Monday, February 26. 2018
WebAssembly
-----
![]()
WebAssembly (wasm, WA) is a web standard that defines a binary format and a corresponding assembly-like text format for executable code in Web pages. It is meant to enable executing code nearly as fast as running native machine code. It was envisioned to complement JavaScript to speed up performance-critical parts of web applications and later on to enable web development in other languages than JavaScript.[1][2][3] It is developed at the World Wide Web Consortium (W3C) with engineers from Mozilla, Microsoft, Google and Apple.[4]
It is executed in a sandbox in the web browser after a formal verification step. Programs can be compiled from high-level languages into wasm modules and loaded as libraries from within JavaScript applets.
Sunday, February 25. 2018
BeagleBoard
Wednesday, February 21. 2018
Inching closer to a DNA-based file system
Sunday, August 27. 2017
MIT - Moral Machine

Welcome to the Moral Machine! A platform for gathering a human perspective on moral decisions made by machine intelligence, such as self-driving cars.
We show you moral dilemmas, where a driverless car must choose the lesser of two evils, such as killing two passengers or five pedestrians. As an outside observer, you
judge
which outcome you think is more acceptable. You can then see how your responses compare with those of other people.
If you’re feeling creative, you can also
design
your own scenarios, for you and other users to
browse
, share, and discuss.
Wednesday, May 31. 2017
New Bioprinter Makes It Easier to Fabricate 3D Flesh and Bone
Via IEEE Spectrum
-----
The ideal 3D bioprinter, says tissue engineering expert Y. Shrike Zhang, would resemble a breadmaker: “You’d have a few buttons on top, and you’d press a button to choose heart tissue or liver tissue.” Then Zhang would walk away from the machine while it laid down complex layers of cells and other materials.
The technology isn’t quite there yet. But the new BioBot 2 printer seems a step in that direction. The tabletop device includes a suite of new features designed to give users easy control over a powerful device, including automated calibration; six print heads to extrude six different bioinks; placement of materials with 1-micrometer precision on the x, y, and z axes; and a user-friendly software interface that manages the printing process from beginning to end.
BioBots cofounder and CEO Danny Cabrera says the BioBot 2’s features are a result of collaboration with researchers who work in tissue engineering.
“We’ve been working closely with scientists over the past year and a half to understand what they need to push this work forward,” he says. “What we found is that they needed more than just a bioprinter—and we had to do more than just develop a new robot.”
The company’s cloud-based software makes it easy for users to upload their printing parameters, which the system translates into protocols for the machine. After the tissue is printed, the system can use embedded cameras and computer-vision software to run basic analyses. For example, it can count the number of living versus dead cells in a printed tissue, or measure the length of axons in printed neurons. “This platform lets them measure how different printing parameters, like pressure or cellular resolution, affect the biology of the tissue,” Cabrera says.
The BioBot 1 hit the market in 2015 and sells for US $10,000. The company is now taking orders for the $40,000 BioBot 2, and plans to ship later this year.
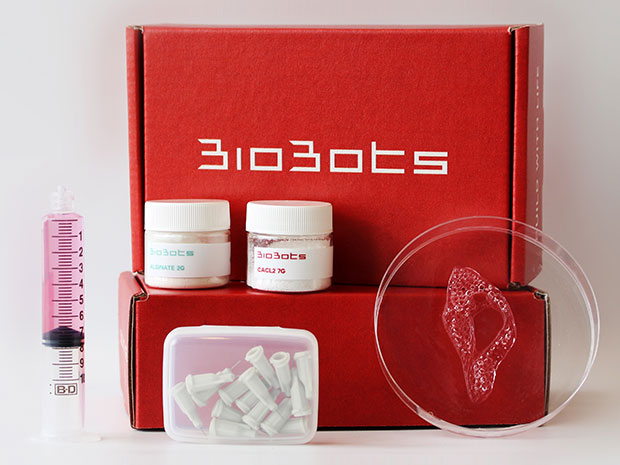
Each of the BioBot 2’s print heads can cool its bioink to 4 degrees Celsius or heat it to 200 degrees Celsius. The printbed is also temperature-controlled, and it’s equipped with visible and ultraviolet lights that trigger cross-linking in materials to give make printed forms more solid.
Cabrera says the temperature controls make it easier to print collagen, a principal component of connective tissue and bone, because it cross-links at colder temperatures. “A lot of people were hacking their bioprinters to get collagen to print,” Cabrera says. “Some were printing in the refrigerator.”
While some researchers won’t be interested in using the six print heads to make tissue composed of six different materials, Cabrera says the design also allows researchers to multiplex experiments. For example, if researchers are experimenting with the concentration of cells in a bioink, this setup allows them to simultaneously test six different versions. “That can save weeks if you have to wait for your cells to grow after each experiment,” Cabrera says.
And the machine can deposit materials not only on a petri dish, but also into a cell-culture plate with many small wells. With a 96-well plate, “you could have 96 lilttle experiments,” says Cabrera.
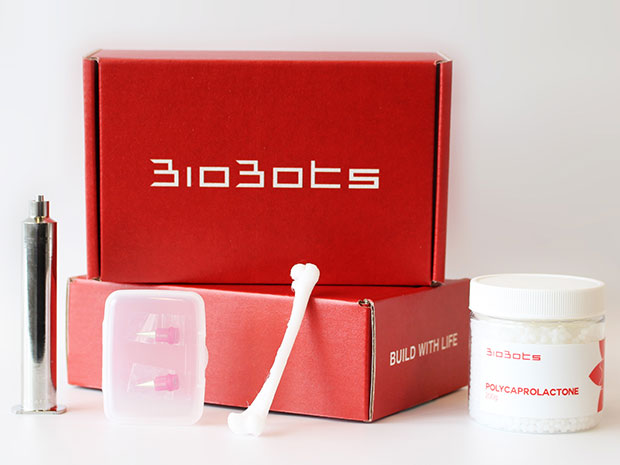
One long-term goal of bioprinting is to give doctors the ability to press a button and print out a sheet of skin for a burn patient, or a precisely shaped bone graft for someone who’s had a disfiguring accident. Such things have been achieved in the lab, but they’re far from gaining regulatory approval. An even longer-term goal is to give doctors the power to print out entire replacement organs, thus ending the shortage of organs available for transplant, but that’s still in the realm of sci-fi.
While we wait for those applications, however, 3D bioprinters are already finding plenty of uses in biomedical research.
Zhang experimented with an early beta version of the BioBot 1 while working in the Harvard Medical School lab of Ali Khademhosseini. He used bioprinters to create organ-on-a-chip structures, which mimic the essential nature of organs like hearts, livers, and blood vessels with layers of the appropriate cell types laid down in careful patterns. These small chips can be used for drug screening and basic medical research. With the BioBot beta, Zhang made a “thrombosis-on-a-chip” where blood clots formed inside miniature blood vessels.
Now an instructor of medicine and an associate bioengineer at Brigham and Women’s Hospital in Boston, Zhang says he’s intrigued by the BioBot 2. Its ability to print with multiple materials is enticing, he says, because he wants to reproduce complex tissues composed of different cell types. But he hasn’t decided yet whether he’ll order one. Like so much in science, “it depends on funding,” he says.
The BioBot 2 is on the cheaper end of the bioprinter market.
The top-notch machines used by researchers who want nanometer-scale precision typically cost around $200,000—like the large 3D-Bioplotter from EnvisionTec. This machine was used in research announced just today, in which Northwestern University scientists 3D-printed a structure that resembled a mouse ovary. When they seeded it with immature egg cells and implanted it into a mouse, the animal gave birth to live pups.
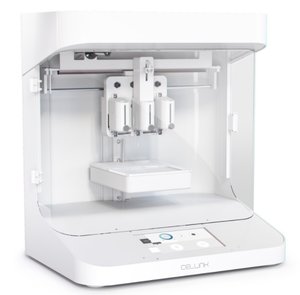
But there are a few other bioprinters that compete with the BioBot machines on price. Most notably, a Swedish company called Cellink sells three desktop-sized bioprinters that range in price from $10,000 to $40,000.
And a San Francisco startup called Aether just recently began sending beta units to researchers for testing and feedback; the company has promised to begin selling its Aether 1 this year for only $9000.

The biggest source of competition may not be other companies, but bioengineers’ innate propensity for tinkering. “We’ll often get some basic sort of printer and make our own print heads and bioinks,” Zhang says.
But for biology researchers who don’t have an engineering background,
Zhang says, the BioBot 2 would provide a powerful boost in abilities.
It would be almost like giving a kitchen-phobic individual the sudden
capacity to bake a perfect loaf of whole wheat bread.
Monday, April 24. 2017
Replika is a personal device that learns your personality, talks to people FOR you
Via The Real Daily (C.L. Brenton)
-----

We’ve been warned…
Remember the movie Surrogates, where everyone lives in at home plugged in to virtual reality screens and robot versions of them run around and do their bidding? Or Her, where Siri’s personality is so attractive and real, that it’s possible to fall in love with an AI?
Replika may be the seedling of such a world, and there’s no denying the future implications of that kind of technology.
Replika is a personal chatbot that you can raise through SMS. By chatting with it, you teach it your personality and gain in-app points. Through the app it can chat with your friends and learn enough about you so that maybe one day it will take over some of your responsibilities like social media, or checking in with your mom. It’s in beta right now, so we haven’t gotten our hands on one, and there is little information available about it, but color me fascinated and freaked out based on what we already know.
AI is just that – artificial
I have never been a fan of technological advances that replace human interaction. Social media, in general, seems to replace and enhance traditional communication, which is fine. But robots that hug you when you’re grieving a lost child, or AI personalities that text your girlfriend sweet nothings for you don’t seem like human enhancement, they feel like human loss.
You know that feeling when you get a text message from someone you care about, who cares about you? It’s that little dopamine rush, that little charge that gets your blood pumping, your heart racing. Just one ding, and your day could change. What if a robot’s text could make you feel that way?
It’s a real boy?
Replika began when one of its founders lost her roommate, Roman, to a car accident. Eugenia Kyuda created Luka, a restaurant recommending chatbot, and she realized that with all of her old text messages from Roman, she could create an AI that texts and chats just like him. When she offered the use of his chatbot to his friends and family, she found a new business.
People were communicating with their deceased friend, sibling, and child, like he was still there. They wanted to tell him things, to talk about changes in their lives, to tell him they missed him, to hear what he had to say back.
This is human loss and grieving tempered by an AI version of the dead, and the implications are severe. Your personality could be preserved in servers after you die. Your loved ones could feel like they’re talking to you when you’re six feet under. Doesn’t that make anyone else feel uncomfortable?
Bringing an X-file to life
If you think about your closest loved one dying, talking to them via chatbot may seem like a dream come true. But in the long run, continuing a relationship with a dead person via their AI avatar is dangerous. Maybe it will help you grieve in the short term, but what are we replacing? And is it worth it?
Imagine texting a friend, a parent, a sibling, a spouse instead of Replika. Wouldn’t your interaction with them be more valuable than your conversation with this personality? Because you’re building on a lifetime of friendship, one that has value after the conversation is over. One that can exist in real tangible life. One that can actually help you grieve when the AI replacement just isn’t enough. One that can give you a hug.
“One day it will do things for you,” Kyuda said in an interview with Bloomberg, “including keeping you alive. You talk to it, and it becomes you.”
Replacing you is so easy
This kind of rhetoric from Replika’s founder has to make you wonder if this app was intended as a sort of technological fountain of youth. You never have to “die” as long as your personality sticks around to comfort your loved ones after you pass. I could even see myself trying to cope with a terminal diagnosis by creating my own Replika to assist family members after I’m gone.
But it’s wrong isn’t it? Isn’t it? Psychologically and socially wrong?
It all starts with a chatbot. That replicates your personality. It begins with a woman who was just trying to grieve. This is a taste of the future, and a scary one too. One of clones, downloaded personalities, and creating a life that sticks around after you’re gone.
Monday, April 17. 2017
Google says its custom machine learning chips are often 15-30x faster than GPUs and CPUs
Via Tech Crunch
-----

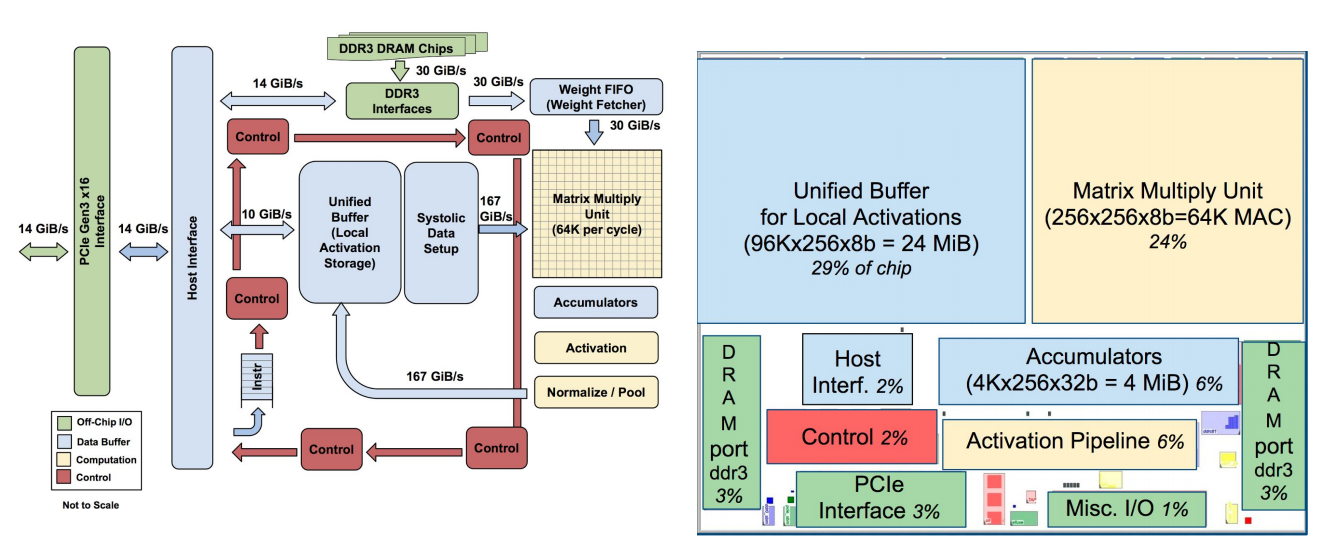
It’s no secret that Google has developed its own custom chips to accelerate its machine learning algorithms. The company first revealed those chips, called Tensor Processing Units (TPUs), at its I/O developer conference back in May 2016, but it never went into all that many details about them, except for saying that they were optimized around the company’s own TensorFlow machine-learning framework. Today, for the first time, it’s sharing more details and benchmarks about the project.
If you’re a chip designer, you can find all the gory glorious details of how the TPU works in Google’s paper.
The numbers that matter most here, though, are that based on Google’s
own benchmarks (and it’s worth keeping in mind that this is Google
evaluating its own chip), the TPUs are on average 15x to 30x faster in
executing Google’s regular machine learning workloads than a standard
GPU/CPU combination (in this case, Intel Haswell processors and Nvidia
K80 GPUs). And because power consumption counts in a data center, the
TPUs also offer 30x to 80x higher TeraOps/Watt (and with using faster
memory in the future, those numbers will probably increase).
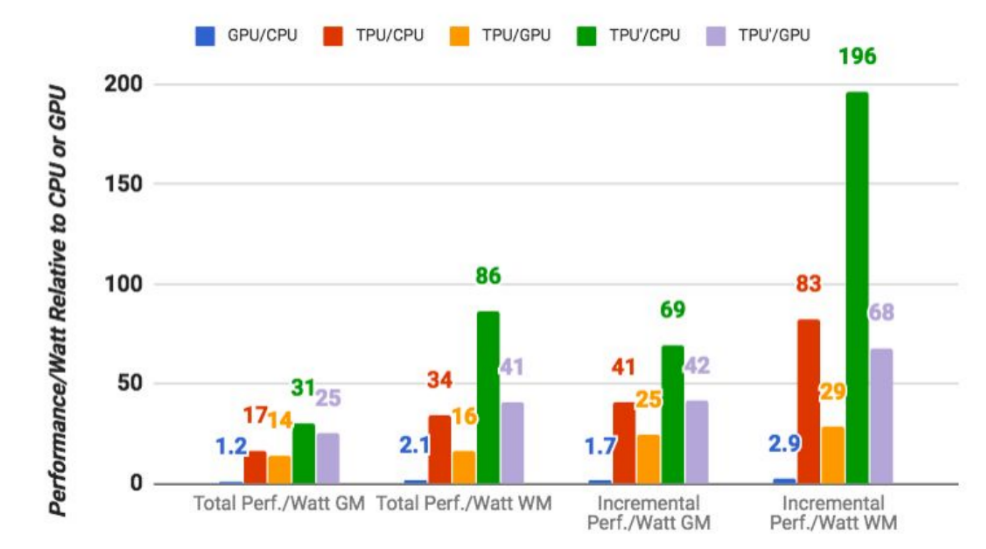
It’s worth noting that these numbers are about using machine learning models in production, by the way — not about creating the model in the first place.
Google also notes that while most architects optimize their chips for convolutional neural networks (a specific type of neural network that works well for image recognition, for example). Google, however, says, those networks only account for about 5 percent of its own data center workload while the majority of its applications use multi-layer perceptrons.
Google says it started looking into how it could use GPUs, FPGAs and custom ASICS (which is essentially what the TPUs are) in its data centers back in 2006. At the time, though, there weren’t all that many applications that could really benefit from this special hardware because most of the heavy workloads they required could just make use of the excess hardware that was already available in the data center anyway. “The conversation changed in 2013 when we projected that DNNs could become so popular that they might double computation demands on our data centers, which would be very expensive to satisfy with conventional CPUs,” the authors of Google’s paper write. “Thus, we started a high-priority project to quickly produce a custom ASIC for inference (and bought off-the-shelf GPUs for training).” The goal here, Google’s researchers say, “was to improve cost-performance by 10x over GPUs.”
Google isn’t likely to make the TPUs available outside of its own cloud, but the company notes that it expects that others will take what it has learned and “build successors that will raise the bar even higher.”
Monday, April 10. 2017
A second life for open-world games as self-driving car training software
Via Tech Crunch
-----

A lot of top-tier video games enjoy lengthy long-tail lives with remasters and re-releases on different platforms, but the effort put into some games could pay dividends in a whole new way, as companies training things like autonomous cars, delivery drones and other robots are looking to rich, detailed virtual worlds to provided simulated training environments that mimic the real world.
Just as companies including Boom can now build supersonic jets with a small team and limited funds, thanks to advances made possible in simulation, startups like NIO (formerly NextEV) can now keep pace with larger tech concerns with ample funding in developing self-driving software, using simulations of real-world environments including those derived from games like Grand Theft Auto V. Bloomberg reports that the approach is increasingly popular among companies that are looking to supplement real-world driving experience, including Waymo and Toyota’s Research Institute.
There are some drawbacks, of course: Anyone will tell you that regardless of the industry, simulation can do a lot, but it can’t yet fully replace real-world testing, which always diverges in some ways from what you’d find in even the most advanced simulations. Also, miles driven in simulation don’t count towards the total miles driven by autonomous software figures most regulatory bodies will actually care about in determining the road worthiness of self-driving systems.
The more surprising takeaway here is that GTA V in this instance isn’t a second-rate alternative to simulation software created for the purpose of testing autonomous driving software – it proves an incredibly advanced testing platform, because of the care taken in its open-world game design. That means there’s no reason these two market uses can’t be more aligned in future: Better, more comprehensive open-world game design means better play experiences for users looking for that truly immersive quality, and better simulation results for researchers who then leverage the same platforms as a supplement to real-world testing.
Monday, March 20. 2017
How Uber Deceives the Authorities Worldwide
Via New York Times (Mike Isaac)
-----

SAN FRANCISCO — Uber has for years engaged in a worldwide program to deceive the authorities in markets where its low-cost ride-hailing service was resisted by law enforcement or, in some instances, had been banned.
The program, involving a tool called Greyball, uses data collected from the Uber app and other techniques to identify and circumvent officials who were trying to clamp down on the ride-hailing service. Uber used these methods to evade the authorities in cities like Boston, Paris and Las Vegas, and in countries like Australia, China and South Korea.
Greyball was part of a program called VTOS, short for “violation of terms of service,” which Uber created to root out people it thought were using or targeting its service improperly. The program, including Greyball, began as early as 2014 and remains in use, predominantly outside the United States. Greyball was approved by Uber’s legal team.
Greyball and the VTOS program were described to The New York Times by four current and former Uber employees, who also provided documents. The four spoke on the condition of anonymity because the tools and their use are confidential and because of fear of retaliation by Uber.
Uber’s use of Greyball was recorded on video in late 2014, when Erich England, a code enforcement inspector in Portland, Ore., tried to hail an Uber car downtown in a sting operation against the company.
At the time, Uber had just started its ride-hailing service in Portland without seeking permission from the city, which later declared the service illegal. To build a case against the company, officers like Mr. England posed as riders, opening the Uber app to hail a car and watching as miniature vehicles on the screen made their way toward the potential fares.
But unknown to Mr. England and other authorities, some of the digital cars they saw in the app did not represent actual vehicles. And the Uber drivers they were able to hail also quickly canceled. That was because Uber had tagged Mr. England and his colleagues — essentially Greyballing them as city officials — based on data collected from the app and in other ways. The company then served up a fake version of the app, populated with ghost cars, to evade capture.
At a time when Uber is already under scrutiny for its boundary-pushing workplace culture, its use of the Greyball tool underscores the lengths to which the company will go to dominate its market. Uber has long flouted laws and regulations to gain an edge against entrenched transportation providers, a modus operandi that has helped propel it into more than 70 countries and to a valuation close to $70 billion.
Yet using its app to identify and sidestep the authorities where regulators said Uber was breaking the law goes further toward skirting ethical lines — and, potentially, legal ones. Some at Uber who knew of the VTOS program and how the Greyball tool was being used were troubled by it.
In a statement, Uber said, “This program denies ride requests to users who are violating our terms of service — whether that’s people aiming to physically harm drivers, competitors looking to disrupt our operations, or opponents who collude with officials on secret ‘stings’ meant to entrap drivers.”
The mayor of Portland, Ted Wheeler, said in a statement, “I am very concerned that Uber may have purposefully worked to thwart the city’s job to protect the public.”
Uber, which lets people hail rides using a smartphone app, operates multiple types of services, including a luxury Black Car offering in which drivers are commercially licensed. But an Uber service that many regulators have had problems with is the lower-cost version, known in the United States as UberX.
UberX essentially lets people who have passed a background check and vehicle inspection become Uber drivers quickly. In the past, many cities have banned the service and declared it illegal.
That is because the ability to summon a noncommercial driver — which is how UberX drivers using private vehicles are typically categorized — was often unregulated. In barreling into new markets, Uber capitalized on this lack of regulation to quickly enlist UberX drivers and put them to work before local regulators could stop them.
After the authorities caught on to what was happening, Uber and local officials often clashed. Uber has encountered legal problems over UberX in cities including Austin, Tex., Philadelphia and Tampa, Fla., as well as internationally. Eventually, agreements were reached under which regulators developed a legal framework for the low-cost service.
That approach has been costly. Law enforcement officials in some cities have impounded vehicles or issued tickets to UberX drivers, with Uber generally picking up those costs on the drivers’ behalf. The company has estimated thousands of dollars in lost revenue for every vehicle impounded and ticket received.
This is where the VTOS program and the use of the Greyball tool came in. When Uber moved into a new city, it appointed a general manager to lead the charge. This person, using various technologies and techniques, would try to spot enforcement officers.
One technique involved drawing a digital perimeter, or “geofence,” around the government offices on a digital map of a city that Uber was monitoring. The company watched which people were frequently opening and closing the app — a process known internally as eyeballing — near such locations as evidence that the users might be associated with city agencies.
Other techniques included looking at a user’s credit card information and determining whether the card was tied directly to an institution like a police credit union.
Enforcement officials involved in large-scale sting operations meant to catch Uber drivers would sometimes buy dozens of cellphones to create different accounts. To circumvent that tactic, Uber employees would go to local electronics stores to look up device numbers of the cheapest mobile phones for sale, which were often the ones bought by city officials working with budgets that were not large.
In all, there were at least a dozen or so signifiers in the VTOS program that Uber employees could use to assess whether users were regular new riders or probably city officials.
If such clues did not confirm a user’s identity, Uber employees would search social media profiles and other information available online. If users were identified as being linked to law enforcement, Uber Greyballed them by tagging them with a small piece of code that read “Greyball” followed by a string of numbers.
When someone tagged this way called a car, Uber could scramble a set of ghost cars in a fake version of the app for that person to see, or show that no cars were available. Occasionally, if a driver accidentally picked up someone tagged as an officer, Uber called the driver with instructions to end the ride.
Uber employees said the practices and tools were born in part out of safety measures meant to protect drivers in some countries. In France, India and Kenya, for instance, taxi companies and workers targeted and attacked new Uber drivers.
“They’re beating the cars with metal bats,” the singer Courtney Love posted on Twitter from an Uber car in Paris at a time of clashes between the company and taxi drivers in 2015. Ms. Love said that protesters had ambushed her Uber ride and had held her driver hostage. “This is France? I’m safer in Baghdad.”
Uber has said it was also at risk from tactics used by taxi and limousine companies in some markets. In Tampa, for instance, Uber cited collusion between the local transportation authority and taxi companies in fighting ride-hailing services.
In those areas, Greyballing started as a way to scramble the locations of UberX drivers to prevent competitors from finding them. Uber said that was still the tool’s primary use.
But as Uber moved into new markets, its engineers saw that the same methods could be used to evade law enforcement. Once the Greyball tool was put in place and tested, Uber engineers created a playbook with a list of tactics and distributed it to general managers in more than a dozen countries on five continents.
At least 50 people inside Uber knew about Greyball, and some had qualms about whether it was ethical or legal. Greyball was approved by Uber’s legal team, led by Salle Yoo, the company’s general counsel. Ryan Graves, an early hire who became senior vice president of global operations and a board member, was also aware of the program.
Ms. Yoo and Mr. Graves did not respond to requests for comment.
Outside legal specialists said they were uncertain about the legality of the program. Greyball could be considered a violation of the federal Computer Fraud and Abuse Act, or possibly intentional obstruction of justice, depending on local laws and jurisdictions, said Peter Henning, a law professor at Wayne State University who also writes for The New York Times.
“With any type of systematic thwarting of the law, you’re flirting with disaster,” Professor Henning said. “We all take our foot off the gas when we see the police car at the intersection up ahead, and there’s nothing wrong with that. But this goes far beyond avoiding a speed trap.”
On Friday, Marietje Schaake, a member of the European Parliament for the Dutch Democratic Party in the Netherlands, wrote that she had written to the European Commission asking, among other things, if it planned to investigate the legality of Greyball.
To date, Greyballing has been effective. In Portland on that day in late 2014, Mr. England, the enforcement officer, did not catch an Uber, according to local reports.
And two weeks after Uber began dispatching drivers in Portland, the company reached an agreement with local officials that said that after a three-month suspension, UberX would eventually be legally available in the city.
Monday, February 27. 2017
Samsung scraps a Raspberry Pi 3 competitor, shrinks Artik line
Via PCWorld
-----

Samsung has scrapped its Raspberry Pi 3 competitor called Artik 10 as it moves to smaller and more powerful boards to create gadgets, robots, drones, and IoT devices.
A last remaining stock of the US$149 boards is still available through online retailers Digi-Key and Arrow.
Samsung has stopped making Artik 10 and is asking users to buy its Artik 7 boards instead.
"New development for high-performance IoT products should be based on the Samsung Artik 710, as the Artik 1020 is no longer in production. Limited stocks of Artik 1020 modules and developer kits are still available for experimentation and small-scale projects," the company said on its Artik website.
The Artik boards have been used to develop robots, drone, smart lighting systems, and other smart home products. Samsung has a grand plan to make all its appliances, including refrigerators and washing machines, smart in the coming years, and Artik is a big part of that strategy.
Samsung hopes that tinkerers will make devices that work with its smart appliances. Artik can also be programmed to work with Amazon Echo.
Artik 10 started shipping in May last year, and out-performed Raspberry Pi 3 in many ways, but also lagged on some features.
The board had a plethora of wireless connectivity features including 802.11b/g/n Wi-Fi, Zigbee, and Bluetooth, and it had a better graphics processor than Raspberry Pi. The Artik 10 had 16GB flash storage and 2GB of RAM, both more than Raspberry Pi 3.
The board's biggest flaw was a 32-bit eight-core ARM processor; Raspberry Pi had a 64-bit ARM processor.
The Artik 7 is smaller and a worthy replacement. It has an eight-core 64-bit ARM processor, and it also has Wi-Fi, Bluetooth, and ZigBee. It supports 1080p graphics, and it has 1GB of RAM and 4GB of flash storage, less than in Artik 10. Cameras and sensors can be easily attached to the board.
The Artik boards work on Linux and Tizen. The company also sells Artik 5 and Artik 0, which are smaller boards with lower power processors.
Quicksearch
Popular Entries
- The great Ars Android interface shootout (129010)
- MeCam $49 flying camera concept follows you around, streams video to your phone (97608)
- Norton cyber crime study offers striking revenue loss statistics (93573)
- The PC inside your phone: A guide to the system-on-a-chip (55391)
- Norton cyber crime study offers striking revenue loss statistics (49802)
Categories

Show tagged entries
Syndicate This Blog
Calendar
|
|
April '24 | |||||
| Mon | Tue | Wed | Thu | Fri | Sat | Sun |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | |||||