Monday, April 24. 2017
Replika is a personal device that learns your personality, talks to people FOR you
Via The Real Daily (C.L. Brenton)
-----

We’ve been warned…
Remember the movie Surrogates, where everyone lives in at home plugged in to virtual reality screens and robot versions of them run around and do their bidding? Or Her, where Siri’s personality is so attractive and real, that it’s possible to fall in love with an AI?
Replika may be the seedling of such a world, and there’s no denying the future implications of that kind of technology.
Replika is a personal chatbot that you can raise through SMS. By chatting with it, you teach it your personality and gain in-app points. Through the app it can chat with your friends and learn enough about you so that maybe one day it will take over some of your responsibilities like social media, or checking in with your mom. It’s in beta right now, so we haven’t gotten our hands on one, and there is little information available about it, but color me fascinated and freaked out based on what we already know.
AI is just that – artificial
I have never been a fan of technological advances that replace human interaction. Social media, in general, seems to replace and enhance traditional communication, which is fine. But robots that hug you when you’re grieving a lost child, or AI personalities that text your girlfriend sweet nothings for you don’t seem like human enhancement, they feel like human loss.
You know that feeling when you get a text message from someone you care about, who cares about you? It’s that little dopamine rush, that little charge that gets your blood pumping, your heart racing. Just one ding, and your day could change. What if a robot’s text could make you feel that way?
It’s a real boy?
Replika began when one of its founders lost her roommate, Roman, to a car accident. Eugenia Kyuda created Luka, a restaurant recommending chatbot, and she realized that with all of her old text messages from Roman, she could create an AI that texts and chats just like him. When she offered the use of his chatbot to his friends and family, she found a new business.
People were communicating with their deceased friend, sibling, and child, like he was still there. They wanted to tell him things, to talk about changes in their lives, to tell him they missed him, to hear what he had to say back.
This is human loss and grieving tempered by an AI version of the dead, and the implications are severe. Your personality could be preserved in servers after you die. Your loved ones could feel like they’re talking to you when you’re six feet under. Doesn’t that make anyone else feel uncomfortable?
Bringing an X-file to life
If you think about your closest loved one dying, talking to them via chatbot may seem like a dream come true. But in the long run, continuing a relationship with a dead person via their AI avatar is dangerous. Maybe it will help you grieve in the short term, but what are we replacing? And is it worth it?
Imagine texting a friend, a parent, a sibling, a spouse instead of Replika. Wouldn’t your interaction with them be more valuable than your conversation with this personality? Because you’re building on a lifetime of friendship, one that has value after the conversation is over. One that can exist in real tangible life. One that can actually help you grieve when the AI replacement just isn’t enough. One that can give you a hug.
“One day it will do things for you,” Kyuda said in an interview with Bloomberg, “including keeping you alive. You talk to it, and it becomes you.”
Replacing you is so easy
This kind of rhetoric from Replika’s founder has to make you wonder if this app was intended as a sort of technological fountain of youth. You never have to “die” as long as your personality sticks around to comfort your loved ones after you pass. I could even see myself trying to cope with a terminal diagnosis by creating my own Replika to assist family members after I’m gone.
But it’s wrong isn’t it? Isn’t it? Psychologically and socially wrong?
It all starts with a chatbot. That replicates your personality. It begins with a woman who was just trying to grieve. This is a taste of the future, and a scary one too. One of clones, downloaded personalities, and creating a life that sticks around after you’re gone.
Monday, April 10. 2017
A second life for open-world games as self-driving car training software
Via Tech Crunch
-----

A lot of top-tier video games enjoy lengthy long-tail lives with remasters and re-releases on different platforms, but the effort put into some games could pay dividends in a whole new way, as companies training things like autonomous cars, delivery drones and other robots are looking to rich, detailed virtual worlds to provided simulated training environments that mimic the real world.
Just as companies including Boom can now build supersonic jets with a small team and limited funds, thanks to advances made possible in simulation, startups like NIO (formerly NextEV) can now keep pace with larger tech concerns with ample funding in developing self-driving software, using simulations of real-world environments including those derived from games like Grand Theft Auto V. Bloomberg reports that the approach is increasingly popular among companies that are looking to supplement real-world driving experience, including Waymo and Toyota’s Research Institute.
There are some drawbacks, of course: Anyone will tell you that regardless of the industry, simulation can do a lot, but it can’t yet fully replace real-world testing, which always diverges in some ways from what you’d find in even the most advanced simulations. Also, miles driven in simulation don’t count towards the total miles driven by autonomous software figures most regulatory bodies will actually care about in determining the road worthiness of self-driving systems.
The more surprising takeaway here is that GTA V in this instance isn’t a second-rate alternative to simulation software created for the purpose of testing autonomous driving software – it proves an incredibly advanced testing platform, because of the care taken in its open-world game design. That means there’s no reason these two market uses can’t be more aligned in future: Better, more comprehensive open-world game design means better play experiences for users looking for that truly immersive quality, and better simulation results for researchers who then leverage the same platforms as a supplement to real-world testing.
Monday, January 30. 2017
Hungry penguins help keep car code safe
Tuesday, December 16. 2014
We’ve Put a Worm’s Mind in a Lego Robot's Body
Via Smithsonian
-----
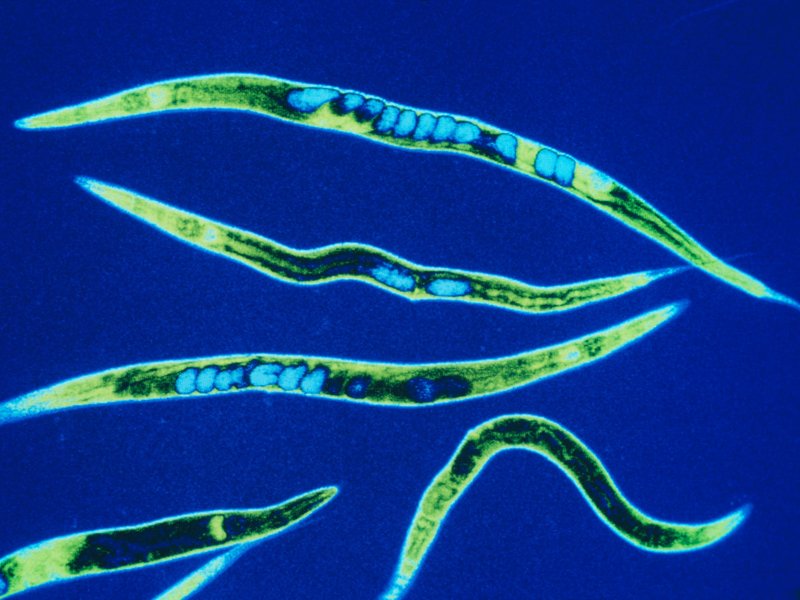
If the brain is a collection of electrical signals, then, if you could catalog all those those signals digitally, you might be able upload your brain into a computer, thus achieving digital immortality.
While the plausibility—and ethics—of this upload for humans can be debated, some people are forging ahead in the field of whole-brain emulation. There are massive efforts to map the connectome—all the connections in the brain—and to understand how we think. Simulating brains could lead us to better robots and artificial intelligence, but the first steps need to be simple.
So, one group of scientists started with the roundworm Caenorhabditis elegans, a critter whose genes and simple nervous system we know intimately.
The OpenWorm project has mapped the connections between the worm’s 302 neurons and simulated them in software. (The project’s ultimate goal is to completely simulate C. elegans as a virtual organism.) Recently, they put that software program in a simple Lego robot.
The worm’s body parts and neural networks now have LegoBot equivalents: The worm’s nose neurons were replaced by a sonar sensor on the robot. The motor neurons running down both sides of the worm now correspond to motors on the left and right of the robot, explains Lucy Black for I Programmer. She writes:
---
It is claimed that the robot behaved in ways that are similar to observed C. elegans. Stimulation of the nose stopped forward motion. Touching the anterior and posterior touch sensors made the robot move forward and back accordingly. Stimulating the food sensor made the robot move forward.
---
Timothy Busbice, a founder for the OpenWorm project, posted a video of the Lego-Worm-Bot stopping and backing:
The simulation isn’t exact—the program has some simplifications on the thresholds needed to trigger a "neuron" firing, for example. But the behavior is impressive considering that no instructions were programmed into this robot. All it has is a network of connections mimicking those in the brain of a worm.
Of course, the goal of uploading our brains assumes that we aren’t already living in a computer simulation. Hear out the logic: Technologically advanced civilizations will eventually make simulations that are indistinguishable from reality. If that can happen, odds are it has. And if it has, there are probably billions of simulations making their own simulations. Work out that math, and "the odds are nearly infinity to one that we are all living in a computer simulation," writes Ed Grabianowski for io9.
Is your mind spinning yet?
Thursday, November 20. 2014
MAME Arcade Game Emulator online
![[screenshot]](https://archive.org/serve/arcade_mpatrol/mpatrol_screenshot.gif)
Mame (standing for Multiple Arcade Machine Emulator) is an emulator able to load and run classic arcade games on your computer. In the late 90s, one was able to download arcade game's board numerical images (like a backup of the game program, called 'Rom files') from a set of websites. Arcade game lovers were trying to find as much as possible old game's boards in order to extract ROM programs from the physical board and make them available within the MAME emulator (which drives the emulator to support more and more games, by adding more and more emulated environments, as running a game within MAME is like switching on the original game, you have to go through ROM and hardware check like if your were in front of the original game hardware). One of these well none web sites was mame.dk.
While, for years, no one seems to care about those forgotten games brought back to life for free, classic arcade game's owners start to re-distribute their forgotten games on console like XBox or PS (re-discovering that one may be able to make money with those old games), and start to shutdown MAME based web sites, suing them for illegal distribution of games (obvious violation of copyright laws when freely distributing game's ROM files). Nevertheless this copyright infringement issue, MAME community has performed an impressive work of archive, saving thousand of vintage games that would have disappeared otherwise.
So it is quite a good news that many of those old games seem to be available again through this javascript version of the MAME emulator, being able to run and play those cute old games from within a simple web browser.
-----
Welcome to Internet Arcade
The Internet Arcade is a web-based library of arcade (coin-operated) video games from the 1970s through to the 1990s, emulated in JSMAME, part of the JSMESS software package. Containing hundreds of games ranging through many different genres and styles, the Arcade provides research, comparison, and entertainment in the realm of the Video Game Arcade.
The game collection ranges from early "bronze-age" videogames, with black and white screens and simple sounds, through to large-scale games containing digitized voices, images and music. Most games are playable in s ome form, although some are useful more for verification of behavior or programming due to the intensity and requirements of their systems.
Many games have a "boot-up" sequence when first turned on, where the systems run through a check and analysis, making sure all systems are go. In some cases, odd controllers make proper playing of the systems on a keyboard or joypad a pale imitation of the original experience. Please report any issues to the Internet Arcade Operator, Jason Scott.
If you are encountering issues with control, sound, or other technical problems, read this entry of some common solutions.
Also, Armchair Arcade (a video game review site) has written an excellent guide to playing on the Internet Arcade as well.
Friday, September 05. 2014
The Internet of Things is here and there -- but not everywhere yet
Via PCWorld
-----

The Internet of Things is still too hard. Even some of its biggest backers say so.
For all the long-term optimism at the M2M Evolution conference this week in Las Vegas, many vendors and analysts are starkly realistic about how far the vaunted set of technologies for connected objects still has to go. IoT is already saving money for some enterprises and boosting revenue for others, but it hasn’t hit the mainstream yet. That’s partly because it’s too complicated to deploy, some say.
For now, implementations, market growth and standards are mostly concentrated in specific sectors, according to several participants at the conference who would love to see IoT span the world.
Cisco Systems has estimated IoT will generate $14.4 trillion in economic value between last year and 2022. But Kevin Shatzkamer, a distinguished systems architect at Cisco, called IoT a misnomer, for now.
“I think we’re pretty far from envisioning this as an Internet,” Shatzkamer said. “Today, what we have is lots of sets of intranets.” Within enterprises, it’s mostly individual business units deploying IoT, in a pattern that echoes the adoption of cloud computing, he said.
In the past, most of the networked machines in factories, energy grids and other settings have been linked using custom-built, often local networks based on proprietary technologies. IoT links those connected machines to the Internet and lets organizations combine those data streams with others. It’s also expected to foster an industry that’s more like the Internet, with horizontal layers of technology and multivendor ecosystems of products.
What’s holding back the Internet of Things
The good news is that cities, utilities, and companies are getting more familiar with IoT and looking to use it. The less good news is that they’re talking about limited IoT rollouts for specific purposes.
“You can’t sell a platform, because a platform doesn’t solve a problem. A vertical solution solves a problem,” Shatzkamer said. “We’re stuck at this impasse of working toward the horizontal while building the vertical.”
“We’re no longer able to just go in and sort of bluff our way through a technology discussion of what’s possible,” said Rick Lisa, Intel’s group sales director for Global M2M. “They want to know what you can do for me today that solves a problem.”
One of the most cited examples of IoT’s potential is the so-called connected city, where myriad sensors and cameras will track the movement of people and resources and generate data to make everything run more efficiently and openly. But now, the key is to get one municipal project up and running to prove it can be done, Lisa said.

ThroughTek, based in China, used a connected fan to demonstrate an Internet of Things device management system at the M2M Evolution conference in Las Vegas this week.
The conference drew stories of many successful projects: A system for tracking construction gear has caught numerous workers on camera walking off with equipment and led to prosecutions. Sensors in taxis detect unsafe driving maneuvers and alert the driver with a tone and a seat vibration, then report it to the taxi company. Major League Baseball is collecting gigabytes of data about every moment in a game, providing more information for fans and teams.
But for the mass market of small and medium-size enterprises that don’t have the resources to do a lot of custom development, even targeted IoT rollouts are too daunting, said analyst James Brehm, founder of James Brehm & Associates.
There are software platforms that pave over some of the complexity of making various devices and applications talk to each other, such as the Omega DevCloud, which RacoWireless introduced on Tuesday. The DevCloud lets developers write applications in the language they know and make those apps work on almost any type of device in the field, RacoWireless said. Thingworx, Xively and Gemalto also offer software platforms that do some of the work for users. But the various platforms on offer from IoT specialist companies are still too fragmented for most customers, Brehm said. There are too many types of platforms—for device activation, device management, application development, and more. “The solutions are too complex.”
He thinks that’s holding back the industry’s growth. Though the past few years have seen rapid adoption in certain industries in certain countries, sometimes promoted by governments—energy in the U.K., transportation in Brazil, security cameras in China—the IoT industry as a whole is only growing by about 35 percent per year, Brehm estimates. That’s a healthy pace, but not the steep “hockey stick” growth that has made other Internet-driven technologies ubiquitous, he said.
What lies ahead
Brehm thinks IoT is in a period where customers are waiting for more complete toolkits to implement it—essentially off-the-shelf products—and the industry hasn’t consolidated enough to deliver them. More companies have to merge, and it’s not clear when that will happen, he said.
“I thought we’d be out of it by now,” Brehm said. What’s hard about consolidation is partly what’s hard about adoption, in that IoT is a complex set of technologies, he said.
And don’t count on industry standards to simplify everything. IoT’s scope is so broad that there’s no way one standard could define any part of it, analysts said. The industry is evolving too quickly for traditional standards processes, which are often mired in industry politics, to keep up, according to Andy Castonguay, an analyst at IoT research firm Machina.
Instead, individual industries will set their own standards while software platforms such as Omega DevCloud help to solve the broader fragmentation, Castonguay believes. Even the Industrial Internet Consortium, formed earlier this year to bring some coherence to IoT for conservative industries such as energy and aviation, plans to work with existing standards from specific industries rather than write its own.
Ryan Martin, an analyst at 451 Research, compared IoT standards to human languages.
“I’d be hard pressed to say we are going to have one universal language that everyone in the world can speak,” and even if there were one, most people would also speak a more local language, Martin said.
Thursday, July 03. 2014
Keren Elazari: Hackers: the Internet's immune system
Tuesday, May 13. 2014
How the police can trace photos back to your camera
Via ITProPortal
-----

Forensic experts have long been able to match a series of prints to the hand that left them, or a bullet to the gun that fired it. Now, the same thing is being done with the photos taken by digital cameras, and is ushering in a new era of digital crime fighting.
New technology is now allowing law enforcement officers to search through any collection of images to help track down the identity of photo-taking criminals, such as smartphone thieves and child pornographers.
Investigations in the past have shown that a digital photo can be paired with the exact same camera that took it, due to the patterns of Sensor Pattern Noise (SPN) imprinted on the photos by the camera's sensor.
Since each pattern is idiosyncratic, this allows law enforcement to "fingerprint" any photos taken. And once the signature has been identified, the police can track the criminal across the Internet, through social media and anywhere else they've kept photos.
Researchers have grabbed photos from Facebook, Flickr, Tumblr, Google+, and personal blogs to see whether one individual image could be matched to a specific user's account.
In a paper entitled "On the usage of Sensor Pattern Noise for Picture-to-Identity linking through social network accounts", the team argues that "digital imaging devices have gained an important role in everyone's life, due to a continuously decreasing price, and of the growing interest on photo sharing through social networks"
Friday, March 07. 2014
Scientists develop a lie detector for tweets
Via The Telegraph
-----

The Twitter logo displayed on a smart phone Photo: PA
Scientists have developed the ultimate lie detector for social media – a system that can tell whether a tweeter is telling the truth.
The creators of the system called Pheme, named after the Greek mythological figure known for scandalous rumour, say it can judge instantly between truth and fiction in 140 characters or less.
Researchers across Europe are joining forces to analyse the truthfulness of statements that appear on social media in “real time” and hope their system will prevent scurrilous rumours and false statements from taking hold, the Times reported.
The creators believe that the system would have proved useful to the police and authorities during the London Riots of 2011. Tweeters spread false reports that animals had been released from London Zoo and landmarks such as the London Eye and Selfridges had been set on fire, which caused panic and led to police being diverted.
Kalina Bontcheva, from the University of Sheffield’s engineering department, said that the system would be able to test information quickly and trace its origins. This would enable governments, emergency services, health agencies, journalists and companies to respond to falsehoods.
Tuesday, March 04. 2014
Should Students Be Able To Take Coding Classes For Language Credits?
Via Gizmodo
-----

The Kentucky Senate just passed a law that will let students take computer programming classes to satisfy their foreign language requirements. Do you think that's a good move?
What this new law means is, rather than taking three years of Spanish or French or whatever, kids can choose to learn to code. Sure, whether it's Java or German, they're both technically languages. But they're also two very different skills. You could easily argue that it's still very necessary for students to pick up a few years of a foreign tongue—though, on the other hand, coding is a skill that's probably a hell of a lot more practically applicable for today's high school students.
I, for one, have said countless times that if I could travel through time, I probably would have taken some computer science classes in college. Too late now, but not for Kentucky teenagers. So what do you think of this new law?
Image by Olly/Shutterstock
Quicksearch
Popular Entries
- The great Ars Android interface shootout (130085)
- MeCam $49 flying camera concept follows you around, streams video to your phone (99010)
- Norton cyber crime study offers striking revenue loss statistics (98603)
- The PC inside your phone: A guide to the system-on-a-chip (56387)
- Norton cyber crime study offers striking revenue loss statistics (54832)
Categories

Show tagged entries
Syndicate This Blog
Calendar
|
|
July '25 | |||||
| Mon | Tue | Wed | Thu | Fri | Sat | Sun |
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 | |||