Entries tagged as software
Tuesday, June 30. 2015
The Problem With Putting All the World’s Code in GitHub
Via Wired
-----

The ancient Library of Alexandria may have been the largest collection of human knowledge in its time, and scholars still mourn its destruction. The risk of so devastating a loss diminished somewhat with the advent of the printing press and further still with the rise of the Internet. Yet centralized repositories of specialized information remain, as does the threat of a catastrophic loss.
Take GitHub, for example.
GitHub has in recent years become the world’s biggest collection of open source software. That’s made it an invaluable education and business resource. Beyond providing installers for countless applications, GitHub hosts the source code for millions of projects, meaning anyone can read the code used to create those applications. And because GitHub also archives past versions of source code, it’s possible to follow the development of a particular piece of software and see how it all came together. That’s made it an irreplaceable teaching tool.
The odds of Github meeting a fate similar to that of the Library of Alexandria are slim. Indeed, rumor has it that Github soon will see a new round of funding that will place the company’s value at $2 billion. That should ensure, financially at least, that GitHub will stay standing.
But GitHub’s pending emergence as Silicon Valley’s latest unicorn holds a certain irony. The ideals of open source software center on freedom, sharing, and collective benefit—the polar opposite of venture capitalists seeking a multibillion-dollar exit. Whatever its stated principles, GitHub is under immense pressure to be more than just a sustainable business. When profit motives and community ideals clash, especially in the software world, the end result isn’t always pretty.
Sourceforge: A Cautionary Tale
Sourceforge is another popular hub for open source software that predates GitHub by nearly a decade. It was once the place to find open source code before GitHub grew so popular.
There are many reasons for GitHub’s ascendance, but Sourceforge hasn’t helped its own cause. In the years since career services outfit DHI Holdings acquired it in 2012, users have lamented the spread of third-party ads that masquerade as download buttons, tricking users into downloading malicious software. Sourceforge has tools that enable users to report misleading ads, but the problem has persisted. That’s part of why the team behind GIMP, a popular open source alternative to Adobe Photoshop, quit hosting its software on Sourceforge in 2013.
Instead of trying to make nice, Sourceforge stirred up more hostility earlier this month when it declared the GIMP project “abandoned” and began hosting “mirrors” of its installer files without permission. Compounding the problem, Sourceforge bundled installers with third party software some have called adware or malware. That prompted other projects, including the popular media player VLC, the code editor Notepad++, and WINE, a tool for running Windows apps on Linux and OS X, to abandon ship.
It’s hard to say how many projects have truly fled Sourceforge because of the site’s tendency to “mirror” certain projects. If you don’t count “forks” in GitHub—copies of projects developers use to make their own tweaks to the code before submitting them to the main project—Sourceforge may still host nearly as many projects as GitHub, says Bill Weinberg of Black Duck Software, which tracks and analyzes open source software.
But the damage to Sourceforge’s reputation may already have been done. Gaurav Kuchhal, managing director of the division of DHI Holdings that handles Sourceforge, says the company stopped its mirroring program and will only bundle installers with projects whose originators explicitly opt in for such add-ons. But misleading “download” ads likely will continue to be a game of whack-a-mole as long as Sourceforge keeps running third-party ads. In its hunt for revenue, Sourceforge is looking less like an important collection of human knowledge and more like a plundered museum full of dangerous traps.
No Ads (For Now)
GitHub has a natural defense against ending up like this: it’s never been an ad-supported business. If you post your code publicly on GitHub, the service is free. This incentivizes code-sharing and collaboration. You pay only to keep your code private. GitHub also makes money offering tech companies private versions of GitHub, which has worked out well: Facebook, Google and Microsoft all do this.
Still, it’s hard to tell how much money the company makes from this model. (It’s certainly not saying.) Yes, it has some of the world’s largest software companies as customers. But it also hosts millions of open source projects free of charge, without ads to offset the costs storage, bandwidth, and the services layered on top of all those repos. Investors will want a return eventually, through an acquisition or IPO. Once that happens, there’s no guarantee new owners or shareholders will be as keen on offering an ad-free loss leader for the company’s enterprise services.
Other freemium services that have raised large rounds of funding, like Box and Dropbox, face similar pressures. (Box even more so since going public earlier this year.) But GitHub is more than a convenient place to store files on the web. It’s a cornerstone of software development—a key repository of open-source code and a crucial body of knowledge. Amassing so much knowledge in one place raises the specter of a catastrophic crash and burn or disastrous decay at the hands of greedy owners loading the site with malware.
Yet GitHub has a defense mechanism the librarians of ancient Alexandria did not. Their library also was a hub. But it didn’t have Git.
Git Goodness
The “Git” part of GitHub is an open source technology that helps programmers manage changes in their code. Basically, a team will place a master copy of the code in a central location, and programmers make copies on their own computers. These programmers then periodically merge their changes with the master copy, the “repository” that remains the canonical version of the project.
Git’s “versioning” makes managing projects much easier when multiple people must make changes to the original code. But it also has an interesting side effect: everyone who works on a GitHub project ends up with a copy own their computers. It’s as if everyone who borrowed a book from the library could keep a copy forever, even after returning it. If GitHub vanished entirely, it could be rebuilt using individual users’ own copies of all the projects. It would take ages to accomplish, but it could be done.
Still, such work would be painful. In addition to the source code itself, GitHub is also home to countless comments, bug reports and feature requests, not to mention the rich history of changes. But the decentralized nature of Git does make it far easier to migrate projects to other hosts, such as GitLab, an open source alternative to GitHub that you can run on your own server.
In short, if GitHub as we know it went away, or under future financial pressures became an inferior version of itself, the world’s code will survive. Libraries didn’t end with Alexandria. The question is ultimately whether GitHub will find ways to stay true to its ideals while generating returns—or wind up the stuff of legend.
Friday, April 24. 2015
Analyst Watch: Ten reasons why open-source software will eat the world
Via SD Times
-----

I recently attended Facebook’s F8 developer conference in San Francisco, where I had a revelation on why it is going to be impossible to succeed as a technology vendor in the long run without deeply embracing open source. Of the many great presentations I listened to, I was most captivated by the ones that explained how Facebook internally developed software. I was impressed by how quickly the company is turning such important IP back into the community.
To be sure, many major Web companies like Google and Yahoo have been leveraging open-source dynamics aggressively and contribute back to the community. My aim is not to single out Facebook, except that it was during the F8 conference I had the opportunity to reflect on the drivers behind Facebook’s actions and why other technology providers may be wise to learn from them.
Here are my 10 reasons why open-source software is effectively becoming inevitable for infrastructure and application platform companies:
- Not reinventing the wheel: The most obvious reason to use open-source software is to build software faster, or to effectively stand on the shoulders of giants. Companies at the top of their game have to move fast and grab the best that have been contributed by a well-honed ecosystem and build their added innovation on top of it. Doing anything else is suboptimal and will ultimately leave you behind.
- Customization with benefits: When a company is at the top of its category, such as a social network with 1.4 billion users, available open-source software is typically only the starting point for a quality solution. Often the software has to be customized to be leveraged. Contributing your customizations back to open source allows them to be vetted and improved for your benefit.
- Motivated workforce: Beyond a good wage and a supportive work environment, there is little that can push developers to do high-quality work more than peer approval, community recognition, and the opportunity for fame. Turning open-source software back to the community and allowing developers to bask in the recognition of their peers is a powerful motivator and an important tool for employee retention.
- Attracting top talent: A similar dynamic is in play in the hiring process as tech companies compete to build their engineering teams. The opportunity to be visible in a broader developer community (or to attain peer recognition and fame) is potentially more important than getting top wages for some. Not contributing open source back to the community narrows the talent pool for tech vendors in an increasingly unacceptable way.
- The efficiency of standardized practices: Using open-source solutions means using standardized solutions to problems. Such standardization of patterns of use or work enforces a normalized set of organizational practices that will improve the work of many engineers at other firms. Such standardization leads to more-optimized organizations, which feature faster developer on-ramping and less wasted time. In other words, open source brings standardized organizational practices, which help avoid unnecessary experimentation.
- Business acceleration: Even in situations where a technology vendor is focused on bringing to market a solution as a central business plan, open source is increasingly replacing proprietary IP for infrastructure and application platform technologies. Creating an innovative solution and releasing it to open source can facilitate broader adoption of the technology with minimal investment in sales, marketing or professional service teams. This dynamic can also be leveraged by larger vendors to experiment in new ventures, and to similarly create wide adoption with minimal cost.
- A moat in plain sight: Creating IP in open source allows the creators to hone their skills and learn usage patterns ahead of the competition. The game then becomes to preserve that lead. Open source may not provide the lock-in protection to the owner that proprietary IP does, but the constant innovation and evolution required in operating in open-source environments fosters fast innovation that has now become essential to business success. Additionally, the visibility of the source code can further enlarge the moat around its innovation, discouraging other businesses from reinventing the wheel.
- Cleaner software: Creating IP in open source also means that the engineers have to operate in full daylight, enabling them to avoid the traps of plagiarized software and generally stay clear of patents. Many proprietary software companies have difficulty turning their large codebases into open source because of necessary time-consuming IP scrubbing processes. Open-source IP-based businesses avoid this problem from the get-go.
- Strategic safety: Basing a new product on open-source software can go a long way to persuade customers who might otherwise be concerned about the vendor’s financial resources or strategic commitment to the technology. It used to be that IT organizations only bought important (but proprietary) software from large, established tech companies. Open source allows smaller players to provide viable solutions by using openness as a competitive weapon to defuse the strategic safety argument. Since the source is open, in theory (and often only in theory) IT organizations can skill up on and support it if and when a small vendor disappears or loses interest.
- Customer goodwill: Finally, open source allows a tech vendor to accrue a great deal of goodwill with its customers and partners. If you are a company like Facebook, constantly and controversially disrupting norms in social interaction and privacy, being able to return value to the larger community through open-source software can go a long way to making up for the negatives of your disruption.
Tuesday, December 16. 2014
We’ve Put a Worm’s Mind in a Lego Robot's Body
Via Smithsonian
-----
If the brain is a collection of electrical signals, then, if you could catalog all those those signals digitally, you might be able upload your brain into a computer, thus achieving digital immortality.
While the plausibility—and ethics—of this upload for humans can be debated, some people are forging ahead in the field of whole-brain emulation. There are massive efforts to map the connectome—all the connections in the brain—and to understand how we think. Simulating brains could lead us to better robots and artificial intelligence, but the first steps need to be simple.
So, one group of scientists started with the roundworm Caenorhabditis elegans, a critter whose genes and simple nervous system we know intimately.
The OpenWorm project has mapped the connections between the worm’s 302 neurons and simulated them in software. (The project’s ultimate goal is to completely simulate C. elegans as a virtual organism.) Recently, they put that software program in a simple Lego robot.
The worm’s body parts and neural networks now have LegoBot equivalents: The worm’s nose neurons were replaced by a sonar sensor on the robot. The motor neurons running down both sides of the worm now correspond to motors on the left and right of the robot, explains Lucy Black for I Programmer. She writes:
---
It is claimed that the robot behaved in ways that are similar to observed C. elegans. Stimulation of the nose stopped forward motion. Touching the anterior and posterior touch sensors made the robot move forward and back accordingly. Stimulating the food sensor made the robot move forward.
---
Timothy Busbice, a founder for the OpenWorm project, posted a video of the Lego-Worm-Bot stopping and backing:
The simulation isn’t exact—the program has some simplifications on the thresholds needed to trigger a "neuron" firing, for example. But the behavior is impressive considering that no instructions were programmed into this robot. All it has is a network of connections mimicking those in the brain of a worm.
Of course, the goal of uploading our brains assumes that we aren’t already living in a computer simulation. Hear out the logic: Technologically advanced civilizations will eventually make simulations that are indistinguishable from reality. If that can happen, odds are it has. And if it has, there are probably billions of simulations making their own simulations. Work out that math, and "the odds are nearly infinity to one that we are all living in a computer simulation," writes Ed Grabianowski for io9.
Is your mind spinning yet?
Tuesday, December 02. 2014
Big Data Digest: Rise of the think-bots
Saturday, November 29. 2014
Human rights organizations launch free tool to detect surveillance software
Via Mashable
-----
More and more, governments are using powerful spying software to target human rights activists and journalists, often the forgotten victims of cyberwar. Now, these victims have a new tool to protect themselves.
Called Detekt, it scans a person's computer for traces of surveillance software, or spyware. A coalition of human rights organizations, including Amnesty International and the Electronic Frontier Foundation launched Detekt on Wednesday, with the goal of equipping activists and journalists with a free tool to discover if they've been hacked.
"Our ultimate aim is for human rights defenders, journalists and civil society groups to be able to carry out their legitimate work without fear of surveillance, harassment, intimidation, arrest or torture," Amnesty wroteThursday in a statement.
The open-source tool was developed by security researcher Claudio Guarnieri, a security researcher who has been investigating government abuse of spyware for years. He often collaborates with other researchers at University of Toronto's Citizen Lab.
During their investigations, Guarnieri and his colleagues discovered, for example, that the Bahraini government used software created by German company FinFisher to spy on human rights activists. They also found out that the Ethiopian government spied on journalists in the U.S. and Europe, using software developed by Hacking Team, another company that sells off-the-shelf surveillance tools.
--------------------------
Guarnieri developed Detekt from software he and the other researchers used during those investigations.
--------------------------
"I decided to release it to the public because keeping it private made no sense," he told Mashable. "It's better to give more people as possible the chance to test and identify the problem as quickly as possible, rather than keeping this knowledge private and let it rot."
Detekt only works with Windows, and it's designed to discover malware developed both by commercial firms, as well as popular spyware used by cybercriminals, such as BlackShades RAT (Remote Access Tool) and Gh0st RAT.
The tool has some limitations, though: It's only a scanner, and doesn't remove the malware infection, which is why Detekt's official site warns that if there are traces of malware on your computer, you should stop using it "immediately," and and look for help. It also might not detect newer versions of the spyware developed by FinFisher, Hacking Team and similar companies.
"If Detekt does not find anything, this unfortunately cannot be considered a clean bill of health," the software's "readme" file warns.
For some, given these limitations, Detekt won't help much.
"The tool appears to be a simple signature-based black list that does not promise it knows all the bad files, and admits that it can be fooled," John Prisco, president and CEO of security firm Triumfant, said. "Given that, it seems worthless to me, but that’s probably why it can be offered for free."

Joanna Rutkowska, a researcher who develops the security-minded operating system Qubes, said computers with traditional operating systems are inherently insecure, and that tools like Detekt can't help with that.
"Releasing yet another malware scanner does nothing to address the primary problem," she told Mashable. "Yet, it might create a false sense of security for users."
But Guarnieri disagrees, saying that Detekt is not a silver-bullet solution intended to be used in place of commercial anti-virus software or other security tools.
"Telling activists and journalists to spend 50 euros a year for some antivirus license in emergency situations isn't very helpful," he said, adding that Detekt is not "just a tool," but also an initiative to spark discussion around the government use of intrusive spyware, which is extremely unregulated.
For Mikko Hypponen, a renowned security expert and chief research officer for anti-virus vendor F-Secure, Detekt is a good project because its target audience — activists and journalists — don't often have access to expensive commercial tools.
“Since Detekt only focuses on detecting a handful of spy tools — but detecting them very well — it might actually outperform traditional antivirus products in this particular area,” he told Mashable.
NSA partners with Apache to release open-source data traffic program
Via zdnet
-----
Many of you probably think that the National Security Agency (NSA) and open-source software get along like a house on fire. That's to say, flaming destruction. You would be wrong.

In partnership with the Apache Software Foundation, the NSA announced on Tuesday that it is releasing the source code for Niagarafiles (Nifi). The spy agency said that Nifi "automates data flows among multiple computer networks, even when data formats and protocols differ".
Details on how Nifi does this are scant at this point, while the ASF continues to set up the site where Nifi's code will reside.
In a statement, Nifi's lead developer Joseph L Witt said the software "provides a way to prioritize data flows more effectively and get rid of artificial delays in identifying and transmitting critical information".
The NSA is making this move because, according to the director of the NSA's Technology Transfer Program (TPP) Linda L Burger, the agency's research projects "often have broad, commercial applications".
"We use open-source releases to move technology from the lab to the marketplace, making state-of-the-art technology more widely available and aiming to accelerate U.S. economic growth," she added.
The NSA has long worked hand-in-glove with open-source projects. Indeed, Security-Enhanced Linux (SELinux), which is used for top-level security in all enterprise Linux distributions — Red Hat Enterprise Linux, SUSE Linux Enterprise Server, and Debian Linux included — began as an NSA project.
More recently, the NSA created Accumulo, a NoSQL database store that's now supervised by the ASF.
More NSA technologies are expected to be open sourced soon. After all, as the NSA pointed out: "Global reviews and critiques that stem from open-source releases can broaden a technology's applications for the US private sector and for the good of the nation at large."
Thursday, October 02. 2014
A Dating Site for Algorithms
-----
![]()
A startup called Algorithmia has a new twist on online matchmaking. Its website is a place for businesses with piles of data to find researchers with a dreamboat algorithm that could extract insights–and profits–from it all.
The aim is to make better use of the many algorithms that are developed in academia but then languish after being published in research papers, says cofounder Diego Oppenheimer. Many have the potential to help companies sort through and make sense of the data they collect from customers or on the Web at large. If Algorithmia makes a fruitful match, a researcher is paid a fee for the algorithm’s use, and the matchmaker takes a small cut. The site is currently in a private beta test with users including academics, students, and some businesses, but Oppenheimer says it already has some paying customers and should open to more users in a public test by the end of the year.
“Algorithms solve a problem. So when you have a collection of algorithms, you essentially have a collection of problem-solving things,” says Oppenheimer, who previously worked on data-analysis features for the Excel team at Microsoft.
Oppenheimer and cofounder Kenny Daniel, a former graduate student at USC who studied artificial intelligence, began working on the site full time late last year. The company raised $2.4 million in seed funding earlier this month from Madrona Venture Group and others, including angel investor Oren Etzioni, the CEO of the Allen Institute for Artificial Intelligence and a computer science professor at the University of Washington.
Etzioni says that many good ideas are essentially wasted in papers presented at computer science conferences and in journals. “Most of them have an algorithm and software associated with them, and the problem is very few people will find them and almost nobody will use them,” he says.
One reason is that academic papers are written for other academics, so people from industry can’t easily discover their ideas, says Etzioni. Even if a company does find an idea it likes, it takes time and money to interpret the academic write-up and turn it into something testable.
To change this, Algorithmia requires algorithms submitted to its site to use a standardized application programming interface that makes them easier to use and compare. Oppenheimer says some of the algorithms currently looking for love could be used for machine learning, extracting meaning from text, and planning routes within things like maps and video games.
Early users of the site have found algorithms to do jobs such as extracting data from receipts so they can be automatically categorized. Over time the company expects around 10 percent of users to contribute their own algorithms. Developers can decide whether they want to offer their algorithms free or set a price.
All algorithms on Algorithmia’s platform are live, Oppenheimer says, so users can immediately use them, see results, and try out other algorithms at the same time.
The site lets users vote and comment on the utility of different algorithms and shows how many times each has been used. Algorithmia encourages developers to let others see the code behind their algorithms so they can spot errors or ways to improve on their efficiency.
One potential challenge is that it’s not always clear who owns the intellectual property for an algorithm developed by a professor or graduate student at a university. Oppenheimer says it varies from school to school, though he notes that several make theirs open source. Algorithmia itself takes no ownership stake in the algorithms posted on the site.
Eventually, Etzioni believes, Algorithmia can go further than just matching up buyers and sellers as its collection of algorithms grows. He envisions it leading to a new, faster way to compose software, in which developers join together many different algorithms from the selection on offer.
Monday, August 11. 2014
PredictionIO Raises $2.5M For Its Open Source Machine Learning Server
Via Techcrunch
-----
Aiming to do for Machine Learning what MySQL did for database servers, U.S. and UK-based PredictionIO has raised $2.5 million in seed funding from a raft of investors including Azure Capital, QuestVP, CrunchFund (of which TechCrunch founder Mike Arrington is a Partner), Stanford University‘s StartX Fund, France-based Kima Ventures, IronFire, Sood Ventures and XG Ventures. The additional capital will be used to further develop its open source Machine Learning server, which significantly lowers the barriers for developers to build more intelligent products, such as recommendation or prediction engines, without having to reinvent the wheel.
Being an open source company — after pivoting from offering a “user behavior prediction-as-a-service” under its old TappingStone product name — PredictionIO plans to generate revenue in the same way MySQL and other open source products do. “We will offer an Enterprise support license and, probably, an enterprise edition with more advanced features,” co-founder and CEO Simon Chan tells me.
The problem PredictionIO is setting out to solve is that building Machine Learning into products is expensive and time-consuming — and in some instances is only really within the reach of major and heavily-funded tech companies, such as Google or Amazon, who can afford a large team of PhDs/data scientists. By utilising the startup’s open source Machine Learning server, startups or larger enterprises no longer need to start from scratch, while also retaining control over the source code and the way in which PredictionIO integrates with their existing wares.
In fact, the degree of flexibility and reassurance an open source product offers is the very reason why PredictionIO pivoted away from a SaaS model and chose to open up its codebase. It did so within a couple of months of launching its original TappingStone product. Fail fast, as they say.
“We changed from TappingStone (Machine Learning as a Service) to PredictionIO (open source server) in the first 2 months once we built the first prototype,” says Chan. “As developers ourselves, we realise that Machine Learning is useful only if it’s customizable to each unique application. Therefore, we decided to open source the whole product.”
The pivot appears to be working, too, and not just validated by today’s funding. To date, Chan says its open source Machine Learning server is powering thousands of applications with 4000+ developers engaged with the project. “Unlike other data science tools that focus on solving data researchers’ problems, PredictionIO is built for every programmer,” he adds.
Other competitors Chan cites include “closed ‘black box” MLaaS services or software’, such as Google Prediction API, Wise.io, BigML, and Skytree.
Examples of who is currently using PredictionIO include Le Tote, a clothing subscription/rental service that is using PredictionIO to predict customers’ fashion preferences, and PerkHub, which is using PredictionIO to personalize product recommendations in the weekly ‘group buying’ emails they send out.
Monday, June 16. 2014
Project Un1c0rn Wants to Be the Google for Lazy Security Flaws
Via Motherboard
-----
Following broad security scares like that caused by the Heartbleed bug, it can be frustratingly difficult to find out if a site you use often still has gaping flaws. But a little known community of software developers is trying to change that, by creating a searchable, public index of websites with known security issues.
Think of Project Un1c0rn as a Google for site security. Launched on May 15th, the site's creators say that so far it has indexed 59,000 websites and counting. The goal, according to its founders, is to document open leaks caused by the Heartbleed bug, as well as "access to users' databases" in Mongo DB and MySQL.
According to the developers, those three types of vulnerabilities are most widespread because they rely on commonly used tools. For example, Mongo databases are used by popular sites like LinkedIn, Expedia, and SourceForge, while MySQL powers applications such as WordPress, Drupal or Joomla, and are even used by Twitter, Google and Facebook.
Having a website’s vulnerability indexed publicly is like advertising that you leave your front doors unlocked and your flat screen in the basement. But Un1c0rn’s founder sees it as teaching people the value of security. And his motto is pretty direct. “Raising total awareness by ‘kicking in the nuts’ is our target,” said the founder, who goes by the alias SweetCorn.
“The exploits and future exploits that will be added are just exploiting people's stupidity or misconception about security from a company selling or buying bullshit protections,” he said. SweetCorn thinks Project Un1c0rn is exposing what is already visible without a lot of effort.
While the Heartbleed bug alerted the general public to how easily hackers can exploit widely used code, clearly vulnerabilities don’t begin and end with the bug. Just last week the CCS Injection vulnerability was discovered, and the OpenSSL foundation posted a security advisory.
“Billions of people are leaving information and trails in billions of different databases, some just left with default configurations that can be found in a matter of seconds for whoever has the resources,” SweetCorn said. Changing and updating passwords is a crucial practice.
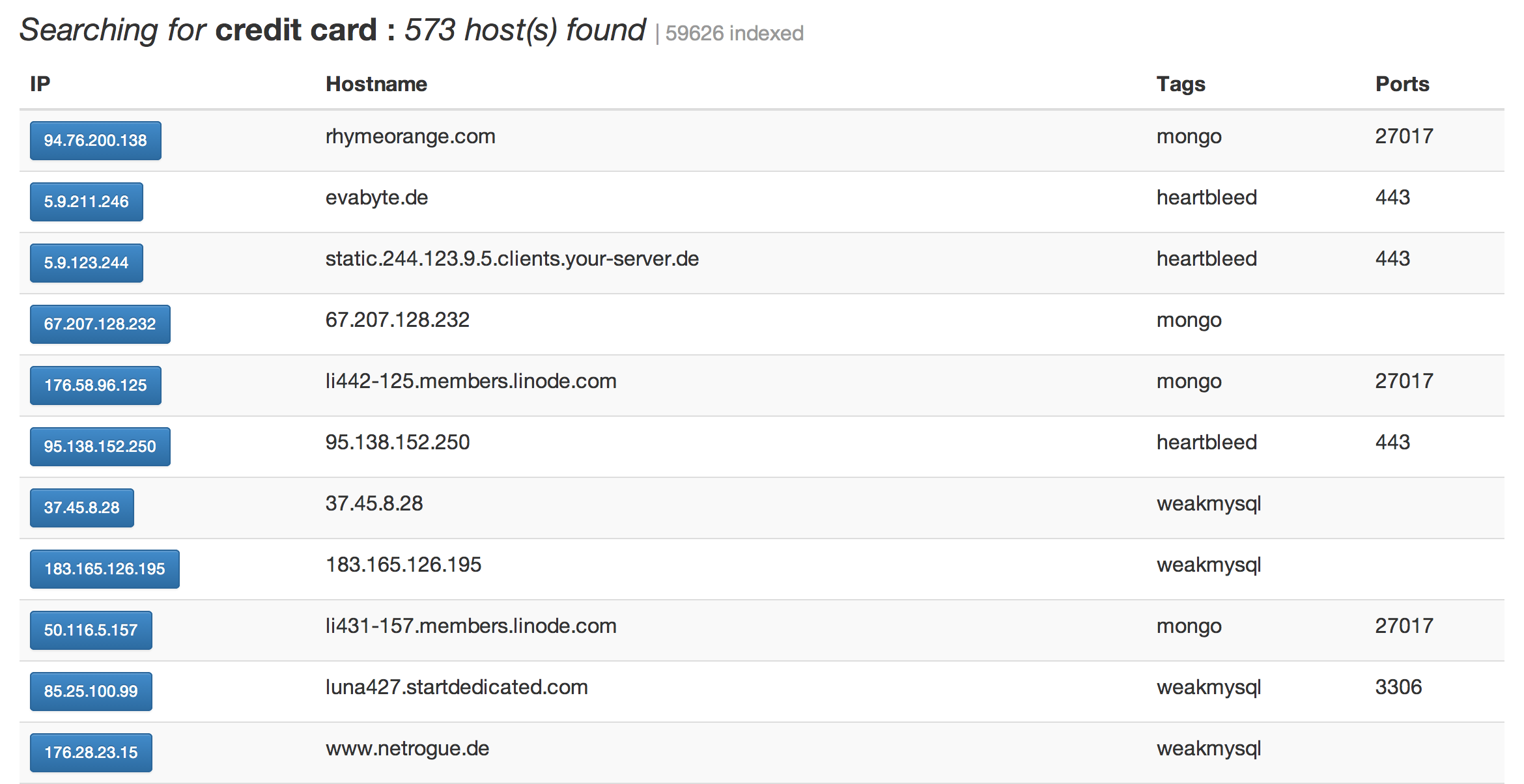
Search results on the Un1c0rn site. Image: Project Un1c0rn
I reached out to José Fernandez, a computer security expert and professor at the Polytechnique school in Montreal, to get his take on Project Un1c0rn. "The (vulnerability) tests are quite objective," he said. "There are no reasons not to believe the vulnerabilities listed."
Fernandez added that the only caveat for the search engine was that a listed server could have been patched after the vulnerability scan had been run.
The project is still in its very early stages, with some indexed websites not yet updated, which means not all of the 58,000 websites listed are currently vulnerable to the same weaknesses.
“The Un1c0rn is still weak”, admitted SweetCorn. “We did this with 0.4 BitCoin, I just can't imagine what someone having enough money to spend on information mining could do.” According to SweetCorn, those funds were used to buy the domain name and rent servers.
SweetCorn is releasing few details about the backend of the project, although he says it relies heavily on the Tor network. Motherboard couldn’t independently confirm what kind of search functions SweetCorn is operating or whether they are legal. In any case, he has bigger plans for his project: making it the first peer-to-peer decentralized exploit system, where individuals could host their own scanning nodes.
“We took some easy steps, Disqus is one of them, we would love to see security researchers going on Un1c0rn, leave comments and help (us) fix stuff,” he said.
He hopes that the attention raised by his project will make people understand “what their privacy really (looks like).”
A quick scan through Un1c0rn’s database brings up some interesting results. McGill University in Montreal had some trouble with one of their MySQL databases. The university has since been notified, and their IT team told me the issue had been addressed.
The UK’s cyberspies at the GHCQ probably forgot they had a test database open (unless it’s a honeypot), though requests for comments were not answered. A search for “credit card” retrieves 573 websites, some of which might just host card data if someone digs enough.
In an example of how bugs can pervade all corners of the web, the IT team in charge of the VPN for the town of Mandurah in Australia were probably napping while the rest of the world was patching their broken version of OpenSSL. Tests run with the Qualys SSL Lab and filippo.io tools confirmed the domain was indeed vulnerable to Heartbleed.
While tools to scan for vulnerabilities across the Internet already exist. Last year, the project critical.io did a mass scan of the Internet to look for vulnerabilities, for research purposes. The data was released online and further analyzed by security experts.
But Project Un1c0rn is certainly one of the first to publicly index the vulnerabilities found. Ultimately, if Project Un1c0rn or something like it is successful and open sourced, checking if your bank or online dating site is vulnerable to exploits will be a click away.
Monday, June 09. 2014
NELL: Never-Ending Language Learning
Via Computed·Blg
-----

Can computers learn to read? We think so. "Read the Web" is a research project that attempts to create a computer system that learns over time to read the web. Since January 2010, our computer system called NELL (Never-Ending Language Learner) has been running continuously, attempting to perform two tasks each day:
- First, it attempts to "read," or extract facts from text found in hundreds of millions of web pages (e.g., playsInstrument(George_Harrison, guitar)).
- Second, it attempts to improve its reading competence, so that tomorrow it can extract more facts from the web, more accurately.
So far, NELL has accumulated over 50 million candidate beliefs by reading the web, and it is considering these at different levels of confidence. NELL has high confidence in 2,132,551 of these beliefs — these are displayed on this website. It is not perfect, but NELL is learning. You can track NELL's progress below or @cmunell on Twitter, browse and download its knowledge base, read more about our technical approach, or join the discussion group.
Quicksearch
Popular Entries
- The great Ars Android interface shootout (131329)
- Norton cyber crime study offers striking revenue loss statistics (102120)
- MeCam $49 flying camera concept follows you around, streams video to your phone (100324)
- Norton cyber crime study offers striking revenue loss statistics (58349)
- The PC inside your phone: A guide to the system-on-a-chip (57984)
Categories

Show tagged entries
Syndicate This Blog
Calendar
|
|
May '26 | |||||
| Mon | Tue | Wed | Thu | Fri | Sat | Sun |
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |