The ancient Library of Alexandria may have been the largest collection of human knowledge in its time,
and scholars still mourn its destruction. The risk of so devastating a
loss diminished somewhat with the advent of the printing press and
further still with the rise of the Internet. Yet centralized
repositories of specialized information remain, as does the threat of a
catastrophic loss.
Take GitHub, for example.
GitHub has in recent years become the world’s biggest collection of open source software.
That’s made it an invaluable education and business resource. Beyond
providing installers for countless applications, GitHub hosts the source
code for millions of projects, meaning anyone can read the code used to
create those applications. And because GitHub also archives past
versions of source code, it’s possible to follow the development of a
particular piece of software and see how it all came together. That’s
made it an irreplaceable teaching tool.
The odds of Github meeting a fate similar to that of the Library of Alexandria are slim. Indeed, rumor has it that
Github soon will see a new round of funding that will place the
company’s value at $2 billion. That should ensure, financially at least,
that GitHub will stay standing.
But GitHub’s pending emergence as Silicon Valley’s latest unicorn holds
a certain irony. The ideals of open source software center on freedom,
sharing, and collective benefit—the polar opposite of venture
capitalists seeking a multibillion-dollar exit. Whatever its stated
principles, GitHub is under immense pressure to be more than just a
sustainable business. When profit motives and community ideals clash,
especially in the software world, the end result isn’t always pretty.
Sourceforge: A Cautionary Tale
Sourceforge is another popular hub for open source software that predates GitHub by nearly a decade. It was once the place to find open source code before GitHub grew so popular.
There are many reasons for GitHub’s ascendance, but Sourceforge
hasn’t helped its own cause. In the years since career services outfit DHI Holdings acquired
it in 2012, users have lamented the spread of third-party ads that
masquerade as download buttons, tricking users into downloading
malicious software. Sourceforge has tools that enable users to report
misleading ads, but the problem has persisted. That’s part of why the
team behind GIMP, a popular open source alternative to Adobe Photoshop, quit hosting its software on Sourceforge in 2013.
Instead of trying to make nice, Sourceforge stirred up more hostility earlier this month when it declared
the GIMP project “abandoned” and began hosting “mirrors” of its
installer files without permission. Compounding the problem, Sourceforge
bundled installers with third party software some have called adware or
malware. That prompted other projects, including the popular media
player VLC, the code editor Notepad++, and WINE, a tool for running Windows apps on Linux and OS X, to abandon ship.
It’s hard to say how many projects have truly fled Sourceforge
because of the site’s tendency to “mirror” certain projects. If you
don’t count “forks” in GitHub—copies of projects developers use to make
their own tweaks to the code before submitting them to the main
project—Sourceforge may still host nearly as many projects as GitHub,
says Bill Weinberg of Black Duck Software, which tracks and analyzes
open source software.
But the damage to Sourceforge’s reputation may already have been
done. Gaurav Kuchhal, managing director of the division of DHI Holdings
that handles Sourceforge, says the company stopped its mirroring program
and will only bundle installers with projects whose
originators explicitly opt in for such add-ons. But misleading
“download” ads likely will continue to be a game of whack-a-mole as long
as Sourceforge keeps running third-party ads. In its hunt for revenue,
Sourceforge is looking less like an important collection of human
knowledge and more like a plundered museum full of dangerous traps.
No Ads (For Now)
GitHub has a natural defense against ending up like this: it’s never
been an ad-supported business. If you post your code publicly on GitHub,
the service is free. This incentivizes code-sharing and collaboration.
You pay only to keep your code private. GitHub also makes money offering
tech companies private versions of GitHub, which has worked out well:
Facebook, Google and Microsoft all do this.
Still, it’s hard to tell how much money the company makes from this
model. (It’s certainly not saying.) Yes, it has some of the world’s
largest software companies as customers. But it also hosts millions of
open source projects free of charge, without ads to offset the costs
storage, bandwidth, and the services layered on top of all those repos.
Investors will want a return eventually, through an acquisition or IPO.
Once that happens, there’s no guarantee new owners or shareholders will
be as keen on offering an ad-free loss leader for the company’s
enterprise services.
Other freemium services that have raised large rounds of funding,
like Box and Dropbox, face similar pressures. (Box even more so since
going public earlier this year.) But GitHub is more than a convenient
place to store files on the web. It’s a cornerstone of software
development—a key repository of open-source code and a crucial body of
knowledge. Amassing so much knowledge in one place raises the specter of
a catastrophic crash and burn or disastrous decay at the hands of
greedy owners loading the site with malware.
Yet GitHub has a defense mechanism the librarians of ancient
Alexandria did not. Their library also was a hub. But it didn’t have
Git.
Git Goodness
The “Git” part of GitHub is an open source technology that helps
programmers manage changes in their code. Basically, a team will place a
master copy of the code in a central location, and programmers make
copies on their own computers. These programmers then periodically merge
their changes with the master copy, the “repository” that remains the
canonical version of the project.
Git’s “versioning” makes managing projects much easier when multiple
people must make changes to the original code. But it also has an
interesting side effect: everyone who works on a GitHub project ends up
with a copy own their computers. It’s as if everyone who borrowed a book
from the library could keep a copy forever, even after returning it. If
GitHub vanished entirely, it could be rebuilt using individual users’
own copies of all the projects. It would take ages to accomplish, but it
could be done.
Still, such work would be painful. In addition to the source code
itself, GitHub is also home to countless comments, bug reports and
feature requests, not to mention the rich history of changes. But the
decentralized nature of Git does make it far easier to migrate projects
to other hosts, such as GitLab, an open source alternative to GitHub that you can run on your own server.
In short, if GitHub as we know it went away, or under future
financial pressures became an inferior version of itself, the world’s
code will survive. Libraries didn’t end with Alexandria. The question is
ultimately whether GitHub will find ways to stay true to its ideals
while generating returns—or wind up the stuff of legend.
I recently attended Facebook’s F8 developer conference
in San Francisco, where I had a revelation on why it is going to be
impossible to succeed as a technology vendor in the long run without
deeply embracing open source. Of the many great presentations I listened
to, I was most captivated by the ones that explained how Facebook
internally developed software. I was impressed by how quickly the
company is turning such important IP back into the community.
To be sure, many major Web companies like Google and Yahoo have been
leveraging open-source dynamics aggressively and contribute back to the
community. My aim is not to single out Facebook, except that it was
during the F8 conference I had the opportunity to reflect on the drivers
behind Facebook’s actions and why other technology providers may be
wise to learn from them.
Here are my 10 reasons why open-source software is effectively
becoming inevitable for infrastructure and application platform
companies:
Not reinventing the wheel: The most obvious reason
to use open-source software is to build software faster, or to
effectively stand on the shoulders of giants. Companies at the top of
their game have to move fast and grab the best that have been
contributed by a well-honed ecosystem and build their added innovation
on top of it. Doing anything else is suboptimal and will ultimately
leave you behind.
Customization with benefits: When a company is at
the top of its category, such as a social network with 1.4 billion
users, available open-source software is typically only the starting
point for a quality solution. Often the software has to be customized to
be leveraged. Contributing your customizations back to open source
allows them to be vetted and improved for your benefit.
Motivated workforce: Beyond a good wage and a
supportive work environment, there is little that can push developers to
do high-quality work more than peer approval, community recognition,
and the opportunity for fame. Turning open-source software back to the
community and allowing developers to bask in the recognition of their
peers is a powerful motivator and an important tool for employee
retention.
Attracting top talent: A similar dynamic is in play
in the hiring process as tech companies compete to build their
engineering teams. The opportunity to be visible in a broader developer
community (or to attain peer recognition and fame) is potentially more
important than getting top wages for some. Not contributing open source
back to the community narrows the talent pool for tech vendors in an
increasingly unacceptable way.
The efficiency of standardized practices: Using
open-source solutions means using standardized solutions to problems.
Such standardization of patterns of use or work enforces a normalized
set of organizational practices that will improve the work of many
engineers at other firms. Such standardization leads to more-optimized
organizations, which feature faster developer on-ramping and less wasted
time. In other words, open source brings standardized organizational
practices, which help avoid unnecessary experimentation.
Business acceleration: Even in situations where a
technology vendor is focused on bringing to market a solution as a
central business plan, open source is increasingly replacing proprietary
IP for infrastructure and application platform technologies. Creating
an innovative solution and releasing it to open source can facilitate
broader adoption of the technology with minimal investment in sales,
marketing or professional service teams. This dynamic can also be
leveraged by larger vendors to experiment in new ventures, and to
similarly create wide adoption with minimal cost.
A moat in plain sight: Creating IP in open source
allows the creators to hone their skills and learn usage patterns ahead
of the competition. The game then becomes to preserve that lead. Open
source may not provide the lock-in protection to the owner that
proprietary IP does, but the constant innovation and evolution required
in operating in open-source environments fosters fast innovation that
has now become essential to business success. Additionally, the
visibility of the source code can further enlarge the moat around its
innovation, discouraging other businesses from reinventing the wheel.
Cleaner software: Creating IP in open source also
means that the engineers have to operate in full daylight, enabling them
to avoid the traps of plagiarized software and generally stay clear of
patents. Many proprietary software companies have difficulty turning
their large codebases into open source because of necessary
time-consuming IP scrubbing processes. Open-source IP-based businesses
avoid this problem from the get-go.
Strategic safety: Basing a new product on
open-source software can go a long way to persuade customers who might
otherwise be concerned about the vendor’s financial resources or
strategic commitment to the technology. It used to be that IT
organizations only bought important (but proprietary) software from
large, established tech companies. Open source allows smaller players to
provide viable solutions by using openness as a competitive weapon to
defuse the strategic safety argument. Since the source is open, in
theory (and often only in theory) IT organizations can skill up on and
support it if and when a small vendor disappears or loses interest.
Customer goodwill: Finally, open source allows a
tech vendor to accrue a great deal of goodwill with its customers and
partners. If you are a company like Facebook, constantly and
controversially disrupting norms in social interaction and privacy,
being able to return value to the larger community through open-source
software can go a long way to making up for the negatives of your
disruption.
A year after it revealed another
attempt to muscle in on the smartphone market, Canonical’s first
Ubuntu-based smartphone is due to go on sale in Europe in the “coming
days”, it said today.
The device will be sold for €169.90 (~$190) unlocked to any carrier
network, although some regional European carriers will be offering SIM
bundles at the point of purchase. The hardware is an existing mid-tier
device, the Aquaris E4.5, made by Spain’s BQ — with the Ubuntu version
of the device known as the ‘Aquaris E4.5 Ubuntu Edition’. So the only
difference here is it will be pre-loaded with Ubuntu’s mobile software,
rather than Google’s Android platform.
Canonical has been trying to get into the mobile space for a while
now. Back in 2013, the open source software maker failed to crowdfund a
high end converged smartphone-cum-desktop-computer, called the Ubuntu Edge —
a smartphone-sized device that would been powerful enough to transform
from a pocket computer into a fully fledged desktop when plugged into a
keyboard and monitor, running Ubuntu’s full-fat desktop OS. Canonical
had sought to raise a hefty $32 million in crowdfunds to make that
project fly. Hence its more modest, mid-tier smartphone debut now.
On the hardware side, Ubuntu’s first smartphone offers pretty bog
standard mid-range specs, with a 4.5 inch screen, 1GB RAM, a quad-core
A7 chip running at “up to 1.3Ghz”, 8GB of on-board storage, 8MP rear
camera and 5MP front-facing lens, plus a dual-SIM slot. But it’s the
mobile software that’s the novelty here (demoed in action in
Canonical’s walkthrough video, embedded below).
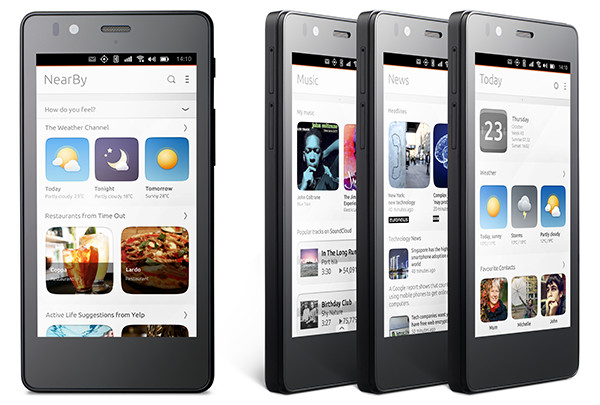
Canonical has created a gesture-based smartphone interface called
Scopes, which puts the homescreen focus on on a series of themed cards
that aggregate content and which the user swipes between to navigate
around the functions of the phone, while app icons are tucked away to
the side of the screen, or gathered together on a single Scope card.
Examples include a contextual ‘Today’ card which contains info like
weather and calendar, or a ‘Nearby’ card for location-specific local
services, or a card for accessing ‘Music’ content on the device, or
‘News’ for accessing various articles in one place.
It’s certainly a different approach to the default grid of apps found
on iOS and Android but has some overlap with other, alternative
platforms such as Palm’s WebOS, or the rebooted BlackBerry OS, or
Jolla’s Sailfish. The problem is, as with all such smaller OSes, it will
be an uphill battle for Canonical to attract developers to build
content for its platform to make it really live and breathe. (It’s got a
few third parties offering content at launch — including Songkick, The
Weather Channel and TimeOut.) And, crucially, a huge challenge to
convince consumers to try something different which requires they learn
new mobile tricks. Especially given that people can’t try before they
buy — as the device will be sold online only.
Canonical said the Aquaris E4.5 Ubuntu Edition will be made available
in a series of flash sales over the coming weeks, via BQ.com. Sales
will be announced through Ubuntu and BQ’s social media channels —
perhaps taking a leaf out of the retail strategy of Android smartphone
maker Xiaomi, which uses online flash sales to hype device launches and
shift inventory quickly. Building similar hype in a mature smartphone
market like Europe — for mid-tier hardware — is going to a Sisyphean
task. But Canonical claims to be in it for the long, uphill haul.
“We are going for the mass market,” Cristian Parrino, its VP of Mobile, told Engadget.
“But that’s a gradual process and a thoughtful process. That’s
something we’re going to be doing intelligently over time — but we’ll
get there.”
NASA officially granted permission
to a group of scientists and enthusiasts who want to do what NASA can't
afford: Make contact with a 36-year-old satellite called ISEE-3 that's
still capable of taking directions for a new mission. It's the first
agreement of its kind—and it could hint at where the space industry is
going.
So, a little back story. As our sister site io9 explained last month,
ISEE-3 was launched back in 1978 to study the relationship between the
Sun and Earth. It enjoyed many more missions over the next three
decades, but NASA officially cut the cord in 1997. Still, ISEE-3 kept on
trucking.
It
wasn't until a decade later that NASA discovered she was still at it,
despite the lack of commands from her benefactors at NASA. Why not send
her on a new mission? Well, that's the trouble: We have no way of
communicating. The antenna used to contact ISEE-3 had been removed.
Enter
the group of scientists including SkyCorp, SpaceRef, Space College
Foundation, and others. They want to use a different antenna, at
Morehead State University, to contact ISEE-3. "Our plan is simple: we
intend to contact the ISEE-3 spacecraft, command it to fire its engines
and enter an orbit near Earth, and then resume its original mission,"
said Keith Cowing, a former Nasa engineer and owner of Nasa Watch, told the Guardian.
The ISEE-3, (later ICE), undergoing testing and evaluation.
Sounds
good, right? Well, it's not so simple. The group, which calls itself
ISEE-3 Reboot, needs to essentially rebuild the entire software used to
communicate with ISEE-3 back in the 70s. That means digging through
archives to find the original commands, then recreating them. With zero
funding available from NASA and only a month or two until the little
satellite makes a close pass in mid-June. The technical challenges are
huge:
We
need to initiate a crash course effort to use 'software radio' to
recreate virtual versions all of the original communications hardware
that no longer physically exists. We also need to cover overhead
involved in operating a large dish antenna, locating and analyzing old
documentation, and possibly some travel.
But, the creators of the project explained in their pitch letter on Rockethub, "if we are successful it may also still be able to chase yet another comet."
If
there was any doubt about whether modern Americans were still enamored
with space, the results of their crowdfunding campaign squash it. The
group blew through their $100,000 goal, and are currently getting close
to a $150,000 stretch goal. There are only two days left to donate—and you should—but the fact that they've raised so much money in so short a time is remarkable.
The ISEE-3 Reboot mission patch.
NASA announced it has signed an agreement with the group called a Non-Reimbursable Space Act Agreement
(NRSAA), which is a contract it signs with its external partners to
describe a collaboration. It gives the group the green light to go ahead
and make its attempt at taking control of ISEE-3—it essence, it gives
Skycorp the right to take over the operation of a satellite that NASA
built almost 40 years ago.
Here's what astronaut John Grunsfeld had to say about the agreement:
The
intrepid ISEE-3 spacecraft was sent away from its primary mission to
study the physics of the solar wind extending its mission of discovery
to study two comets. We have a chance to engage a new generation of
citizen scientists through this creative effort to recapture the ISEE-3
spacecraft as it zips by the Earth this summer.
It's
an incredible development—and it tells us something about where space
travel and research is going. NASA and other state-funded research
entities are being strangled by downsized budgets, but the push into
space amongst independent scientists, engineers, and citizens is
booming. As Elon Musk sues to let commercial space companies compete for government contracts, students and scientists are launching their own satellites.
Over
the next few decades, plenty of other NASA-built spacecraft will begin
to age—just like ISEE-3. And unless something drastic changes about
NASA's budget, it may not have the cash to keep them up. Imagine a
future in which craft built by NASA in the 70s, 80s, and 90s, are
inherited by independent groups of scientists and space companies who
take over operations, just like Skycorp is. The privatization of space
might not be so far away—and NASA might play a heavy role in its
creation.
With its first computer based on the extremely low-power Quark
processor, Intel is tapping into the 'maker' community to figure out
ways the new chip could be best used.
The chip maker announced the Galileo computer -- which is a board
without a case -- with the Intel Quark X1000 processor on Thursday. The
board is targeted at the community of do-it-yourself enthusiasts who
make computing devices ranging from robots and health monitors to home
media centers and PCs.
The Galileo board should become widely available for under $60 by the
end of November, said Mike Bell, vice president and general manager of
the New Devices Group at Intel.
Bell hopes the maker community will use the board to build prototypes
and debug devices. The Galileo board will be open-source, and the
schematics will be released over time so it can be replicated by
individuals and companies.
Bell's New Devices Group is investigating business opportunities in
the emerging markets of wearable devices and the "Internet of things."
The chip maker launched the extremely low-power Quark processor for such
devices last month.
Intel's Quark processor.
"People want to be able to use our chips to do creative things," Bell
said. "All of the coolest devices are coming from the maker community."
But at around $60, the Galileo will be more expensive than the
popular Raspberry Pi, which is based on an ARM processor and sells for
$25. The Raspberry Pi can also render 1080p graphics, which Intel's
Galileo can't match.
Making inroads in the enthusiast community
Questions also remain on whether Intel's overtures will be accepted
by the maker community, which embraces the open-source ethos of a
community working together to tweak hardware designs. Intel has made a
lot of contributions to the Linux OS, but has kept its hardware designs
secret. Intel's efforts to reach out to the enthusiast community is
recent; the company's first open-source PC went on sale in July.
Intel is committed long-term to the enthusiast community, Bell said.
Intel also announced a partnership with Arduino, which provides a
software development environment for the Galileo motherboard. The
enthusiast community has largely relied on Arduino microcontrollers and
boards with ARM processors to create interactive computing devices.
The Galileo is equipped with a 32-bit Quark SoC X1000 CPU, which has a
clock speed of 400MHz and is based on the x86 Pentium Instruction Set
Architecture. The Galileo board supports Linux OS and the Arduino
development environment. It also supports standard data transfer and
networking interfaces such as PCI-Express, Ethernet and USB 2.0.
Intel has demonstrated its Quark chip running in eyewear and a
medical patch to check for vitals. The company has also talked about the
possibility of using the chip in personalized medicine, sensor devices
and cars.
Intel hopes creating interactive computing devices with Galileo will
be easy. Writing applications for the board is as simple as writing
programs to standard microcontrollers with support for the Arduino
development environment.
"Essentially it's transparent to the development," Bell said.
Intel is shipping out 50,000 Galileo boards for free to students at over 1,000 universities over the next 18 months.
At Velocity 2011, Nicole Sullivan and I introduced CSS Lint,
the first code-quality tool for CSS. We had spent the previous two
weeks coding like crazy, trying to create an application that was both
useful for end users and easy to modify. Neither of us had any
experience launching an open-source project like this, and we learned a
lot through the process.
After some initial missteps, the project finally hit a groove, and it
now regularly get compliments from people using and contributing to CSS
Lint. It’s actually not that hard to create a successful open-source
project when you stop to think about your goals.
(Smashing’s note: Subscribe to the Smashing eBook Library and get immediate unlimited access
to all Smashing eBooks, released in the past and in the future,
including digital versions of our printed books. At least 24 quality
eBooks a year, 60 eBooks during the first year. Subscribe today!)
What Are Your Goals?
These days, it seems that anybody who writes a piece of code ends up
pushing it to GitHub with an open-source license and says, “I’ve
open-sourced it.” Creating an open-source project isn’t just about
making your code freely available to others. So, before announcing to
the world that you have open-sourced something that hasn’t been used by
anyone other than you in your spare time, stop to ask yourself what your
goals are for the project.
The first goal is always to create something useful.
For CSS Lint, our goal was to create an extensible tool for CSS code
quality that could easily fit into a developer’s workflow, whether the
workflow is automated or not. Make sure that what you’re offering is
useful by looking for others who are doing similar projects and figuring
out how large of a user base you’re looking at.
After that, decide why you are open-sourcing the project in the first
place. Is it because you just want to share what you’ve done? Do you
intend to continue developing the code, or is this just
a snapshot that you’re putting out into the world? If you have no
intention of continuing to develop the code, then the rest of this
article doesn’t apply to you. Make sure that the readme file in your
repository states this clearly so that anyone who finds your project
isn’t confused.
If you are going to continue developing the code, do you want to accept contributions
from others? If not, then, once again, this article doesn’t apply to
you. If yes, then you have some work to do. Creating an open-source
project that’s conducive to outside contributions is more work than it
seems. You have to create environments in which those who are unfamiliar
with the project can get up to speed and be productive reasonably
quickly, and that takes some planning.
This article is about starting an open-source project with these goals:
Create something useful for the world.
Continue to develop the code for the foreseeable future.
Accept outside contributions.
Choosing A License
Before you share your code, the most important decision to make is
what license to apply. The open-source license that you choose could
greatly help or hurt your chances of attracting contributors. All
licenses allow you to retain the copyright of the code you produce.
While the concept of licensing is quite complex, there are a few common
licenses and a few basic things you should know about each. (If you are
open-sourcing a project on behalf of a company, please speak to your
legal counsel before choosing a license.)
GPL
The GNU Public License was created for the GNU project and has been
credited with the rise of Linux as a viable operating system. The GPL
license requires that any project using a GPL-licensed component must
also be made available under the GPL. To put it simply, any project
using a GPL-licensed component in any way must also be open-sourced
under the GPL. There is no restriction on the use of GPL-licensed
applications; the restriction only has to do with the modification and
distribution of derived works.
LGPL
The Lesser GPL is a slightly more permissive version of GPL. An
LGPL-licensed component may be linked to from an application without the
application itself needing to be open-sourced under GPL or LGPL. In all
other ways, LGPL is the same as GPL, so any derived works must also be
open-sourced under GPL or LGPL.
MIT
Also called X11, this licence is permissive, allowing for the use and
redistribution of code so long as the license and copyright are included
along with it. MIT-licensed code may be included in proprietary code
without any additional restrictions. Additionally, MIT-licensed code is
GPL-compatible and can be combined with such code to create new
GPL-licensed applications.
BSD3
This is also a permissive license that allows for the use and
redistribution of code as long as the license and copyright are included
with it. In addition, any redistribution of the code in binary form
must include a license and copyright in its available documentation. The
clause that sets BSD3 apart from MIT is the prohibition of using the
copyright holder’s name to promote a product that uses the code. For
example, if I wrote some code and licensed it under BSD3, then an
application that uses that code couldn’t use my name to promote the
product without my permission. BSD3-licensed code is also compatible
with GPL.
There are many other open-source licenses, but these tend to be the most commonly discussed and used.
One thing to keep in mind is that Creative Commons licenses are not
designed to be used with software. All of the Creative Commons licenses
are intended for “creative work,” including audio, images, video and
text. The Creative Commons organization itself recommends
not using Creative Commons licenses for software and instead to use
licenses that have been specifically formulated to cover software, as is
the case with the four options discussed above.
So, which license should you choose? It largely
depends on how you intend your code to be used. Because LGPL, MIT and
BSD3 are all compatible with GPL, that’s not a major concern. If you
want any modified versions of your code to be used only in open-source
software, then GPL is the way to go. If your code is designed to be a
standalone component that may be included in other applications without
modification, then you might want to consider LGPL. Otherwise, the MIT
or BSD3 licenses are popular choices. Individuals tend to favor the MIT
license, while businesses tend to favor BSD3 to ensure that their
company name can’t be used without permission.
To help you decide, look at how some popular open-source projects are licensed:
Another option is to release your code into the public domain.
Public-domain code has no copyright owner and may be used in absolutely
any way. If you have no intention of maintaining control over your code
or you just want to share your code with the world and not continue to
develop it, then consider releasing it into the public domain.
To learn more about licenses, their associated legal issues and how licensing actually works, please read David Bushell’s “Understanding Copyright and Licenses.”
Code Organization
After deciding how to license your open-source project, it’s almost
time to push your code out into the world. But before doing that, look
at how the code is organized. Not all code invites contributions.
If a potential contributor can’t figure out how to read through the
code, then it’s highly unlikely any contribution will emerge. The way
you lay out the code, in terms of file and directory structure as well
as coding style, is a key aspect to consider before sharing it publicly.
Don’t just throw out whatever code you have been writing into the wild;
spend some time figuring out how others will view your code and what
questions they might have.
For CSS Lint, we decided on a basic top-level directory structure of src for source code, lib for external dependencies, and tests for all test code. The src directory is further subdivided into directories that group together related files. All CSS Lint rules are in the rules subdirectory; all output formatters are in the formatters directory; etc. The tests directory is split up into the same subdirectories as src,
thereby indicating the relationship between the test code and the
source code. Over time, we’ve added top-level directories as needed, but
the same basic structure has been in place since the beginning.
Documentation
One of the biggest complaints about open-source projects is the lack
of documentation. Documentation isn’t as fun or exciting as writing
executable code, but it is critical to the success of an open-source
project. The best way to discourage use of and contributions to your
software is to have no documentation. This was an early mistake we made
with CSS Lint. When the project launched, we had no documentation, and
everyone was confused about how to use it. Don’t make the same mistake:
get some documentation ready before pushing the project live.
The documentation should be easy to update and shouldn’t require a
code push, because it will need to be changed very quickly in response
to user feedback. This means that the best place for documentation isn’t
in the same repository as the code. If your code is hosted on GitHub,
then make use of the built-in wiki for each project. All of the CSS Lint documentation
is in a GitHub wiki. If your code is hosted elsewhere, consider setting
up your own wiki or a similar system that enables you to update the
documentation in real time. A good documentation system must be easy to
update, or else you will never update it.
End-User Documentation
Whether you’re creating a command-line program, an application
framework, a utility library or anything else, keep the end user in
mind. The end user is not the person who will be modifying the code;
it’s the one who will be using the code. People were initially confused
about CSS Lint’s purpose and how to use it effectively because of the
lack of documentation. Your project will never gain contributors without
first gaining end users. Satisfied end users are the ones who will end
up becoming contributors because they see the value in what you’ve
created.
Developer Guide
Even if you’ve laid out the code in a logical manner and have decent
end-user documentation, contributions are not guaranteed to start
flowing. You’ll need a developer guide to help get contributors up and
running as quickly as possible. A good developer guide covers the
following:
How to get the source code
Yes, you would hope that contributors would be familiar with how to
check out and clone a repository, but that’s not always the case. A
gentle introduction to getting the source code is always appreciated.
How the code is laid out
Even though the code and directory structures should be fairly
self-explanatory, writing down a description for posterity always helps.
How to set up the build system
If you are using a build system, then you’ll need to include
instructions on how to set it up. These instructions should include
where to get build-time dependencies that aren’t already included in the
repository.
How to run a build
These are the steps necessary to run a development build and to execute unit tests.
How to contribute
Spell out the criteria for contributing to the project. If you require
unit tests, then state that. If you require documentation, mention that
as well. Give people a checklist of things to go over before submitting a
contribution.
I spent a lot of time refining the “CSS Lint Developer Guide”
based on conversations I had had with contributors and questions that
others would ask. As with all documentation, the developer guide should
be a living document that continues to grow as the project grows.
Use A Mailing List
All good open-source projects give people a place to go to ask
questions, and the easiest way to achieve that is by setting up a
mailing list. When we first launched CSS Lint, Nicole and I were
inundated with questions. The problem is that those questions were
coming in through many different channels. People were asking questions
on Twitter as well as emailing each of us directly. That’s exactly the
situation you don’t want.
Setting up a mailing list with Yahoo Groups or Google Groups
is easy and free. Make sure to do that before announcing the project’s
availability, and actively encourage people to use the mailing list to
ask questions. Link to the mailing list prominently on the website (if
you have one) or in the documentation.
The other important part of running a mailing list is to actively
monitor it. Nothing is more frustrating for end users or contributors
than being ignored. If you’ve set up a mailing list, take the time to
monitor it and respond to people who ask questions.
This is the best way to foster a community of developers around the
project. Getting a decent amount of traffic onto the mailing list can
take some time, but it’s worth the effort. Offer advice to people who
want to contribute; suggest to people to file tickets when appropriate
(don’t let the mailing list turn into a bug tracker!); and use the
feedback you get from the mailing list to improve documentation.
Use Version Numbers
One common mistake made with open-source projects is neglecting to
use version numbers. Version numbers are incredibly important for the
long-term stability and maintenance of your project. CSS Lint didn’t use
version numbers when it was first released, and I quickly realized the
mistake. When bugs came in, I had no idea whether people were using the
most recent version because there was no way for them to tell when the
code was released. Bugs were being reported that had already been fixed,
but there was no way for the end user to figure that out.
Stamping each release with an official version number puts a stake in
the ground. When somebody files a bug, you can ask what version they
are using and then check whether that bug has already been fixed. This
greatly reduced the amount of time I spent with bug reports because I
was able to quickly determine whether someone was using the most recent
version.
Unless your project has been previously used and vetted, start the
version number at 0.1.0 and go up incrementally with each release. With
CSS Lint, we increased the second number for planned releases; so, 0.2.0
was the second planned release, 0.3.0 was the third and so on. If we
needed to release a version in between planned releases in order to fix
bugs, then we increased the third number. So, the second unplanned
release after 0.2.0 was 0.2.2. Don’t get me wrong: there are no set
rules on how to increase version numbers in a project, though there are a
couple of resources worth looking at: Apache APR Versioning and Semantic Versioning. Just pick something and stick with it.
In addition to helping with tracking, version numbers do a number of other great things for your project.
Tag Versions in Source Control
When you decide on a new release, use a source-control tag to mark
the state of the code for that release. I started doing this for CSS
Lint as soon as we started using version numbers. I didn’t think much of
it until the first time I forgot to tag a release and a bug was filed
by someone looking for that tag. It turns out that developers like to
check out particular versions of code.
Tie the tag obviously to the version number by including the version
number directly in the tag’s name. With CSS Lint, our tags are in the
format of “v0.9.9.” This will make it very easy for anyone looking
through tags to figure out what those tags mean — including you, because
you’ll be able to better keep track of what changes have been made in
each release.
Change Logs
Another benefit of versioning is in producing change logs. Change
logs are important for communicating version differences to both end
users and contributors. The added benefit of tagging versions and source
control is that you can automatically generate change logs based on
those tags. CSS Lint’s build system automatically creates a change log
for each release that includes not just the commit message but also the
contributor. In this way, the change log becomes a record not only of
code changes, but also of contributions from the community.
Availability Announcements
Whenever a new version of the project is available, announce its
availability somewhere. Whether you do this on a blog or on the mailing
list (or in both places), formally announcing that a new version is
available is very important. The announcement should include any major
changes made in the code, as well as who has contributed those changes.
Contributors tend to contribute more if they get some recognition for
their work, so reward the people who have taken the time to contribute
to your project by acknowledging their contribution.
Managing Contributions
Once you have everything set up, the next step is to figure out how
you will accept contributions. Your contribution model can be as
informal or formal as you’d like, depending on your goals. For a
personal project, you might not have any formal contribution process.
The developer guide would lay out what is necessary in order for the
code to be merged into the repository and would state that as long as a
submission follows that format, then the contribution will be accepted.
For a larger project, you might want to have a more formal policy.
The first thing to look into is whether you will require a
contributor license agreement (CLA). CLAs are used in many large
open-source projects to protect the legal rights of the project. Every
person who submits code to the project would need to fill out a CLA
certifying that any contributed code is original work and that the
copyright for that work is being turned over to the project. CLAs also
give the project owner license to use the contribution as part of the
project, and it warrants that the contributor isn’t knowingly including
code to which someone else has a copyright, patent or other right. jQuery, YUI and Dojo
all require CLAs for code submissions. If you are considering requiring
a CLA from contributors, then getting legal advice regarding it and
your licensing structure would be worthwhile.
Next, you may want to establish a hierarchy of people working on the
project. Open-source projects typically have three primary designations:
Contributor
Anyone who has had source code merged into the repository is considered a
contributor. The contributor cannot access the repository directly but
has submitted patches that have been accepted.
Committer
People who have direct access to the repository are committers. These
people work on features and fix bugs regularly, and they submit code
directly to the repository.
Reviewer
The highest level of contributor, reviewers are commanders who also have
directional impact on the project. Reviewers fulfill their title by
reviewing submissions from contributors and committers, approving or
denying patches, promoting or demoting committers, and generally running
the project.
If you’re going to have a formal hierarchy such as this, you’ll need
to draft a document that describes the role of each type of contributor
and how one may be promoted through the ranks. YUI has just created a
formal “Contributor Model,” along with excellent documentation on roles and responsibilities.
At the moment, CSS Lint doesn’t require a CLA and doesn’t have a
formal contribution model in place, but everyone should consider it as
their open-source project grows.
The Proof
It probably took us about six months from its initial release to get
CSS Lint to the point of being a fully functioning open-source project.
Since then, over a dozen contributors have submitted code that is now
included in the project. While that number might seem small by the
standard of a large open-source project, we take great pride in it.
Getting one external contribution is easy; getting contributions over an
extended period of time is difficult.
And we know that we’ve been doing something right because of the
feedback we receive. Jonathan Klein recently took to the mailing list to
ask some questions and ended up submitting a pull request that was
accepted into the project. He then emailed me this feedback:
I just wanted to say that I think CSS Lint is a model open-source
project — great documentation, easy to extend, clean code, fast replies
on the mailing list and to pull requests, and easily customizable to fit
any environment. Starting to do development on CSS Lint was as easy as
reading a couple of wiki pages, and the fact that you explicitly called
out the typical workflow of a change made the barrier to entry extremely
low. I wish more open-source projects would follow suit and make it
easy to contribute.
Getting emails like this has become commonplace for CSS Lint, and it
can become the norm for your project, too, if you take the time to set
up a sustainable eco-system. We all want our projects to succeed, and we
want people to want to contribute to them. As Jonathan said, make the
barrier to entry as low as possible and developers will find ways to
help out.
Software is an integral component of a range of devices that perform critical,
lifesaving functions and basic daily tasks. As patients grow more reliant
on computerized devices, the dependability of software is a life-or-death
issue. The need to address software vulnerability is especially pressing for
Implantable Medical Devices (IMDs), which are commonly used by millions of
patients to treat chronic heart conditions, epilepsy, diabetes, obesity, and even
depression.
The software on these devices performs life-sustaining functions such as cardiac
pacing and defibrillation, drug delivery, and insulin administration. It is also
responsible for monitoring, recording and storing private patient information,
communicating wirelessly with other computers, and responding to changes in
doctors’ orders.
The Food and Drug Administration (FDA) is responsible for evaluating
the risks of new devices and monitoring the safety and efficacy of those
currently on market. However, the agency is unlikely to scrutinize the software
operating on devices during any phase of the regulatory process unless a model
that has already been surgically implanted repeatedly malfunctions or is
recalled.
The FDA has issued 23 recalls of defective devices during the first half of 2010, all of
which are categorized as “Class I,” meaning there is “reasonable probability that use
of these products will cause serious adverse health consequences or death.” At least
six of the recalls were likely caused by software defects.1 Physio-Control, Inc., a
wholly owned subsidiary of Medtronic and the manufacturer of one defibrillator that
was probably recalled due to software-related failures, admitted in a press
release that it had received reports of similar failures from patients “over the
eight year life of the product,” including one “unconfirmed adverse patient
event.”2
Despite the crucial importance of these devices and the absence of comprehensive
federal oversight, medical device software is considered the exclusive property of its
manufacturers, meaning neither patients nor their doctors are permitted to access
their IMD’s source code or test its security.3
In 2008, the Supreme Court of the United States’ ruling in Riegel v. Medtronic, Inc.
made people with IMDs even more vulnerable to negligence on the part of device
manufacturers.4 Following a wave of high-profile recalls of defective IMDs in 2005,
the Court’s decision prohibited patients harmed by defects in FDA-approved devices
from seeking damages against manufacturers in state court and eliminated the only
consumer safeguard protecting patients from potentially fatal IMD malfunctions:
product liability lawsuits. Prevented from recovering compensation from
IMD-manufacturers for injuries, lost wages, or health expenses in the wake of device
failures, people with chronic medical conditions are now faced with a stark choice:
trust manufacturers entirely or risk their lives by opting against life-saving
treatment.
We at the Software Freedom Law Center (SFLC) propose an unexplored solution to
the software liability issues that are increasingly pressing as the population of
IMD-users grows--requiring medical device manufacturers to make IMD source-code
publicly auditable. As a non-profit legal services organization for Free and
Open Source (FOSS) software developers, part of the SFLC’s mission is to
promote the use of open, auditable source code5 in all computerized technology.
This paper demonstrates why increased transparency in the field of medical
device software is in the public’s interest. It unifies various research into the
privacy and security risks of medical device software and the benefits of
published systems over closed, proprietary alternatives. Our intention is
to demonstrate that auditable medical device software would mitigate the
privacy and security risks in IMDs by reducing the occurrence of source
code bugs and the potential for malicious device hacking in the long-term.
Although there is no way to eliminate software vulnerabilities entirely, this
paper demonstrates that free and open source medical device software would
improve the safety of patients with IMDs, increase the accountability of device
manufacturers, and address some of the legal and regulatory constraints of the
current regime.
We focus specifically on the security and privacy risks of implantable medical
devices, specifically pacemakers and implantable cardioverter defibrillators, but
they are a microcosm of the wider software liability issues which must be
addressed as we become more dependent on embedded systems and devices. The
broader objective of our research is to debunk the “security through obscurity”
misconception by showing that vulnerabilities are spotted and fixed faster in
FOSS programs compared to proprietary alternatives. The argument for
public access to source code of IMDs can, and should be, extended to all the
software people interact with everyday. The well-documented recent incidents of
software malfunctions in voting booths, cars, commercial airlines, and financial
markets are just the beginning of a problem that can only be addressed by
requiring the use of open, auditable source code in safety-critical computerized
devices.6
In section one, we give an overview of research related to potentially fatal software
vulnerabilities in IMDs and cases of confirmed device failures linked to source code
vulnerabilities. In section two, we summarize research on the security benefits of
FOSS compared to closed-source, proprietary programs. In section three, we assess
the technical and legal limitations of the existing medical device review process and
evaluate the FDA’s capacity to assess software security. We conclude with our
recommendations on how to promote the use of FOSS in IMDs. The research
suggests that the occurrence of privacy and security breaches linked to software
vulnerabilities is likely to increase in the future as embedded devices become more
common.
II Software Vulnerabilities in IMDs
A variety of wirelessly reprogrammable IMDs are surgically implanted directly into
the body to detect and treat chronic health conditions. For example, an implantable
cardioverter defibrillator, roughly the size of a small mobile phone, connects to a
patient’s heart, monitors rhythm, and delivers an electric shock when it detects
abnormal patterns. Once an IMD has been implanted, health care practitioners
extract data, such as electrocardiogram readings, and modify device settings
remotely, without invasive surgery. New generation ICDs can be contacted and
reprogrammed via wireless radio signals using an external device called a
“programmer.”
In 2008, approximately 350,000 pacemakers and 140,000 ICDs were implanted in the
United States, according to a forecast on the implantable medical device market
published earlier this year.7 Nation-wide demand for all IMDs is projected to increase
8.3 percent annually to $48 billion by 2014, the report says, as “improvements
in safety and performance properties …enable ICDs to recapture growth
opportunities lost over the past year to product recall.”8 Cardiac implants in
the U.S. will increase 7.3 percent annually, the article predicts, to $16.7
billion in 2014, and pacing devices will remain the top-selling group in this
category.9
Though the surge in IMD treatment over the past decade has had undeniable health
benefits, device failures have also had fatal consequences. From 1997 to 2003, an
estimated 400,000 to 450,000 ICDs were implanted world-wide and the majority of
the procedures took place in the United States. At least 212 deaths from device
failures in five different brands of ICD occurred during this period, according to a
study of the adverse events reported to the FDA conducted by cardiologists from the
Minneapolis Heart Institute Foundation.10
Research indicates that as IMD usage grows, the frequency of potentially fatal
software glitches, accidental device malfunctions, and the possibility of malicious
attacks will grow. While there has yet to be a documented incident in which the
source code of a medical device was breached for malicious purposes, a 2008-study
led by software engineer and security expert Kevin Fu proved that it is possible to
interfere with an ICD that had passed the FDA’s premarket approval process and
been implanted in hundreds of thousands of patients. A team of researchers from
three universities partially reverse-engineered the communications protocol of a
2003-model ICD and launched several radio-based software attacks from a short
distance. Using low-cost, commercially available equipment to bypass the device
programmer, the researchers were able to extract private data stored inside the ICD
such as patients’ vital signs and medical history; “eavesdrop” on wireless
communication with the device programmer; reprogram the therapy settings that
detect and treat abnormal heart rhythms; and keep the device in “awake” mode
in order to deplete its battery, which can only be replaced with invasive
surgery.
In one experimental attack conducted in the study, researchers were able to first
disable the ICD to prevent it from delivering a life-saving shock and then direct the
same device to deliver multiple shocks averaging 137.7 volts that would induce
ventricular fibrillation in a patient. The study concluded that there were no
“technological mechanisms in place to ensure that programmers can only be operated
by authorized personnel.” Fu’s findings show that almost anyone could use
store-bought tools to build a device that could “be easily miniaturized to the size of
an iPhone and carried through a crowded mall or subway, sending its heart-attack
command to random victims.”11
The vulnerabilities Fu’s lab exploited are the result of the very same features that
enable the ICD to save lives. The model breached in the experiment was designed to
immediately respond to reprogramming instructions from health-care practitioners,
but is not equipped to distinguish whether treatment requests originate from a
doctor or an adversary. An earlier paper co-authored by Fu proposed a solution to
the communication-security paradox. The paper recommends the development of a
wearable “cloaker” for IMD-patients that would prevent anyone but pre-specified,
authorized commercial programmers to interact with the device. In an emergency
situation, a doctor with a previously unauthorized commercial programmer would be
able to enable emergency access to the IMD by physically removing the cloaker from
the patient.12
Though the adversarial conditions demonstrated in Fu’s studies were hypothetical,
two early incidents of malicious hacking underscore the need to address the threat
software liabilities pose to the security of IMDs. In November 2007, a group of
attackers infiltrated the Coping with Epilepsy website and planted flashing computer
animations that triggered migraine headaches and seizures in photosensitive site
visitors.13 A year later, malicious hackers mounted a similar attack on the Epilepsy
Foundation website.14
Ample evidence of software vulnerabilities in other common IMD treatments also
indicates that the worst-case scenario envisioned by Fu’s research is not unfounded.
From 1983 to 1997 there were 2,792 quality problems that resulted in recalls of
medical devices, 383 of which were related to computer software, according to a 2001
study analyzing FDA reports of the medical devices that were voluntarily recalled by
manufacturers over a 15-year period.15 Cardiology devices accounted for
21 percent of the IMDs that were recalled. Authors Dolores R. Wallace
and D. Richard Kuhn discovered that 98 percent of the software failures
they analyzed would have been detected through basic scientific testing
methods. While none of the failures they researched caused serious personal
injury or death, the paper notes that there was not enough information to
determine the potential health consequences had the IMDs remained in
service.
Nearly 30 percent of the software-related recalls investigated in the report occurred
between 1994 and 1996. “One possibility for this higher percentage in later years may
be the rapid increase of software in medical devices. The amount of software in
general consumer products is doubling every two to three years,” the report
said.
As more individual IMDs are designed to automatically communicate wirelessly with
physician’s offices, hospitals, and manufacturers, routine tasks like reprogramming,
data extraction, and software updates may spur even more accidental software
glitches that could compromise the security of IMDs.
The FDA launched an “Infusion Pump Improvement Initiative” in April 2010, after
receiving thousands of reports of problems associated with the use of infusion pumps
that deliver fluids such as insulin and chemotherapy medication to patients
electronically and mechanically.16 Between 2005 and 2009, the FDA received
approximately 56,000 reports of adverse events related to infusion pumps,
including numerous cases of injury and death. The agency analyzed the reports
it received during the period in a white paper published in the spring of
2010 and found that the most common types of problems reported were
associated with software defects or malfunctions, user interface issues, and
mechanical or electrical failures. (The FDA said most of the pumps covered
in the report are operated by a trained user, who programs the rate and
duration of fluid delivery through a built-in software interface). During the
period, 87 infusion pumps were recalled due to safety concerns, 14 of which
were characterized as “Class I” – situations in which there is a reasonable
probability that use of the recalled device will cause serious adverse health
consequences or death. Software defects lead to over-and-under infusion and
caused pre-programmed alarms on pumps to fail in emergencies or activate in
absence of a problem. In one instance a “key bounce” caused an infusion pump
to occasionally register one keystroke (e.g., a single zero, “0”) as multiple
keystrokes (e.g., a double zero, “00”), causing an inappropriate dosage to be
delivered to a patient. Though the report does not apply to implantable infusion
pumps, it demonstrates the prevalence of software-related malfunctions in
medical device software and the flexibility of the FDA’s pre-market approval
process.
In order to facilitate the early detection and correction of any design defects, the
FDA has begun offering manufacturers “the option of submitting the software code
used in their infusion pumps for analysis by agency experts prior to premarket review
of new or modified devices.” It is also working with third-party researchers to
develop “an open-source software safety model and reference specifications that
infusion pump manufacturers can use or adapt to verify the software in their
devices.”
Though the voluntary initiative appears to be an endorsement of the safety benefits
of FOSS and a step in the right direction, it does not address the overall problem of
software insecurity since it is not mandatory.
III Why Free Software is More Secure
“Continuous and broad peer-review, enabled by publicly available source code,
improves software reliability and security through the identification and elimination
of defects that might otherwise go unrecognized by the core development team.
Conversely, where source code is hidden from the public, attackers can attack the
software anyway …. Hiding source code does inhibit the ability of third parties to
respond to vulnerabilities (because changing software is more difficult without the
source code), but this is obviously not a security advantage. In general, ‘Security by
Obscurity’ is widely denigrated.” — Department of Defense (DoD) FAQ’s response to
question: “Doesn’t Hiding Source Code Automatically Make Software More
Secure?”17
The DoD indicates that FOSS has been central to its Information Technology
(IT) operations since the mid-1990’s, and, according to some estimates,
one-third to one-half of the software currently used by the agency is open
source.18 The U.S. Office of Management and Budget issued a memorandum in
2004, which recommends that all federal agencies use the same procurement
procedures for FOSS as they would for proprietary software.19 Other public sector
agencies, such as the U.S. Navy, the Federal Aviation Administration, the
U.S. Census Bureau and the U.S. Patent and Trademark Office have been
identified as recognizing the security benefits of publicly auditable source
code.20
To understand why free and open source software has become a common component
in the IT systems of so many businesses and organizations that perform life-critical
or mission-critical functions, one must first accept that software bugs are a fact of
life. The Software Engineering Institute estimates that an experienced software
engineer produces approximately one defect for every 100 lines of code.21 Based on
this estimate, even if most of the bugs in a modest, one million-line code base are
fixed over the course of a typical program life cycle, approximately 1,000 bugs would
remain.
In its first “State of Software Security” report released in March 2010, the private
software security analysis firm Veracode reviewed the source code of 1,591 software
applications voluntarily submitted by commercial vendors, businesses, and
government agencies.22 Regardless of program origins, Veracode found that
58 percent of all software submitted for review did not meet the security
assessment criteria the report established.23 Based on its findings, Veracode
concluded that “most software is indeed very insecure …[and] more than half of
the software deployed in enterprises today is potentially susceptible to an
application layer attack similar to that used in the recent …Google security
breaches.”24
Though open source applications had almost as many source code vulnerabilities
upon first submission as proprietary programs, researchers found that they contained
fewer potential backdoors than commercial or outsourced software and that open
source project teams remediated security vulnerabilities within an average of 36 days
of the first submission, compared to 48 days for internally developed applications and
82 days for commercial applications.25 Not only were bugs patched the fastest in
open source programs, but the quality of remediation was also higher than
commercial programs.26
Veracode’s study confirms the research and anecdotal evidence into the security
benefits of open source software published over the past decade. According to the
web-security analysis site SecurityPortal, vulnerabilities took an average of 11.2 days
to be spotted in Red Hat/Linux systems with a standard deviation of 17.5 compared
to an average of 16.1 days with a standard deviation of 27.7 in Microsoft
programs.27
Sun Microsystems’ COO Bill Vass summed up the most common case for FOSS in a
blog post published in April 2009: “By making the code open source, nothing can be
hidden in the code,” Vass wrote. “If the Trojan Horse was made of glass, would the
Trojans have rolled it into their city? NO.”28
Vass’ logic is backed up by numerous research papers and academic studies that have
debunked the myth of security through obscurity and advanced the “more eyes, fewer
bugs” thesis. Though it might seem counterintuitive, making source code publicly
available for users, security analysts, and even potential adversaries does not make
systems more vulnerable to attack in the long-run. To the contrary, keeping
source code under lock-and-key is more likely to hamstring “defenders” by
preventing them from finding and patching bugs that could be exploited by
potential attackers to gain entry into a given code base, whether or not access is
restricted by the supplier.29 “In a world of rapid communications among
attackers where exploits are spread on the Internet, a vulnerability known to
one attacker is rapidly learned by others,” reads a 2006 article comparing
open source and proprietary software use in government systems.30 “For
Open Source, the next assumption is that disclosure of a flaw will prompt
other programmers to improve the design of defenses. In addition, disclosure
will prompt many third parties — all of those using the software or the
system — to install patches or otherwise protect themselves against the
newly announced vulnerability. In sum, disclosure does not help attackers
much but is highly valuable to the defenders who create new code and install
it.”
Academia and internet security professionals appear to have reached a consensus that
open, auditable source code gives users the ability to independently assess the
exposure of a system and the risks associated with using it; enables bugs to be
patched more easily and quickly; and removes dependence on a single party, forcing
software suppliers and developers to spend more effort on the quality of their code, as
authors Jaap-Henk Hoepman and Bart Jacobs also conclude in their 2007 article,
Increased Security Through Open Source.31
By contrast, vulnerabilities often go unnoticed, unannounced, and unfixed in closed
source programs because the vendor, rather than users who have a higher stake in
maintaining the quality of software, is the only party allowed to evaluate the security
of the code base.32 Some studies have argued that commercial software suppliers have
less of an incentive to fix defects after a program is initially released so users do not
become aware of vulnerabilities until after they have caused a problem. “Once the
initial version of [a proprietary software product] has saturated its market, the
producer’s interest tends to shift to generating upgrades …Security is difficult to
market in this process because, although features are visible, security functions tend
to be invisible during normal operations and only visible when security trouble
occurs.”33
The consequences of manufacturers’ failure to disclose malfunctions to patients and
physicians have proven fatal in the past. In 2005, a 21-year-old man died from cardiac
arrest after the ICD he wore short-circuited and failed to deliver a life-saving shock.
The fatal incident prompted Guidant, the manufacturer of the flawed ICD,
to recall four different device models they sold. In total 70,000 Guidant
ICDs were recalled in one of the biggest regulatory actions of the past 25
years.34
Guidant came under intense public scrutiny when the patient’s physician Dr. Robert
Hauser discovered that the company first observed the flaw that caused his patient’s
device to malfunction in 2002, and even went so far as to implement manufacturing
changes to correct it, but failed to disclose it to the public or health-care
industry.
The body of research analyzed for this paper points to the same conclusion: security
is not achieved through obscurity and closed source programs force users to
forfeit their ability to evaluate and improve a system’s security. Though there
is lingering debate over the degree to which end-users contribute to the
maintenance of FOSS programs and how to ensure the quality of the patches
submitted, most of the evidence supports our paper’s central assumption that
auditable, peer-reviewed software is comparatively more secure than proprietary
programs.
Programs have different standards to ensure the quality of the patches submitted to
open source programs, but even the most open, transparent systems have established
methods of quality control. Well-established open source software, such as the
kind favored by the DoD and the other agencies mentioned above, cannot
be infiltrated by “just anyone.” To protect the code base from potential
adversaries and malicious patch submissions, large open source systems have a
“trusted repository” that only certain, “trusted,” developers can directly
modify. As an additional safeguard, the source code is publicly released,
meaning not only are there more people policing it for defects, but more
copies of each version of the software exist making it easier to compare new
code.
IV The FDA Review Process and Legal Obstacles to Device Manufacturer
Accountability
“Implanted medical devices have enriched and extended the lives of countless people,
but device malfunctions and software glitches have become modern ‘diseases’ that
will continue to occur. The failure of manufacturers and the FDA to provide the
public with timely, critical information about device performance, malfunctions, and
’fixes’ enables potentially defective devices to reach unwary consumers.” — Capitol
Hill Hearing Testimony of William H. Maisel, Director of Beth Israel Deaconess
Medical Center, May 12, 2009.
The FDA’s Center for Devices and Radiological Health (CDRH) is responsible for
regulating medical devices, but since the Medical Device Modernization Act
(MDMA) was passed in 1997 the agency has increasingly ceded control over
the pre-market evaluation and post-market surveillance of IMDs to their
manufacturers.35 While the agency has been making strides towards the MDMA’s
stated objective of streamlining the device approval process, the expedient regulatory
process appears to have come at the expense of the CDRH’s broader mandate to
“protect the public health in the fields of medical devices” by developing and
implementing programs “intended to assure the safety, effectiveness, and proper
labeling of medical devices.”36
Since the MDMA was passed, the FDA has largely deferred these responsibilities to
the companies that sell these devices.37 The legislation effectively allowed the
businesses selling critical devices to establish their own set of pre-market
safety evaluation standards and determine the testing conducted during the
review process. Manufacturers also maintain a large degree of discretion over
post-market IMD surveillance. Though IMD-manufacturers are obligated to
inform the FDA if they alert physicians to a product defect or if the device is
recalled, they determine whether a particular defect constitutes a public safety
risk.
“Manufacturers should use good judgment when developing their quality system and
apply those sections of the QS regulation that are applicable to their specific
products and operations,” reads section 21 of Quality Standards regulation
outlined on the FDA’s website. “Operating within this flexibility, it is the
responsibility of each manufacturer to establish requirements for each type
or family of devices that will result in devices that are safe and effective,
and to establish methods and procedures to design, produce, distribute,
etc. devices that meet the quality system requirements. The responsibility for
meeting these requirements and for having objective evidence of meeting these
requirements may not be delegated even though the actual work may be
delegated.”
By implementing guidelines such as these, the FDA has refocused regulation from
developing and implementing programs in the field of medical devices that protect
the public health to auditing manufacturers’ compliance with their own
standards.
“To the FDA, you are the experts in your device and your quality programs,” Jeff
Geisler wrote in a 2010 book chapter, Software for Medical Systems.38 “Writing down
the procedures is necessary — it is assumed that you know best what the
procedures should be — but it is essential that you comply with your written
procedures.”
The elastic regulatory standards are a product of the 1976 amendment to the Food,
Drug, and Cosmetics Act.39The Amendment established three different device classes
and outlined broad pre-market requirements that each category of IMD must meet
depending on the risk it poses to a patient. Class I devices, whose failure
would have no adverse health consequences, are not subject to a pre-market
approval process. Class III devices that “support or sustain human life, are of
substantial importance in preventing impairment of human health, or which
present a potential, unreasonable risk of illness or injury,” such as IMDs, are
subject to the most stringent FDA review process, Premarket Approval
(PMA).40
By the FDA’s own admission, the original legislation did not account for
technological complexity of IMDs, but neither has subsequent regulation.41
In 2002, an amendment to the MDMA was passed that was intended to help the
FDA “focus its limited inspection resources on higher-risk inspections and give
medical device firms that operate in global markets an opportunity to more efficiently
schedule multiple inspections,” the agency’s website reads.42
The legislation further eroded the CDRH’s control over pre-market approval
data, along with the FDA’s capacity to respond to rapid changes in medical
treatment and the introduction of increasingly complex devices for a broader
range of diseases. The new provisions allowed manufacturers to pay certain
FDA-accredited inspectors to conduct reviews during the PMA process in
lieu of government regulators. It did not outline specific software review
procedures for the agency to conduct or precise requirements that medical device
manufacturers must meet before introducing a new product. “The regulation
…provides some guidance [on how to ensure the reliability of medical device
software],” Joe Bremner wrote of the FDA’s guidance on software validation.43
“Written in broad terms, it can apply to all medical device manufacturers.
However, while it identifies problems to be solved or an end point to be
achieved, it does not specify how to do so to meet the intent of the regulatory
requirement.”
The death of 21-year-old Joshua Oukrop in 2005 due to the failure of a
Guidant device has increased calls for regulatory reform at the FDA.44 In a
paper published shortly after Oukrop’s death, his physician, Dr. Hauser
concluded that the FDA’s post-market ICD device surveillance system is
broken.45
After returning the failed Prizm 2 DR pacemaker to Guidant, Dr. Hauser learned
that the company had known the model was prone to the same defect that killed
Oukrop for at least three years. Since 2002, Guidant received 25 different reports of
failures in the Prizm model, three of which required rescue defibrillation. Though the
company was sufficiently concerned about the problem to make manufacturing
changes, Guidant continued to sell earlier models and failed to make patients and
physicians aware that the Prizm was prone to electronic defects. They claimed that
disclosing the defect was inadvisable because the risk of infection during
de-implantation surgery posed a greater threat to public safety than device
failure. “Guidant’s statistical argument ignored the basic tenet that patients
have a fundamental right to be fully informed when they are exposed to the
risk of death no matter how low that risk may be perceived,” Dr. Hauser
argued. “Furthermore, by withholding vital information, Guidant had in effect
assumed the primary role of managing high-risk patients, a responsibility that
belongs to physicians. The prognosis of our young, otherwise healthy patient
for a long, productive life was favorable if sudden death could have been
prevented.”
The FDA was also guilty of violating the principle of informed consent. In 2004,
Guidant had reported two different adverse events to the FDA that described the
same defect in the Prizm 2 DR models, but the agency also withheld the information
from the public. “The present experience suggests that the FDA is currently
unable to satisfy its legal responsibility to monitor the safety of market
released medical devices like the Prizm 2 DR,” he wrote, referring to the
device whose failure resulted in his patient’s death. “The explanation for
the FDA’s inaction is unknown, but it may be that the agency was not
prepared for the extraordinary upsurge in ICD technology and the extraordinary
growth in the number of implantations that has occurred in the past five
years.”
While the Guidant recalls prompted increased scrutiny on the FDA’s medical device
review process, it remains difficult to gauge the precise process of regulating IMD
software or the public health risk posed by source code bugs since neither doctors,
nor IMD users, are permitted to access it. Nonetheless, the information that does
exist suggests that the pre-market approval process alone is not a sufficient consumer
safeguard since medical devices are less likely than drugs to have demonstrated
clinical safety before they are marketed.46
An article published in the Journal of the American Medical Association
(JAMA) studied the safety and effectiveness data in every PMA application
the FDA reviewed from January 2000 to December 2007 and concluded
that “premarket approval of cardiovascular devices by the FDA is often
based on studies that lack strength and may be prone to bias.”47 Of the 78
high-risk device approvals analyzed in the paper, 51 were based on a single
study.48
The JAMA study noted that the need to address the inadequacies of the FDA’s
device regulation process has become particularly urgent since the Supreme Court
changed the landscape of medical liability law with its ruling in Riegel v. Medtronic
in February 2008. The Court held that the plaintiff Charles Riegel could not seek
damages in state court from the manufacturer of a catheter that exploded in his leg
during an angioplasty. “Riegel v. Medtronic means that FDA approval of a
device preempts consumers from suing because of problems with the safety or
effectiveness of the device, making this approval a vital consumer protection
safeguard.”49
Since the FDA is a federal agency, its authority supersedes state law. Based on the
concept of preemption, the Supreme Court held that damages actions permitted
under state tort law could not be filed against device manufacturers deemed to be in
compliance with the FDA, even in the event of gross negligence. The decision eroded
one of the last legal recourses to protect consumers and hold IMD manufacturers
accountable for catastrophic, failure of an IMD. Not only are the millions of people
who rely on IMD’s for their most life-sustaining bodily functions more vulnerable to
software malfunctions than ever before, but they have little choice but to trust its
manufacturers.
“It is clear that medical device manufacturers have responsibilities that extend far
beyond FDA approval and that many companies have failed to meet their
obligations,” William H. Maisel said in recent congressional testimony on the
Medical Device Reform bill.50 “Yet, the U.S. Supreme Court ruled in their February
2008 decision, Riegel v. Medtronic, that manufacturers could not be sued under state
law by patients harmed by product defects from FDA-approved medical devices ….
[C]onsumers are unable to seek compensation from manufacturers for their injuries,
lost wages, or health expenses. Most importantly, the Riegel decision eliminates an
important consumer safeguard — the threat of manufacturer liability — and
will lead to less safe medical devices and an increased number of patient
injuries.”
In light of our research and the existing legal and regulatory limitations that prevent
IMD users from holding medical device manufacturers accountable for critical
software vulnerabilities, auditable source code is critical to minimize the harm caused
by inevitable medical device software bugs.
V Conclusion
The Supreme Court’s decision in favor of Medtronic in 2008, increasingly flexible
regulation of medical device software on the part of the FDA, and a spike in the level
and scope of IMD usage over the past decade suggest a software liability nightmare
on the horizon. We urge the FDA to introduce more stringent, mandatory standards
to protect IMD-wearers from the potential adverse consequences of software
malfunctions discussed in this paper. Specifically, we call on the FDA to require
manufacturers of life-critical IMDs to publish the source code of medical device
software so the public and regulators can examine and evaluate it. At the very
least, we urge the FDA to establish a repository of medical device software
running on implanted IMDs in order to ensure continued access to source code
in the event of a catastrophic failure, such as the bankruptcy of a device
manufacturer. While we hope regulators will require that the software of all
medical devices, regardless of risk, be auditable, it is particularly urgent that
these standards be included in the pre-market approval process of Class III
IMDs. We hope this paper will also prompt IMD users, their physicians, and
the public to demand greater transparency in the field of medical device
software.
Notes
1Though software defects are never explicitly mentioned as the “Reason for Recall” in the alertsposted on the FDA’s website, the descriptions of device failures match those associated withsouce-code errors. List of Device Recalls, U.S. Food & Drug Admin., http://www.fda.gov/MedicalDevices/Safety/RecallsCorrectionsRemovals/ListofRecalls/default.htm(last visited Jul. 19, 2010).
2Medtronic recalled its Lifepak 15 Monitor/Defibrillator in March 4, 2010 due to failures thatwere almost certainly caused by software defects that caused the device to unexpectedlyshut-down and regain power on its own. The company admitted in a press release thatit first learned that the recalled model was prone to defects eight years earlier and hadsubmitted one “adverse event” report to the FDA. Medtronic, Physio-Control Field Correctionto LIFEPAK20/20e Defibrillator/ Monitors, BusinessWire(Jul. 02, 2010, 9:00 AM),http://www.businesswire.com/news/home/20100702005034/en/Physio-Control-Field-Correction-LIFEPAK%C2%AE-2020e-Defibrillator-Monitors.html
3Quality Systems Regulation, U.S. Food & DrugAdmin., http://www.fda.gov/MedicalDevices/default.htm(follow “Device Advice: DeviceRegulation and Guidance” hyperlink; then follow “Postmarket Requirements (Devices)”hyperlink; then follow “Quality Systems Regulation” hyperlink) (last visited Jul. 2010)
5The Software Freedom Law Center (SFLC) prefers the term Free and Open Source Software(FOSS) to describe software that can be freely viewed, used, and modified by anyone. In thispaper, we sometimes use mixed terminology, including the term “open source” to maintainconsistency with the articles cited.
6See Josie Garthwaite, Hacking the Car: Cyber Security Risks Hit the Road, Earth2Tech(Mar. 19, 2010, 12:00 AM), http://earth2tech.com.
7Sanket S. Dhruva et al., Strength of Study Evidence Examined by the FDA in PremarketApproval of Cardiovascular Devices, 302 J. Am. Med. Ass’n2679 (2009).
10RobertG. Hauser & Linda Kallinen, Deaths Associated With Implantable Cardioverter DefibrillatorFailure and Deactivation Reported in the United States Food and Drug AdministrationManufacturer and User Facility Device Experience Database, 1 HeartRhythm399, availableat http://www.heartrhythmjournal.com/article/S1547-5271%2804%2900286-3/.
Everyone likes personal cloud services, like Apple’s iCloud, Google Music, and Dropbox.
But, many of aren’t crazy about the fact that our files, music, and
whatever are sitting on someone else’s servers without our control.
That’s where ownCloud comes in.
OwnCloud is an open-source cloud program. You use it to set up your
own cloud server for file-sharing, music-streaming, and calendar,
contact, and bookmark sharing project. As a server program it’s not that
easy to set up. OpenSUSE, with its Mirall installation program and desktop client makes it easier to set up your own personal ownCloud, but it’s still not a simple operation. That’s going to change.
According to ownCloud’s business crew,
“OwnCloud offers the ease-of-use and cost effectiveness of Dropbox and
box.net with a more secure, better managed offering that, because it’s
open source, offers greater flexibility and no vendor lock in. This
makes it perfect for business use. OwnCloud users can run file sync and
share services on their own hardware and storage or use popular public
hosting and storage offerings.” I’ve tried it myself and while setting
it up is still mildly painful, once up ownCloud works well.
OwnCloud enables universal access to files through a Web browser or WebDAV.
It also provides a platform to easily view and sync contacts, calendars
and bookmarks across all devices and enables basic editing right on the
Web. Programmers will be able to add features to it via its open
application programming interface (API).
OwnCloud is going to become an easy to run and use personal, private
cloud thanks to a new commercial company that’s going to take ownCloud
from interesting open-source project to end-user friendly program. This
new company will be headed by former SUSE/Novell executive Markus Rex.
Rex, who I’ve known for years and is both a business and technology
wizard, will serve as both CEO and CTO. Frank Karlitschek, founder of
the ownCloud project, will be staying.
To make this happen, this popular–350,000 users-program’s commercial
side is being funded by Boston-based General Catalyst, a high-tech.
venture capital firm. In the past, General Catalyst has helped fund such
companies as online travel company Kayak and online video platform leader Brightcove.
General Catalyst came on board, said John Simon, Managing Director at
General Catalyst in a statement, because, “With the explosion of
unstructured data in the enterprise and increasingly mobile (and
insecure) ways to access it, many companies have been forced to lock
down their data–sometimes forcing employees to find less than secure
means of access, or, if security is too restrictive, risk having all
that unavailable When we saw the ease-of-use, security and flexibility
of ownCloud, we were sold.”
“In a cloud-oriented world, ownCloud is the only tool based on a
ubiquitous open-source platform,” said Rex, in a statement. “This
differentiator enables businesses complete, transparent, compliant
control over their data and data storage costs, while also allowing
employees simple and easy data access from anywhere.”
As a Linux geek, I already liked ownCloud. At the company releases
mass-market ownCloud products and service in 2012, I think many of you
are going to like it as well. I’m really looking forward to seeing where
this program goes from here.
“Apps that are released under an Open Source
Initiative-recognised open source licence can, at least in the
pre-release version of the Windows Store, be distributed according to
terms that contradict Microsoft’s Standard Application License Terms if
this is required by the open source licence. Among other things, the
Standard Application License Terms prohibit the sharing of
applications.”
Microsoft officials shared more details about the coming Windows Store
earlier this week. Metro-style applications will be licensable,
marketable and downloadable from the Windows 8 Store. Non-Metro-style
Desktop Apps will only be marketable from inside the store, with links
provided to developers’ sites for sales/downloads.
I’ve had a few developers ask me whether Microsoft will allow the use
of open-source languages/development environments — like PHP, Ruby,
Python, Eclipse, etc. — to create Windows 8 apps. The Windows 8
architectural diagrams (from Microsoft and others) make me believe the
answer is no, even though HTML5/JavaScript/CSS are all supported (and
treated as better than first-class citizens in Windows 8)….Anyone know
otherwise?
Recently, you may have heard about new efforts to bring online access
to regions where it has been economically nonviable before. This idea
is not new, of course. The One Laptop Per Child (OLPC) initiative was
squarely aimed at the goal until it ran into some significant hiccups. One of the latest moves on this front comes from Geeks Without Frontiers,
which has a stated goal of positively impacting one billion lives with
technology over the next 10 years. The organization, sponsored by
Google and The Tides Foundation, is working on low cost, open source
Wi-Fi solutions for "areas where legacy broadband models are currently
considered to be uneconomical."
"GEEKS
expects that this technology, built mainly by Cozybit, managed by
GEEKS and I-Net Solutions, and sponsored by Google, Global Connect,
Nortel, One Laptop Per Child, and the Manna Energy Foundation, will
enable the development and rollout of large-scale mesh Wi-Fi networks
for atleast half of the traditional network cost. This is a major step
in achieving the vision of affordable broadband for all."
It's
notable that One Laptop Per Child is among the sponsors of this
initiative. The organization has open sourced key parts of its software
platform, and could have natural synergies with a global Wi-Fi effort.
“By
driving down the cost of metropolitan and village scale Wi-Fi
networks, millions more people will be able to reap the economic and
social benefits of significantly lower cost Internet access,” said
Michael Potter, one of the founders of the GEEKS initiative.
The Wi-Fi technology that GEEKS is pursuing is mesh networking technology. Specifically, open80211s (o11s),
which implements the AMPE (Authenticated Mesh Peering Exchange)
enabling multiple authenticated nodes to encrypt traffic between
themselves. Mesh networks are essentially widely distributed wireless
networks based on many repeaters throught a specific location.
You can read much more about the open80211s standard here.
The GEEKS initiative has significant backers, and with sponsorship from
OLPC, will probably benefit from good advice on the topic of bringing
advanced technologies to disadvantaged regions of the world. The effort
will be worth watching.