As mobile devices have continued to evolve and spread,
so has the process of designing and developing Web sites and services
that work across a diverse range of devices. From responsive Web design
to future friendly thinking, here's how I've seen things evolve over the
past year and a half.
If
you haven't been keeping up with all the detailed conversations about
multi-device Web design, I hope this overview and set of resources can
quickly bring you up to speed. I'm only covering the last 18 months
because it has been a very exciting time with lots of new ideas and
voices. Prior to these developments, most multi-device Web design
problems were solved with device detection and many still are. But the introduction of Responsive Web Design really stirred things up.
Responsive Web Design
Responsive
Web Design is a combination of fluid grids and images with media
queries to change layout based on the size of a device viewport. It uses
feature detection (mostly on the client) to determine available screen
capabilities and adapt accordingly. RWD is most useful for layout but
some have extended it to interactive elements as well (although this
often requires Javascript).
Responsive Web Design allows you to
use a single URL structure for a site, thereby removing the need for
separate mobile, tablet, desktop, etc. sites.
For a short overview read Ethan Marcotte's original article. For the full story read Ethan Marcotte's book. For a deeper dive into the philosophy behind RWD, read over Jeremy Keith's supporting arguments. To see a lot of responsive layout examples, browse around the mediaqueri.es site.
Challenges
Responsive
Web Design isn't a silver bullet for mobile Web experiences. Not only
does client-side adaptation require a careful approach, but it can also
be difficult to optimize source order, media, third-party widgets, URL
structure, and application design within a RWD solution.
Jason Grigsby has written up many of the reasons RWD doesn't instantly provide a mobile solution especially for images. I've documented (with concrete) examples why we opted for separate mobile and desktop templates in my last startup -a technique that's also employed by many Web companies like Facebook, Twitter, Google, etc. In short, separation tends to give greater ability to optimize specifically for mobile.
Mobile First Responsive Design
Mobile
First Responsive Design takes Responsive Web Design and flips the
process around to address some of the media query challenges outlined
above. Instead of starting with a desktop site, you start with the
mobile site and then progressively enhance to devices with larger
screens.
The Yiibu team was one of the first to apply this approach and wrote about how they did it. Jason Grigsby has put together an overview and analysis of where Mobile First Responsive Design is being applied. Brad Frost has a more high-level write-up of the approach. For a more in-depth technical discussion, check out the thread about mobile-first media queries on the HMTL5 boilerplate project.
Techniques
Many
folks are working through the challenges of designing Web sites for
multiple devices. This includes detailed overviews of how to set up
Mobile First Responsive Design markup, style sheet, and Javascript
solutions.
Ethan Marcotte has shared what it takes for teams of developers and designers to collaborate on a responsive workflow based on lessons learned on the Boston Globe redesign. Scott Jehl outlined what Javascript is doing (PDF) behind the scenes of the Globe redesign (hint: a lot!).
Stephanie Rieger assembled a detailed overview (PDF)
of a real-world mobile first responsive design solution for hundreds of
devices. Stephan Hay put together a pragmatic overview of designing with media queries.
Media
adaptation remains a big challenge for cross-device design. In
particular, images, videos, data tables, fonts, and many other "widgets"
need special care. Jason Grigsby has written up the situation with images and compiled many approaches for making images responsive. A number of solutions have also emerged for handling things like videos and data tables.
Server Side Components
Combining
Mobile First Responsive Design with server side component (not full
page) optimization is a way to extend client-side only solutions. With
this technique, a single set of page templates define an entire Web site
for all devices but key components within that site have device-class
specific implementations that are rendered server side. Done right, this
technique can deliver the best of both worlds without the challenges
that can hamper each.
I've put together an overview of how a Responsive Design + Server Side Components structure can work with concrete examples. Bryan Rieger has outlined an extensive set of thoughts on server-side adaption techniques and Lyza Gardner has a complete overview of how all these techniques can work together. After analyzing many client-side solutions to dynamic images, Jason Grigsby outlined why using a server-side solution is probably the most future friendly.
Future Thinking
If
all the considerations above seem like a lot to take in to create a Web
site, they are. We are in a period of transition and still figuring
things out. So expect to be learning and iterating a lot. That's both
exciting and daunting.
It also prepares you for what's ahead.
We've just begun to see the onset of cheap networked devices of every
shape and size. The zombie apocalypse of devices is coming. And while we can't know exactly what the future will bring, we can strive to design and develop in a future-friendly way so we are better prepared for what's next.
Resources
I
referenced lots of great multi-device Web design resources above. Here
they are in one list. Read them in order and rock the future Web!
In the beginning, there was the web and you accessed it though the
browser and all was good. Stuff didn’t download until you clicked on
something; you expected cookies to be tracking you and you always knew
if HTTPS was being used. In general, the casual observer had a pretty
good idea of what was going on between the client and the server.
Not
so in the mobile app world of today. These days, there’s this great big
fat abstraction layer on top of everything that keeps you pretty well
disconnected from what’s actually going on. Thing is, it’s a trivial
task to see what’s going on underneath, you just fire up an HTTP proxy
like Fiddler, sit back and watch the show.
Let
me introduce you to the seedy underbelly of the iPhone, a world where
not all is as it seems and certainly not all is as it should be.
There’s no such thing as too much information – or is there?
Here’s
a good place to start: conventional wisdom says that network efficiency
is always a good thing. Content downloads faster, content renders more
quickly and site owners minimise their bandwidth footprint. But even
more importantly in the mobile world, consumers are frequently limited
to fairly meagre download limits, at least by today’s broadband
standards. Bottom line: bandwidth optimisation in mobile apps is very important, far more so than in your browser-based web apps of today.
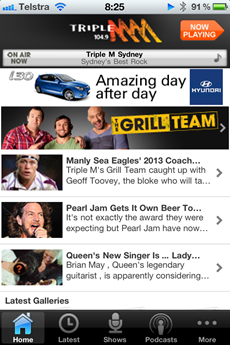
Let me give you an example of where this all starts to go wrong with mobile apps. Take the Triple M app, designed to give you a bunch of info about one of Australia’s premier radio stations and play it over 3G for you. Here’s how it looks:
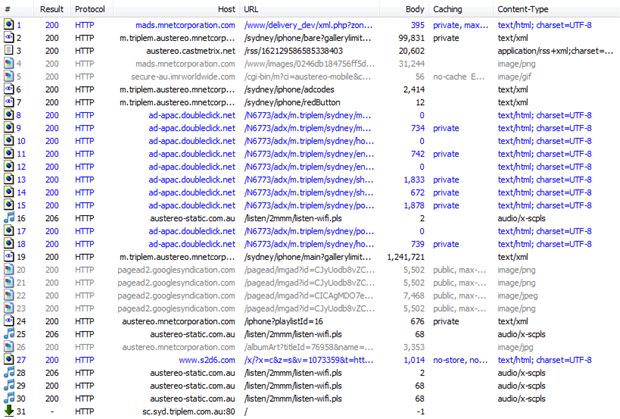
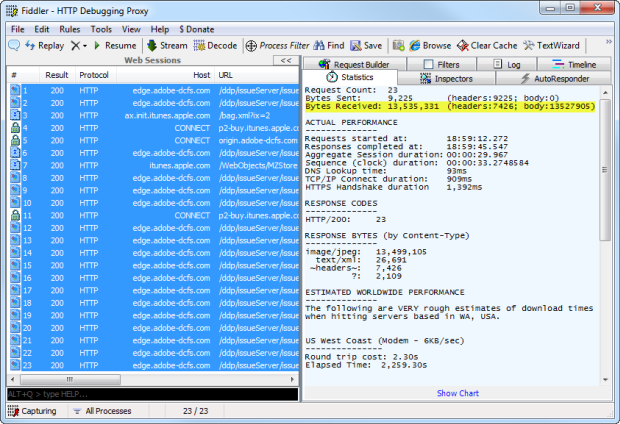
Where it all starts to go wrong is when you look at the requests being made just to load the app, you’re up to 1.3MB alone:
Why?
Well, part of the problem is that you’ve got no gzip compression.
Actually, that’s not entirely true, some of the small stuff is
compressed, just none of the big stuff. Go figure.
But there’s
also a lot of redundancy. For example, on the app above you can see the
first article titled “Manly Sea Eagles’ 2013 Coach…” and this is
returned in request #2 as is the body of the story. So far, so good. But
jump down to request #19 – that massive 1.2MB one – and you get the
whole thing again. Valuable bandwidth right out the window there.
Now
of course this app is designed to stream audio so it’s never going to
be light on bandwidth (as my wife discovered when she hit her cap “just
by listening to the radio”), and of course some of the upfront load is
also to allow the app to respond instantaneously when you drill down to
stories. But the patterns above are just unnecessary; why send redundant
data in an uncompressed format?
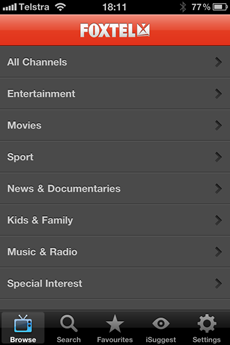
Here’s a dirty Foxtel secret;
what do you reckon it costs you in bandwidth to load the app you see
below? A few KB? Maybe a hundred KB to pull down a nice gzipped JSON
feed of all the channels? Maybe nothing because it will pull data on
demand when you actually do something?
Guess again, you’ll be needing a couple of meg just to start the app:
Part
of the problem is shown under the Content-Type heading above; it’s
nearly all PNG files. Actually, it’s 134 PNG files. Why? I mean what on
earth could justify nearly 2 meg of PNGs just to open the app? Take a
look at this fella:
This is just one of the actual images at original size. And why is this humungous PNG required? To generate this screen:
Hmmm, not really a use case for a 425x243, 86KB PNG. Why? Probably because as we’ve seen before,
developers like to take something that’s already in existence and
repurpose it outside its intended context, and just as in that
aforementioned link, this can start causing all sorts of problems.
Unfortunately it makes for an unpleasant user experience as you sit
there waiting for things to load while it does unpleasant things to your
(possibly meagre) data allocation.
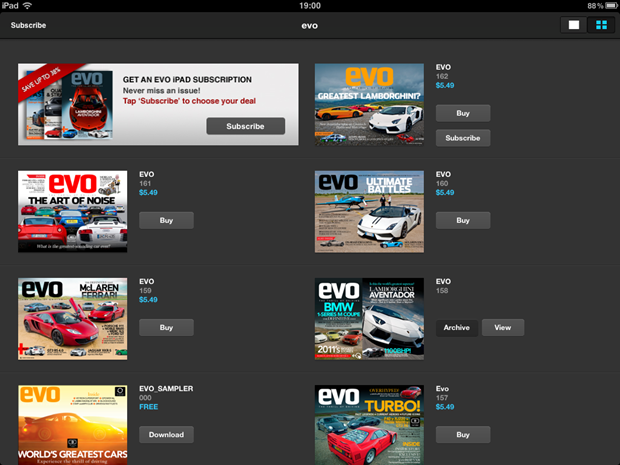
But we’re only just warming up. Let’s take a look at the very excellent, visually stunning EVO magazine on the iPad. The initial screen is just a list of editions like so:
Let’s
talk in real terms for a moment; the iPad resolution is 1024x768 or
what we used to think of as “high-res” not that long ago. The image
above has been resized down to about 60% of original but on the iPad,
each of those little magazine covers was originally 180x135 which even
saved as a high quality PNG, can be brought down well under 50KB apiece.
However:
Thirteen and a half meg?! Where an earth did all that go?! Here’s a clue:
Go on, click it, I’ll wait.
Yep, 1.6MB.
4,267 pixels wide, 3,200 pixels high.
Why?
I have no idea, perhaps the art department just sent over the originals
intended for print and it was “easy” to dump that into the app. All you
can do in the app without purchasing the magazine (for which you expect
a big bandwidth hit), is just look at those thumbnails. So there you
go, 13.5MB chewed out of your 3G plan before you even do anything just
because images are being loaded with 560 times more pixels than they
need.
The secret stalker within
Apps you install
directly onto the OS have always been a bit of a black box. I mean it’s
not the same “view source” world that we've become so accustomed to with
the web over the last decade and a half where it’s pretty easy to see
what’s going on under the covers (at least under the browser covers).
With the volume and affordability of iOS apps out there, we’re now well
and truly back in the world of rich clients which performs all sorts of
things out of your immediate view, and some of them are rather
interesting.
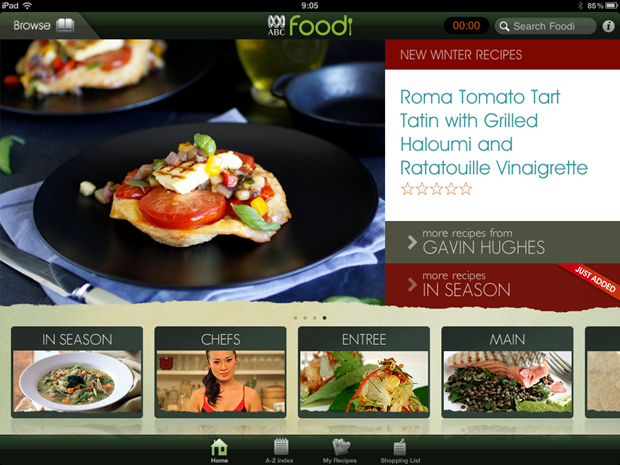
Let’s take cooking as an example; the ABC Foodi app is a beautiful piece of work. I mean it really is visually delightful and a great example of what can be done on the iPad:
But
it’s spying on you and phoning home at every opportunity. For example,
you can’t just open the app and start browsing around in the privacy of
your own home, oh no, this activity is immediately reported (I’m
deliberately obfuscating part of the device ID):
Ok, that’s a mostly innocuous, but it looks like my location – or at least my city
– is also in there so obviously my movements are traceable. Sure, far
greater location fidelity can usually be derived from the IP address
anyway (and they may well be doing this on the back end), but it’s
interesting to see this explicitly captured.
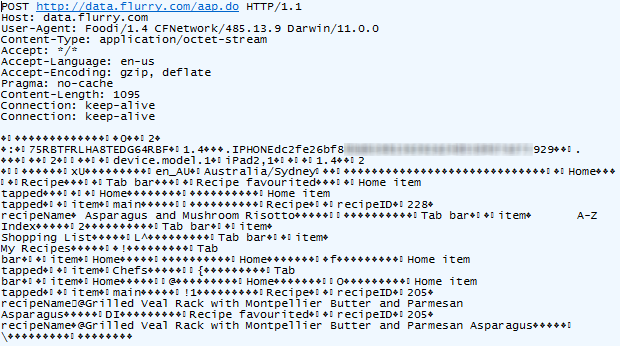
Let’s try something else, say, favouriting a dish:
Not the asparagus!!! Looks like you can’t even create a favourite
without your every move being tracked. But it’s actually even more than
that; I just located a nice chocolate cake and emailed it to myself
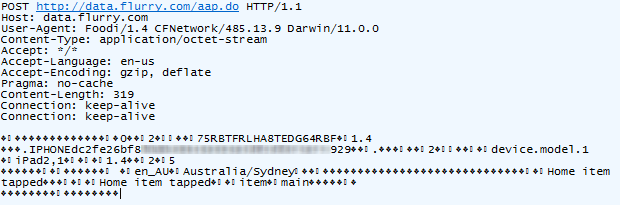
using the “share” feature. Here’s what happened next:
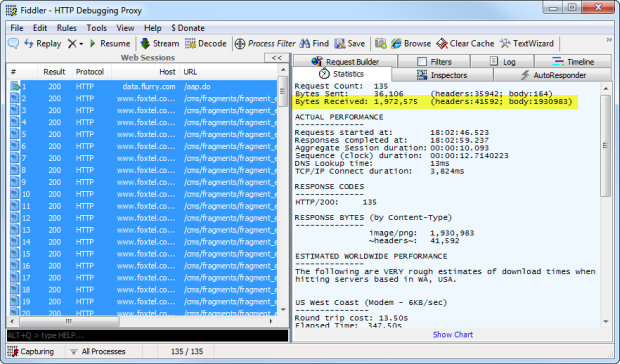
The app tracks your every moveand sends it back to base in small batches. In this case, that base is at flurry.com, and who are these guys? Well it’s quite clear from their website:
Flurry powers acquisition, engagement and monetization for the new
mobile app economy, using powerful data and applying game-changing
insight.
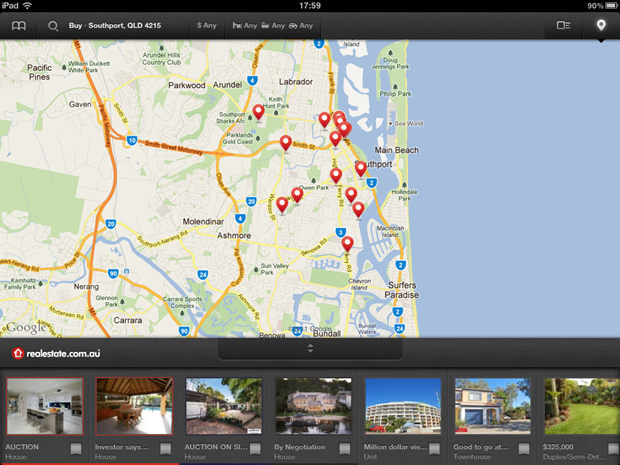
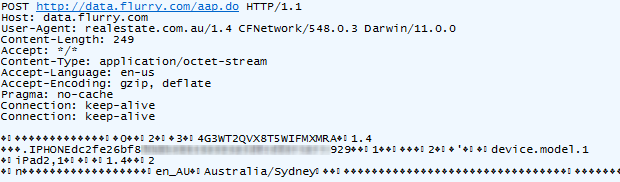
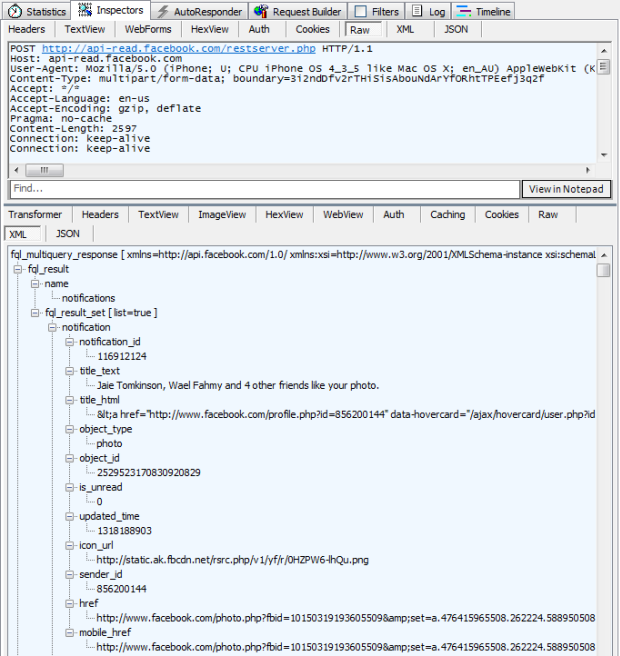
Here’s something I’ve seen before: POST requests to data.flurry.com. It’s perfectly obvious when you use the realestate.com.au iPad app:
Uh, except it isn’t really obvious, it’s another sneaky backdoor to
help power acquisitions and monetise the new app economy with
game-changing insight. Here’s what it’s doing and clearly it has nothing
to do with finding real estate:
Hang on – does that partially obfuscated device ID look a bit
familiar?! Yes it does, so Flurry now knows both what I’m cooking and
which kitchen I’d like to be cooking it in. And in case you missed it,
the first request when the Foxtel app was loaded earlier on was also to
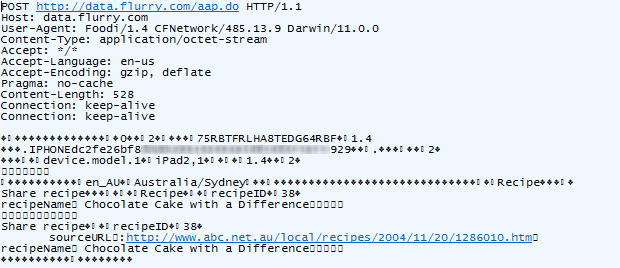
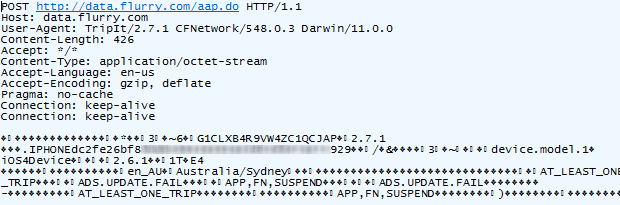
data.flurry.com. Oh, and how about those travel plans with TripIt – the cheerful blue sky looks innocuous enough:
But under the covers:
Suddenly monetisation with powerful data starts to make more sense.
But this is no different to a tracking cookie on a website, right?
Well, yes and no. Firstly, tracking cookies can be disabled. If you
don’t like ‘em, turn ‘em off. Not so the iOS app as everything is hidden
under the covers. Actually, it’s in much the same way as a classic app
that gets installed on any OS although in the desktop world, we’ve
become accustomed to being asked if we’re happy to share our activities “for product improvement purposes”.
These privacy issues simply come down to this: what does the user
expect? Do they expect to be tracked when browsing a cook book installed
on their local device? And do they expect this activity to be
cross-referenceable with the use of other apparently unrelated apps? I
highly doubt it, and therein lays the problem.
Security? We don’t need no stinkin’ security!
Many people are touting mobile apps as the new security frontier, and rightly so IMHO. When I wrote about Westfield
last month I observed how easy it was for the security of services used
by apps to be all but ignored as they don’t have the same direct public
exposure as the apps themselves. A browse through my iPhone collection
supports the theory that mobile app security is taking a back seat to
their browser-based peers.
Let’s take the Facebook app. Now to be honest, this one surprised me a
little. Back in Jan of this year, Facebook allowed opt-in SSL or in or in the words of The Register,
this is also known as “Turn it on yourself...bitch”. Harsh, but fair –
this valuable security feature was going to be overlooked by many, many
people. “SS what?”
Unfortunately, the very security that is offered to browser-based
Facebook users is not accessible on the iPhone client. You know, the
device which is most likely to be carried around to wireless hotspots
where insecure communications are most vulnerable. Here’s what we’re
left with:
This is especially surprising as that little bit of packet-sniffing magic that is Firesheep was no doubt the impetus for even having the choice of enable SSL. But here we are, one year on and apparently Facebook is none the wiser.
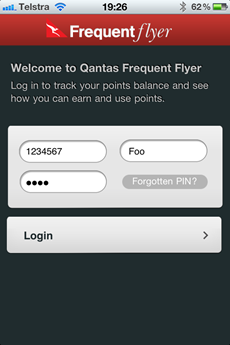
Let’s change pace a little and take a look inside the Australian Frequent Flyer app.
This is “Australia's leading Frequent Flyer Community” and clearly a
community of such standing would take security very, very seriously.
Let’s login:
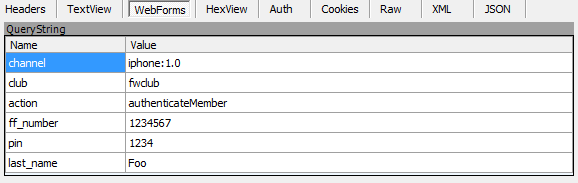
As with the Qantas example above, you have absolutely no idea
how these credentials are being transported across the wire. Well,
unless you have Fiddler then it’s perfectly clear they’re just being
posted to this HTTP address: http://www.australianfrequentflyer.com.au/mobiquo-withsponsor/mobiquo.php
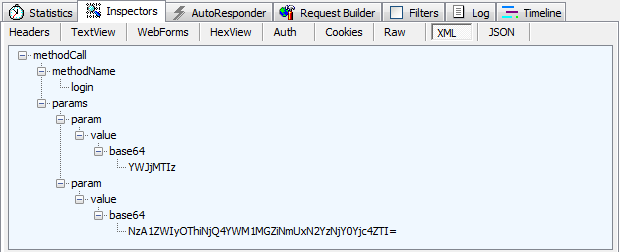
And of course it’s all very simple to see the post body which in this case, is little chunk of XML:
Bugger, clearly this is going to tack some sort of hacker mastermind
to figure out what these credentials are! Except it doesn’t, it just
takes a bit of Googling. There are two parameters and they’re both Base64
encoded. How do we know this? Well, firstly it tells us in one of the
XML nodes and secondly, it’s a pretty common practice to encode data in
this fashion before shipping it around the place (refer the link in this
paragraph for the ins and outs of why this is useful).
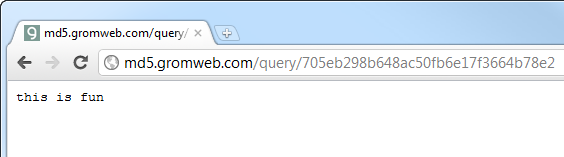
So we have a value of “YWJjMTIz” and because Base64 is designed to allow for simple encoding and decoding (unlike a hash which is a one way process), you can simply convert this back to plain text using any old Base64 decoder. Here’s an online one right here and it tells us this value is “abc123”. Well how about that!
The next value is “NzA1ZWIyOThiNjQ4YWM1MGZiNmUxN2YzNjY0Yjc4ZTI=”
which is obviously going to be the password. Once we Base64 decode this,
we have something a little different:
“705eb298b648ac50fb6e17f3664b78e2?”. Wow, that’s an impressive password!
Except that as we well know, people choosing impressive passwords is a
very rare occurrence indeed so in all likelihood this is a hash. Now
there are all sorts of nifty brute forcing tools out there but when it
comes to finding the plain text of a hash, nothing beats Google. And
what does the first result Google gives us? Take a look:
I told you that was a useless password
dammit! You see the thing is, there’s a smorgasbord of hashes and their
plain text equivalents just sitting out there waiting to be searched
which is why it’s always important to apply a cryptographically random salt to the plain text before hashing. A straight hash of most user-created passwords – which we know are generally crap – can very frequently be resolved to plain text in about 5 seconds via Google.
The bottom line is that this is almost no better than plain
text credentials and it’s definitely no alternative to transport layer
security. I’ve had numerous conversations with developers before trying
to explain the difference between encoding, hashing and encryption and
if I were to take a guess, someone behind this thinks they’re
“encrypted” the password. Not quite.
But is this really any different to logging onto the Australian Frequent Flyer website
which also (sadly) has no HTTPS? Yes, what’s different is that firstly,
on the website it’s clear to see that no HTTPS has been employed, or at
least not properly employed (the login form isn’t loaded over HTTPS). I
can then make a judgement call on the trust and credibility of the
site; I can’t do that with the app. But secondly, this is a mobile app – a mobile travel
app – you know, the kind of thing that’s going to be used while roaming
around wireless hotspots vulnerable to eavesdropping. It’s more
important than ever to protect sensitive communications and the app
totally misses the mark on that one.
While we’re talking travel apps, let’s take another look at Qantas. I’ve written about these guys before, in fact they made my Who’s who of bad password practices list earlier in the year. Although they made a small attempt at implementing security by posting to SSL, as I’ve said before, SSL is not about encryption and loading login forms over HTTP is a big no-no. But at least they made some attempt.
So why does the iPhone app just abandon all hope and do everything
without any transport layer encryption at all? Even worse, it just
whacks all the credentials in a query string. So it’s a GET request.
Over HTTP. Here’s how it goes down:
This is a fairly typical login screen. So far, so good, although of
course there’s no way to know how the credentials are handled. At least,
that is, until you take a look at the underlying request that’s made.
Here’s those query string parameters:
Go ahead, give it a run. What I find most odd about this situation is that clearly a conscious decision was made to apply some
degree of transport encryption to the browser app, why not the mobile
app? Why must the mobile client remain the poor cousin when it comes to
basic security measures? It’s not it’s going to be used inside any
highly vulnerable public wifi hotspots like, oh I don’t know, an airport
lounge, right?
Apps continue to get security wrong. Not just iOS apps mind you,
there are plenty of problems on Android and once anyone buys a Windows
Mobile 7 device we’ll see plenty of problems on those too. It’s just too
easy to get wrong and when you do get it wrong, it’s further out of
sight than your traditional web app. Fortunately the good folks at OWASP are doing some great work around a set of Top 10 mobile security risks so there’s certainly acknowledge of the issues and work being done to help developers get mobile security right.
Summary
What I discovered about is the result of casually observing some of
only a few dozen apps I have installed on my iOS devices. There are
about half a million more out there and if I were a betting man, my
money would be the issues above only being the tip of the iceberg.
You can kind of get how these issues happen; every man and his dog
appears to be building mobile apps these days and a low bar to entry is
always going to introduce some quality issues. But Facebook? And Qantas?
What are their excuses for making security take a back seat?
Developers can get away with more sloppy or sneaky practices in mobile apps as the execution is usually further out of view.
You can smack the user with a massive asynchronous download as their
attention is on other content; but it kills their data plan.
You can track their moves across entirely autonomous apps; but it erodes their privacy.
And most importantly to me, you can jeopardise their security without
their noticing; but the potential ramifications are severe.
When Tim Berners-Lee arrived at CERN,
Geneva's celebrated European Particle Physics Laboratory in 1980, the
enterprise had hired him to upgrade the control systems for several of
the lab's particle accelerators. But almost immediately, the inventor of
the modern webpage noticed a problem: thousands of people were floating
in and out of the famous research institute, many of them temporary
hires.
"The big challenge for contract programmers was to try to
understand the systems, both human and computer, that ran this fantastic
playground," Berners-Lee later wrote. "Much of the crucial information
existed only in people's heads."
So in his spare time, he wrote up some software to address this
shortfall: a little program he named Enquire. It allowed users to create
"nodes"—information-packed index card-style pages that linked to other
pages. Unfortunately, the PASCAL application ran on CERN's proprietary
operating system. "The few people who saw it thought it was a nice idea,
but no one used it. Eventually, the disk was lost, and with it, the
original Enquire."
Some years later Berners-Lee returned to CERN.
This time he relaunched his "World Wide Web" project in a way that
would more likely secure its success. On August 6, 1991, he published an
explanation of WWW on the alt.hypertext usegroup. He also released a code library, libWWW, which he wrote with his assistant
Jean-François Groff. The library allowed participants to create their own Web browsers.
"Their efforts—over half a dozen browsers within 18 months—saved
the poorly funded Web project and kicked off the Web development
community," notes a commemoration of this project by the Computer History Museum in Mountain View, California. The best known early browser was Mosaic, produced by Marc Andreesen and Eric Bina at the
National Center for Supercomputing Applications (NCSA).
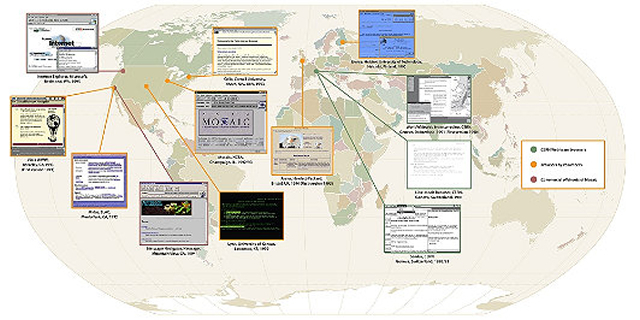
Mosaic was soon spun into Netscape, but it was not the first browser. A map
assembled by the Museum offers a sense of the global scope of the early
project. What's striking about these early applications is that they
had already worked out many of the features we associate with later
browsers. Here is a tour of World Wide Web viewing applications, before
they became famous.
The CERN browsers
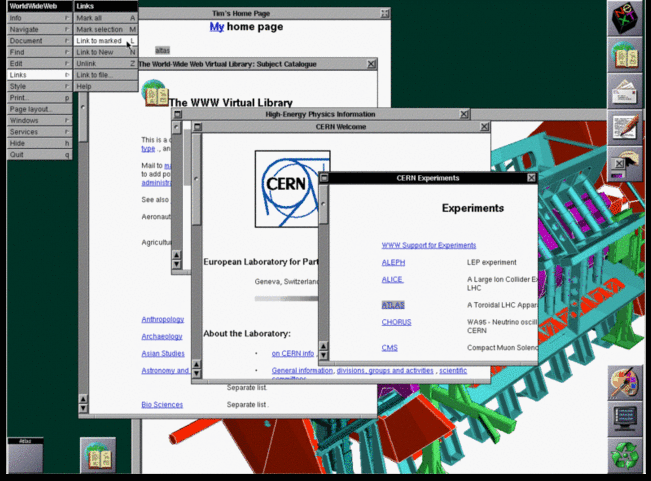
Tim Berners-Lee's original 1990 WorldWideWeb browser was both a
browser and an editor. That was the direction he hoped future browser
projects would go. CERN has put together a reproduction
of its formative content. As you can see in the screenshot below, by
1993 it offered many of the characteristics of modern browsers.
Tim Berners-Lee's original WorldWideWeb browser running on a NeXT computer in 1993
The software's biggest limitation was that it ran on the NeXTStep
operating system. But shortly after WorldWideWeb, CERN mathematics
intern Nicola Pellow wrote a line mode browser that could function
elsewhere, including on UNIX and MS-DOS networks. Thus "anyone could
access the web," explains Internet historian Bill Stewart, "at that point consisting primarily of the CERN phone book."
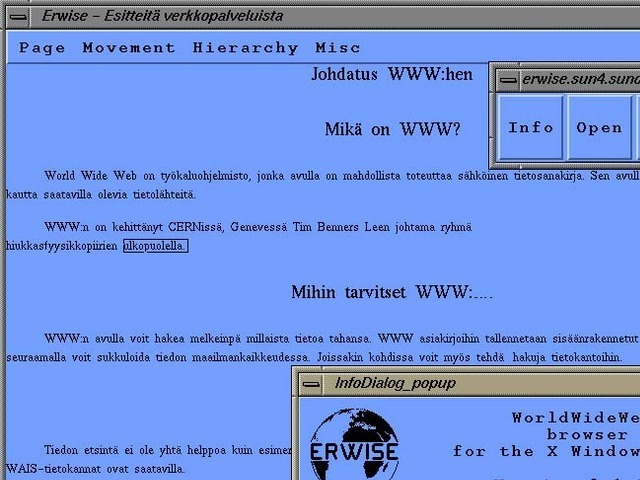
Erwise came next. It was written by four Finnish college students in 1991 and released in 1992. Erwise is credited as the first browser that offered a graphical interface. It could also search for words on pages.
Berners-Lee wrote a review
of Erwise in 1992. He noted its ability to handle various fonts,
underline hyperlinks, let users double-click them to jump to other
pages, and to host multiple windows.
"Erwise looks very smart," he declared, albeit puzzling over a
"strange box which is around one word in the document, a little like a
selection box or a button. It is neither of these—perhaps a handle for
something to come."
So why didn't the application take off? In a later interview, one of
Erwise's creators noted that Finland was mired in a deep recession at
the time. The country was devoid of angel investors.
"We could not have created a business around Erwise in Finland then," he explained.
"The only way we could have made money would have been to continue our
developing it so that Netscape might have finally bought us. Still, the
big thing is, we could have reached the initial Mosaic level with
relatively small extra work. We should have just finalized Erwise and
published it on several platforms."
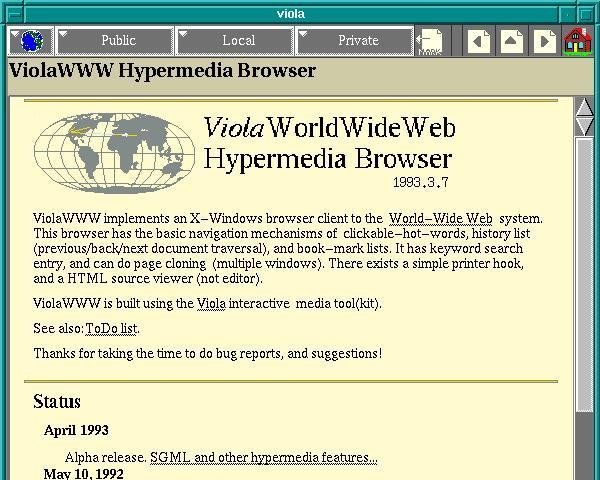
ViolaWWW was released in April
of 1992. Developer
Pei-Yuan Wei wrote it at the University of California at Berkeley via
his UNIX-based Viola programming/scripting language. No, Pei Wei didn't
play the viola, "it just happened to make a snappy abbreviation" of
Visually Interactive Object-oriented Language and Application, write
James Gillies and Robert Cailliau in their history of the World Wide
Web.
Wei appears to have gotten his inspiration from the early Mac
program HyperCard, which allowed users to build matrices of formatted
hyper-linked documents. "HyperCard was very compelling back then, you
know graphically, this hyperlink thing," he later recalled. But the
program was "not very global and it only worked on Mac. And I didn't
even have a Mac."
But he did have access to UNIX X-terminals at UC Berkeley's
Experimental Computing Facility. "I got a HyperCard manual and looked at
it and just basically took the concepts and implemented them in
X-windows." Except, most impressively, he created them via his Viola
language.
One of the most significant and innovative features of ViolaWWW was
that it allowed a developer to embed scripts and "applets" in the
browser page. This anticipated the huge wave of Java-based applet
features that appeared on websites in the later 1990s.
In his documentation, Wei also noted various "misfeatures" of ViolaWWW, most notably its inaccessibility to PCs.
Not ported to PC platform.
HTML Printing is not supported.
HTTP is not interruptable, and not multi-threaded.
Proxy is still not supported.
Language interpreter is not multi-threaded.
"The author is working on these problems... etc," Wei acknowledged
at the time. Still, "a very neat browser useable by anyone: very
intuitive and straightforward," Berners-Lee concluded in his review
of ViolaWWW. "The extra features are probably more than 90% of 'real'
users will actually use, but just the things which an experienced user
will want."
In September of 1991, Stanford Linear Accelerator physicist Paul
Kunz visited CERN. He returned with the code necessary to set up the
first North American Web server at SLAC. "I've just been to CERN," Kunz
told SLAC's head librarian Louise Addis, "and I found this wonderful
thing that a guy named Tim Berners-Lee is developing. It's just the
ticket for what you guys need for your database."
Addis agreed. The site's head librarian put the research center's
key database over the Web. Fermilab physicists set up a server shortly
after.
Then over the summer of 1992 SLAC physicist Tony Johnson wrote Midas, a graphical browser for the Stanford physics community. The big draw
for Midas users was that it could display postscript documents, favored
by physicists because of their ability to accurately reproduce
paper-scribbled scientific formulas.
"With these key advances, Web use surged in the high energy physics community," concluded a 2001 Department of Energy assessment of SLAC's progress.
Meanwhile, CERN associates Pellow and Robert Cailliau released the
first Web browser for the Macintosh computer. Gillies and Cailliau
narrate Samba's development.
For Pellow, progress in getting Samba up and running was slow,
because after every few links it would crash and nobody could work out
why. "The Mac browser was still in a buggy form,' lamented Tim
[Berners-Lee] in a September '92 newsletter. 'A W3 T-shirt to the first
one to bring it up and running!" he announced. The T shirt duly went to
Fermilab's John Streets, who tracked down the bug, allowing Nicola
Pellow to get on with producing a usable version of Samba.
Samba "was an attempt to port the design of the original WWW
browser, which I wrote on the NeXT machine, onto the Mac platform,"
Berners-Lee adds,
"but was not ready before NCSA [National Center for Supercomputing
Applications] brought out the Mac version of Mosaic, which eclipsed it."
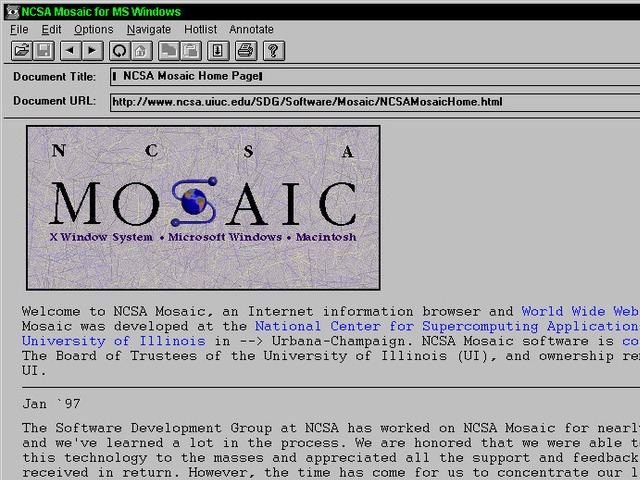
Mosaic was "the spark that lit the Web's explosive growth in 1993,"
historians Gillies and Cailliau explain. But it could not have been
developed without forerunners and the NCSA's University of Illinois
offices, which were equipped with the best UNIX machines. NCSA also had
Dr. Ping Fu, a PhD computer graphics wizard who had worked on morphing
effects for Terminator 2. She had recently hired an assistant named Marc Andreesen.
"How about you write a graphical interface for a browser?" Fu
suggested to her new helper. "What's a browser?" Andreesen asked. But
several days later NCSA staff member Dave Thompson gave a demonstration
of Nicola Pellow's early line browser and Pei Wei's ViolaWWW. And just
before this demo, Tony Johnson posted the first public release of Midas.
The latter software set Andreesen back on his heels. "Superb!
Fantastic! Stunning! Impressive as hell!" he wrote to Johnson. Then
Andreesen got NCSA Unix expert Eric Bina to help him write their own
X-browser.
Mosaic offered many new web features, including support for video
clips, sound, forms, bookmarks, and history files. "The striking thing
about it was that unlike all the earlier X-browsers, it was all
contained in a single file," Gillies and Cailliau explain:
Installing it was as simple as pulling it across the network and
running it. Later on Mosaic would rise to fame because of the
<IMG> tag that allowed you to put images inline for the first
time, rather than having them pop up in a different window like Tim's
original NeXT browser did. That made it easier for people to make Web
pages look more like the familiar print media they were use to; not
everyone's idea of a brave new world, but it certainly got Mosaic
noticed.
"What I think Marc did really well," Tim Berners-Lee later wrote,
"is make it very easy to install, and he supported it by fixing bugs via
e-mail any time night or day. You'd send him a bug report and then two
hours later he'd mail you a fix."
Perhaps Mosaic's biggest breakthrough, in retrospect, was that it
was a cross-platform browser. "By the power vested in me by nobody in
particular, X-Mosaic is hereby released," Andreeson proudly declared on
the www-talk group on January 23, 1993. Aleks Totic unveiled his Mac
version a few months later. A PC version came from the hands of Chris
Wilson and Jon Mittelhauser.
The Mosaic browser was based on Viola and Midas, the Computer History museum's exhibit notes.
And it used the CERN code library. "But unlike others, it was reliable,
could be installed by amateurs, and soon added colorful graphics within
Web pages instead of as separate windows."
The Mosaic browser was available for X Windows, the Mac, and Microsoft Windows
But Mosaic wasn't the only innovation to show up on the scene around that same time. University of Kansas student Lou Montulli
adapted a campus information hypertext browser for the Internet and
Web. It launched in March, 1993. "Lynx quickly became the preferred web
browser for character mode terminals without graphics, and remains in
use today," historian Stewart explains.
And at Cornell University's Law School, Tom Bruce was writing a Web
application for PCs, "since those were the computers that lawyers tended
to use," Gillies and Cailliau observe. Bruce unveiled his browser Cello on June 8, 1993, "which was soon being downloaded at a rate of 500 copies a day."
Cello!
Six months later, Andreesen was in Mountain View, California, his
team poised to release Mosaic Netscape on October 13, 1994. He, Totic,
and Mittelhauser nervously put the application up on an FTP server. The
latter developer later recalled the moment. "And it was five minutes and
we're sitting there. Nothing has happened. And all of a sudden the
first download happened. It was a guy from Japan. We swore we'd send him
a T shirt!"
But what this complex story reminds is that is that no innovation is
created by one person. The Web browser was propelled into our lives by
visionaries around the world, people who often didn't quite understand
what they were doing, but were motivated by curiosity, practical
concerns, or even playfulness. Their separate sparks of genius kept the
process going. So did Tim Berners-Lee's insistence that the project stay
collaborative and, most importantly, open.
"The early days of the web were very hand-to-mouth," he writes. "So many things to do, such a delicate flame to keep alive."
Further reading
Tim Berners-Lee, Weaving the Web: The Original Design and Ultimate Destiny of the World Wide Web
James Gillies and R. Cailliau, How the web was born
As new platform versions get released more and more quickly,
are users keeping up? Zeh Fernando, a senior developer at Firstborn,
looks at current adoption rates and points to some intriguing trends
There's a quiet revolution happening on the web, and it's related to one aspect of the rich web that is rarely discussed: the adoption rate of new platform versions.
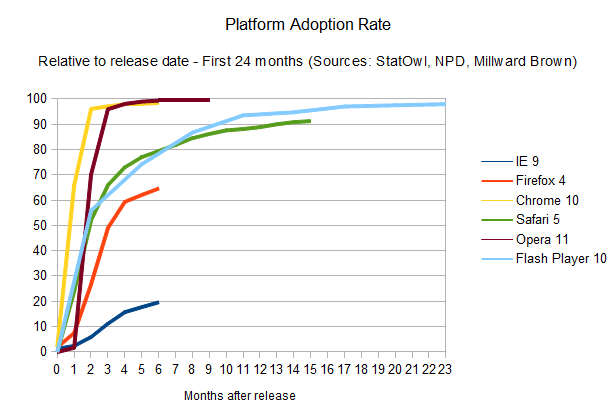
First,
to put things into perspective, we can look at the most popular browser
plug-in out there: Adobe's Flash Player. It's pretty well known that
the adoption of new versions of the Flash plug-in happens pretty
quickly: users update Flash Player quickly and often after a new version
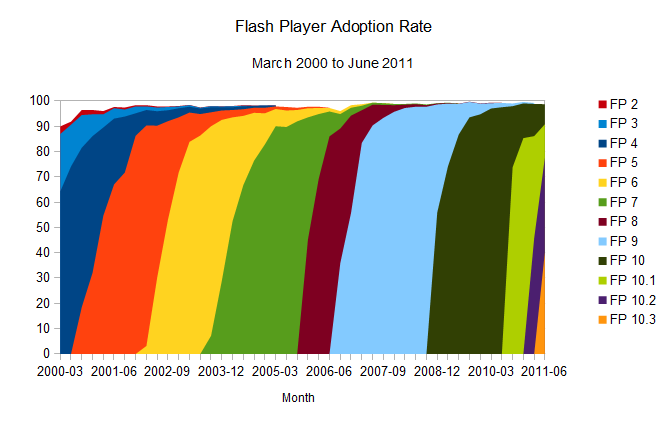
of the plug-in is released [see Adobe's sponsored NPD, United
States, Mar 2000-Jun 2006, and Milward Brown’s “Mature markets”, Sep
2006-Jun 2011 research (here and here) collected by way of the Internet Archive and saved over time; here’s the complete spreadsheet with version release date help from Wikipedia].
To
simplify it: give it around eight months, and 90 per cent of the
desktops out there will have the newest version of the plug-in
installed. And as the numbers represented in the charts above show, this
update rate is only improving. That’s party due to the fact that
Chrome, now a powerful force in the browser battles, installs new
versions of the Flash Player automatically (sometimes even before it is
formally released by Adobe), and that Firefox frequently detects the
user's version and insists on them installing an updated, more secure
version.
Gone are the days where the Flash platform needed an
event such as the Olympics or a major website like MySpace or YouTube
making use of a new version of Flash to make it propagate faster; this
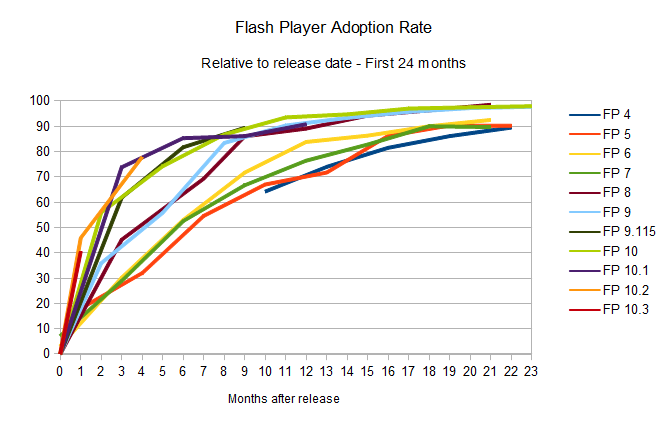
now happens naturally. Version 10.3 only needed one month to get to a
40.5 per cent install base, and given the trends set by the previous
releases, it's likely that the plug-in's new version 11 will break new speed records.
Any technology that can allow developers and publishers to take advantage of it in a real world scenario
so fast has to be considered a breakthrough. Any new platform feature
can be proposed, developed, and made available with cross-platform
consistency in record time; such is the advantage of a proprietary
platform like Flash. To mention one of the more adequate examples of
the opposite effect, features added to the HTML platform (in any of its
flavours or versions) can take many years of proposal and beta support
until they're officially accepted, and when that happens, it takes many
more years until it becomes available on most of the computers out
there. A plug-in is usually easier and quicker to update than a browser
too.
That has been the story so far. But that's changing.
Advertisement
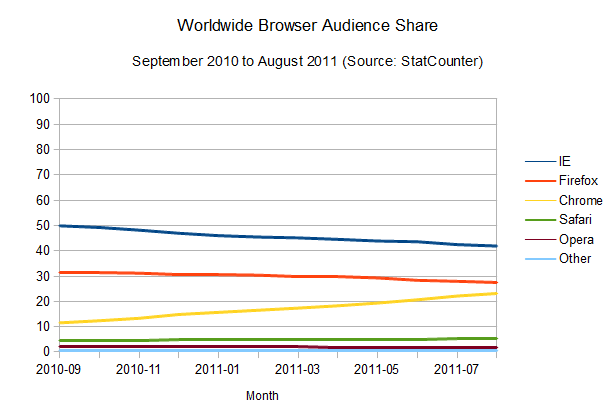
Google Chrome adoption rate
Looking
at the statistics for the adoption rate of the Flash plug-in, it's easy
to see it's accelerating constantly, meaning the last versions of the
player were finding their way to the user's desktops quicker and quicker
with every new version. But when you have a look at similar adoption
rate for browsers, a somewhat similar but more complex story unfolds.
Let's
have a look at Google Chrome's adoption rates in the same manner I've
done the Flash player comparisons, to see how many people had each of
its version installed (but notice that, given that Chrome is not used by
100 per cent of the people on the internet, it is normalised for the
comparison to make sense).
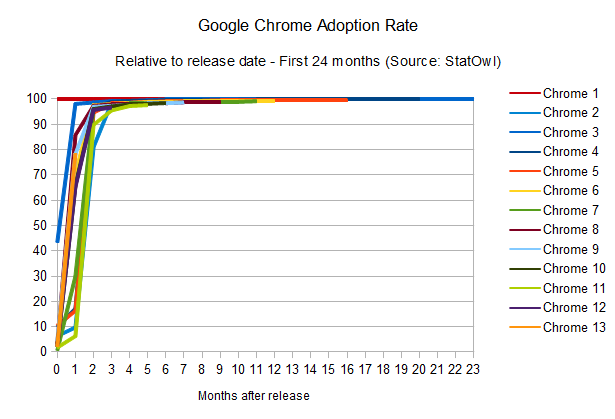
The striking thing here is that the adoption rate of Google Chrome manages to be faster than Flash Player itself [see StatOwl's web browser usage statistics, browser version release dates from Google Chrome on
Wikipedia]. This is helped, of course, by the fact that updates happens
automatically (without user approval necessary) and easily (using its smart diff-based update engine to
provide small update files). As a result, Chrome can get to the same 90
per cent of user penetration rate in around two months only; but what
it really means is that Google manages to put out updates to their HTML engine much faster than Flash Player.
Of
course, there's a catch here if we're to compare that to Flash Player
adoption rate: as mentioned, Google does the same auto-update for the
Flash Player itself. So the point is not that there's a race and
Chrome's HTML engine is leading it; instead, Chrome is changing the
rules of the game to not only make everybody win, but to make them win faster.
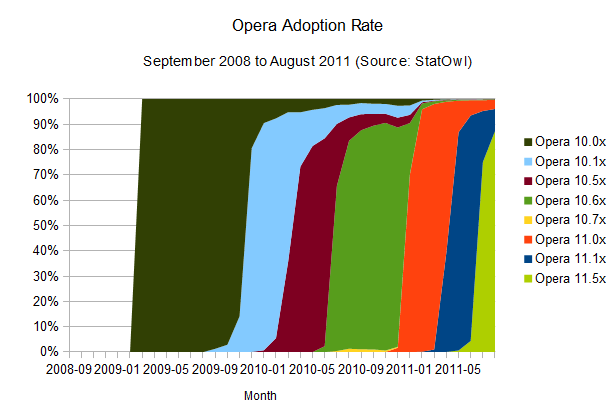
Opera adoption rate
The
fast update rate employed by Chrome is not news. In fact, one smaller
player on the browser front, Opera, tells a similar story.
Opera also manages to have updates reach a larger audience very quickly [see browser version release dates from History of the Opera web browser, Opera 10 and Opera 11
on Wikipedia]. This is probably due to its automatic update feature.
The mass updates seem to take a little bit longer than Chrome, around
three months for a 90 per cent reach, but it's important to notice that
its update workflow is not entirely automatic; last time I tested, it
still required user approval (and Admin rights) to work its magic.
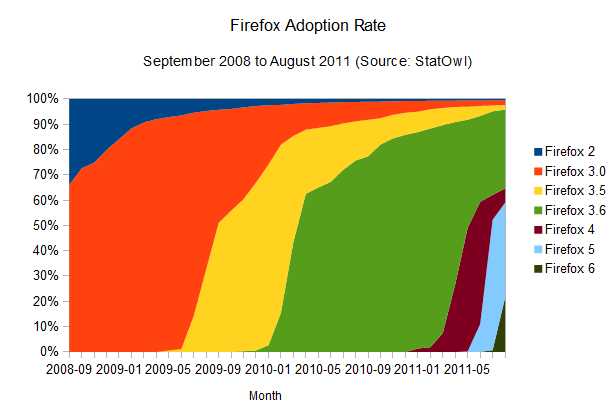
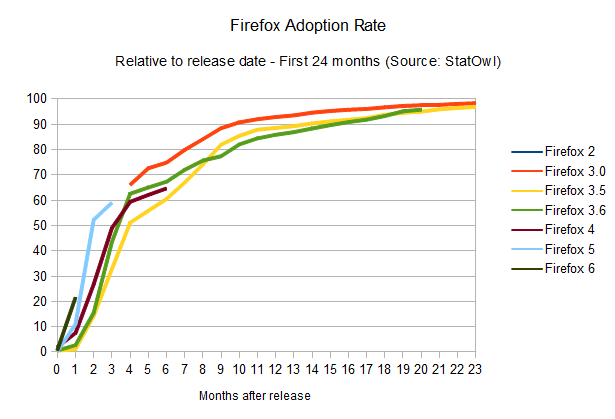
Firefox adoption rate
The
results of this browser update analysis start deviating when we take a
similar look at the adoption rates of the other browsers. Take Firefox,
for example:
It's also clear that Firefox's update rate is accelerating (browser version release dates from Firefox on
Wikipedia), and the time-to-90-per-cent is shrinking: it should take
around 12 months to get to that point. And given Mozilla's decision to
adopt release cycles that mimics Chrome's,
with its quick release schedule, and automatic updates, we're likely to
see a big boost in those numbers, potentially making the update
adoption rates as good as Chrome's.
One interesting point here is
that a few users seem to have been stuck with Firefox 3.6, which is the
last version that employs the old updating method (where the user has
to manually check for new versions), causing Firefox updates to spread
quickly but stall around the 60 per cent mark. Some users still need to
realise there's an update waiting for them; and similarly to the problem the Mozilla team had to face with Firefox 3.5, it's likely that we'll see the update being automatically imposed upon users soon, although they'll still be able to disable it. It's gonna be interesting to see how this develops over the next few months.
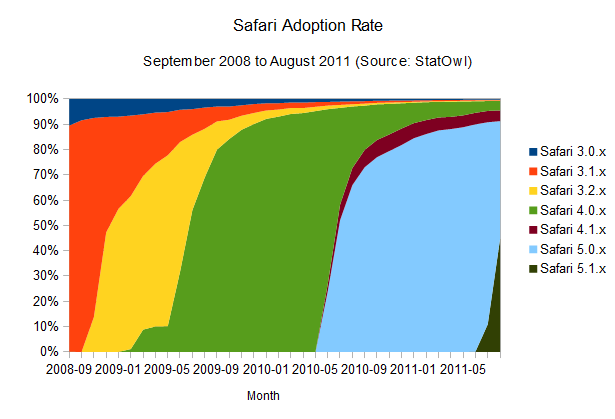
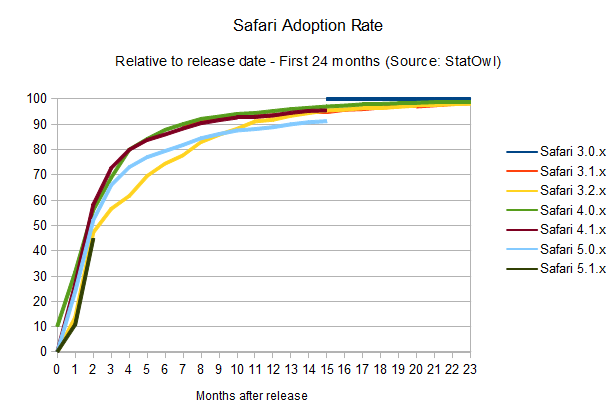
What does Apple's Safari look like?
Safari adoption rate
Right now, adoption rates seem on par with Firefox (browser version release dates from Safari on
Wikipedia), maybe a bit better, since it takes users around 10 months
to get a 90 per cent adoption rate of the newest versions of the
browser. The interesting thing is that this seems to happen in a pretty solid
fashion, probably helped by Apple's OS X frequent update schedule,
since the browser update is bundled with system updates. Overall, update
rates are not improving – but they're keeping at a good pace.
Notice
that the small bump on the above charts for Safari 4.0.x is due to the
public beta release of that version of the browser, and the odd area for
Safari 4.1.x is due to its release in pair with Safari 5.0.x, but for a
different version of OSX.
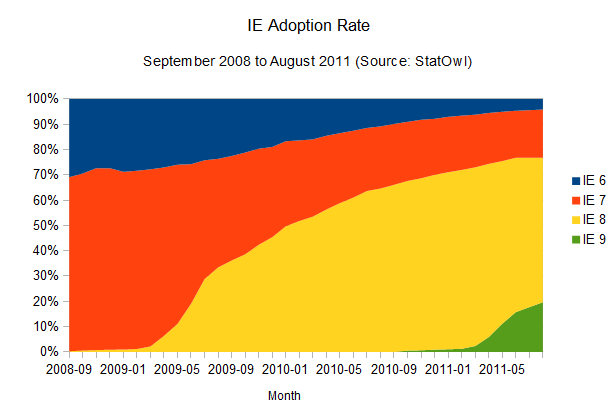
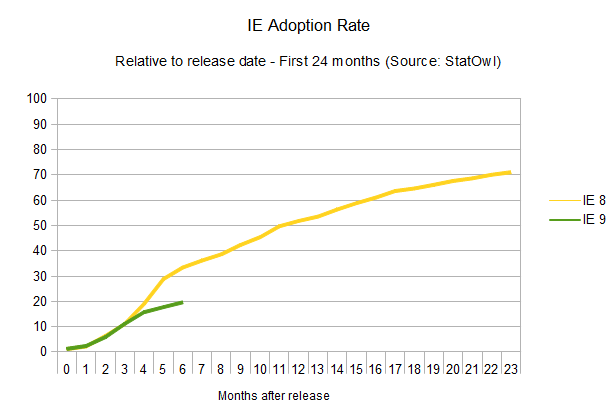
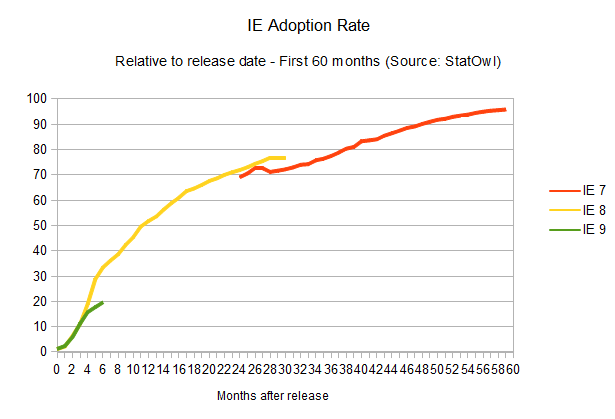
IE adoption rate
All in all it seems to me that browser vendors, as well as the users, are starting to get it. Overall, updates are happening faster and the cycle from interesting idea to a feature that can be used on a real-world scenario is getting shorter and shorter.
There's just one big asterisk in this prognosis: the adoption rate for the most popular browser out there.
The adoption rate of updates to Internet Explorer is not improving at all (browser version release dates from Internet Explorer on Wikipedia). In fact, it seems to be getting worse.
As
is historically known, the adoption rate of new versions of Internet
Explorer is, well, painstakingly slow. IE6, a browser that was released
10 years ago, is still used by four per cent of the IE users, and newer
versions don't fare much better. IE7, released five years ago, is still
used by 19 per cent of all the IE users. The renewing cycle here is so
slow that it's impossible to even try to guess how long it would take
for new versions to reach a 90 per cent adoption rate, given the lack of
reliable data. But considering update rates haven't improved at all for
new versions of the browser (in fact, IE9 is doing worse than IE8 in
terms of adoption), one can assume a cycle of four years until any released version of Internet Explorer reaches 90 per cent user adoption. Microsoft itself is trying to make users abandon IE6,
and whatever the reason for the version lag – system administrators
hung up on old versions, proliferation of pirated XP installations that
can't update – it's just not getting there.
And the adoption rates
of new HTML features is, unfortunately, only as quick as the adoption
rate of the slowest browser, especially when it's someone that still
powers such a large number of desktops out there.
Internet Explorer will probably continue to be the most popular browser for a very long time.
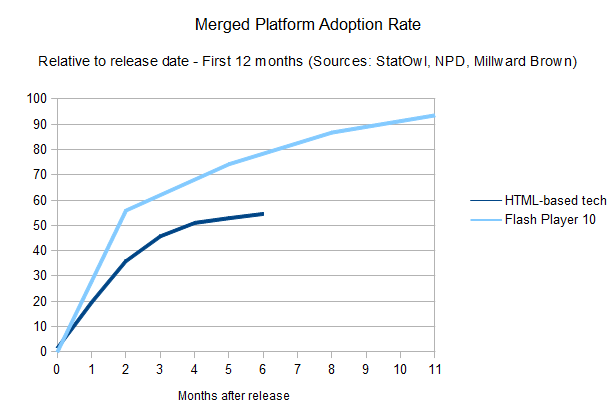
The long road for HTML-based tech
The
story, so far, has been that browser plug-ins are usually easier and
quicker to update. Developers can rely on new features of a proprietary
platform such as Flash earlier than someone who uses the native HTML
platform could. This is changing, however, one browser at a time.
A merged
chart, using the weighted distribution of each browser's penetration
and the time it takes for its users to update, tells that the overall
story for HTML developers still has a long way to go.
Of course, this shouldn't be taken into account blindly. You should always have your audience in mind when developing a website,
and come up with your own numbers when deciding what kind of features
to make use of. But it works as a general rule of thumb to be taken into
account before falling in love with whatever feature has just been
added to a browser's rendering engine (or a new plug-in version, for
that matter). In that sense, be sure to use websites like caniuse.com to
check on what's supported (check the “global user stats” box!), and
look at whatever browser share data you have for your audience (and
desktop/mobile share too, although it's out of the scope of this
article).
Conclusion
Updating the browser has always been a
certain roadblock to most users. In the past, even maintaining
bookmarks and preferences when doing an update was a problem.
That
has already changed. With the exception of Internet Explorer, browsers
vendors are realising how important it is to provide easy and timely
updates for users; similarly, users themselves are, I like to believe,
starting to realise how an update can be easy and painless too.
Personally,
I used to look at the penetration numbers of Flash and HTML in
comparison to each other and it always baffled me how anyone would
compare them in a realistic fashion when it came down to the speed that
any new feature would take to be adopted globally. Looking at them this
time, however, gave me a different view on things; our rich web
platforms are not only getting better, but they're getting better at
getting better, by doing so faster.
In retrospect, it
seems obvious now, but I can only see all other browser vendors adopting
similar quick-release, auto-update features similar to what was
introduced by Chrome. Safari probably needs to make the updates install
without user intervention, and we can only hope that Microsoft will
consider something similar for Internet Explorer. And when that happens,
the web, both HTML-based and plug-ins-based but especially on the HTML
side, will be moving at a pace that we haven't seen before. And
everybody wins with that.
Well, this is a little unsettling: it turns out that Wi-Fi signals are slightly affected by people breathing, and with the right tech someone could pinpoint where you are in a room from afar using just Wi-Fi.
This was discovered when University of Utah researcher Neal Patwari was looking for a way to monitor breathing without using uncomfortable equipment. If you can track breathing using just a Wi-Fi signal, it'll make sleep studies easier for both researchers and subjects. And it worked! By laying in a hospital bed surrounded by a bunch of wireless routers, they were able to accurately estimate his breathing rate within 0.4 breaths per minute.
Now that this is known, it's only a matter of time until there's a way to detect people in rooms using Wi-Fi signals. But don't worry! If you're nervous, there's a simple solution: stop breathing.
The operators of the TDSS botnet are renting out access to infected computers for anonymous Web activities
Cloud computing isn't just opening up new opportunities for
legitimate organizations worldwide; it's also proving a potential boon
for cyber criminals as it inexpensively and conveniently puts disposal
powerful computing resources at their fingertips, which helps them
quickly and anonymously do their dirty deeds.
Among the latest examples of this unfortunate trend comes via Kaspersky Labs:
The company has reported that the operators of TDSS, one of the world's
largest, most sophisticated botnets, are renting out infected computers
to would-be customers through the awmproxy.net storefront. Not only has
TDSS developed a convenient Firefox add-on, it's accepting payment via
PayPal, MasterCard, and Visa, as well as e-currency like WebMoney and Liberty Reserve.
Also
known as TDL-4, the TDSS malware employs a rootkit to infect
Windows-based systems, allowing outsiders to use affected machines to
anonymously surf the Web, according to Kaspersky researchers Sergey Golobanov and Igor Soumenkov.
The malware also removes some 20 malicious programs from host PCs to
sever communication with other bot families. (Evidently, botnet
operators are becoming increasingly competitive with one another.)
According
to the researchers, the operators of TDSS are effectively offering
anonymous Internet access as a service for about $100 per month. "For
the sake of convenience, the cyber criminals have also developed a
Firefox add-on that makes it easy to toggle between proxy servers within
the browser," they reported.
According to Golovanov, once
machines are infected, a component called socks.dll notifies
awmproxy.net that a new proxy is available for rent. Soon after, the
infected PC starts to accept proxy requests.
Notably, Kapersky does offer a utility to remove TDSS dubbed TDSSKiller.
This
isn't the first instance of an organization making expansive
cloud-based systems available to potential ne'er-do-wells, though it's
arguably among the most brazen examples. Amazon Web Services have proven
possible to exploit to pull off cheap brute-force attacks and could be abused for other unsavory deeds as well, such as spam propagation.
Between
2010 and 2015, the number of U.S. mobile Internet users will increase by
a compound annual growth rate of 16.6 percent while PCs and other
wireline services first stagnate, then gradually decline
The
International Data Corporation (IDC) released its Worldwide New Media Market Model (NMMM) predictions
yesterday, which forecasts that the number of people who use mobile devices to
access the Internet will significantly increase over the next few years while
wireline internet access will slowly decline.
According to the IDC's Worldwide New Media Market Model, more U.S. internet
users will access the web through mobile devices rather than through PCs or
wireline services by 2015.
Between 2010 and 2015, the number of U.S. mobile internet users will increase
by a compound annual growth rate of 16.6 percent while PCs and other wireline
services first stagnate, then gradually decline.
Globally, the number of internet users will increase from 2 billion in 2010 to
2.7 billion in 2015, as 40 percent of the world's population will have Web
access by that time. Also, global B2C e-commerce spending will increase from
$708 billion in 2010 to $1,285 billion in 2015 at a compound annual growth rate
of 12.7 percent, and worldwide online advertising will increase from $70
billion in 2010 to $138 billion in 2015.
"Forget what we have taken for granted on how consumers use the Internet," said Karsten Weide,
research vice president, Media and Entertainment. "Soon, more users will
access the Web using mobile devices than using PCs, and it's going to make the
Internet a very different place."
These
predictions may seem unsurprising, considering the fact that tech giants like
Apple, Samsung, Google and Motorola are consistently releasing smartphones and
tablets (in Google's case, its Android OS). A recent study conducted by the Pew
Internet & American Life Project found that 35 percent of American
adults now own a smartphone instead of a feature phone.
The spotlight was placed on the decline of wireline services last month
when 45,000 Verizon wireline
employees went on strike because the company had to cut pensions,
make employees pay more for healthcare, etc. in order to cut costs and
compensate for its declining wireline business.
We’ve worked hard to reduce the amount of energy our services use. In fact, to provide you with Google products for a month—not just search, but Google+, Gmail, YouTube and everything else we have to offer—our servers use less energy per user than a light left on for three hours. And, because we’ve been a carbon-neutral company since 2007, even that small amount of energy is offset completely, so the carbon footprint of your life on Google is zero.
We’ve learned a lot in the process of reducing our environmental impact, so we’ve added a new section called“The Big Picture”to ourGoogle Green sitewith numbers on our annual energy use and carbon footprint.
We started the process of getting to zero by making sure our operations use as little energy as possible. For the last decade, energy use has been an obsession. We’ve designed and built some of the most efficient servers anddata centersin the world—using half the electricity of a typical data center. Ournewest facilityin Hamina, Finland, opening this weekend, uses a unique seawater cooling system that requires very little electricity.
Whenever possible, we use renewable energy. We have a large solar panel installation at our Mountain View campus, and we’vepurchased the outputof two wind farms to power our data centers. For the greenhouse gas emissions we can’t eliminate, we purchase high-qualitycarbon offsets.
But we’re not stopping there. Byinvestinghundreds of millions of dollars in renewable energy projects and companies, we’re helping to create 1.7 GW of renewable power. That’s the same amount of energy used to power over 350,000 homes, and far more than what our operations consume.
Finally, our products can help people reduce their own carbon footprints. Thestudy(PDF) we released yesterday on Gmail is just one example of how cloud-based services can be much more energy efficient than locally hosted services helping businesses cut their electricity bills.
Now
that Chromebooks--portable computers based on Google's Chrome OS--are
maturing, it's easier to gauge the prospects for Google's first-ever
operating system. As Jon Buys discussed
here on OStatic, these portables have a number of strong points.
However, there are criticisms appearing about them, too, and some of
them echo ones made here on OStatic before.
Specifically, Chrome OS imposes a very two-fisted, cloud-centric model
for using data and applications, where traditional, local storage of
data and apps is discouraged. Recently, Google has sought to close
this gap with its own apps, allowing users to work with its Gmail,
Calendar and Docs apps offline. Will these moves help boost Chrome OS
and use of Chromebooks? In enterprises, they may do so.
Google officials have explained the logic behind allowing offline usage of key Google apps in this post, where they write:
"Today’s
world doesn’t slow down when you’re offline and it’s a great feeling to
be productive from anywhere, on any device, at any time. We’re pushing
the boundaries of modern browsers to make this possible, and while we
hope that many users will already find today’s offline functionality
useful, this is only the beginning. Support for offline document editing
and customizing the amount of email to be synchronized will be coming
in the future. We also look forward to making offline access more widely
available when other browsers support advanced functionality (like
background pages)."
While Google had previously
announced its intent to deliver this offline functionality, the need for
it was undoubtedly accelerated by some of the criticisms of the way
Chrome OS forces users to work almost exclusively in the cloud. It's
also not accidental that the offline capabilities are focused on Google
applications that enterprises care about: mail, document-creation apps,
etc.
Guillermo Garron has gone so far as to reverse his previous
criticisms of Chrome OS based on the new offline functionality, as seen in his post here. He writes:
"This
is something specially good for Chromebooks. Now they are not just new
toys, they can be real productive tools…now Chromebooks are ready for
Prime Time at least to do what they were designed for, with no
limitations."
Researchers at Microsoft have produced
data before that shows that most people use a maximum of five software
applications on a regular basis. In delivering offline functionality for
mail, document creation, and other absolutely key tasks for working
people, Google is hedging the cloud-only bet that it made with Chrome OS
upon its debut. It's the right move for Google to be making, and is
likely to help win over some enterprises that would find working
exclusively in the cloud to be too limiting.
Symantec, the company behind Norton Anti-Virus, has published a
startling report which estimates nearly $388 billion is lost each year
to cyber crime – $274 billion in sheer wasted time, and the remaining
$114 billion either spent to combat it or deposited into the bank
accounts of criminals.
Source: Norton
According to the “Norton Cybercrime Report 2011,”
viruses and malware are the “preventable yet more prevalent” methods
employed by cyber criminals. Conducted earlier this year by StrategyOne,
who polled 19,636 adults, kids and teachers in 24 countries, the study
revealed over 54 percent of online adults have indeed encountered either
threat despite the fact 59 percent incorporate active, up-to-date
anti-virus software. Online scams and phishing rounded out the most
common methods.
Resolving a cyber crime is also a huge hassle for those affected.
Norton’s research found the entire process takes anywhere from four to
16 days depending on where you live; on average, victims spend 10 days.
“These latest cyber crime statistics reflect crime rates in the
physical world, where young adults and men are more often victims of
crime,” said Adam Palmer, Norton Lead Cyber Security Analyst. “Countries
like South Africa and Brazil, where physical crimes against people are
among the highest in the world, are clearly emerging as cyber crime
capitals, too.”
China topped Norton’s list of countries most affected by cyber crime,
boasting an ignominious 85 percent of adults affected. The U.S. wasn’t
too far behind at 73 percent.
The fact the Internet is such a huge part of everyday life in many
countries means cyber thieves have ample prey. 24 percent of respondents
said that they “can’t live without the Internet,” while 41 percent
“need the Internet in their everyday life.” Considering that level of
dependency, it’s not too shocking that nearly 70 percent of adults
reported being the victim of some form of cyber crime.
Joseph LaBrie, an Associate Professor of Psychology at Loyola Marymount University, addressed the mental state of online users and their resistance to educating or protecting themselves.
“Often, because people feel the Internet is too complicated and the
threats are unknown or ambiguous, they default to a learned helplessness
where they simply accept cyber crime as part of the cost of going
online,” said LaBrie. “Also, they cannot visualize online protection
like they can offline security systems like a fence or alarm that act as
a physical deterrent.”
Norton asserts that each day cyber crime affects over one million
people and that 431 million people have been victims of cyber crime in
the last year alone. (via Threat Post)














 Now
that Chromebooks--portable computers based on Google's Chrome OS--are
maturing, it's easier to gauge the prospects for Google's first-ever
operating system.
Now
that Chromebooks--portable computers based on Google's Chrome OS--are
maturing, it's easier to gauge the prospects for Google's first-ever
operating system. 

{kind=link}
{kind=link}
{kind=link}