Photo: University of Michigan and TSMC
One of several varieties of University of Michigan micromotes. This one incorporates 1 megabyte of flash memory.
Computer scientist David Blaauw
pulls a small plastic box from his bag. He carefully uses his
fingernail to pick up the tiny black speck inside and place it on the
hotel café table. At 1 cubic millimeter, this is one of a line of the
world’s smallest computers. I had to be careful not to cough or sneeze
lest it blow away and be swept into the trash.
Blaauw and his colleague Dennis Sylvester,
both IEEE Fellows and computer scientists at the University of
Michigan, were in San Francisco this week to present 10 papers related
to these “micromote” computers at the IEEE International Solid-State Circuits Conference (ISSCC). They’ve been presenting different variations on the tiny devices for a few years.
Their broader goal is to make smarter, smaller sensors for medical
devices and the Internet of Things—sensors that can do more with less
energy. Many of the microphones, cameras, and other sensors that make up
the eyes and ears of smart devices are always on alert, and frequently
beam personal data into the cloud because they can’t analyze it
themselves. Some have predicted that by 2035, there will be 1 trillion such devices.
“If you’ve got a trillion devices producing readings constantly, we’re
going to drown in data,” says Blaauw. By developing tiny,
energy-efficient computing sensors that can do analysis on board, Blaauw
and Sylvester hope to make these devices more secure, while also saving
energy.
At the conference, they described micromote designs that use only a
few nanowatts of power to perform tasks such as distinguishing the sound
of a passing car and measuring temperature and light levels. They
showed off a compact radio that can send data from the small computers
to receivers 20 meters away—a considerable boost compared to the
50-centimeter range they reported last year at ISSCC. They also described their work with TSMC
(Taiwan Semiconductor Manufacturing Company) on embedding flash memory
into the devices, and a project to bring on board dedicated, low-power
hardware for running artificial intelligence algorithms called deep
neural networks.
Blaauw and Sylvester say they take a holistic approach to adding new
features without ramping up power consumption. “There’s no one answer”
to how the group does it, says Sylvester. If anything, it’s “smart
circuit design,” Blaauw adds. (They pass ideas back and forth rapidly,
not finishing each other’s sentences but something close to it.)
The memory research is a good example of how the right trade-offs can
improve performance, says Sylvester. Previous versions of the
micromotes used 8 kilobytes of SRAM (static RAM), which makes for a
pretty low-performance computer. To record video and sound, the tiny
computers need more memory. So the group worked with TSMC to bring flash
memory on board. Now they can make tiny computers with 1 megabyte of
storage.
Flash can store more data in a smaller footprint than SRAM, but it
takes a big burst of power to write to the memory. With TSMC, the group
designed a new memory array that uses a more efficient charge pump for
the writing process. The memory arrays are a bit less dense than TSMC’s
commercial products, for example, but still much better than SRAM. “We
were able to get huge gains with small trade-offs,” says Sylvester.
Another micromote they presented at the ISSCC incorporates a deep-learning
processor that can operate a neural network while using just 288
microwatts. Neural networks are artificial intelligence algorithms that
perform well at tasks such as face and voice recognition. They typically
demand both large memory banks and intense processing power, and so
they’re usually run on banks of servers often powered by advanced GPUs.
Some researchers have been trying to lessen the size and power demands
of deep-learning AI with dedicated hardware that’s specially designed to
run these algorithms. But even those processors still use over 50
milliwatts of power—far too much for a micromote. The Michigan group
brought down the power requirements by redesigning the chip
architecture, for example by situating four processing elements within
the memory (in this case, SRAM) to minimize data movement.
The idea is to bring neural networks to the Internet of Things. “A
lot of motion detection cameras take pictures of branches moving in the
wind—that’s not very helpful,” says Blaauw. Security cameras and other
connected devices are not smart enough to tell the difference between a
burglar and a tree, so they waste energy sending uninteresting footage
to the cloud for analysis. Onboard deep-learning processors could make
better decisions, but only if they don’t use too much power. The
Michigan group imagine that deep-learning processors could be integrated
into many other Internet-connected things besides security systems. For
example, an HVAC system could decide to turn the air-conditioning down
if it sees multiple people putting on their coats.
After demonstrating many variations on these micromotes in an
academic setting, the Michigan group hopes they will be ready for market
in a few years. Blaauw and Sylvester say their startup company, CubeWorks,
is currently prototyping devices and researching markets. The company
was quietly incorporated in late 2013. Last October, Intel Capital announced they had invested an undisclosed amount in the tiny computer company.
HyperFace is being developed for Hyphen Labs NeuroSpeculative AfroFeminism
project at Sundance Film Festival and is a collaboration with Hyphen
Labs members Ashley Baccus-Clark, Carmen Aguilar y Wedge, Ece Tankal,
Nitzan Bartov, and JB Rubinovitz.
NeuroSpeculative AfroFeminism
is a transmedia exploration of black women and the roles they play in
technology, society and culture—including speculative products,
immersive experiences and neurocognitive impact research. Using fashion,
cosmetics and the economy of beauty as entry points, the project
illuminates issues of privacy, transparency, identity and perception.
HyperFace
is a new kind of camouflage that aims to reduce the confidence score of
facial detection and recognition by providing false faces that distract computer vision algorithms. HyperFace development began in 2013 and was first presented at 33c3 in Hamburg, Germany on December 30th, 2016. HyperFace will launch as a textile print at Sundance Film Festival on January 16, 2017.
Together HyperFace and NeuroSpeculative AfroFeminism will explore an Afrocentric countersurveillance aesthetic.
For more information about NeuroSpeculative AfroFeminism visit nsaf.space
How Does HyperFace Work?
HyperFace
works by providing maximally activated false faces based on ideal
algorithmic representations of a human face. These maximal activations
are targeted for specific algorithms. The prototype above is specific to
OpenCV’s default frontalface profile. Other patterns target
convolutional nueral networks and HoG/SVM detectors. The technical
concept is an extension of earlier work on CV Dazzle.
The difference between the two projects is that HyperFace aims to alter
the surrounding area (ground) while CV Dazzle targets the facial area
(figure). In camouflage, the objective is often to minimize the
difference between figure and ground. HyperFace reduces the confidence score of the true face (figure) by redirecting more attention to the nearby false face regions (ground).
Conceptually, HyperFace
recognizes that completely concealing a face to facial detection
algorithms remains a technical and aesthetic challenge. Instead of
seeking computer vision anonymity through minimizing the confidence
score of a true face (i.e. CV Dazzle), HyperFace offers a
higher confidence score for a nearby false face by exploiting a common
algorithmic preference for the highest confidence facial region. In
other words, if a computer vision algorithm is expecting a face, give it
what it wants.
How Well Does This Work?
The
patterns are still under development and are expected to change. Please
check back towards the end of January for more information.
Product Photos
Please check back towards the end of January for product photos
Notifications
If
you’re interested in purchasing one of the first commercially available
HyperFace textiles, please add yourself to my mailing list at Undisclosed.studio
Notes
Designs subject to change
Displayed patterns are prototypes and are currently undergoing testing.
First prototype designed for OpenCV Haarcascade. Future iterations will include patterns for HoG/SVM and CNN detectors
Will not make you invisible
Please credit image as HyperFace Prototype by “Adam Harvey / ahprojects.com”
Please credit scarf rendering prototype as “Rendering by Ece Tankal / hyphen-labs.com”
Not affilliated with the IARPA funded Hyperface algorithm for pose and gender recognition
Today’s mobile users want faster data speeds and more reliable
service. The next generation of wireless networks—5G—promises to deliver
that, and much more. With 5G, users should be able to download a
high-definition film in under a second (a task that could take10 minutes on 4G LTE). And wireless engineers say these networks will boost the development of other new technologies, too, such as autonomous vehicles, virtual reality, and the Internet of Things.
If all goes well, telecommunications companies hope to debut the first commercial 5G networksin the early 2020s. Right now, though, 5G
is still in the planning stages, and companies and industry groups are
working together to figure out exactly what it will be. But they all
agree on one matter: As the number of mobile users and their demand for
data rises, 5G must handle far more traffic at much higher speeds than
the base stations that make up today’s cellular networks.
At the moment, it’s not yet clear which technologies will do
the most for 5G in the long run, but a few early favorites have emerged.
The front-runners include millimeter waves, small cells, massive MIMO,
full duplex, and beamforming. To understand how 5G will differ from
today’s 4G networks, it’s helpful to walk through these five
technologies and consider what each will mean for wireless users.
Millimeter Waves
Today’s wireless networks have run into a problem: More people
and devices are consuming more data than ever before, but it remains
crammed on the same bands of the radio-frequency spectrum that mobile
providers have always used. That means less bandwidth for everyone,
causing slower service and more dropped connections.
One way to get around that problem is to simply transmit
signals on a whole new swath of the spectrum, one that’s never been used
for mobile service before. That’s why providers are experimenting with
broadcasting on millimeter waves, which use higher frequencies than the radio waves that have long been used for mobile phones.
Millimeter waves are broadcast at frequencies between30 and 300 gigahertz,
compared to the bands below 6 GHz that were used for mobile devices in
the past. They are called millimeter waves because they vary in length
from1 to 10 mm, compared to the radio waves that serve today’s smartphones, which measuretens of centimeters in length.
Until now, only operators of satellites and radar systems used
millimeter waves for real-world applications. Now, some cellular
providers have begun to use them to send data between stationary points,
such as two base stations. But using millimeter waves to connect mobile
users with a nearby base station is an entirely new approach.
There is one major drawback to millimeter waves, though—they
can’t easily travel through buildings or obstacles and they can be
absorbed by foliage and rain. That’s why 5G networks will likely augment
traditional cellular towers with another new technology, called small
cells.
Small Cells
Small cells are
portable miniature base stations that require minimal power to operate
and can be placed every 250 meters or so throughout cities. To prevent
signals from being dropped, carriers could install thousands of these
stations in a city to form a dense network that acts like a relay team,
receiving signals from other base stations and sending data to users at
any location.
While traditional cell networks have also come to rely on an
increasing number of base stations, achieving 5G performance will
require an even greater infrastructure. Luckily, antennas on small cells
can be much smaller than traditional antennas if they are transmitting
tiny millimeter waves. This size difference makes it even easier to
stick cells on light poles and atop buildings.
This radically different network structure should provide more
targeted and efficient use of spectrum. Having more stations means the
frequencies that one station uses to connect with devices in one area
can be reused by another station in a different area to serve another
customer. There is a problem, though—the sheer number of small cells
required to build a 5G network may make it hard to set up in rural
areas.
In addition to broadcasting over millimeter waves, 5G base
stations will also have many more antennas than the base stations of
today’s cellular networks—to take advantage of another new technology:
massive MIMO.
Massive MIMO
Today’s 4G base stations have a dozen ports for antennas that
handle all cellular traffic: eight for transmitters and four for
receivers. But 5G base stations can support about a hundred ports, which
means many more antennas can fit on a single array. That capability
means a base station could send and receive signals from many more users
at once, increasing the capacity of mobile networks by a factor of22 or greater.
This technology is called massive MIMO.
It all starts with MIMO, which stands for multiple-input
multiple-output. MIMO describes wireless systems that use two or more
transmitters and receivers to send and receive more data at once.
Massive MIMO takes this concept to a new level by featuring dozens of
antennas on a single array.
MIMO is already found on some 4G base stations. But so far,
massive MIMO has only been tested in labs and a few field trials. In
early tests, it has set new records for spectrum efficiency, which is a measure of how many bits of data can be transmitted to a certain number of users per second.
Massive MIMO looks very promising for the future of 5G.
However, installing so many more antennas to handle cellular traffic
also causes more interference if those signals cross. That’s why 5G
stations must incorporate beamforming.
Beamforming
Beamforming is a traffic-signaling system for cellular base
stations that identifies the most efficient data-delivery route to a
particular user, and it reduces interference for nearby users in the
process. Depending on the situation and the technology, there are
several ways for 5G networks to implement it.
Beamforming can help massive MIMO arrays make more efficient
use of the spectrum around them. The primary challenge for massive MIMO
is to reduce interference while transmitting more information from many
more antennas at once. At massive MIMO base stations, signal-processing
algorithms plot the best transmission route through the air to each
user. Then they can send individual data packets in many different
directions, bouncing them off buildings and other objects in a precisely
coordinated pattern. By choreographing the packets’ movements and
arrival time, beamforming allows many users and antennas on a massive
MIMO array to exchange much more information at once.
For millimeter waves, beamforming is primarily used to address a
different set of problems: Cellular signals are easily blocked by
objects and tend to weaken over long distances. In this case,
beamforming can help by focusing a signal in a concentrated beam that
points only in the direction of a user, rather than broadcasting in many
directions at once. This approach can strengthen the signal’s chances
of arriving intact and reduce interference for everyone else.
Besides boosting data rates by broadcasting over millimeter
waves and beefing up spectrum efficiency with massive MIMO, wireless
engineers are also trying to achieve the high throughput and low latency
required for 5G through a technology called full duplex, which modifies
the way antennas deliver and receive data.
Full Duplex
Today's base stations and cellphones rely on transceivers that
must take turns if transmitting and receiving information over the same
frequency, or operate on different frequencies if a user wishes to
transmit and receive information at the same time.
With 5G, a transceiver will be able to transmit and receive
data at the same time, on the same frequency. This technology is known
as full duplex,
and it could double the capacity of wireless networks at their most
fundamental physical layer: Picture two people talking at the same time
but still able to understand one another—which means their conversation
could take half as long and their next discussion could start sooner.
Some militaries already use full duplex technology that relies on bulky equipment. To achieve full duplex in personal devices,
researchers must design a circuit that can route incoming and outgoing
signals so they don’t collide while an antenna is transmitting and
receiving data at the same time.
This is especially hard because of the tendency of radio waves
to travel both forward and backward on the same frequency—a principle
known as reciprocity. But recently,
experts have assembled silicon transistors that act like high-speed
switches to halt the backward roll of these waves, enabling them to
transmit and receive signals on the same frequency at once.
One drawback to full duplex is that it also creates more signal
interference, through a pesky echo. When a transmitter emits a signal,
that signal is much closer to the device’s antenna and therefore more
powerful than any signal it receives. Expecting an antenna to both speak
and listen at the same time is possible only with special
echo-canceling technology.
With these and other 5G technologies, engineers hope to build
the wireless network that future smartphone users, VR gamers, and
autonomous cars will rely on every day. Already, researchers and
companies have set high expectations for 5G by promising ultralow
latency and record-breaking data speeds for consumers. If they can solve
the remaining challenges, and figure out how to make all these systems
work together, ultrafast 5G service could reach consumers in the next
five years.
Writing Credits:
Amy Nordrum–Article Author & Voice Over
Produced By:
Celia Gorman–Executive Producer
Kristen Clark–Producer
Art Direction and Illustrations:
Brandon Palacio–Art Director
Mike Spector–Illustrator
Ove Edfors–Expert & Illustrator
Special Thanks: IEEE Spectrum would like to thank the following experts for their contributions to this video: Harish
Krishnaswamy, Columbia University; Gabriel M. Rebeiz, UCSD; Ove Edfors,
Lund University; Yonghui Li, University of Sydney; Paul Harris,
University of Bristol; Andrew Nix, University of Bristol; Mark Beach,
University of Bristol.
Hungry penguins have inspired a novel way of making sure computer code in smart cars does not crash.
Tools based on the way the birds co-operatively hunt for fish are
being developed to test different ways of organising in-car software.
The tools look for safe ways to organise code in the same way that penguins seek food sources in the open ocean.
Experts said such testing systems would be vital as cars get more connected.
Engineers have often turned to nature for good solutions to tricky
problems, said Prof Yiannis Papadopoulos, a computer scientist at the
University of Hull who developed the penguin-inspired testing system.
The way ants pass messages among nest-mates has helped telecoms firms
keep telephone networks running, and many robots get around using
methods of locomotion based on the ways animals move.
‘Big society’
Penguins were another candidate, said Prof Papadopoulos, because
millions of years of evolution has helped them develop very efficient
hunting strategies.
This was useful behaviour to copy, he said, because it showed that
penguins had solved a tricky optimisation problem – how to ensure as
many penguins as possible get enough to eat.
“Penguins are social birds and we know they live in colonies that are
often very large and can include hundreds of thousands of birds. This
raises the question of how can they sustain this kind of big society
given that together they need a vast amount of food.
“There must be something special about their hunting strategy,” he
said, adding that an inefficient strategy would mean many birds starved.
Prof Papadopoulos said many problems in software engineering could be
framed as a search among all hypothetical solutions for the one that
produces the best results. Evolution, through penguins and many other
creatures, has already searched through and discarded a lot of bad
solutions.
Studies of hunting penguins have hinted at how they organised themselves.
“They forage in groups and have been observed to synchronise their
dives to get fish,” said Prof Papadopoulos. “They also have the ability
to communicate using vocalisations and possibly convey information about
food resources.”
The communal, co-ordinated action helps the penguins get the most out
of a hunting expedition. Groups of birds are regularly reconfigured to
match the shoals of fish and squid they find. It helps the colony as a
whole optimise the amount of energy they have to expend to catch food.
“This solution has generic elements which can be abstracted and be
used to solve other problems,” he said, “such as determining the
integrity of software components needed to reach the high safety
requirements of a modern car.”
Integrity in this sense means ensuring the software does what is
intended, handles data well, and does not introduce errors or crash.
By mimicking penguin behaviour in a testing system which seeks the
safest ways to arrange code instead of shoals of fish, it becomes
possible to slowly zero in on the best way for that software to be
structured.
The Hull researchers, in conjunction with Dr Youcef Gheraibia, a
postdoctoral researcher from Algeria, turned to search tools based on
the collaborative foraging behaviour of penguins.
The foraging-based system helped to quickly search through the many
possible ways software can be specified to home in on the most optimal
solutions in terms of safety and cost.
Currently, complex software was put together and tested manually,
with only experience and engineering judgement to guide it, said Prof
Papadopoulos. While this could produce decent results it could consider
only a small fraction of all possible good solutions.
The penguin-based system could crank through more solutions and do a better job of assessing which was best, he said.
Under pressure
Mike Ahmadi, global director of critical systems security at
Synopsys, which helps vehicle-makers secure code, said modern car
manufacturing methods made optimisation necessary.
“When you look at a car today, it’s essentially something that’s put together from a vast and extended supply chain,” he said.
Building a car was about getting sub-systems made by different
manufacturers to work together well, rather than being something made
wholly in one place.
That was a tricky task given how much code was present in modern cars, he added.
“There’s about a million lines of code in the average car today and there’s far more in connected cars.”
Carmakers were under pressure, said Mr Ahmadi, to adapt cars quickly
so they could interface with smartphones and act as mobile entertainment
hubs, as well as make them more autonomous.
“From a performance point of view carmakers have gone as far as they
can,” he said. “What they have discovered is that the way to offer
features now is through software.”
Security would become a priority as cars got smarter and started
taking in and using data from other cars, traffic lights and online
sources, said Nick Cook from software firm Intercede, which is working
with carmakers on safe in-car software.
“If somebody wants to interfere with a car today then generally they
have to go to the car itself,” he said. “But as soon as it’s connected
they can be anywhere in the world.
“Your threat landscape is quite significantly different and the opportunity for a hack is much higher.”
In 2011, when Stanford computer scientists Sebastian Thrun and Peter Norvig came up with the bright idea of streaming their robotics lectures over the Internet,
they knew it was an inventive departure from the usual college course.
For hundreds of years, professors had lectured to groups of no more than
a few hundred students. But MOOCs—massive open online courses—made it
possible to reach many thousands at once. Through the extraordinary
reach of the Internet, learners could log on to lectures streamed to
wherever they happened to be. To date, about 58 million people have signed up for a MOOC.
Familiar with the technical elements required for a MOOC—video
streaming, IT infrastructure, the Internet—MOOC developers put code
together to send their lectures into cyberspace. When more than 160,000
enrolled in Thrun and Norvig’s introduction to artificial intelligence
MOOC, the professors thought they held a tiger by the tail. Not long
after, Thrun cofounded Udacity to commercialize MOOCs. He predicted that in 50 years, streaming lectures would so subvert face-to-face education that only 10 higher-education institutions would remain.
Our quaint campuses would become obsolete, replaced by star faculty
streaming lectures on computer screens all over the world. Thrun and
other MOOC evangelists imagined they had inspired a revolution,
overthrowing a thousand years of classroom teaching.
These MOOC pioneers were therefore stunned when their online courses
didn’t perform anything like they had expected. At first, the average
completion rate for MOOCs was less than 7 percent. Completion rates have since gone up a bit, to a median of about 12.6 percent, although there’s considerable variation from course to course. While
a number of factors contribute to the completion rate, my own
observation is that students who have to pay a fee to enroll tend to be
more committed to finishing the course.
Looking closer at students’ MOOC habits, researchers found that some
people quit watching within the first few minutes. Many others were
merely “grazing,” taking advantage of the technology to quickly log in,
absorb just the morsel they were hunting for, and then log off as soon
as their appetite was satisfied. Most of those who did finish a MOOC
were accomplished learners, many with advanced degrees.
What accounts for MOOCs’ modest performance? While the technological
solution they devised was novel, most MOOC innovators were unfamiliar
with key trends in education. That is, they knew a lot about computers
and networks, but they hadn’t really thought through how people learn.
It’s unsurprising then that the first MOOCs merely replicated the
standard lecture, an uninspiring teaching style but one with which the
computer scientists were most familiar. As the education technology consultant Phil Hill recently observed in the Chronicle of Higher Education,
“The big MOOCs mostly employed smooth-functioning but basic video
recording of lectures, multiple-choice quizzes, and unruly discussion
forums. They were big, but they did not break new ground in pedagogy.”
Indeed, most MOOC founders were unaware that a pedagogical revolution
was already under way at the nation’s universities: The traditional
lecture was being rejected by many scholars, practitioners, and, most
tellingly, tech-savvy students. MOOC advocates also failed to appreciate
the existing body of knowledge about learning online, built over the
last couple of decades by adventurous faculty who were attracted to
online teaching for its innovative potential, such as peer-to-peer
learning, virtual teamwork, and interactive exercises. These modes of
instruction, known collectively as “active” learning, encourage student
engagement, in stark contrast to passive listening in lectures. Indeed,
even as the first MOOCs were being unveiled, traditional lectures were
on their way out.
The impact of active learning can be significant. In a 2014 meta-analysis published in Proceedings of the National Academy of Sciences
[PDF], researchers looked at 225 studies in which standard lectures
were compared with active learning for undergraduate science, math, and
engineering. The results were unambiguous: Average test scores went up
about 6 percent in active-learning sections, while students in
traditional lecture classes were 1.5 times more likely to fail than
their peers in active-learning classes.
Even lectures by “star” faculty were no match for active-learning
sections taught by novice instructors: Students still performed better
in active classes. “We’ve yet to see any evidence that celebrated
lecturers can help students more than even first-generation active
learning does,” Scott Freeman, the lead author of the study, told Wired.
Unfortunately, early MOOCs failed to incorporate active learning
approaches or any of the other innovations in teaching and learning
common in other online courses. The three principal MOOC
providers—Coursera, Udacity, and edX—wandered into a territory they
thought was uninhabited. Yet it was a place that was already well
occupied by accomplished practitioners who had thought deeply and
productively over the last couple of decades about how students learn
online. Like poor, baffled Columbus, MOOC makers believed they had
“discovered” a new world. It’s telling that in their latest offerings,
these vendors have introduced a number of active-learning innovations.
To be sure, MOOCs have been wildly successful in giving millions of
people all over the world access to a wide range of subjects presented
by eminent scholars at the world’s elite schools. Some courses attract
so many students that a 7 percent completion rate still translates into
several thousand students finishing—greater than the total enrollment of
many colleges.
But MOOC pioneers were presumptuous to imagine they could not only
topple the university—an institution that has successfully withstood
revolutions far more devastating than the Web—but also ignore common
experience. They erroneously assumed they could open the minds of
millions who were unprepared to tackle sophisticated curriculum. MOOCs
will never sweep away face-to-face classrooms, nor can they take the
place of more intensive and intimate online degree programs. The real
contribution of MOOCs is likely to be much more modest, as yet another
digital education option.
In
the closing weeks of 2016, Google published an article that quietly
sailed under most people’s radars. Which is a shame, because it may just
be the most astonishing article about machine learning that I read last
year.
This doesn’t exactly scream must read,
does it? Especially when you’ve got projects to wind up, gifts to buy,
and family feuds to be resolved — all while the advent calendar
relentlessly counts down the days until Christmas like some kind of
chocolate-filled Yuletide doomsday clock.
Luckily, I’m here to bring you up to speed. Here’s the deal.
Up
until September of last year, Google Translate used phrase-based
translation. It basically did the same thing you and I do when we look
up key words and phrases in our Lonely Planet language guides. It’s
effective enough, and blisteringly fast compared to awkwardly thumbing
your way through a bunch of pages looking for the French equivalent of
“please bring me all of your cheese and don’t stop until I fall over.”
But it lacks nuance.
Phrase-based
translation is a blunt instrument. It does the job well enough to get
by. But mapping roughly equivalent words and phrases without an
understanding of linguistic structures can only produce crude results.
This
approach is also limited by the extent of an available vocabulary.
Phrase-based translation has no capacity to make educated guesses at
words it doesn’t recognize, and can’t learn from new input.
All
that changed in September, when Google gave their translation tool a
new engine: the Google Neural Machine Translation system (GNMT). This
new engine comes fully loaded with all the hot 2016 buzzwords, like neural network and machine learning.
The
short version is that Google Translate got smart. It developed the
ability to learn from the people who used it. It learned how to make
educated guesses about the content, tone, and meaning of phrases based
on the context of other words and phrases around them. And — here’s the
bit that should make your brain explode — it got creative.
Google Translate invented its own language to help it translate more effectively.
What’s more, nobody told it to. It didn’t develop a language (or interlingua,
as Google call it) because it was coded to. It developed a new language
because the software determined over time that this was the most
efficient way to solve the problem of translation.
Stop
and think about that for a moment. Let it sink in. A neural computing
system designed to translate content from one human language into
another developed its own internal language to make the task more
efficient. Without being told to do so. In a matter of weeks.
To
understand what’s going on, we need to understand what zero-shot
translation capability is. Here’s Google’s Mike Schuster, Nikhil Thorat,
and Melvin Johnson from the original blog post:
Let’s
say we train a multilingual system with Japanese⇄English and
Korean⇄English examples. Our multilingual system, with the same size as a
single GNMT system, shares its parameters to translate between these
four different language pairs. This sharing enables the system to
transfer the “translation knowledge” from one language pair to the
others. This transfer learning and the need to translate between
multiple languages forces the system to better use its modeling power.
This
inspired us to ask the following question: Can we translate between a
language pair which the system has never seen before? An example of this
would be translations between Korean and Japanese where Korean⇄Japanese
examples were not shown to the system. Impressively, the answer is
yes — it can generate reasonable Korean⇄Japanese translations, even
though it has never been taught to do so.
Here
you can see an advantage of Google’s new neural machine over the old
phrase-based approach. The GMNT is able to learn how to translate
between two languages without being explicitly taught. This wouldn’t be
possible in a phrase-based model, where translation is dependent upon an
explicit dictionary to map words and phrases between each pair of
languages being translated.
And this leads the Google engineers onto that truly astonishing discovery of creation:
The
success of the zero-shot translation raises another important question:
Is the system learning a common representation in which sentences with
the same meaning are represented in similar ways regardless of
language — i.e. an “interlingua”? Using a 3-dimensional representation
of internal network data, we were able to take a peek into the system as
it translates a set of sentences between all possible pairs of the
Japanese, Korean, and English languages.
Within
a single group, we see a sentence with the same meaning but from three
different languages. This means the network must be encoding something
about the semantics of the sentence rather than simply memorizing
phrase-to-phrase translations. We interpret this as a sign of existence
of an interlingua in the network.
So
there you have it. In the last weeks of 2016, as journos around the
world started penning their “was this the worst year in living memory”
thinkpieces, Google engineers were quietly documenting a genuinely
astonishing breakthrough in software engineering and linguistics.
I just thought maybe you’d want to know.
Ok, to really
understand what’s going on we probably need multiple computer science
and linguistics degrees. I’m just barely scraping the surface here. If
you’ve got time to get a few degrees (or if you’ve already got them)
please drop me a line and explain it all me to. Slowly.
Update 1:
in my excitement, it’s fair to say that I’ve exaggerated the idea of
this as an ‘intelligent’ system — at least so far as we would think
about human intelligence and decision making. Make sure you read Chris McDonald’s comment after the article for a more sober perspective.
Researchers at MIT’s Computer Science and Artificial Intelligence Lab
(CSAIL) have created an algorithm they claim can predict how memorable
or forgettable an image is almost as accurately as a human — which is to
say that their tech can predict how likely a person would be to
remember or forget a particular photo.
The algorithm performed 30 per cent better than existing algorithms
and was within a few percentage points of the average human performance,
according to the researchers.
The team has put a demo of their tool online here,
where you can upload your selfie to get a memorability score and view a
heat map showing areas the algorithm considers more or less memorable.
They have also published a paper on the research which can be found here.
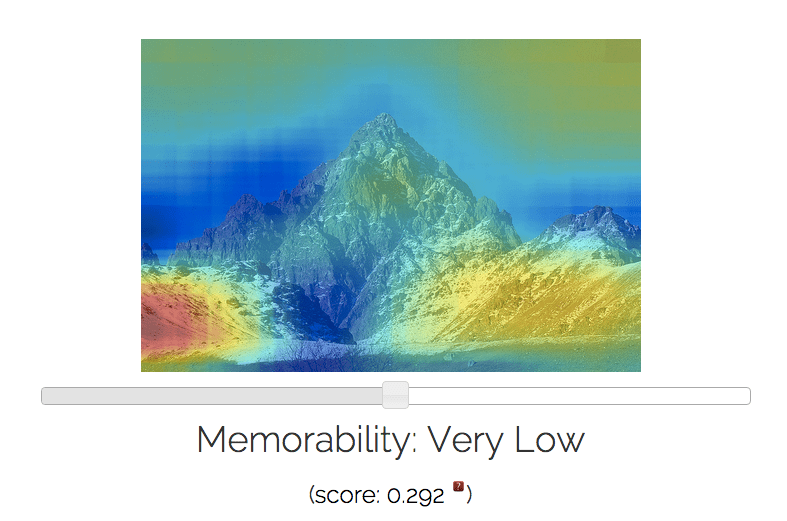
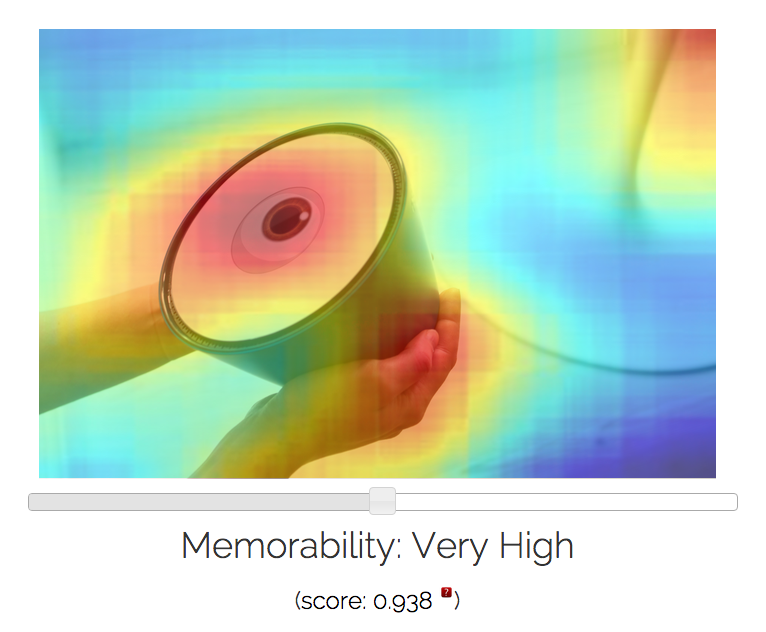
Here are some examples of images I ran through their MemNet
algorithm, with resulting memorability scores and most and least
forgettable areas depicted via heat map:
Potential applications for the algorithm are very broad indeed when
you consider how photos and photo-sharing remains the currency of the
social web. Anything that helps improve understanding of how people
process visual information and the impact of that information on memory
has clear utility.
The team says it plans to release an app in future to allow users to
tweak images to improve their impact. So the research could be used to
underpin future photo filters that do more than airbrush facial
features to make a shot more photogenic — but maybe tweak some of the
elements to make the image more memorable too.
Beyond helping people create a more lasting impression with
their selfies, the team envisages applications for the algorithm to
enhance ad/marketing content, improve teaching resources and even power
health-related applications aimed at improving a person’s capacity to
remember or even as a way to diagnose errors in memory and perhaps
identify particular medical conditions.
The MemNet algorithm was created using deep learning AI techniques,
and specifically trained on tens of thousands of tagged images from
several different datasets all developed at CSAIL — including LaMem,
which contains 60,000 images each annotated with detailed metadata about
qualities such as popularity and emotional impact.
Publishing the LaMem database alongside their paper is part of the
team’s effort to encourage further research into what they say has often
been an under-studied topic in computer vision.
Asked to explain what kind of patterns the deep-learning algorithm is
trying to identify in order to predict memorability/forgettability, PhD
candidate at MIT CSAIL, Aditya Khosla, who was lead author on a related
paper, tells TechCrunch: “This is a very difficult question and active
area of research. While the deep learning algorithms are extremely
powerful and are able to identify patterns in images that make them more
or less memorable, it is rather challenging to look under the hood to
identify the precise characteristics the algorithm is identifying.
“In general, the algorithm makes use of the objects and scenes in the
image but exactly how it does so is difficult to explain. Some initial
analysis shows that (exposed) body parts and faces tend to be highly
memorable while images showing outdoor scenes such as beaches or the
horizon tend to be rather forgettable.”
The research involved showing people images, one after another, and
asking them to press a key when they encounter an image they had seen
before to create a memorability score for images used to train the
algorithm. The team had about 5,000 people from the Amazon Mechanical
Turk crowdsourcing platform view a subset of its images, with each image
in their LaMem dataset viewed on average by 80 unique individuals,
according to Khosla.
In terms of shortcomings, the algorithm does less well on types of
images it has not been trained on so far, as you’d expect — so it’s
better on natural images and less good on logos or line drawings right
now.
“It has not seen how variations in colors, fonts, etc affect the
memorability of logos, so it would have a limited understanding of
these,” says Khosla. “But addressing this is a matter of capturing such
data, and this is something we hope to explore in the near future —
capturing specialized data for specific domains in order to better
understand them and potentially allow for commercial applications there.
One of those domains we’re focusing on at the moment is faces.”
The team has previously developed a similar algorithm for face memorability.
Discussing how the planned MemNet app might work, Khosla says there
are various options for how images could be tweaked based on algorithmic
input, although ensuring a pleasing end photo is part of the challenge
here. “The simple approach would be to use the heat map to blur out
regions that are not memorable to emphasize the regions of high
memorability, or simply applying an Instagram-like filter or cropping
the image a particular way,” he notes.
“The complex approach would involve adding or removing objects from
images automatically to change the memorability of the image — but as
you can imagine, this is pretty hard — we would have to ensure that the
object size, shape, pose and so on match the scene they are being added
to, to avoid looking like a photoshop job gone bad.”
Looking ahead, the next step for the researchers will be to try to
update their system to be able to predict the memory of a specific
person. They also want to be able to better tailor it for individual
“expert industries” such as retail clothing and logo-design.
How many training images they’d need to show an individual person
before being able to algorithmically predict their capacity to remember
images in future is not yet clear. “This is something we are still
investigating,” says Khosla.
Everyone on the internet
has come across at least couple error codes, the most well-known being
404, for page not found, while other common ones include 500, for
internal server error, or 403, for a "forbidden" page. However, with
latter, there's the growing issue of why a certain webpage has become
forbidden, or who made it so. In an effort to address things like
censorship or "legal obstacles," a new code has been published, to be
used when legal demands require access to a page be blocked: error 451.
The number is a knowing reference Fahrenheit 451,
the novel by Ray Bradbury that depicted a dystopian future where books
are banned for spreading dissenting ideas, and in burned as a way censor
the spread of information. The code itself was approved for use by the
Internet Engineering Steering Group (IESG), which helps maintain
internet standards.
The idea for code 451 originally came about around 3 years ago, when a
UK court ruling required some websites to block The Pirate Bay. Most
sites in turn used the 403 "forbidden" code, making it unclear to users
about what the issue was. The goal of 451 is to eliminate some of the
confusion around why sites may be blocked.
The use of the code is completely voluntary, however, and requires
developers to begin adopting it. But if widely implemented, it should be
able to communicate to users that some information has been taken down
because of a legal demand, or is being censored by a national
government.
As humanity debates the threats and opportunities of advanced artificialintelligence,
we are simultaneously enabling that technology through the increasing
use of personalization that is understanding and anticipating our needs
through sophisticated machine learning solutions.
In effect, while using personalization technologies in our everyday
lives, we are contributing in a real way to the development of the intelligent systems we purport to fear.
Perhaps uncovering the currently inaccessible personalization systems
is crucial for creating a sustainable relationship between humans and super–intelligent machines?
From Machines Learning About You…
Industry giants are currently racing to develop more intelligent and lucrative AI
solutions. Google is extending the ways machine learning can be applied
in search, and beyond. Facebook’s messenger assistant M is
combining deep learning and human curators to achieve the next level in
personalization.
With your iPhone you’re carrying Apple’s digital assistant Siri with you everywhere; Microsoft’s counterpart Cortana can live in your
smartphone, too. IBM’s Watson has highlighted its diverse features,
varying from computer vision and natural language processing to cooking
skills and business analytics.
At the same time, your data and personalized
experiences are used to develop and train the machine learning systems
that are powering the Siris, Watsons, Ms and Cortanas. Be it a speech
recognition solution or a recommendation algorithm, your actions and personal data affect how these sophisticated systems learn more about you and the world around you.
The less explicit fact is that your diverse interactions — your
likes, photos, locations, tags, videos, comments, route
selections, recommendations and ratings — feed learning systems that
could someday transform into super–intelligent AIs with unpredictable consequences.
As of today, you can’t directly affect how your personal data is used in these systems.
In these times, when we’re starting to use serious resources to contemplate the creation of ethical frameworks for super–intelligent AIs-to-be,
we also should focus on creating ethical terms for the use of personal
data and the personalization technologies that are powering the
development of such systems.
To make sure that you as an individual continue to have a meaningful agency in the emerging algorithmic reality, we need learning algorithms that are on your side and solutions that augment and extend your abilities. How could this happen?
…To Machines That Learn For You
Smart devices extend and augment your memory (no forgotten birthdays) and brain processing power (no calculating in your head anymore). And they augment your senses by letting you experience things beyond your immediate environment (think AR and VR).
The web itself gives you access to a huge amount of diverse
information and collective knowledge. The next step would be that smart
devices and systems enhance and expand your abilities even more. What is required for that to happen in a human-centric way?
Data Awareness And Algorithmic Accountability
Algorithmic systems and personal data are too
often seen as something abstract, incomprehensible and uncontrollable.
Concretely, how many really stopped using Facebook or Google after PRISM
came out in the open? Or after we learned that we are exposed
to continuous A/B testing that is used to develop even more powerful
algorithms?
More and more people are getting interested in data ethics and algorithmic accountability. Academics are already analyzing the effects of current data policies and algorithmic systems. Educational organizations are starting to emphasize the importance of coding and digital literacy.
Initiatives such as VRM, Indie Web and MyData are raising
awareness on alternative data ecosystems and data management practices.
Big companies like Apple and various upcoming startups are bringing
personal data issues to the mainstream discussion.
Yet we still need new tools and techniques to become more data aware
and to see how algorithms can be more beneficial for us as
unique individuals. We need apps and data visualizations with great user
experience to illuminate the possibilities of more human-centric
personalization.
It’s time to create systems that evaluate algorithmic
biases and keep them in check. More accessible algorithms and
transparent data policies are created only through wider collaboration
that brings together companies, developers, designers, users and
scientists alike.
Personal Machine Learning Systems
Personalization technologies are already augmenting your decision making and future thinking by learning from you and recommending to you what to see and do next. However, not on your own terms. Rather than letting someone else and their motives and values dictate how the algorithms work and affect your life, it’s time to create solutions, such as algorithmic angels, that let you develop and customize your own algorithms and choose how they use your data.
When you’re in control, you can let your personal learning system access previously hidden data and surface intimate insights about your own behavior, thus increasing yourself-awareness in an actionable way.
Personal learners could help you develop skills related to work or personal life, augmenting and expanding your abilities. For example, learning languages, writing or playing new games. Fitness or mediation apps powered by your personal algorithms would know you better than any personal trainer.
Google’s experiments with deep learning and image manipulation showed
us how machine learning could be used to augment creative output.
Systems capable of combining your data with different materials like images, text, sound and video could expand your abilities to see and utilize new and unexpected connections around you.
In effect, your personal algorithm can take a mind-expanding “trip” on your
behalf, letting you see music or sense other dimensions beyond normal
human abilities. By knowing you, personal algorithms can expose you to
new diverse information, thus breaking your existing filter bubbles.
Additionally, people tinkering with their personal algorithms would create more “citizen algorithm
experts,” like “citizen scientists,” coming up with new ideas,
solutions and observations, stemming from real live situations and
experiences.
However, personally adjustable algorithms for the general public are
not happening overnight, even though Google recently open-sourced parts
of its machine learning framework. But it’s possible to see how today’s
personalization experiences can someday evolve into customizable
algorithms that strengthen your agency and capacity to deal with other algorithmic systems.
AlgorithmicSelf
The next step is that your personal algorithms become a more concrete part of you, continuously evolving with you by learning from your interactions both in digital and physical environments. Youralgorithmicself combines your personal abilities and knowledge with machine learning systems that adapt to you and work for you. Be it your smartwatch, self-driving car or an intelligent home system, they can all be spirited by youralgorithmicself.
Youralgorithmicself also can connect with other algorithmic selves, thus empowering you with the accumulating collective knowledge and intelligence. To expand your existing skills and faculties, youralgorithmicself also starts to learn and act on its own, filtering information, making online transactions and comparing best options on your behalf. It makes you more resourceful, and even a better person, when you can concentrate on things that really require your human presence and attention.
Partly algorithmic humans are not bound by existing human capabilities; new skills and abilities emerge when human intelligence is extended with algorithmic selves. For example, youralgorithmicself can multiply to execute different actions simultaneously. Algorithmic selves could also create simple simulations by playing out different scenarios involving your real-life choices and their consequences, helping you to make better decisions in the future.
Algorithmic selves — tuned by your
data and personal learners — also could be the key when creating
invasive human-computer interfaces that connect digital systems directly
to your brain, expanding human brain concretely beyond the “wetware.”
But to ensure that youralgorithmicself works for your benefit, could you trust someone building that for you without you participating in the process?
Machine learning expert Pedro Domingos says in his new book “The Master Algorithm” that “[m]achine learning will not single-handedly determine the future… it’s what we decide to do with it that counts.”
Machines are still far from human intelligence. No one knows exactly when super–intelligent AIs will become concrete reality. But developing personal machine learning systems could enable us to interact with any algorithmic entities, be it an obtrusive recommendation algorithm or a super–intelligent AI.
In general, being more transparent on how learning algorithms work
and use our data could be crucial for creating ethical and sustainable artificial intelligence. And potentially, maybe we wouldn’t need to fear being overpowered by our own creations.
what3words is a geocoding system for the simple communication of precise locations. what3words encodes geographic co-ordinates into 3 dictionary words (for example, the Statue of Liberty is located at planet.inches.most). what3words is different from other alphanumeric location systems and GPS coordinates in that it displays 3 words rather than long strings of numbers or random letters or numbers. what3words has an iOS App, Android App, a website and an API that enables bi-directional conversion of what3words address and latitude/longitude co-ordinates.