Entries tagged as software
Thursday, May 02. 2013
Driving Miss dAIsy: What Google’s self-driving cars see on the road
Via Slash Gear
-----
We’ve been hearing a lot about Google‘s self-driving car lately, and we’re all probably wanting to know how exactly the search giant is able to construct such a thing and drive itself without hitting anything or anyone. A new photo has surfaced that demonstrates what Google’s self-driving vehicles see while they’re out on the town, and it looks rather frightening.

The image was tweeted by Idealab founder Bill Gross, along with a claim that the self-driving car collects almost 1GB of data every second (yes, every second). This data includes imagery of the cars surroundings in order to effectively and safely navigate roads. The image shows that the car sees its surroundings through an infrared-like camera sensor, and it even can pick out people walking on the sidewalk.
Of course, 1GB of data every second isn’t too surprising when you consider that the car has to get a 360-degree image of its surroundings at all times. The image we see above even distinguishes different objects by color and shape. For instance, pedestrians are in bright green, cars are shaped like boxes, and the road is in dark blue.
However, we’re not sure where this photo came from, so it could simply be a rendering of someone’s idea of what Google’s self-driving car sees. Either way, Google says that we could see self-driving cars make their way to public roads in the next five years or so, which actually isn’t that far off, and Tesla Motors CEO Elon Musk is even interested in developing self-driving cars as well. However, they certainly don’t come without their problems, and we’re guessing that the first batch of self-driving cars probably won’t be in 100% tip-top shape.
Cern re-creating first web page to revere early ideals
Via BBC
-----

Lost to the world: The first website. At the time, few imagined how ubiquitous the technology would become
A team at the European Organisation for Nuclear Research (Cern) has launched a project to re-create the first web page.
The aim is to preserve the original hardware and software associated with the birth of the web.
The world wide web was developed by Prof Sir Tim Berners-Lee while working at Cern.
The initiative coincides with the 20th anniversary of the research centre giving the web to the world.
According to Dan Noyes, the web manager for Cern's communication group, re-creation of the world's first website will enable future generations to explore, examine and think about how the web is changing modern life.
"I want my children to be able to understand the significance of this point in time: the web is already so ubiquitous - so, well, normal - that one risks failing to see how fundamentally it has changed," he told BBC News
"We are in a unique moment where we can still switch on the first web server and experience it. We want to document and preserve that".
The hope is that the restoration of the first web page and web site will serve as a reminder and inspiration of the web's fundamental values.
At the heart of the original web is technology to decentralise control and make access to information freely available to all. It is this architecture that seems to imbue those that work with the web with a culture of free expression, a belief in universal access and a tendency toward decentralising information.
SubversiveIt is the early technology's innate ability to subvert that makes re-creation of the first website especially interesting.
While I was at Cern it was clear in speaking to those involved with the project that it means much more than refurbishing old computers and installing them with early software: it is about enshrining a powerful idea that they believe is gradually changing the world.
I went to Sir Tim's old office where he worked at Cern's IT department trying to find new ways to handle the vast amount of data the particle accelerators were producing.
I was not allowed in because apparently the present incumbent is fed up with people wanting to go into the office.
But waiting outside was someone who worked at Cern as a young researcher at the same time as Sir Tim. James Gillies has since risen to be Cern's head of communications. He is occasionally referred to as the organisation's half-spin doctor, a reference to one of the properties of some sub-atomic particles.
Amazing dream
Mr Gillies is among those involved in the project. I asked him why he wanted to restore the first website.
"One of my dreams is to enable people to see what that early web experience was like," was the reply.
"You might have thought that the first browser would be very primitive but it was not. It had graphical capabilities. You could edit into it straightaway. It was an amazing thing. It was a very sophisticated thing."
Those not heavily into web technology may be sceptical of the idea that using a 20-year-old machine and software to view text on a web page might be a thrilling experience.
But Mr Gillies and Mr Noyes believe that the first web page and web site is worth resurrecting because embedded within the original systems developed by Sir Tim are the principles of universality and universal access that many enthusiasts at the time hoped would eventually make the world a fairer and more equal place.
The first browser, for example, allowed users to edit and write directly into the content they were viewing, a feature not available on present-day browsers.
Ideals erodedAnd early on in the world wide web's development, Nicola Pellow, who worked with Sir Tim at Cern on the www project, produced a simple browser to view content that did not require an expensive powerful computer and so made the technology available to anyone with a simple computer.
According to Mr Noyes, many of the values that went into that original vision have now been eroded. His aim, he says, is to "go back in time and somehow preserve that experience".

Soon to be refurbished: The NeXT computer that was home to the world's first website
"This universal access of information and flexibility of delivery is something that we are struggling to re-create and deal with now.
"Present-day browsers offer gorgeous experiences but when we go back and look at the early browsers I think we have lost some of the features that Tim Berners-Lee had in mind."
Mr Noyes is reaching out to ask those who were involved in the NeXT computers used by Sir Tim for advice on how to restore the original machines.
AweThe machines were the most advanced of their time. Sir Tim used two of them to construct the web. One of them is on show in an out-of-the-way cabinet outside Mr Noyes's office.
I told him that as I approached the sleek black machine I felt drawn towards it and compelled to pause, reflect and admire in awe.
"So just imagine the reaction of passers-by if it was possible to bring the machine back to life," he responded, with a twinkle in his eye.
The initiative coincides with the 20th anniversary of Cern giving the web away to the world free.
There was a serious discussion by Cern's management in 1993 about whether the organisation should remain the home of the web or whether it should focus on its core mission of basic research in physics.
Sir Tim and his colleagues on the project argued that Cern should not claim ownership of the web.
Great giveawayManagement agreed and signed a legal document that made the web publicly available in such a way that no one could claim ownership of it and that would ensure it was a free and open standard for everyone to use.
Mr Gillies believes that the document is "the single most valuable document in the history of the world wide web".
He says: "Without it you would have had web-like things but they would have belonged to Microsoft or Apple or Vodafone or whoever else. You would not have a single open standard for everyone."
The web has not brought about the degree of social change some had envisaged 20 years ago. Most web sites, including this one, still tend towards one-way communication. The web space is still dominated by a handful of powerful online companies.
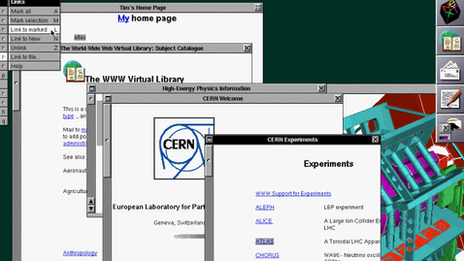
A screen shot from the first browser: Those who saw it say it was "amazing and sophisticated". It allowed people to write directly into content, a feature that modern-day browsers no longer have
But those who study the world wide web, such as Prof Nigel Shadbolt, of Southampton University, believe the principles on which it was built are worth preserving and there is no better monument to them than the first website.
"We have to defend the principle of universality and universal access," he told BBC News.
"That it does not fall into a special set of standards that certain organisations and corporations control. So keeping the web free and freely available is almost a human right."
Friday, April 19. 2013
A new way to report data center's Power and Water Usage Effectiveness (PUE and WUE)
-----
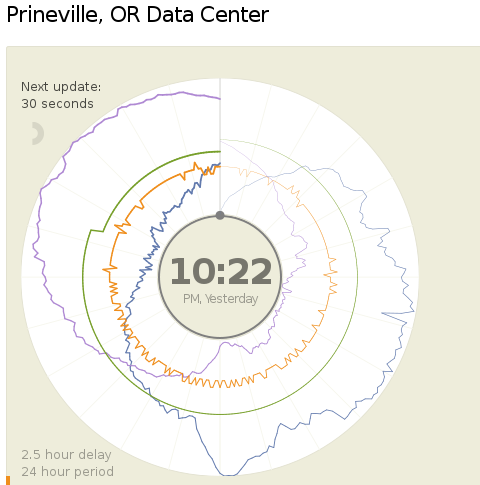
Today (18.04.2013) Facebook launched two public dashboards that report continuous, near-real-time data for key efficiency metrics – specifically, PUE and WUE – for our data centers in Prineville, OR and Forest City, NC. These dashboards include both a granular look at the past 24 hours of data and a historical view of the past year’s values. In the historical view, trends within each data set and correlations between different metrics become visible. Once our data center in Luleå, Sweden, comes online, we’ll begin publishing for that site as well.
We began sharing PUE for our Prineville data center at the end of Q2 2011 and released our first Prineville WUE in the summer of 2012. Now we’re pulling back the curtain to share some of the same information that our data center technicians view every day. We’ll continue updating our annualized averages as we have in the past, and you’ll be able to find them on the Prineville and Forest City dashboards, right below the real-time data.
Why are we doing this? Well, we’re proud of our data center efficiency, and we think it’s important to demystify data centers and share more about what our operations really look like. Through the Open Compute Project (OCP), we’ve shared the building and hardware designs for our data centers. These dashboards are the natural next step, since they answer the question, “What really happens when those servers are installed and the power’s turned on?”
Creating these dashboards wasn’t a straightforward task. Our data centers aren’t completed yet; we’re still in the process of building out suites and finalizing the parameters for our building managements systems. All our data centers are literally still construction sites, with new data halls coming online at different points throughout the year. Since we’ve created dashboards that visualize an environment with so many shifting variables, you’ll probably see some weird numbers from time to time. That’s OK. These dashboards are about surfacing raw data – and sometimes, raw data looks messy. But we believe in iteration, in getting projects out the door and improving them over time. So we welcome you behind the curtain, wonky numbers and all. As our data centers near completion and our load evens out, we expect these inevitable fluctuations to correspondingly decrease.
We’re excited about sharing this data, and we encourage others to do the same. Working together with AREA 17, the company that designed these visualizations, we’ve decided to open-source the front-end code for these dashboards so that any organization interested in sharing PUE, WUE, temperature, and humidity at its data center sites can use these dashboards to get started. Sometime in the coming weeks we’ll publish the code on the Open Compute Project’s GitHub repository. All you have to do is connect your own CSV files to get started. And in the spirit of all other technologies shared via OCP, we encourage you to poke through the code and make updates to it. Do you have an idea to make these visuals even more compelling? Great! We encourage you to treat this as a starting point and use these dashboards to make everyone’s ability to share this data even more interesting and robust.
Lyrica McTiernan is a program manager for Facebook’s sustainability team.
Wednesday, April 17. 2013
Google Mirror API now available

Tuesday, April 16. 2013
Oculus Rift finally gets the reaction virtual reality always wanted
Via Slash Gear
-----
We’ve already heard plenty about the Oculus Rift virtual reality headset, and while we youngsters are pretty amazed by the technology, nobody has their mind blown more than the elderly, who could only dream about such technology back in their younger days. Recently, a 90-year-old grandmother ended up trying out the Oculus Rift for herself, and she was quite amazed.

Imagimind Studio developer Paul Rivot ended up grabbing an Oculus Rift in order to play around with it and develop some games, but he took a break from that and decided to give his grandmother a little treat, by strapping the Oculus Rift to her head in order to experience a bit of virtual reality herself.
The video is quite entertaining to watch, and we can’t imagine what’s going on inside of her head, knowing that she never grew up with such technology as the Oculus Rift, let alone 3D video games. She even gets to the point where she thought the images being displayed were actual images taken on-location, when in fact it’s all 3D-rendered on a computer.
Currently, the Oculus Rift is out in the wild for developers only at this point, and there’s no announced release date for the device, although the company has noted that it should arrive to the general public before the 2014 holiday season. In the meantime, it’s videos like this that only excite us even more.
Tuesday, April 09. 2013
A Problem Google Has Created for Itself
Via The Atlantic
-----
Over the eons I've been a fan of, and sucker for, each latest automated system to "simplify" and "bring order to" my life. Very early on this led me to the beautiful-and-doomed Lotus Agenda for my DOS computers, and Actioneer for the early Palm. For the last few years Evernote has been my favorite, and I really like it. Still I always have the roving eye.
So naturally I have already downloaded the Android version of Google's new app for collecting notes, photos, and info, called Google Keep, with logo at right. This early version has nothing like Evernote's power or polish, but you can see where Google is headed.

Thursday, April 04. 2013
Writing Open Source Software? Make Sure You Know Your Copyright Rights
Via SmartBear
-----

Open source is all fine and dandy, but before throwing yourself – and untold lines of code – into a project, make sure you understand exactly what’s going to happen to your code’s copyrights. And to your career.
I know. If you wanted to be a lawyer, you would have gone to law school instead of spending your nights poring over K&R. Tough. In 2013, if you're an open source programmer you need to know a few things about copyright law. If you don't, bad things can happen. Really bad things.
Before launching into this topic, I must point out that I Am Not A Lawyer (IANAL). If you have a specific, real-world question, talk to someone who is a lawyer. Better still, talk to an attorney who specializes in intellectual property (IP) law.
Every time you write code, you're creating copyrighted work. As Simon Phipps, President of the OSI Open Source Initiative (OSI) said when I asked him about programmer copyright gotchas, "The biggest one is the tendency for headstrong younger developers to shun copyright licensing altogether. When they do that, they put all their collaborators at risk and themselves face potential liability claims.”
Developers need to know that copyright is automatic under the Berne Convention, Phipps explained. Since that convention was put into place, all software development involve copying and derivatives, Phipps said; all programming without a license potentially infringes on copyright. “It may not pose a problem today, but without a perpetual copyright license collaborators are permanently at risk."
“You can pretend copyright doesn't exist all you want, but one day it will bite you,” Phipps continued. “That's why [if you want to start a new project] you need to apply an open source license.” If you want public domain, use the MIT license; it's very simple and protects you and your collaborators from these risks. If you really care, use a modern patent-protecting license like Apache, MPLv2, or GPLv3. Just make sure you get one.
Who Owns That Work-for-Hire Code? It Might Be You
You should know when you own the copyright and when your employer or consulting client does. If the code you wrote belongs to the boss, after all, it isn’t yours. And if it isn’t yours, you don’t have the right to assign the copyright to an open source project. So let’s look, first, at the assumption that employment or freelance work is automatically work for hire.
For example, that little project of yours that you've been working on during your off-hours at work? It's probably yours but... as Daniel A. Tysver, a partner at Beck & Tysver wrote on BitLaw:
"Software developers should pay close attention to copyright ownership issues when hiring computer programmers. Programs written by salaried employees will, in almost all cases, be considered works made for hire. …
As a result, the software developer itself will be considered the author of the software written by those employees, and ownership will properly reside with the developer. However, the prudent developer will nonetheless have employees sign agreements whereby they agree to assign all copyrights in software they develop to the software developer. The reason for this prudence is that the determination of who is an employee under the law of agency requires an analysis of many factors and might cause unexpected results in rare cases. In addition, the work made for hire doctrine requires that the work be done 'within the scope of' the employee's employment. Generally, programs written by a software programmer employee will be within the scope of his or her employment, but this again is an ambiguous phrase that is best not to rely upon."
What if you're a freelance programmer and you're writing code under a "work for hire" contract? Does your client then own the copyright to the code you wrote – whether or not it’s part of an open source project as well? Well... actually maybe they do, maybe they don't.
Tysver continued:
Software developers must be especially careful when hiring contract programmers. In order for the work of contract programmers to be considered a work made for hire, three facts must exist:
The program must be specially ordered or commissioned;
The contract retaining the programmer must be in writing and must explicitly say that the programs created under the agreement are to be considered a work made for hire; and
The program created must fall into one of the nine enumerated categories of work.
The first element will generally be true when the programmer is hired to work on a specific project. The second element can be met through careful drafting of contract programmer's retainer agreement. The third element, however, can be more difficult. Computer software programs are not one of the nine enumerated categories. The best bet is to fit the software program under the definition of an "audiovisual work." While some software programs are clearly audiovisual works, it is unclear whether courts will allow this phrase to include all computer software programs. Thus, a software developer cannot be sure whether the contract programmer is creating a work made for hire.
It is best to draft an agreement which reflects this uncertainty. The agreement should state that the work is a work made for hire. However, the agreement should also state that if the software is not considered a work made for hire, the contract programmer agrees to assign the copyright in the software to the software developer.
Finally, when hiring a company to provide contract programming services, it is important to make sure that the copyright ownership passes all the way from the individual programmer to the software developer. Therefore, the software developer should review not only its agreement with the company providing the services, but also the agreements by which that company hires individual programmers.
Is he saying that that work-for-hire contract you signed that didn't spell who got the copyright for the code means you may still have the copyright? Well, yes, actually he is. If you take a close look at U.S. Copyright law (PDF), you'll find that there are nine classes of work that are described as “work made for hire” (WMFH). None of them are programming code.
So, as an author wrote on Law-Forums.org, under the nom de plume of morcan, “Computer programs do not generally fall into any of the statutory categories for commissioned WMFH and therefore, simply calling it that still won't conform to the statute."
He or she continued, "Therefore, you can certainly have a written WMFH agreement (for what it's worth) that expressly outlines the intent of the parties that you be the 'author and owner of the copyright' of the commissioned work, but you still need a (separate) transfer and assignment of all right, title and interest of the contractor's copyright of any and all portions of the works created under the project, which naturally arises from his or her being the author of the WMFH." In other words, without a “transfer of copyright ownership” clause in your contract, you the programmer, not the company that gave you the contract, may still have the copyright.
 That
can lead to real trouble. "I have actually seen major corporate
acquisitions get scuttled because someone at the target software company
had 'contracted programmers' under WMFH agreements but failed to obtain
the necessary written transfer of the contractors' copyrights,” morcan
added.
That
can lead to real trouble. "I have actually seen major corporate
acquisitions get scuttled because someone at the target software company
had 'contracted programmers' under WMFH agreements but failed to obtain
the necessary written transfer of the contractors' copyrights,” morcan
added.
Rich Santalesa, senior counsel at InformationLawGroup, agreed with morcan. “What tends to happen is that cautious (read: solid) software/copyright attorneys use a belt and suspenders approach, adding into the development agreement that it’s 'to the full extent applicable' a 'Work for Hire' — in the event, practically, that the IRS or some other taxing entity says 'no that person is an employee and not an independent contractor,’” said Santalesa. They also include a transfer and assignment provision that is effective immediately upon execution.
“Whenever and wherever possible we [copyright attorneys representing the contracting party for the work] attempt to apply a Work for Hire situation,” explained Santalesa. “So the writer/programmer is, for copyright purposes, never the 'legal author.' It can get tricky, and as always the specific facts matter, with the proof ultimately in the contractual pudding that comes out of the oven.”
What I take all this to mean is you should make darn sure that both you and the company that contracted you have a legal contract spelling out exactly what happens to the copyright of any custom code. Simply saying something is a work for hire doesn't cut the mustard.
Now, Add in Open Source Contributions
These same concerns also apply to open source projects. Most projects have some kind of copyright assignment agreements (CAAs) or copyright licensing agreements (CLAs) you must sign before the code you write is committed to the project. In CAAs, you assign your copyright to a company or organization; in CLAs you give the group a broad license to work with your code.
While some open source figures, such as Bradley Kuhn of the Software Freedom Conservancy, don't want either kind of copyright agreement in open source software, almost all projects have them.
And they can often cause headaches.
Take, for example, the recent copyright fuss in the GnuTLS project, a free software implementation of the SSL (Secure Socket Layer) protocol. The project's founder, and one of its two main authors, Nikos Mavrogiannopoulos, announced in December 2012 that he was moving the project outside the infrastructure of the GNU project because of a major disagreement with the Free Software Foundation’s (FSF) decisions and practices. “I no longer consider GnuTLS a GNU project,” he wrote, “and future contributions are not required to be under the copyright of FSF.”
Richard M. Stallman, founder of GNU and the FSF, wasn't having any of that! In an e-mail entitled, GNUTLS is not going anywhere, Stallman, a.k.a. RMS, replied, "You cannot take GNUTLS out of the GNU Project. You cannot designate a non-GNU program as a replacement for a GNU package. We will continue the development of GNUTLS."
You see, while you don't have to assign your copyright to the FSF when you create a GNU project, the FSF won't protect the project's IP under the GPL unless you do make that assignment. And, back when the project started, Mavrogiannopoulos had transferred the copyrights. In addition, no matter where you are in the world, as RMS noted, if you do elect this path, the copyright goes to the U.S. FSF, not to one of its sister organizations.
After many heated words, this particular conflict calmed down. Mavrogiannopoulos now wishes he had made a different decision. “I pretty much regret transferring all rights to FSF, but it seems there is nothing I can do to change that.” He can fork the code, but he can't take the project's name with him since that's part of the copyright.
That may sound as though it’s getting far afield of The Least I Need to Know About Copyright as an Open Source Developer, but bear with me for a moment. Because it raises several troubling issues
As Michael Kerrisk, a LWN.net author put it, "The first of these problems has already been shown above: Who owns the project? The GnuTLS project was initiated in good faith by Nikos as a GNU project. Over the lifetime of the project, the vast majority of the code contributed to the project has been written by two individuals, both of whom (presumably) now want to leave the GNU project. If the project had been independently developed, then clearly Nikos and Simon would be considered to own the project code and name. However, in assigning copyright to the FSF, they have given up the rights of owners.”
However, there's more. As Kerrisk pointed out, “The ability of the FSF—as the sole copyright holder—to sue license violators is touted as one of the major advantages of copyright assignment. However, what if, for one reason or another, the FSF chooses not to exercise its rights?" What advantage does the programmer get then from assigning his or her copyright?
Finally, Kerrisk added, there's a problem that occurs with assignment both to companies and to non-profits. “The requirement to sign a copyright assignment agreement imposes a barrier on participation. Some individuals and companies simply won't bother with doing the paperwork. Others may have no problem contributing code under a free software license, but they (or their lawyers) balk at giving away all rights in the code.”
Can You Contribute to a Project? Legally?
The barrier to participation isn't just theoretical. Kerrisk cites the example of Greg Kroah-Hartman, the well-known Linux kernel developer. Kroah-Hartman, during a conversation about whether the Gentoo Linux distribution should seek copyright assignments, said, "On a personal note, if any copyright assignment was in place, I would never have been able to become a Gentoo developer, and if it were to be put into place, I do not think that I would be allowed to continue to be one. I'm sure lots of other current developers are in this same situation.”
Other non-profit open source groups take different approaches. The Apache Foundation, for instance, asks for "a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare derivative works of, publicly display, publicly perform, sublicense, and distribute Your Contributions and such derivative works."
If you have any questions about a particular group—and you should have questions—check to see exactly what rights the group requires in its contributor license agreement. Then, if you still have questions (you probably will) check with the organization or an IP attorney. This is not a check-mark that you ignore as blithely as all those websites where you click on “I have read and will adhere to the privacy policy.” In a literal sense you are committing yourself, or at least the code you wrote in all those bleary-eyed debugging sessions that required three cups of coffee.
The assignment of rights is not just a copyright problem for non-profit open source groups. Several commercial open source organizations ask you to give them your contributed code's copyright for their projects. Others, such as Oracle (PDF) asks for joint copyright to any of your contributions for its OpenJDK, GlassFish, and MySQL projects.
Some companies, such as Ubuntu Linux's parent company, Canonical, have backed off on asking for these claims. Canonical, for instance, now states that “You retain ownership of the Copyright in Your Contribution and have the same rights to use or license the Contribution which You would have had without entering into the Agreement." Red Hat, in its Fedora Project Contributor Agreement now asks only that you have the right to grant use of the copyrighted code and that it be licensed under either the Creative Commons Attribution-ShareAlike 3.0 Unported License or a variation of the MIT License. If you don't know what is being asked of you, get expert advice.
With all these differences in how to handle copyright disagreements you might wonder why someone hasn't tried to come with one common way of handling them. Well, they have: It’s called Project Harmony. However, Project Harmony hasn't picked up a lot of support and its copyright templates have not been widely accepted.
The bottom line isn't that you have to become a lawyer to code—although I could understand how you might feel that way!—but you do have to carefully examine what rights you have to your code. You need to understand what rights you're giving up or sharing with an open source license and a particular project. And if you're still puzzled, you need to seek expert legal help.
You don't want to find yourself in a copyright quagmire. Good luck.
Monday, March 25. 2013
New Kinect SDK now out
Via Rob Miles
-----
The new SDK for the Kinect sensor is now available for free download. This brings with it a whole ton of upgrades for those who want to make their computers more aware of their surroundings. There are new sensor modes and all kinds of good stuff. There is also a sizeable gallery of sample programs which you can just play with. This makes it worth a look even if you don’t intend to write any programs for the sensor, but just want to get a feel for the kinds of wonderful things it can do.
The highlight, which I’m really looking forward to playing with, is “Kinect Fusion”. This lets you use the sensor as kind of hand held 3D scanner. You wave the Kinect around a scene and the program will build up a 3D model of what is in front of it. You’ll need a fairly beefy graphics card in your PC to make it work quickly (it uses the power of the GPU to crunch the scene data), but the results look really impressive. I’m really looking forward to printing little plastic models of me that I can give as Christmas presents…
You can download the SDK from here.
Tuesday, March 19. 2013
Google Details Glass Mirror API At SXSW, Shows Off Gmail, NYT, Evernote And Path Integrations
Via TechCrunch
-----

At SXSW this afternoon, Google provided developers with a first glance at the Google Glass Mirror API, the main interface between Google Glass, Google’s servers and the apps that developers will write for them. In addition, Google showed off a first round of applications that work on Glass, including how Gmail works on the device, as well as integrations from companies like the New York Times, Evernote, Path and others.
The Mirror API is essentially a REST API, which should make developing for it very easy for most developers. The Glass device essentially talks to Google’s servers and the developers’ applications then get the data from there and also push it to Glass through Google’s APIs. All of this data is then presented on Glass through what Google calls “timeline cards.” These cards can include text, images, rich HTML and video. Besides single cards, Google also lets developers use what it calls bundles, which are basically sets of cards that users can navigate using their voice or the touchpad on the side of Glass.
It looks like sharing to Google+ is a built-in feature of the Mirror API, but as Google’s Timothy Jordan noted in today’s presentation, developers can always add their own sharing options, as well. Other built-in features seem to include voice recognition, access to the camera and a text-to-speech engine.
Glass Rules
Because Glass is a new and unique form factor, Jordan also noted, Google is setting a few rules for Glass apps. They shouldn’t, for example, show full news stories but only headlines, as everything else would be too distracting. For longer stories, developers can always just use Glass to read text to users.
Essentially, developers should make sure that they don’t annoy users with too many notifications, and the data they send to Glass should always be relevant. Developers should also make sure that everything that happens on Glass should be something the user expects, said Jordan. Glass isn’t the kind of device, he said, where a push notification about an update to your app makes sense.
Using Glass With Gmail, Evernote, Path and Others

As part of today’s presentation, Jordan also detailed some Glass apps Google has been working on itself, and apps that some of its partners have created. The New York Times app, for example, shows headlines and then lets you listen to a summary of the article by telling Glass to “read aloud.” Google’s own Gmail app uses voice recognition to answer emails (and it obviously shows you incoming mail, as well). Evernote’s Skitch can be used to take and share photos, and Jordan also showed a demo of social network Path running on Glass to share your location.
So far, there is no additional information about the Mirror API on any of Google’s usual sites, but we expect the company to release more information shortly and will update this post once we hear more.
Tuesday, February 19. 2013
Technical Reference – Intel® HTML5 App Porter Tool - BETA
Via Intel Software
-----
Introduction
The Intel® HTML5 App Porter Tool - BETA is an application that helps mobile application developers to port native iOS* code into HTML5, by automatically translating portions of the original code into HTML5. This tool is not a complete solution to automatically port 100% of iOS* applications, but instead it speeds up the porting process by translating as much code and artifacts as possible.
It helps in the translation of the following artifacts:
- Objective-C* (and a subset of C) source code into JavaScript
- iOS* API types and calls into JavaScript/HTML5 objects and calls
- Layouts of views inside Xcode* Interface Builder (XIB) files into HTML + CSS files
- Xcode* project files into Microsoft* Visual Studio* 2012 projects
This document provides a high-level explanation about how the tool works and some details about supported features. This overview will help you determine how to process the different parts of your project and take the best advantage from the current capabilities.
How does it work?
The Intel® HTML5 App Porter Tool - BETA is essentially a source-to-source translator that can handle a number of conversions from Objective-C* into JavaScript/HTML5 including the translation of APIs calls. A number of open source projects are used as foundation for the conversion including a modified version of Clang front-end, LayerD framework and jQuery Mobile for widgets rendering in the translated source code.
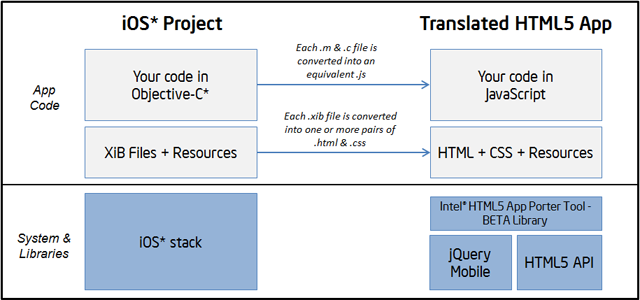
Translation of Objective-C into JavaScript
At a high level, the transformation pipeline looks like this:
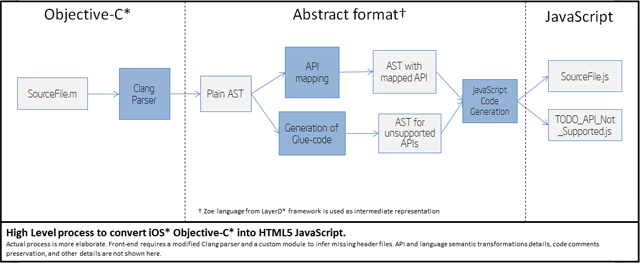
This pipeline follows the following stages:
- Parsing of Objective-C* files into an intermediate AST (Abstract Syntax Tree).
- Mapping of supported iOS* API calls into equivalent JavaScript calls.
- Generation of placeholder definitions for unsupported API calls.
- Final generation of JavaScript and HTML5 files.
About coverage of API mappings
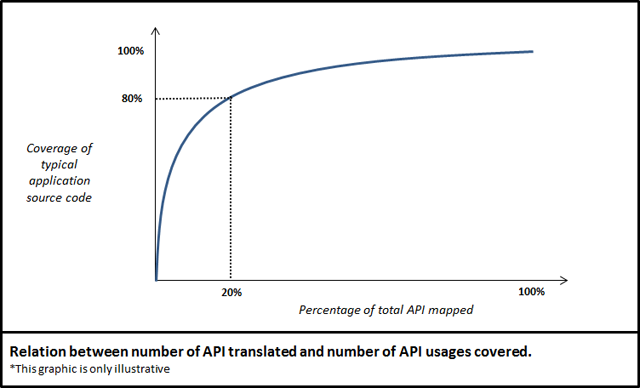
Mapping APIs from iOS* SDK into JavaScript is a task that involves a good deal of effort. The iOS* APIs have thousands of methods and hundreds of types. Fortunately, a rather small amount of those APIs are in fact heavily used by most applications. The graph below conceptually shows how many APIs need to be mapped in order to have certain level of translation for API calls .
Currently, the Intel® HTML5 App Porter Tool - BETA supports the most used types and methods from:
- UIKit framework
- Foundation framework
Additionally, it supports a few classes of other frameworks such as CoreGraphics. For further information on supported APIs refer to the list of supported APIs.
Generation of placeholder definitions and TODO JavaScript files
For the APIs that the Intel® HTML5 App Porter Tool - BETA cannot translate, the tool generates placeholder functions in "TODO" files. In the translated application, you will find one TODO file for each type that is used in the original application and which has API methods not supported by the current version. For example, in the following portion of code:
1 |
-(void)sampleMethod |
2 |
{ |
3 |
UIButton* myButton = [UIButton buttonWithType:UIButtonTypeRoundedRect]; |
4 |
|
5 |
[myButton setTitle:text forState:UIControlStateNormal]; |
6 |
|
7 |
myButton.showsTouchWhenHighlighted = YES; |
8 |
} |
If property setter for showsTouchWhenHighligthed is not supported by the tool, it will generate the following placeholder for you to provide its implementation:
1 |
APT.Button.prototype.setShowsTouchWhenHighligthed = function(arg1) { |
2 |
//
================================================================ //
REFERENCES TO THIS FUNCTION: // line(108): SampleCode.m // In scope:
Test.sampleMethod // Actual arguments types: [boolean] // Expected
return type: [unknown type] // |
3 |
if (APT.Global.THROW_IF_NOT_IMPLEMENTED) |
4 |
{ |
5 |
// TODO remove exception handling when implementing this method |
6 |
throw "Not implemented function: APT.Button.setShowsTouchWhenHighligthed"; |
7 |
} |
8 |
}; |
These placeholders are created for methods, constants, and types that the tool does not support. Additionally, these placeholders may be generated for APIs other than the iOS* SDK APIs. If some files from the original application (containing class or function definitions) are not included in the translation process, the tool may also generate placeholders for the definitions in those missing files.
In each TODO file, you will find details about where those types, methods, or constants are used in the original code. Moreover, for each function or method the TODO file includes information about the type of the arguments that were inferred by the tool. Using these TODO files, you can complete the translation process by the providing the placeholders with your own implementation for that API.
Translation of XIB files into HTML/CSS code
The Intel® HTML5 App Porter Tool - BETA translates most of the definitions in the Xcode* Interface Builder files (i.e.,
XIB files) into equivalent HTML/CSS code. These HTML files use JQuery*
markup to define layouts equivalent to the views in the original XIB
files. That markup is defined based on the translated version of the
view classes and can be accessed programmatically.
Moreover, most
of the events that are linked with handlers in the original application
code are also linked with their respective handles in the translated
version. All the view controller objects, connection logic between
objects and event handlers from all translated XIB files are included in
the XibBoilerplateCode.js. Only one XibBoilerplateCode.js file is created per application.
The figure below shows how the different components of each XIB file are translated.
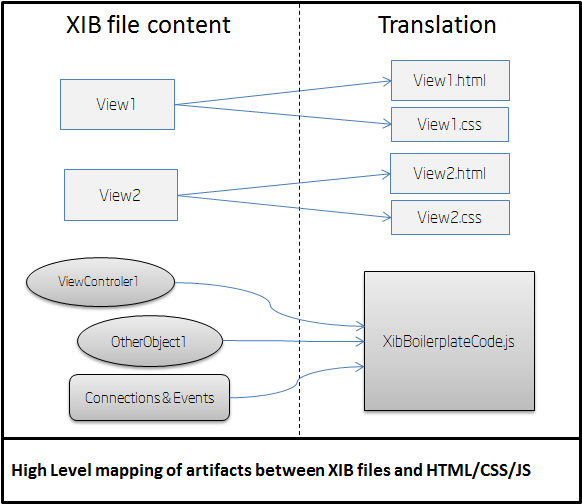
This is a summary of the artifacts generated from XIB files:
- For each view inside an XIB file, a pair of HTML+CSS files is generated.
- Objects inside XIB files, such as Controllers and Delegates, and instantiation code are generated in the
XibBoilerplateCode.jsfile. - Connections between objects and events handlers for views described
inside XIB files are also implemented by generated code in the
XibBoilerplateCode.jsfile.
For further information on supported widgets and properties refer to the Supported .XIB file featuressection.
Architecture of translated applications
The translated application keeps the very same high level structure as the original one. Constructs such as Objective-C* interfaces, categories, C structs, functions, variables, and statements are kept without significant changes in the translated code but expressed in JavaScript.
The execution of the Intel® HTML5 App Porter Tool – BETA produces a set of files that can be divided in four groups:
- The translated app code: These are the JavaScript files that were created as a translation from the original app Objective-C* files.
- For each translated module (i.e. each
.mfile) there should be a.jsfile with a matching name. - The default.html file is the entry point for the HTML5 app, where all the other
.jsfiles are included. - Additionally, there are some JavaScript files included in the
\libfolder that corresponds to some 3rd party libraries and Intel® HTML5 App Porter Tool – BETA library which implements most of the functionality that is not available in HTML5. - Translated
.xibfiles (if any): For each translated.xibfile there should be.htmland.cssfiles with matching names. These files correspond to their HTML5 version. - “ToDo” JavaScript files: As the translation of some of the
APIs in the original app may not be supported by the current version,
empty definitions as placeholders for those not-mapped APIs are
generated in the translated HTML5 app. This “ToDo” files contain those
placeholders and are named after the class of the not-mapped APIs. For
instance, the placeholders for not-mapped methods of the
NSDataclass, would be located in a file named something liketodo_api_js_apt_data.jsortodo_js_nsdata.js. - Resources: All the resources from the original iOS* project will be copied to the root folder of the translated HTML5 app.
The generated JavaScript files have names which are practically the
same as the original ones. For example, if you have a file called AppDelegate.m in the original application, you will end up with a file called AppDelegate.js
in the translated output. Likewise, the names of interfaces, functions,
fields, or variables are not changed, unless the differences between
Objective-C* and JavaScript require the tool to do so.
In short, the high level structure of the translated application is practically the same as the original one. Therefore, the design and structure of the original application will remain the same in the translated version.
About target HTML5 APIs and libraries
The Intel® HTML5 App Porter Tool - BETA both translates the syntax and semantics of the source language (Objective-C*) into JavaScript and maps the iOS* SDK API calls into an equivalent functionality in HTML5. In order to map iOS* API types and calls into HTML5, we use the following libraries and APIs:
- The standard HTML5 API: The tool maps iOS* types and calls into plain standard objects and functions of HTML5 API as its main target. Most notably, considerable portions of supported Foundation framework APIs are mapped directly into standard HTML5. When that is not possible, the tool provides a small adaptation layer as part of its library.
- The jQuery Mobile library: Most of the UIKit widgets are mapped jQuery Mobile widgets or a composite of them and standard HTML5 markup. Layouts from XIB files are also mapped to jQuery Mobile widgets or other standard HTML5 markup.
- The Intel® HTML5 App Porter Tool - BETA library:
This is a 'thin-layer' library build on top of jQuery Mobile and HTML5
APIs and implements functionality that is no directly available in those
libraries, including Controller objects, Delegates, and logic to
encapsulate jQuery Mobile widgets. The library provides a facade very
similar to the original APIs that should be familiar to iOS* developers.
This library is distributed with the tool and included as part of the
translated code in the
libfolder.
You should expect that future versions of the tool will incrementally add more support for API mapping, based on further statistical analysis and user feedback.
Translated identifier names
In Objective-C*, methods names can be composed by several parts
separated with colons (:) and the methods calls interleaved these parts
with the actual arguments. Since that peculiar syntactic construct is
not available in JavaScript, those methods names are translated by
combining all the methods parts replacing the colons (:) with
underscores (_). For example, a function called initWithColor:AndBackground: is translated to use the name initWithColor_AndBackground
Identifier names, in general, may also be changed in the translation if there are any conflicts in JavaScript scope. For example, if you have duplicated names for interfaces and protocol, or one instance method and one class method that share the same name in the same interface. Because identifier scoping rules are different in JavaScript, you cannot share names between fields, methods, and interfaces. In any of those cases, the tool renames one of the clashing identifiers by prepending an underscore (_) to the original name.
Additional tips to get the most out of the Intel® HTML5 App Porter Tool – BETA
Here is a list of recommendations to make the most of the tool.
- Keep your code modular
Having a well-designed and architected source code may help you to take the most advantage of the translation performed by tool. If the modules of the original source code can be easily decoupled, tested, and refactored the same will be true for the translated code. Having loosely coupled modules in your original application allows you to isolate the modules that are not translated well into JavaScript. In this way, you should be able to simply skip those modules and only select the ones suitable for translation. - Avoid translating third party libraries source code with equivalents in JavaScript
For some iOS* libraries you can find replacement libraries or APIs in JavaScript. Common examples are libraries to parse JSON, libraries to interact with social networks, or utilities libraries such as Box2D* for games development. If your project originally uses the source code of third party library which has a replacement version in JavaScript, try to use the replacement version instead of translated code, whenever it is possible. - Isolate low level C or any C++ code behind Objective-C* interfaces: The tool currently supports translating from Objective-C*, only. It covers the translation of most of C language constructs, but it does not support some low level features such as unions, pointers, or bit fields. Moreover, the current version does not support C++ or Objective-C++ code. Because of this limitation, it is advisable to encapsulate that code behind Objective-C interfaces to facilitate any additional editing, after running the tool.
In conclusion, having a well-designed application in the first place will make your life a lot easier when porting your code, even in a completely manual process.
Further technical information
This section provides additional information for developers and it is not required to effectively use Intel® HTML5 App Porter Tool - BETA. You can skip this section if you are not interested in implementation details of the tool.
Implementation of the translation steps
Here, you can find some high level details of how the different processing steps of the Intel® HTML5 App Porter Tool - BETA are implemented.
Objective-C* and C files parsing
To parse Objective-C* files, the tool uses a modified version of clang parser. A custom version of the parser is needed because:
- iOS* SDK header files are not available.
- clang is only used to parse the source files (not to compile them) and dump the AST to disk.
The following picture shows the actual detailed process for parsing .m and .c files:
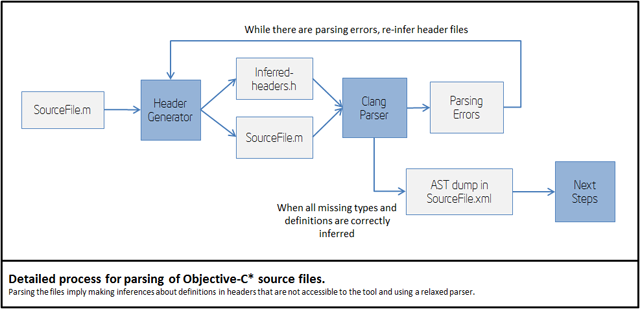
Missing iOS* SDK headers are inferred as part of the parsing process. The header inference process is heuristic, so you may get parsing errors, in some cases. Thus, you can help the front-end of the tool by providing forward declaration of types or other definitions in header files that are accessible to the tool.
Also, you can try the "Header Generator" module in individual files
by using the command line. In the binary folder of the tool, you will
find an executable headergenerator.exe that rubs that process.
Objective-C* language transformation into JavaScript
The translation of Objective-C* language into JavaScript involves a number of steps. We can divide the process in what happens in the front-end and what is in the back-end.
Steps in the front-end:
- Parsing .m and .c into an XML AST.
- Parsing comments from .m, .c and .h files and dumping comments to disk.
- Translating Clang AST into Zoe AST and re-appending the comments.
The output of the front-end is a Zoe program. Zoe is an intermediate abstract language used by LayerD framework; the engine that is used to apply most of the transformations.
The back-end is fully implemented in LayerD by using compile time classes of Zoe language that apply a number of transformations in the AST.
Steps in the back-end:
- Handling some Objective-C* features such as properties getter/setter injection and merging of categories into Zoe classes.
- Supported iOS* API conversion into target JavaScript API.
- Injection of not supported API types, or types that were left outside of the translation by the user.
- Injection of dummy methods for missing API transformations or any other code left outside of the translation by the user.
- JavaScript code generation.
iOS* API mapping into JavaScript/HTML5
The tool supports a limited subset of iOS* API. That subset is developed following statistical information about usage of each API. Each release of the tool will include support for more APIs. If you miss a particular kind of API your feedback about it will be very valuable in our assessment of API support.
For some APIs such as Arrays and Strings the tool provides direct mappings into native HTML5 objects and methods. The following table shows a summary of the approach followed for each kind of currently supported APIs.
| Framework | Mapping design guideline |
| Foundation | Direct mapping to JavaScript when possible. If direct mapping is not possible, use a new class built over standard JavaScript. |
| Core Graphics | Direct mapping to Canvas and related HTML5 APIs when possible. If direct mapping is not possible, use a new class built over standard JavaScript. |
| UIKit Views | Provide a similar class in package APT, such as APT.View for UIView, APT.Label for UILabel, etc. All views are implemented using jQuery Mobile markup and library. When there are not equivalent jQuery widgets we build new ones in the APT library. |
| UIKit Controllers and Delegates | Because HTML5 does not provide natively controllers or delegate objects the tool provides an implementation of base classes for controllers and delegates inside the APT package. |
Direct mapping implies that the original code will be transformed into plain JavaScript without any type of additional layer. For example,
1 |
NSArray anArray = [NSArray arrayWithObjects:@"One",@"Two",@"Three",nil]; |
2 |
// Is translated to JavaScript code: |
3 |
var anArray = ["One", "Two", "Three"]; |
The entire API mapping happens in the back-end of the tool. This process is implemented using compile time classes and other infrastructure provided by the LayerD framework.
XIB files conversion into HTML/CSS
XIB files are converted in two steps:
- XIB parsing and generation of intermediate XML files.
- Intermediate XML files are converted into final HTML, CSS and JavaScript boilerplate code.
The first step generates one XML file - with extension .gld - for each view inside the XIB file and one additional XML file with information about other objects inside XIB files and connections between objects and views such as outlets and event handling.
The second stage runs inside the Zoe compiler of LayerD to convert intermediate XML files into final HTML/CSS and JavaScript boilerplate code to duplicate all the functionality that XIB files provides in the original project.
Generated HTML code is as similar as possible to static markup used by jQuery Mobile library or standard HTML5 markup. For widgets that do not have an equivalent in jQuery Mobile, HTML5, or behaves differently, simple markup is generated and handled by classes in APT library.
Supported iOS SDK APIs for Translation
The following table details the APIs supported by the current version of the tool.
Notes:
-
Types refers to Interfaces, Protocols, Structs, Typedefs or Enums
-
Type 'C global' mean that it is not a type, but it is a supported global C function or constant
-
Colons in Objective-C names are replaced by underscores
-
Objective-C properties are detailed as a pair of getter/setter method names such as 'title' and 'setTitle'
-
Objective-C static members appear with a prefixed underscore like in '_dictionaryWithObjectsAndKeys'
-
Inherited members are not listed, but are supported. For example, NSArray supports the 'count' method. The method 'count' is not listed in NSMutableArray, but it is supported because it inherits from NSArray
Quicksearch
Popular Entries
- The great Ars Android interface shootout (131504)
- Norton cyber crime study offers striking revenue loss statistics (102382)
- MeCam $49 flying camera concept follows you around, streams video to your phone (100515)
- The PC inside your phone: A guide to the system-on-a-chip (58690)
- Norton cyber crime study offers striking revenue loss statistics (58611)
Categories

Show tagged entries
Syndicate This Blog
Calendar
|
|
July '26 | |||||
| Mon | Tue | Wed | Thu | Fri | Sat | Sun |
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 | ||