. That would shed
light on the theory that our Facebook friends create an "echo chamber"
that amplifies news and opinions we have already heard about. So he
messed with how Facebook operated for a quarter of a billion users. Over
a seven-week period, the 76 million links that those users shared with
each other were logged. Then, on 219 million randomly chosen occasions,
Facebook prevented someone from seeing a link shared by a friend. Hiding
links this way created a control group so that Bakshy could assess how
often people end up promoting the same links because they have similar
information sources and interests.
He found that our close friends strongly sway which information we
share, but overall their impact is dwarfed by the collective influence
of numerous more distant contacts—what sociologists call "weak ties." It
is our diverse collection of weak ties that most powerfully determines
what information we're exposed to.
That study provides strong evidence against the idea that social networking creates harmful "filter bubbles," to use activist Eli Pariser's
term for the effects of tuning the information we receive to match our
expectations. But the study also reveals the power Facebook has. "If
[Facebook's] News Feed is the thing that everyone sees and it controls
how information is disseminated, it's controlling how information is
revealed to society, and it's something we need to pay very close
attention to," Marlow says. He points out that his team helps Facebook
understand what it is doing to society and publishes its findings to fulfill a public duty to transparency. Another recent study,
which investigated which types of Facebook activity cause people to
feel a greater sense of support from their friends, falls into the same
category.
But Marlow speaks as an employee of a company that will prosper
largely by catering to advertisers who want to control the flow of
information between its users. And indeed, Bakshy is working with
managers outside the Data Science Team to extract advertising-related
findings from the results of experiments on social influence.
"Advertisers and brands are a part of this network as well, so giving
them some insight into how people are sharing the content they are
producing is a very core part of the business model," says Marlow.
Facebook told prospective investors before its IPO that people
are 50 percent more likely to remember ads on the site if they're
visibly endorsed by a friend. Figuring out how influence works could
make ads even more memorable or help Facebook find ways to induce more
people to share or click on its ads.
Social Engineering
Marlow says his team wants to divine the rules of online social
life to understand what's going on inside Facebook, not to develop ways
to manipulate it. "Our goal is not to change the pattern of
communication in society," he says. "Our goal is to understand it so we
can adapt our platform to give people the experience that they want."
But some of his team's work and the attitudes of Facebook's leaders show
that the company is not above using its platform to tweak users'
behavior. Unlike academic social scientists, Facebook's employees have a
short path from an idea to an experiment on hundreds of millions of
people.
In April, influenced in part by conversations over dinner with his
med-student girlfriend (now his wife), Zuckerberg decided that he
should use social influence within Facebook to increase organ donor
registrations. Users were given an opportunity to click a box on their
Timeline pages to signal that they were registered donors, which
triggered a notification to their friends. The new feature started a
cascade of social pressure, and organ donor enrollment increased by a
factor of 23 across 44 states.
Marlow's team is in the process of publishing results from the
last U.S. midterm election that show another striking example of
Facebook's potential to direct its users' influence on one another.
Since 2008, the company has offered a way for users to signal that they
have voted; Facebook promotes that to their friends with a note to say
that they should be sure to vote, too. Marlow says that in the 2010
election his group matched voter registration logs with the data to see
which of the Facebook users who got nudges actually went to the polls.
(He stresses that the researchers worked with cryptographically
"anonymized" data and could not match specific users with their voting
records.)
This is just the beginning. By learning more about how small changes
on Facebook can alter users' behavior outside the site, the company
eventually "could allow others to make use of Facebook in the same way,"
says Marlow. If the American Heart Association wanted to encourage
healthy eating, for example, it might be able to refer to a playbook of
Facebook social engineering. "We want to be a platform that others can
use to initiate change," he says.
Advertisers, too, would be eager to know in greater detail what
could make a campaign on Facebook affect people's actions in the outside
world, even though they realize there are limits to how firmly human
beings can be steered. "It's not clear to me that social science will
ever be an engineering science in a way that building bridges is," says
Duncan Watts, who works on computational social science at Microsoft's
recently opened New York research lab and previously worked alongside
Marlow at Yahoo's labs. "Nevertheless, if you have enough data, you can
make predictions that are better than simply random guessing, and that's
really lucrative."
Doubling Data
Like other social-Web companies, such as Twitter, Facebook has
never attained the reputation for technical innovation enjoyed by such
Internet pioneers as Google. If Silicon Valley were a high school, the
search company would be the quiet math genius who didn't excel socially
but invented something indispensable. Facebook would be the annoying kid
who started a club with such social momentum that people had to join
whether they wanted to or not. In reality, Facebook employs hordes of
talented software engineers (many poached from Google and other
math-genius companies) to build and maintain its irresistible club. The
technology built to support the Data Science Team's efforts is
particularly innovative. The scale at which Facebook operates has led it
to invent hardware and software that are the envy of other companies
trying to adapt to the world of "big data."
In a kind of passing of the technological baton, Facebook built
its data storage system by expanding the power of open-source software
called Hadoop, which was inspired by work at Google and built at Yahoo.
Hadoop can tame seemingly impossible computational tasks—like working on
all the data Facebook's users have entrusted to it—by spreading them
across many machines inside a data center. But Hadoop wasn't built with
data science in mind, and using it for that purpose requires
specialized, unwieldy programming. Facebook's engineers solved that
problem with the invention of Hive, open-source software that's now
independent of Facebook and used by many other companies. Hive acts as a
translation service, making it possible to query vast Hadoop data
stores using relatively simple code. To cut down on computational
demands, it can request random samples of an entire data set, a feature
that's invaluable for companies swamped by data. Much of Facebook's data
resides in one Hadoop store more than 100 petabytes (a million
gigabytes) in size, says Sameet Agarwal, a director of engineering at
Facebook who works on data infrastructure, and the quantity is growing
exponentially. "Over the last few years we have more than doubled in
size every year," he says. That means his team must constantly build
more efficient systems.
All this has given Facebook a unique level of expertise, says Jeff Hammerbacher,
Marlow's predecessor at Facebook, who initiated the company's effort to
develop its own data storage and analysis technology. (He left Facebook
in 2008 to found Cloudera, which develops Hadoop-based systems to
manage large collections of data.) Most large businesses have paid
established software companies such as Oracle a lot of money for data
analysis and storage. But now, big companies are trying to understand
how Facebook handles its enormous information trove on open-source
systems, says Hammerbacher. "I recently spent the day at Fidelity
helping them understand how the 'data scientist' role at Facebook was
conceived ... and I've had the same discussion at countless other
firms," he says.
As executives in every industry try to exploit the opportunities
in "big data," the intense interest in Facebook's data technology
suggests that its ad business may be just an offshoot of something much
more valuable. The tools and techniques the company has developed to
handle large volumes of information could become a product in their own
right.
Mining for Gold
Facebook needs new sources of income to meet investors'
expectations. Even after its disappointing IPO, it has a staggeringly
high price-to-earnings ratio that can't be justified by the barrage of
cheap ads the site now displays. Facebook's new campus in Menlo Park,
California, previously inhabited by Sun Microsystems, makes that
pressure tangible. The company's 3,500 employees rattle around in enough
space for 6,600. I walked past expanses of empty desks in one building;
another, next door, was completely uninhabited. A vacant lot waited
nearby, presumably until someone invents a use of our data that will
justify the expense of developing the space.
One potential use would be simply to sell insights mined from the information. DJ Patil,
data scientist in residence with the venture capital firm Greylock
Partners and previously leader of LinkedIn's data science team, believes
Facebook could take inspiration from Gil Elbaz, the inventor of
Google's AdSense ad business, which provides over a quarter of Google's
revenue. He has moved on from advertising and now runs a fast-growing
startup, Factual,
that charges businesses to access large, carefully curated collections
of data ranging from restaurant locations to celebrity body-mass
indexes, which the company collects from free public sources and by
buying private data sets. Factual cleans up data and makes the result
available over the Internet as an on-demand knowledge store to be tapped
by software, not humans. Customers use it to fill in the gaps in their
own data and make smarter apps or services; for example, Facebook itself
uses Factual for information about business locations. Patil points out
that Facebook could become a data source in its own right, selling
access to information compiled from the actions of its users. Such
information, he says, could be the basis for almost any kind of
business, such as online dating or charts of popular music. Assuming
Facebook can take this step without upsetting users and regulators, it
could be lucrative. An online store wishing to target its promotions,
for example, could pay to use Facebook as a source of knowledge about
which brands are most popular in which places, or how the popularity of
certain products changes through the year.
Hammerbacher agrees that Facebook could sell its data science and
points to its currently free Insights service for advertisers and
website owners, which shows how their content is being shared on
Facebook. That could become much more useful to businesses if Facebook
added data obtained when its "Like" button tracks activity all over the
Web, or demographic data or information about what people read on the
site. There's precedent for offering such analytics for a fee: at the
end of 2011 Google started charging $150,000 annually for a premium
version of a service that analyzes a business's Web traffic.
Back at Facebook, Marlow isn't the one who makes decisions about
what the company charges for, even if his work will shape them. Whatever
happens, he says, the primary goal of his team is to support the
well-being of the people who provide Facebook with their data, using it
to make the service sm
Of all the noises that my children will not understand, the one that is
nearest to my heart is not from a song or a television show or a jingle.
It's the sound of a modem connecting with another modem across the
repurposed telephone infrastructure. It was the noise of being part of
the beginning of the Internet.
I heard that sound again this week on Brendan Chillcut's simple and wondrous site: The Museum of Endangered Sounds.
It takes technological objects and lets you relive the noises they
made: Tetris, the Windows 95 startup chime, that Nokia ringtone,
television static. The site archives not just the intentional sounds --
ringtones, etc -- but the incidental ones, like the mechanical noise a
VHS tape made when it entered the VCR or the way a portable CD player
sounded when it skipped. If you grew up at a certain time, these sounds
are like technoaural nostalgia whippets. One minute, you're browsing the
Internet in 2012, the next you're on a bus headed up I-5 to an 8th
grade football game against Castle Rock in 1995.
The noises our technologies make, as much as any music, are the soundtrack to an era. Soundscapes
are not static; completely new sets of frequencies arrive, old things
go. Locomotives rumbled their way through the landscapes of 19th century
New England, interrupting Nathaniel Hawthorne-types' reveries in Sleepy
Hollows. A city used to be synonymous with the sound of horse hooves
and the clatter of carriages on the stone streets. Imagine the people
who first heard the clicks of a bike wheel or the vroom of a car engine.
It's no accident that early films featuring industrial work often
include shots of steam whistles, even though in many (say, Metropolis)
we can't hear that whistle.
When I think of 2012, I will think of the overworked fan of my laptop
and the ding of getting a text message on my iPhone. I will think of
the beep of the FastTrak in my car as it debits my credit card so I can
pass through a toll onto the Golden Gate Bridge. I will think of Siri's
uncanny valley voice.
But to me, all of those sounds -- as symbols of the era in which I've
come up -- remain secondary to the hissing and crackling of the modem
handshake. I first heard that sound as a nine-year-old. To this day, I
can't remember how I figured out how to dial the modem of our old
Zenith. Even more mysterious is how I found the BBS number to call or
even knew what a BBS was. But I did. BBS were dial-in communities, kind
of like a local AOL.
You could post messages and play games, even chat with people on the
bigger BBSs. It was personal: sometimes, you'd be the only person
connected to that community. Other times, there'd be one other person,
who was almost definitely within your local prefix.
When we moved to Ridgefield, which sits outside Portland, Oregon, I had a summer with no
friends and no school: The telephone wire became a lifeline. I
discovered Country Computing, a BBS I've eulogized before,
located in a town a few miles from mine. The rural Washington BBS world
was weird and fun, filled with old ham-radio operators and
computer nerds. After my parents' closed up
shop for the work day, their "fax line" became my modem line, and I
called across the I-5 to play games and then, slowly, to participate in
the
nascent community.
In the beginning of those sessions, there was the sound, and the sound was data.
Fascinatingly, there's no good guide to the what the beeps and hisses
represent that I could find on the Internet. For one, few people care
about the technical details of 1997's hottest 56k modems. And for
another, whatever good information exists out there predates the popular
explosion of the web and the all-knowing Google.
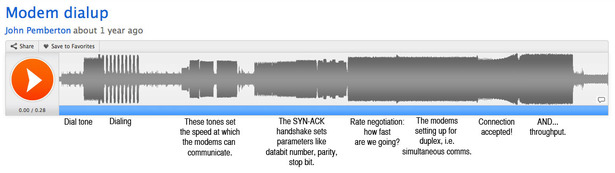
So, I asked on Twitter and was rewarded with an accessible and elegant explanation from another user whose nom-de-plume is Miso Susanowa.
(Susanowa used to run a BBS.) I transformed it into the annotated
graphic below, which explains the modem sound part-by-part. (You can
click it to make it bigger.)
This is a choreographed sequence that allowed these digital devices to
piggyback on an analog telephone network. "A phone line carries only the small range of frequencies in
which most human conversation takes place: about 300 to 3,300 hertz," Glenn Fleishman explained in the Times back in 1998. "The
modem works within these limits in creating sound waves to carry data
across phone lines." What you're hearing is the way 20th century technology tunneled through a 19th century network;
what you're hearing is how a network designed to send the noises made
by your muscles as they pushed around air came to transmit anything, or
the almost-anything that can be coded in 0s and 1s.
The frequencies of the modem's sounds represent
parameters for further communication. In the early going, for example,
the modem that's been dialed up will play a note that says, "I can go
this fast." As a wonderful old 1997 website explained, "Depending on the speed the modem is trying to talk at, this tone will have a
different pitch."
That is to say, the sounds weren't a sign that data was being
transferred: they were the data being transferred. This noise was the
analog world being bridged by the digital. If you are old enough to
remember it, you still knew a world that was analog-first.
Long before I actually had this answer in hand, I could sense that the
patterns of the beats and noise meant something. The sound would move
me, my head nodding to the beeps that followed the initial connection.
You could feel two things trying to come into sync: Were they computers
or me and my version of the world?
As I learned again today, as I learn every day, the answer is both.
Microsoft has let it be known that their final release of the Internet Explorer 10
web browser software will have “Do Not Track” activated right out of
the box. This information has upset advertisers across the board as web
ad targeting – based on your online activities – is one of the current
mainstays of big-time advertiser profits. What Do Not Track, or DNT does
is to send out signal from your web browser, Internet Explorer 10 in
this case, to websites letting them know that the user refuses to be
seen in such a way.
A very similar Do Not Track feature currently exists on Mozilla’s Firefox browser
and is swiftly becoming ubiquitous around the web as a must-have
feature for web privacy. This will very likely bring about a large
change in the world of online advertising specifically as, again,
advertisers rely on invisible tracking methods so heavily. Tracking in
place today also exists on sites such as Google where your search
history will inform Google on what you’d like to see for search results, News posts, and advertisement content.
The Digital Advertising Aliance, or DAA, has countered Microsoft’s
announcement saying that the IE10 browser release would oppose
Microsoft’s agreement with the White House earlier this year. This
agreement had the DAA agreeing to recognize and obey the Do Not Track
signals from IE10 just so long as the option to have DNT activated was
not turned on by default. Microsoft Chief Privacy Officer Brendan Lynch
spoke up this week on the situation this week as well.
“In a world where consumers live a large part of their
lives online, it is critical that we build trust that their personal
information will be treated with respect, and that they will be given a
choice to have their information used for unexpected purposes.
While there is still work to do in agreeing on an industry-wide
definition of DNT, we believe turning on Do Not Track by default in IE10
on Windows 8 is an important step in this process of establishing
privacy by default, putting consumers in control and building trust
online.” – Lynch
Last September, during the f8 Developers’ Conference, Facebook CTO Bret Taylor said that the company had no plans for a “central app repository” – an app store. Today, Facebook is changing its tune. The social giant has announced App Center,
a section of Facebook dedicated to discovering and deploying
high-quality apps on the company’s platform. The App Center will push
apps to iPhone, Android and the mobile Web, giving Facebook its first
true store for mobile app discovery.
The departure from Facebook’s previous company line
comes as the social platform ramps up its mobile offerings to make money
from its hundreds of millions of mobile users. This is not your
father's app store, though.
Let's start with the requirements. Facebook has announced a strict
set of style and quality guidelines to get apps placed in App
Center. Apps that are considered high-quality, as decided by Facebook’s
Insights analytics platform, will get prominent placement. Quality is
determined by user ratings and app engagement. Apps that receive poor
ratings or do not meet Facebook’s quality guidelines won't be listed.
Whether or not an app is a potential Facebook App Center candidate hinges on several factors. It must
• have a canvas page (a page that sets the app's permissions on Facebook’s platform)
• be built for iOS, Android or the mobile Web
• use a Facebook Login or be a website that uses a Facebook Login.
Facebook is in a tricky spot with App Center. It will house not only
apps that are specifically run through its platform but also iOS and
Android apps. Thus it needs to achieve a balance between competition and
cooperation with some of the most powerful forces in the tech universe.
If an app in App Center requires a download, the download link on the
app’s detail page will bring the user to the appropriate app repository,
either Apple's App Store or Android’s Google Play.
One of the more interesting parts of App Center is that Facebook will
allow paid apps. This is a huge move for Facebook as it provides a
boost to its Credits payment service. One of the benefits of having a
store is that whoever controls the store also controls transactions
arising from the items in it, whether payments per download or in-app
purchases. This will go a long way towards Facebook’s goal of monetizing
its mobile presence without relying on advertising.
Facebook App Center Icon Guidelines
Developers interested in publishing apps to Facebook’s App Center should take a look at both the guidelines and the tutorial
that outlines how to upload the appropriate icons, how to request
permissions, how to use Single Sign On (SSO, a requirement for App
Center) and the app detail page.
This is a good move for Facebook. It will give the company several
avenues to start making money off of mobile but also strengthen its
position as one of the backbones of the Web. For instance, App Center is
both separate from iOS and Android but also a part of it. Through App
Center, Facebook can direct traffic to its apps, monitor who and how
users are downloading applications and keep itself at the center of the
user experience.
The cloud storage scene has heated up recently, with a long-awaited
entry by Google and a revamped SkyDrive from Microsoft. Dropbox has gone
unchallenged by the major players for a long time, but that’s changed –
both Google and Microsoft are now challenging Dropbox on its own turf,
and all three services have their own compelling features. One thing’s
for sure – Dropbox is no longer the one-size-fits-all solution.
These three aren’t the only cloud storage services – the cloud
storage arena is full of services with different features and
priorities, including privacy-protecting encryption and the ability to
synchronize any folder on your system.
Dropbox
introduced cloud storage to the masses, with its simple approach to
cloud storage and synchronization – a single magic folder that follows
you everywhere. Dropbox deserves credit for being a pioneer in this
space and the new Google Drive and SkyDrive both build on the foundation
that Dropbox laid.
Dropbox doesn’t have strong integration with any ecosystems – which
can be a good thing, as it is an ecosystem-agnostic approach that isn’t
tied to Google, Microsoft, Apple, or any other company’s platform.
Dropbox today is a compelling and mature offering supporting a wide
variety of platforms. Dropbox offers less free storage than the other
services (unless you get involved in their referral scheme) and its
prices are significantly higher than those of competing services – for
example, an extra 100GB is four times more expensive with Dropbox compared to Google Drive.
Price for Additional Storage: 50 GB for $10/month, 100 GB for $20/month.
File Size Limit: Unlimited.
Standout Features: the Public folder is an easy way to share files.
Other services allow you to share files, but it isn’t quite as easy.
You can sync files from other computers running Dropbox over the local
network, speeding up transfers and taking a load off your Internet
connection.
Google Drive is the evolution of Google Docs,
which already allowed you to upload any file – Google Drive bumps the
storage space up from 1 GB to 5 GB, offers desktop sync clients, and
provides a new web interface and APIs for web app developers.
Google Drive is a serious entry from Google, not just an afterthought like the upload-any-file option was in Google Docs.
Its integration with third-party web apps – you can install apps and
associate them with file types in Google Drive – shows Google’s vision
of Google Drive being a web-based hard drive that eventually replaces
the need for desktop sync clients entirely.
Like Google with Google Drive, Microsoft’s new SkyDrive product imitates the magic folder pioneered by Dropbox.
Microsoft offers the most free storage space at 7 GB – although this is down from the original 25 GB. Microsoft also offers good prices for additional storage.
Supported Platforms: Windows, Mac, Windows Phone, iOS, Web.
Free Storage: 7 GB.
Price for Additional Storage: 20 GB for $10/year, 50 GB for $25/year, 100 GB for $50/year
File Size Limit: 2 GB
Standout Features: Ability to fetch unsynced files from outside the synced folders on connected PCs, if they’ve been left on.
Other Services
SugarSync is a popular
alternative to Dropbox. It offers a free 5 GB of storage and it lets you
choose the folders you want to synchronize – a feature missing in the
above services, although you can use some tricks
to synchronize other folders. SugarSync also has clients for mobile
platforms that don’t get a lot of love, including Symbian, Windows
Mobile, and Blackberry (Dropbox also has a Blackberry client).
Amazon also offers their own cloud storage service, known as Amazon Cloud Drive.
There’s one big problem, though – there’s no official desktop sync
client. Expect Amazon to launch their own desktop sync program if
they’re serious about competing in this space. If you really want to use Amazon Cloud Drive, you can use a third-party application to access it from your desktop.
Box is popular, but its 25 MB file
size limit is extremely low. It also offers no desktop sync client
(except for businesses). While Box may be a good fit for the enterprise,
it can’t stand toe-to-toe with the other services here for consumer
cloud storage and syncing.
If you’re worried about the privacy of your data, you can use an encrypted service, such as SpiderOak or Wuala, instead. Or, if you prefer one of these services, use an app like BoxCryptor to encrypt files and store them on any cloud storage service.
It doesn't get much more futuristic than "universal quantum network,"
but we're going to have to find something else to pine over, since a
UQN now exists. A group from the Max Planck Institute of Quantum Optics
has tied the quantum states of two atoms together using photons, creating the first network of qubits.
A quantum network is just like a regular network, the one that you're
almost certainly connected to at this very moment. The only difference
is that each node in the network is just a single atom (rubidium atoms,
as it happens), and those atoms are connected by photons. For the first
time ever, scientists have managed to get these individual atoms to read
a qubit off of a photon, store that qubit, and then write it out onto
another photon and send it off to another atom, creating a fully
functional quantum network that has the potential to be expanded to
however many atoms we want.
How Quantum Networking Works
You remember the deal with the quantum states of atoms, right? You
know, how you can use quantum spin to represent the binary states of
zero or one or both or neither all at the same time? Yeah, don't worry,
when it comes down to it it's not something that anyone really
understands. You just sort of have to accept that that's the way it is,
and that quantum bits (qubits) are rather weird.
So, okay, this quantum weirdness comes in handy when you want to create a very specific sort of computer,
but what's the point of a quantum network? Well, if you're the paranoid
sort, you're probably aware that when you send data from one place to
another in a traditional network, those data can be intercepted en route and read by some nefarious person with nothing better to do with their time.
The cool bit about a quantum network is that it offers a way
to keep a data transmission perfectly secure. To explain why this is
the case, let's first go over how the network functions. Basically,
you've got one single atom on one end, and other single atom on the
other end, and these two atoms are connected with a length of optical
fiber through which single photons can travel. If you get a bunch of
very clever people with a bunch of very expensive equipment together in a
room with one of those atoms, you can get that atom to emit a photon
that travels down the optical fiber containing the quantum signature of
the atom that it was emitted from. And when that photon runs smack into
the second atom, it imprints it with the quantum information from the first atom, entangling the two.
When two atoms are entangled like this, it means that you can measure
the quantum state of one of them, and even though the result of your
measurement will be random, you can be 100% certain that the quantum
state of the other one will match it. Why and how does this work? Nobody
has any idea. Seriously. But it definitely does, because we can do it.
Quantum Lockdown
Now, let's get back to this whole secure network thing. You've got a
pair of entangled atoms that you can measure, and you'll get back a
random state (a one or a zero) that you know will be the same for both
atoms. You can measure them over and over, getting a new random state
each time you do, and gradually you and the person measuring the other
atom will be able to build up a long string of totally random (but
totally identical) ones and zeros. This is your quantum key.
There are three things that make a quantum key so secure. Thing one
is that the single photon that transmits the entanglement itself cannot
be messed with, since messing with it screws up the quantum signature of
the atom that it originally came from. Thing two is that while you're
measuring your random ones and zeroes, if anyone tries to peek in and
measure your atom at the same time (to figure out your key), you'll be
able to tell. And thing three is that you don't have to send the key
itself back and forth, since you're relying on entangled atoms that
totally ignore conventional rules of space and time.*
Hooray, you've got a super-secure quantum key! To use it, you turn it
into what's called a one-time pad, which is a very old fashioned and
very simple but theoretically 100% secure way to encrypt something. A
one-time pad is just a completely random string of ones and zeros.
That's it, and you've got one of those in the form of your quantum key.
Using binary arithmetic, you add that perfectly random string of data to
the data that make up your decidedly non-random message, ending up with
a new batch of data that looks completely random. You can send
that message through any non-secure network you like, and nobody will
ever be able to break it. Ever.
When your recipient (the dude with the other entangled atom and an
identical quantum key) gets your message, all they have to do is do that
binary arithmetic backwards, subtracting the quantum key from the
encrypted message, and that's it. Message decoded!
The reason this system is so appealing is that theoretically, there are zero
weak points in the information chain. Theoretically (and we really do
have to stress that "theoretically"), an entangled quantum network
offers a way to send information back and forth with 100% confidence
that nobody will be able to spy on you. We don't have this capability
yet, but with this first operational entangled quantum network, we're
getting closer, in that all of the pieces of the puzzle do seem to
exist.
*If you're wondering why we can't use entanglement to transmit
information faster than the speed of light, it's because entangled atoms
only share their randomness. You can be sure that measuring one of them
will result in the same measurement on the other one no matter how far
away it is, but we have no control over what that measurement will be.
When the Internet was created, decades ago, one thing was inevitable:
the war today over how (or whether) to control it, and who should have
that power. Battle lines have been drawn between repressive regimes and
Western democracies, corporations and customers, hackers and law
enforcement. Looking toward a year-end negotiation in Dubai, where 193
nations will gather to revise a U.N. treaty concerning the Internet,
Michael Joseph Gross lays out the stakes in a conflict that could split
the virtual world as we know it.
It's nice to imagine the cloud as an idyllic server room—with faux
grass, no less!—but there's actually far more going on than you'd think.
Maybe you're a Dropbox devotee. Or perhaps you really like streaming Sherlock on Netflix. For that, you can thank the cloud.
In fact, it's safe to say that Amazon Web Services (AWS)
has become synonymous with cloud computing; it's the platform on which
some of the Internet's most popular sites and services are built. But
just as cloud computing is used as a simplistic catchall term for a
variety of online services, the same can be said for AWS—there's a lot
more going on behind the scenes than you might think.
If you've ever wanted to drop terms like EC2 and S3 into casual
conversation (and really, who doesn't?) we're going to demystify the
most important parts of AWS and show you how Amazon's cloud really
works.
Elastic Cloud Compute (EC2)
Think of EC2 as the computational brain behind an online application
or service. EC2 is made up of myriad instances, which is really just
Amazon's way of saying virtual machines. Each server can run multiple
instances at a time, in either Linux or Windows configurations, and
developers can harness multiple instances—hundreds, even thousands—to
handle computational tasks of varying degrees. This is what the elastic
in Elastic Cloud Compute refers to; EC2 will scale based on a user's
unique needs.
Instances can be configured as either Windows machines, or with
various flavors of Linux. Again, each instance comes in different sizes,
depending on a developer's needs. Micro instances, for example, only
come with 613 MB of RAM, while Extra Large instances can go up to 15GB.
There are also other configurations for various CPU or GPU processing
needs.
Finally, EC2 instances can be deployed across multiple regions—which
is really just a fancy way of referring to the geographic location of
Amazon's data centers. Multiple instances can be deployed within the
same region (on separate blocks of infrastructure called availability
zones, such as US East-1, US East-2, etc.), or across more than one
region if increased redundancy and reduced latency is desired
Elastic Load Balance (ELB)
Another reason why a developer might deploy EC2 instances across
multiple availability zones and regions is for the purpose of load
balancing. Netflix, for example,
uses a number of EC2 instances across multiple geographic location. If
there was a problem with Amazon's US East center, for example, users
would hopefully be able to connect to Netflix via the service's US West
instances instead.
But what if there is no problem, and a higher number of users are
connecting via instances on the East Coast than on the West? Or what if
something goes wrong with a particular instance in a given availability
zone? Amazon's Elastic Load Balance allows developers to create multiple
EC2 instances and set rules that allow traffic to be distributed
between them. That way, no one instance is needlessly burdened while
others idle—and when combined with the ability for EC2 to scale, more
instances can also be added for balance where required.
Elastic Block Storage (EBS)
Think of EBS as a hard drive in your computer—it's where an EC2
instance stores persistent files and applications that can be accessed
again over time. An EBS volume can only be attached to one EC2 instance
at a time, but multiple volumes can be attached to the same instance. An
EBS volume can range from 1GB to 1TB in size, but must be located in
the same availability zone as the instance you'd like to attach to.
Because EC2 instances by default don't include a great deal of local
storage, it's possible to boot from an EBS volume instead. That way,
when you shut down an EC2 instance and want to re-launch it at a later
date, it's not just files and application data that persist, but the
operating system itself.
Simple Storage Service (S3)
Unlike EBS volumes, which are used to store operating system and
application data for use with an EC2 instance, Amazon's Simple Storage
Service is where publicly facing data is usually stored instead. In
other words, when you upload a new profile picture to Twitter, it's not
being stored on an EBS volume, but with S3.
S3 is often used for static content, such as videos, images or music,
though virtually anything can be uploaded and stored. Files uploaded to
S3 are referred to as objects, which are then stored in buckets. As
with EC2, S3 storage is scalable, which means that the only limit on
storage is the amount of money you have to pay for it.
Buckets are also stored in regions, and within that region “are redundantly stored on multiple devices across multiple facilities.”
However, this can cause latency issues if a user in Europe is trying to
access files stored in a bucket within the US West region, for example.
As a result, Amazon also offers a service called CloudFront, which
allows objects to be mirrored across other regions.
While these are the core features that make up Amazon Web Services,
this is far from a comprehensive list. For example, on the AWS landing
page alone, you'll find things such as DynamoDB, Route53, Elastic
Beanstalk, and other features that would take much longer to detail
here.
However, if you've ever been confused about how the basics of AWS
work—specifically, how computational data and storage is provisioned and
scaled—we hope this gives you a better sense of how Amazon's brand of
cloud works.
Correction: Initially, we confused regions in AWS with
availability zones. As Mhj.work explains in the comments of this
article, "availability Zones are actually "discrete" blocks of
infrastructure ... at a single geographical location, whereas the
geographical units are called Regions. So for example, EU-West is the
Region, whilst EU-West-1, EU-West-2, and EU-West-3 are Availability
Zones in that Region." We have updated the text to make this point
clearer.
Business travelers -- and the enterprises that foot their phone bills -- have been complaining about high roaming fees in Europe for years. Now, some relief is finally in sight.
Indeed, both data roaming and phone calls travelers make while doing business (or taking a vacation) in Europe should be much cheaper this summer
thanks to a deal done in the European Parliament this week.
Members of the European Parliament and the Danish Presidency of the
Council of Ministers agreed to lower price caps on roaming. Parliament
as a whole still needs to approve the deal. But if all runs smoothly the
new rules will take effect July 1.
"I am satisfied that the Council approved Parliament's approach to
tackle very high prices of phone calls, SMS and in particular of data
roaming," said Angelika Niebler of Germany, Parliament's reporter for
the draft legislation. "The proposed price caps ensure a sufficient
margin between wholesale and retail prices to assure a level of
competition that will enable new players to enter the market."
How Low Do They Go?
The agreement increases transparency and consumer protection to prevent
bill shocks, Niebler said. That means European Union consumers no longer
need to worry about accidentally running up huge bills when using their
mobile devices both within and outside the EU. Of course, it's also a boon for consumers from other nations traveling to Europe.
How much savings are we talking about? According to the new rules, a
downloaded megabyte would cost no more than 70 cents. That cost drops
down to 45 cents in 2013 and 20 cents by July 2014. This is a big
improvement, seeing as there is currently no price ceiling for mobile
data services charged to consumers.
On the phone call front, the cost of a one-minute call would not exceed
29 cents under the new rules. That declines to 19 cents as of July 2014.
That's down from 35 cents under the current legislation. Finally, an
SMS would cost no more than 9 cents. That drops to 6 cents as by July
2014 and marks an 11 percent cut from current costs.
Nixing Roaming Altogether
"Mobile roaming charges in the EU are artificially high. Given the fact
that they are trying to treat the entire continent like a single
country, I don't understand why mobile roaming charges are so high
between countries," said Mike Disabato, managing vice president of network and telecom at Gartner.
Practically speaking, the new rules mean that you only need one SIM card
while traveling in Europe. Of course, you can't get a SIM card on an
iPhone unless you buy an unlocked phone for $800. But if you do use a
SIM card you will not have to change phone numbers every time you go to a
different country.
"The new rules will make it a lot cheaper for people who actually have
to do business in Europe. Any time you start reducing these types of
rates it's a good thing," Disabato said. "We got rid of roaming charges a
long time ago. It's about time they go in Europe. It will take until
the EU decides they are going to make it happen."
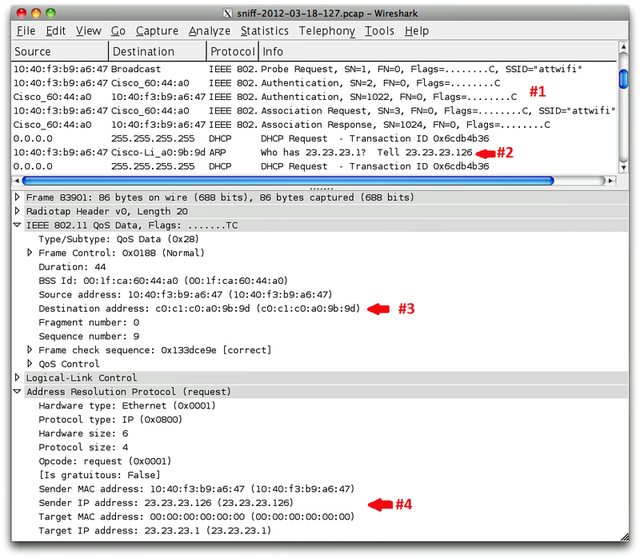
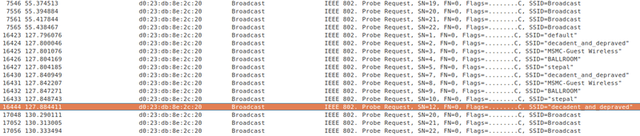
This
screen capture of a Wireshark session initiated by hacker Rob Graham
shows his iPad 3 exposing the MAC address of his home router. The unique
identifier could be viewed by anyone connected to the Starbucks hotspot
he accessed.
An Ars story from earlier this month reported that iPhones expose the unique identifiers of recently accessed wireless routers,
which generated no shortage of reader outrage. What possible
justification does Apple have for building this leakage capability into
its entire line of wireless products when smartphones, laptops, and
tablets from competitors don't? And how is it that Google, Wigle.net,
and others get away with publishing the MAC addresses of millions of
wireless access devices and their precise geographic location?
Some readers wanted more technical detail about the exposure, which
applies to three access points the devices have most recently connected
to. Some went as far as to challenge the validity of security researcher
Mark Wuergler's findings. "Until I see the code running or at least a
youtube I don't believe this guy has the goods," one Ars commenter wrote.
According to penetration tester Robert Graham, the findings are legit.
In the service of our readers, and to demonstrate to skeptics that
the privacy leak is real, Ars approached Graham and asked him to review
the article for accuracy and independently confirm or debunk Wuergler's
findings.
"I can confirm all the technical details of this 'hack,'" Graham, who
is CEO of Errata Security, told Ars via e-mail. "Apple products do
indeed send out three packets that will reveal your home router MAC
address. I confirmed this with my latest iPad 3."
He provided the image at the top of this post as proof. It shows a
screen from Wireshark, a popular packet-sniffing program, as his iPad
connected to a public hotspot at a Starbucks in Atlanta. Milliseconds
after it connected to an SSID named "attwifi" (as shown in the section
labeled #1), the iPad broadcasted the MAC address of his Linksys home
router (shown in the section labeled #2). In section #3, the iPad sent
the MAC address of this router a second time, and curiously, the
identifier was routed to this access point even though it's not
available on the local network. As is clear in section #4, the iPad also
exposed the local IP address the iPad used when accessing Graham's home
router. All of this information is relatively simple to view by anyone
within radio range.
The image is consistent with one provided by Wuergler below. Just as
Wuergler first claimed, it shows an iPhone disclosing the last three
access points it has connected to.
Mark Wuergler, Immunity Inc.
Graham used Wireshark to monitor the same Starbucks hotspot when he
connected with his Windows 7 laptop and Android-based Kindle Fire.
Neither device exposed any previously connected MAC addresses. He also
reviewed hundreds of other non-Apple devices as they connected to the
network, and none of them exposed previously accessed addresses, either.
As the data makes clear, the MAC addresses were exposed in ARP (address resolution protocol)
packets immediately after Graham's iPad associated with the access
point but prior to it receiving an IP address from the router's DHCP
server. Both Graham and Wuergler speculate that Apple engineers
intentionally built this behavior into their products as a way of
speeding up the process of reconnecting to access points, particularly
those in corporate environments. Rather than waiting for a DHCP server
to issue an IP address, the exposure of the MAC addresses allows the
devices to use the same address it was assigned last time.
"This whole thing is related to DHCP and autoconfiguration (for speed
and less traffic on the wire)," Wuergler told Ars. "The Apple devices
want to determine if they are on a network that they have previously
connected to and they send unicast ARPs out on the network in order to
do this."
Indeed, strikingly similar behavior was described in RFC 4436,
a 2006 technical memo co-written by developers from Apple, Microsoft,
and Sun Microsystems. It discusses a method for detecting network
attachment in IPv4-based systems.
"In this case, the host may determine whether it has re-attached to
the logical link where this address is valid for use, by sending a
unicast ARP Request packet to a router previously known for that link
(or, in the case of a link with more than one router, by sending one or
more unicast ARP Request packets to one or more of those routers)," the
document states at one point. "The ARP Request MUST use the host MAC
address as the source, and the test node MAC address as the
destination," it says elsewhere.
Of course, only Apple engineers can say for sure if the MAC
disclosure is intentional, and representatives with the company have
declined to discuss the issue with Ars. What's more, if RFC 4436 is the
reason for the behavior, it's unclear why there's no evidence of Windows
and Android devices doing the same thing. If detecting previously
connected networks is such a good idea, wouldn't Microsoft and Google
want to design their devices to do it, too?
In contrast to the findings of Graham and Wuergler were those of Ars writer Peter Bright, who observed different behavior when his iPod touch connected to a wireless network.
While the Apple device did expose a MAC address, the unique identifier
belonged to the Ethernet interface of his router rather than the MAC
address of the router's WiFi interface, which is the identifier
cataloged by Google, Skyhook, and similar databases.
Bright speculated that many corporate networks likely behave the same
way. And for Apple devices that connect to access points with such
configurations, exposure of the MAC address may pose less of a threat.
Still, while it's unclear what percentage of wireless routers assign a
different MAC address to wired and wireless interfaces, Graham and
Wuergler's tests show that at least some wireless routers by default
make no such distinction.
Wuergler also debunked a few other misconceptions that some people
had about the wireless behavior of Apple devices. Specifically, he said
claims that iPhones don't broadcast the SSID they are looking for
from Errata Security's Graham are incorrect. Some Ars readers had
invoked the 2010 blog post from Graham to cast doubt on Wuergler's
findings
"The truth is Apple products do probe for known SSIDs (and no, there is no limit as to how many)," Wuergler wrote in a post published on Friday to the Daily Dave mailing list. He included the following screenshot to document his claim.
Mark Wuergler, Immunity Inc.
Connecting the dots
What all of this means is that there's good reason to believe that
iPhones and other Apple products—at least when compared to devices
running Windows or Android—are unique in leaking MAC addresses that can
uniquely identify the locations of networks you've connected to
recently. When combined with other data often exposed by virtually all
wireless devices—specifically the names of wireless networks you've
connected to in the past—an attacker in close proximity of you can
harvest this information and use it in targeted attacks.
Over the past year or so, Google and Skyhook have taken steps to make
it harder for snoops to abuse the GPS information stored in their
databases. Google Location Services, for instance, now requires the submission of two MAC addresses
in close proximity of each other before it will divulge where they are
located. In many cases, this requirement can be satisfied simply by
providing one of the other MAC addresses returned by the Apple device.
If it's within a few blocks of the first one, Google will readily
provide the data. It's also feasible for attackers to use war dialing
techniques to map the MAC addresses of wireless devices in a given
neighborhood or city.
Since Apple engineers are remaining mum, we can only guess why
iDevices behave the way they do. What isn't in dispute is that, unlike
hundreds of competing devices that Wuergler and Graham have examined,
the Apple products leak connection details many users would prefer to
keep private.
A video demonstrating the iPhone's vulnerability to fake access point attacks is here.