It turns out that a vital missing ingredient in the long-sought after
goal of getting machines to think like humans—artificial
intelligence—has been lots and lots of data.
Last week, at the O’Reilly Strata + Hadoop World Conference in New York, Salesforce.com’s head of artificial intelligence, Beau Cronin, asserted that AI has gotten a shot in the arm from the big data movement.
“Deep learning on its own, done in academia, doesn’t have the [same]
impact as when it is brought into Google, scaled and built into a new
product,” Cronin said.
In the week since Cronin’s talk, we saw a
whole slew of companies—startups mostly—come out of stealth mode to
offer new ways of analyzing big data, using machine learning, natural
language recognition and other AI techniques that those researchers have
been developing for decades.
One such startup, Cognitive Scale,
applies IBM Watson-like learning capabilities to draw insights from
vast amount of what it calls “dark data,” buried either in the Web—Yelp
reviews, online photos, discussion forums—or on the company network,
such as employee and payroll files, noted KM World.
Cognitive
Scale offers a set of APIs (application programming interfaces) that
businesses can use to tap into cognitive-based capabilities designed to
improve search and analysis jobs running on cloud services such as IBM’s Bluemix, detailed the Programmable Web.
Cognitive Scale was founded by Matt Sanchez, who headed up IBM’s Watson Labs,
helping bring to market some of the first e-commerce applications based
on the Jeopardy-winning Watson technology, pointed out CRN.
Sanchez,
now chief technology officer for Cognitive Scale, is not the only
Watson alumnus who has gone on to commercialize cognitive technologies.
Alert reader Gabrielle Sanchez pointed out that another Watson ex-alum, engineer Pete Bouchard, recently joined the team of another cognitive computing startup Zintera
as the chief innovation office. Sanchez, who studied cognitive
computing in college, found a demonstration of the company’s “deep
learning” cognitive computing platform to be “pretty impressive.”
AI-based deep learning with big data was certainly on the mind of senior Google executives. This week the company snapped up two Oxford University technology spin-off companies that focus on deep learning, Dark Blue Labs and Vision Factory.
The teams will work on image recognition and natural language understanding, Sharon Gaudin reported in Computerworld.
Sumo Logic
has found a way to apply machine learning to large amounts machine
data. An update to its analysis platform now allows the software to
pinpoint casual relationships within sets of data, Inside Big Data concluded.
A company could, for instance, use the Sumo Logic cloud service to analyze log data to troubleshoot a faulty application, for instance.
While companies such as Splunk have long offered search engines for machine data, Sumo Logic moves that technology a step forward, the company claimed.
“The
trouble with search is that you need to know what you are searching
for. If you don’t know everything about your data, you can’t by
definition, search for it. Machine learning became a fundamental part of
how we uncover interesting patterns and anomalies in data,” explained
Sumo Logic chief marketing officer Sanjay Sarathy, in an interview.
For
instance, the company, which processes about 5 petabytes of customer
data each day, can recognize similar queries across different users, and
suggest possible queries and dashboards that others with similar setups
have found useful.
“Crowd-sourcing intelligence around different
infrastructure items is something you can only do as a native cloud
service,” Sarathy said.
With Sumo Logic, an e-commerce company
could ensure that each transaction conducted on its site takes no longer
than three seconds to occur. If the response time is lengthier, then an
administrator can pinpoint where the holdup is occurring in the transactional flow.
One existing Sumo Logic customer, fashion retailer Tobi, plans to use the new capabilities to better understand how its customers interact with its website.
One-upping IBM on the name game is DataRPM, which crowned its own big data-crunching natural language query engine Sherlock (named after Sherlock Holmes who, after all, employed Watson to execute his menial tasks).
Sherlock
is unique in that it can automatically create models of large data
sets. Having a model of a data set can help users pull together
information more quickly, because the model describes what the data is
about, explained DataRPM CEO Sundeep Sanghavi.
DataRPM can analyze
a staggeringly wide array of structured, semi-structured and
unstructured data sources. “We’ll connect to anything and everything,”
Sanghavi said.
The service company can then look for ways that different data sets could be combined to provide more insight.
“We
believe that data warehousing is where data goes to die. Big data is
not just about size, but also about how many different sources of data
you are processing, and how fast you can process that data,” Sanghavi
said, in an interview.
For instance, Sherlock can pull together
different sources of data and respond with a visualization to a query
such as “What was our revenue for last year, based on geography?” The
system can even suggest other possible queries as well.
Sherlock
has a few advantages over Watson, Sanghavi claimed. The training period
is not as long, and the software can be run on-premise, rather than as a
cloud service from IBM, for those shops that want to keep their
computations in-house. “We’re far more affordable than Watson,” Sanghavi
said.
Initially, DataRPM is marketing to the finance, telecommunications, manufacturing, transportation and retail sectors.
One company that certainly does not think data warehousing is going to die is a recently unstealth’ed startup run by Bob Muglia, called Snowflake Computing.
Publicly
launched this week, Snowflake aims “to do for the data warehouse what
Salesforce did for CRM—transforming the product from a piece of
infrastructure that has to be maintained by IT into a service operated
entirely by the provider,” wrote Jon Gold at Network World.
Founded
in 2012, the company brought in Muglia earlier this year to run the
business. Muglia was the head of Microsoft’s server and tools division,
and later, head of the software unit at Juniper Networks.
While Snowflake could offer its software as a product, it chooses to do so as a service, noted Timothy Prickett Morgan at Enterprise Tech.
“Sometime
either this year or next year, we will see more data being created in
the cloud than in an on-premises environment,” Muglia told Morgan.
“Because the data is being created in the cloud, analysis of that data
in the cloud is very appropriate.”
Robert Alexander spends parts of his day listening to a soft white
noise, similar to water falling on the outside of a house during a
rainstorm. Every once in a while, he hears an anomalous sound and marks
the corresponding time in the audio file. Alexander is listening to the
sun’s magnetic field and marking potential areas of interest. After only
ten minutes, he has listened to one month’s worth of data.
Alexander is a PhD candidate in design science at the University of
Michigan. He is a sonification specialist who trains heliophysicists at
NASA’s Goddard Space Flight Center in Greenbelt, Maryland, to pick out
subtle differences by listening to satellite data instead of looking at
it.
Sonification is the process of displaying any type of data or
measurement as sound, such as the beep from a heart rate monitor
measuring a person’s pulse, a door bell ringing every time a person
enters a room, or, in this case, explosions indicating large events
occurring on the sun. In certain cases, scientists can use their ears
instead of their eyes to process data more rapidly -- and to detect more
details – than through visual analysis. A paper on the effectiveness of
sonification in analyzing data from NASA satellites was published in
the July issue of Journal of Geophysical Research: Space Physics.
“NASA produces a vast amount of data from its satellites. Exploring
such large quantities of data can be difficult,” said Alexander.
"Sonification offers a promising supplement to standard visual analysis
techniques.”
LISTENING TO SPACE
Alexander's focus is on improving and quantifying the success of
these techniques. The team created audio clips from the data and shared
them with researchers. While the original data from the Wind satellite
was not in audio file format, the satellite records electromagnetic
fluctuations that can be converted directly to audio samples. Alexander
and his team used custom written computer algorithms to convert those
electromagnetic frequencies into sound. Listen to the following
multimedia clips to hear the sounds of space.
This clip has three distinct sections: a warble noise leading up to a
short knock at slightly higher frequency followed by a quieter segment
containing broadband noise that is both rising and hissing. This clip
gathered from NASA's Wind satellite on Nov. 20, 2007, contains a reverse
shock. This type of event occurs when a fast stream of plasma – that
is, the super hot, charged gas that fills space— is followed by a slower
one, resulting in a shock wave that travels towards the sun.
This audio clip is the previous clip played backwards. Here, trained
listeners will notice the reverse shock event played backwards sounds
similar to forward shock event.
This clip contains audified data from the joint European Space
Agency (ESA) and NASA Ulysses satellite gathered on October 26, 1995.
The participant in Alexander's study was able to detect artificial noise
produced from the instrument, which he did not notice in previous
visual analysis. Here, the artificial noise can be heard as a drifting
tone.
PROCESSING AN OVERWHELMING AMOUNT OF DATA
Alexander's focus is on using clips like these to quantify and
improve sonification techniques in order to speed up access to the
incredible amounts of data provided by space satellites. For example, he
works with space scientist Robert Wicks at NASA Goddard to analyze the
high-resolution observations of the sun. Wicks studies the constant
stream of particles from our closest star, known as the solar wind – a
wind that can cause space weather effects that interfere with human
technology near Earth. The team uses data from NASA's Wind satellite.
Launched in 1994, Wind orbits a point in between Earth and the sun,
constantly observing the temperature, density, speed and the magnetic
field of the solar wind as it rushes past.
Wicks analyzes changes in Wind's magnetic field data. Such data not
only carries information about the solar wind, but understanding such
changes better might help give a forewarning of problematic space
weather that can affect satellites near Earth. The Wind satellite also
provides an abundance of magnetometer data points, as the satellite
measures the magnetic field 11 times per second. Such incredible amounts
of information are beneficial -- but only if all the data can be
analyzed.
“There is a very long, accurate time series of data, which gives a
fantastic view of solar wind changes and what’s going on at small
scales,” said Wicks. “There's a rich diversity of physical processes
going on, but it is more data than I can easily look through.”
The traditional method of processing the data involves making an
educated assertion about where a certain event in the solar wind -- such
as subtle wave movements made by hot plasma -- might show up and then
visually searching, which can be very time consuming. Instead, Alexander
listens to sped up versions of the Wind data and compiles a list of
noteworthy regions that scientists like Wicks can return to and further
analyze, expediting the process.
In one example, Alexander’s team analyzed data points from the Wind
satellite from November 2007, condensing three hours of real-time
recording to a three second audio clip. To an untrained ear, the data
sounds like a microphone recording on a windy day. When Alexander
presented these sounds to a researcher, however, the researcher could
identify a distinct chirping at the beginning of the audio clip followed
by a percussive event, culminating in a loud boom.
By listening only to the auditory representation of the data, the
study’s participant was able to correctly predict what this would look
like on a more traditional graph. He correctly deduced that that the
chirp would show up as a particular kind of peak on a kind of graph
called a spectrogram, a graph that shows different levels of frequencies
present in the waves that Wind recorded. The researcher also correctly
predicted that the corresponding spectrogram representation of the
percussive event would display a steep slope.
CONVERTING DATA INTO SOUND
Alexander translates the data into audio files through a process
known as audification, a specific type of sonification that involves
directly listening to raw, unedited satellite data. Translating this
data into audio can be likened to part of the process of collecting
sound from a person singing into a microphone at a recording studio with
reel-to-reel tape. When a person sings into a microphone, it detects
changes in pressure and converts the pressure signals to changes in
magnetic intensity in the form of an electrical signal. The electrical
signals are stored on the reel tape. Magnetometers on the Wind satellite
measure changes in magnetic field directly creating a similar kind of
electrical signal. Alexander writes a computer program to translate this
data to an audio file.
“The tones come out of the data naturally. If there is a frequency
embedded in the data, then that frequency becomes audible as a sound,”
said Alexander.
Listening to data is not new. In a study in 1982, researchers
used audification to identify micrometeroids, or small ring particles,
hitting the Voyager 2 spacecraft as it traversed Saturn's rings. The
impacts were visually obscured in the data but could be easily heard –
sounding like intense impulses, almost like a hailstorm.
However, the method is not often used in the science community
because it requires a certain level of familiarity with the sounds. For
instance, the listener needs to have an understanding of what typical
solar wind turbulence sounds like in order to identify atypical events.
“It’s about using your ear to pick out subtle differences,” Alexander
said.
Alexander initially spent several months with Wicks teaching him how
to listen to magnetometer data and highlighting certain elements. But
the hard work is paying off as analysis gets faster and easier, leading
to new assessments of the data.
“I’ve never listened to the data before,” said Wicks. “It has definitely opened up a different perspective.”
Ever since covering Fliike,
a beautifully-designed physical ‘Like’ counter for local businesses,
I’ve been thinking about how the idea could be extended, with a
fully-programmable, but simple, ticker-style Internet-connected display.
A few products along those lines do already exist, but I’ve yet to
find anything that quite matches what I had in mind. That is, until
recently, when I was introduced to LaMetric, a smart ticker being
developed by UK/Ukraine Internet of Things (IoT) startup Smart Atoms.
Launching
its Kickstarter crowdfunding campaign today, the LaMetric is aimed at
both consumers and businesses. The idea is you may want to display
alerts, notifications and other information from your online “life” via
an elegant desktop or wall-mountable and glance-able display. Likewise,
businesses that want an Internet-connected ticker, displaying various
business information, either publicly for customers or in an office, are
also a target market.
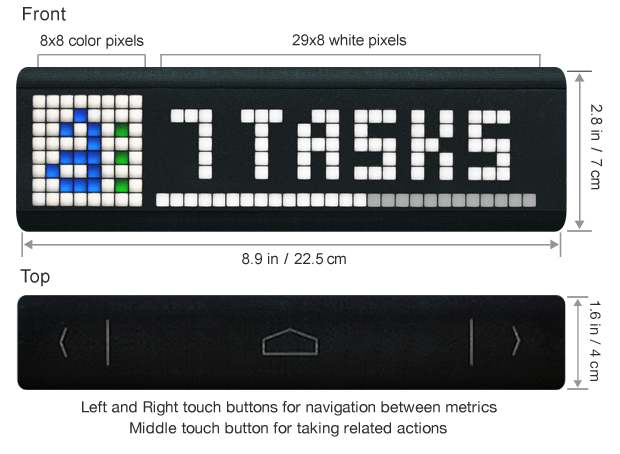
The
device itself has a retro, 8-bit style desktop clock feel to it, thanks
to its ‘blocky’ LED light powered display, which is part of its charm.
The display can output one icon and seven numbers, and is scrollable.
But, best of all, the LaMetric is fully programmable via the
accompanying app (or “hackable”) and comes with a bunch of off-the-shelf
widgets, along with support for RSS and services like IFTTT, Smart
Things, Wig Wag, Ninja Blocks, so you can get it talking to other smart
devices or web services. Seriously, this thing goes way beyond what I
had in mind — try the simulator for yourself — and, for an IoT junkie like me, is just damn cool.
Examples of the kind of things you can track with the device include
time, weather, subject and time left till your next meeting, number of
new emails and their subject lines, CrossFit timings and fitness goals,
number of to-dos for today, stock quotes, and social network
notifications.
Or for businesses, this might include Facebook Likes, website
visitors, conversions and other metrics, app store rankings, downloads,
and revenue.
In addition to the display, the device has back and forward buttons
so you can rotate widgets (though these can be set to automatically
rotate), as well as an enter key for programmed responses, such as
accepting a calendar invitation.
There’s also a loudspeaker for audio alerts. The LaMetric is powered
by micro-USB and also comes as an optional and more expensive
battery-powered version.
Early-bird backers on Kickstarter can pick up the LaMetric for as
little as $89 (plus shipping) for the battery-less version, with
countless other options and perks, increasing in price.
Want to know exactly how much of your Internet time is spent fiddling
around on Facebook versus doing all-important Googling, online shopping
or watching videos? Try Iconic History,
a plugin that puts your whole browser history into an exhaustive stream
of favicons, the icons that appear next to a website's name on a
browser tab.
Created by Carnegie Mellon University computer science student Shan Huang
for a class on interactive art and computational design, the plugin
pulls your browser history from Google Chrome (which keeps up to four
months of data) and visualizes every site you've visited by sorting each
individual URL's associated icon chronologically. So it'll show if
you've spent an entire day surfing Facebook, or if you've stayed up late
into the night visiting Wikipedia.
"Because I spend so much time online every day, doing all sorts of
things from working to socializing to just aimless wandering, I thought
browser history alone could narrate a significant portion of my life and
what was on my mind," Huang writes in her summary of the project. For example, she found she frequently stayed up late online shopping at sites like Urban Outfitters and Macy's.
Each icon is linked to the original URL, so it's easy to go back and
see exactly which Urban Outfitters sweater you were coveting or which
seven YouTube videos you watched in a row, though these are visualized
just as a long list of identical pictures. You can filter the list to
show a specific site or time window during the day, in case you really
need to know what you've been searching between midnight and 6 a.m.
Hopefully you haven't been clearing your most interesting data!
This week the experimental developer-aimed group known as Google ATAP
- aka Advanced Technology and Projects (skunkworks) have announced
Project Tango. They’ve suggested Project Tango will appear first as a
phone with 3D sensors. These 3D sensors will be able to scan and build a
map of the room they’re in, opening up a whole world of possibilities.
The device that Project Tango will release first will be just about
as limited-edition as they come. Issued in an edition of 200, this
device will be sent to developers only. This developer group will be
hand-picked by Google’s ATAP - and sign-ups start today. (We’ll be
publishing the sign-up link once active.)
Speaking on this skunkworks project this morning was Google
user Johnny Lee. Mister Johnny Lee is ATAP’s technical program lead,
and he’ll be heading this project for the public, as you’ll see it. This
is the same group that brought you Motorola’s digital tattoos, if you’ll remember.
Projection mapping, where ordinary objects become surfaces for moving images, is an increasingly common video technique in applications like music videos, phone commercials, and architectural light shows — and now a new film shows what can happen when you add robots to the mix. In Box, a performance artist works with transforming panels hoisted by industrial machineryin
a dazzling demonstration of projection mapping's mind-bending
possibilities. Every effect is captured in-camera, and each section
eventually reveals how the robot arms were used.
It's the work of San Francisco
studio Bot & Dolly, which believes its new technology can "tear down
the fourth wall" in the theater. "Through large-scale robotics,
projection mapping and software engineering, audiences will witness the
trompe l'oeil effect pushed to new boundaries," says creative director
Tarik Abdel-Gawad. "We believe this methodology has tremendous potential
to radically transform visual art forms and define new genres of
expression." Box is an effective demonstration of the studio's
projection mapping system, but it works in its own right as an
enthralling piece of art.
Fed up with the NSA’s infringement of privacy, an internet user by the name of Sang Mun has developed a font which cannot be read by computers.
Called ‘ZXX’, which is used by the Library of Congress to
state that a document has “no linguistic content”, the font is garbled
up in such a way that computers with Optical Character Recognition (OCR)
will not be able to recognize it.
Available in four “disguises”, this font uses camouflage
techniques to trick the computers of governments and corporations into
thinking that no useful information can be collated from people, while
remaining readable to the human eye.
The font developer urges users to fight against this infringement of privacy, and has made this font free for all users on his website.
Wikipedia is constantly growing, and it is written by people around the world. To illustrate this, we created a map of recent changes on Wikipedia, which displays the approximate location of unregistered users and the article that they edit.
Unregistered Wikipedia users
When an unregistered user makes a contribution to Wikipedia,
he or she is identified by his or her IP address. These IP addresses
are translated to the contributor’s approximate geographic location. A study by Fabian Kaelin in 2011 noted that unregistered users make approximately 20% of the edits on English Wikipedia [edit: likely closer to 15%, according to more recent statistics], so Wikipedia’s stream of recent changes includes many other edits that are not shown on this map.
You may see some users add non-productive or disruptive content to Wikipedia. A survey in 2007 indicated
that unregistered users are less likely to make productive edits to the
encyclopedia. Do not fear: improper edits can be removed or corrected by other users, including you!
How it works
This map listens to live feeds of Wikipedia revisions, broadcast using wikimon. We built the map using a few nice libraries and services, including d3, DataMaps, and freegeoip.net. This project was inspired by WikipediaVision’s (almost) real-time edit visualization.
We’ve been hearing a lot about Google‘s
self-driving car lately, and we’re all probably wanting to know how
exactly the search giant is able to construct such a thing and drive
itself without hitting anything or anyone. A new photo has surfaced that
demonstrates what Google’s self-driving vehicles see while they’re out
on the town, and it looks rather frightening.
The image was tweeted
by Idealab founder Bill Gross, along with a claim that the self-driving
car collects almost 1GB of data every second (yes, every second). This
data includes imagery of the cars surroundings in order to effectively
and safely navigate roads. The image shows that the car sees its
surroundings through an infrared-like camera sensor, and it even can
pick out people walking on the sidewalk.
Of course, 1GB of data every second isn’t too surprising when you
consider that the car has to get a 360-degree image of its surroundings
at all times. The image we see above even distinguishes different
objects by color and shape. For instance, pedestrians are in bright
green, cars are shaped like boxes, and the road is in dark blue.
However, we’re not sure where this photo came from, so it could
simply be a rendering of someone’s idea of what Google’s self-driving
car sees. Either way, Google says that we could see self-driving cars
make their way to public roads in the next five years or so, which actually isn’t that far off, and Tesla Motors CEO Elon Musk is even interested in developing self-driving cars as well. However, they certainly don’t come without their problems, and we’re guessing that the first batch of self-driving cars probably won’t be in 100% tip-top shape.
Abstract While playing around with the Nmap Scripting Engine
(NSE) we discovered an amazing number of open embedded devices on the
Internet. Many of them are based on Linux and allow login to standard
BusyBox with empty or default credentials. We used these devices to
build a distributed port scanner to scan all IPv4 addresses. These scans
include service probes for the most common ports, ICMP ping, reverse
DNS and SYN scans. We analyzed some of the data to get an estimation of
the IP address usage.
All data gathered during our research is released into the public domain for further study.