Internet-connected devices are clearly the future of controlling everything from your home to your car, but actually getting "the Internet of things" rolling has been slow going. Now a new project looks to brighten those prospects, quite literally, with a smart light socket.
Created by Zach Supalla (who was inspired by his father, who is deaf and uses lights for notifications), the Spark Socket
lets you to connect the light sockets in your home to the Internet,
allowing them to be controlled via PC, smartphone and tablet (iOS and Android
are both supported) through a Wi-Fi connection. What makes this device
so compelling is its simplicity. By simply screwing a normal light bulb
into the Spark Socket, connected to a standard light fixture, you can
quickly begin controlling and programming the lights in your home.
Some of the uses for the Spark Socket include allowing you to have
your house lights flash when you receive a text or email, programming
lights to turn on with certain alarms, and having lights dim during
certain times of the day. A very cool demonstration of how the device
works can be tested by simply visiting this live Ustream page and tweeting #hellospark. We tested it and the light flashed on instantly as soon as we tweeted the hashtag.
The device is currently on Kickstarter, inching closer toward
its $250,000 goal, and if successful will retail for $60 per unit. You
can watch Supalla offer a more detailed description of the product and
how it came to be in the video below.
How anonymous are you when browsing online? If you're not sure, head
to StayInvisible, where you'll get an immediate online privacy test
revealing what identifiable information is being collected in your
browser.
The site displays the location (via IP address) and
language collected, possible tracking cookies, and other browser
features that could create a unique fingerprint of your browser and session.
If you'd prefer your browsing to be private and anonymous, we have lotsof guidesfor that. Although StayInvisible no longer has the list of proxy tools we mentioned previously, the site is also still useful if you want to test your proxy or VPN server's effectiveness. (Could've come in handy too for a certain CIA director and his biographer.)
Telefonica Digital has unveiled
a new plastic brick device designed to connect just about anything you
can think of to the Internet. These plastic bricks are called Thinking
Things and are described as a simple solution for connecting almost
anything wirelessly to the Internet. Thinking Things is under
development right now.
Telefonica I+D invented the Thinking Things concept and believes that
the product will significantly boost the development of M2M
communications and help to establish an Internet of physical things.
Thinking Things can connect all sorts of inanimate objects to the
Internet, including thermostats and allows users to monitor various
assets or tracking loads.
Thinking Things are comprised of three different elements. The first
is a physical module that contains the core communications and logic
hardware. The second element is energy to make electronics work via a
battery or AC power. The third element is a variety of sensors and
actuators to perform the tasks users want.
The Thinking Things device is modular, and the user can connect
together multiple bricks to perform the task they need. This is an
interesting project that can be used for anything from home automation
offering simple control over a lamp to just about anything else you can
think of. The item connected to the web using Thinking Things
automatically gets its own webpage. That webpage provides online access
allowing the user to control the function of the modules and devices
attached to the modules. An API allows developers to access all
functionality of the Thinking Things from within their software.
In the future, we’re told, homes will be filled with smart gadgets
connected to the Internet, giving us remote control of our homes and
making the grid smarter. Wireless thermostats and now lighting appear to
be leading the way.
Startup Greenwave Reality today announced that its wireless LED
lighting kit is available in the U.S., although not through retail sales
channels. The company, headed by former consumer electronics
executives, plans to sell the set, which includes four
40-watt-equivalent bulbs and a smartphone application, through utilities
and lighting companies for about $200, according to CEO Greg Memo.
The Connected Lighting Solution includes four EnergyStar-rated LED
light bulbs, a gateway box that connects to a home router, and a remote
control. Customers also download a smartphone or tablet app that lets
people turn lights on or off, dim lights, or set up schedules.
Installation is extremely easy. Greenwave Reality sent me a set to
try out, and I had it operating within a few minutes. The bulbs each
have their own IP address and are paired with the gateway out of the
box, so there’s no need to configure the bulbs, which communicate over
the home wireless network or over the Internet for remote access.
Using the app is fun, if only for the novelty. When’s the last time
you used your iPhone to turn off the lights downstairs? It also lets
people put lights on a schedule (they can be used outside in a sheltered
area but not exposed directly to water) or set custom scenes. For
instance, Memo set some of the wireless bulbs in his kitchen to be at
half dimness during the day.
Many smart-home or smart-building advocates say that lighting is the
toehold for a house full of networked gadgets. “The thing about lighting
is that it’s a lot more personal than appliances or a thermostat. It’s
actually something that affects people’s moods and comfort,” Memo says.
“We think this will move the needle on the automated home.”
Rather than sell directly to consumers, as most other smart lighting
products are, Greenwave Reality intends to sell through utilities and
service companies. While gadget-oriented consumers may be attracted to
wireless light bulbs, utilities are interested in energy savings. And
because these lights are connected to the Internet, energy savings can
be quantified.
In Europe and many states, utilities are required to spend money on
customer efficiency programs, such as rebates for efficient appliances
or subsidizing compact fluorescent bulbs. But unlike traditional CFLs,
network-connected LEDs can report usage information. That allows
Greenwave Reality to see how many bulbs are actually in use and verify
the intended energy savings of, for example, subsidized light bulbs.
(The reported data would be anonymized, Memo says.) Utilities could also
make lighting part of demand response programs to lower power during
peak times.
As for performance of the bulbs, there is essentially no latency when
using the smartphone app. The remote control essentially brings dimmers
to fixtures that don’t have them already.
For people who like the idea of bringing the Internet of things to their home with smart gadgets, LED lights (and thermostats)
seem like a good way to start. But in the end, it may be the energy
savings of better managed and more efficient light bulbs that will give
wireless lighting a broader appeal.
The iPhone 5 is the latest smartphone to hop on-board the LTE (Long Term Evolution)
bandwagon, and for good reason: The mobile broadband standard is fast,
flexible, and designed for the future. Yet LTE is still a young
technology, full of growing pains. Here’s an overview of where it came
from, where it is now, and where it might go from here.
The evolution of ‘Long Term Evolution’
LTE is a mobile broadband standard developed by the 3GPP (3rd Generation Partnership Project),
a group that has developed all GSM standards since 1999. (Though GSM
and CDMA—the network Verizon and Sprint use in the United States—were at
one time close competitors, GSM has emerged as the dominant worldwide
mobile standard.)
Cell networks began as analog, circuit-switched systems nearly identical
in function to the public switched telephone network (PSTN), which
placed a finite limit on calls regardless of how many people were
speaking on a line at one time.
The second-generation, GPRS,
added data (at dial-up modem speed). GPRS led to EDGE, and then 3G,
which treated both voice and data as bits passing simultaneously over
the same network (allowing you to surf the web and talk on the phone at
the same time).
GSM-evolved 3G (which brought faster speeds) started with UMTS, and then
accelerated into faster and faster variants of 3G, 3G+, and “4G”
networks (HSPA, HSDPA, HSUPA, HSPA+, and DC-HSPA).
Until now, the term “evolution” meant that no new standard broke or
failed to work with the older ones. GSM, GPRS, UMTS, and so on all work
simultaneously over the same frequency bands: They’re intercompatible,
which made it easier for carriers to roll them out without losing
customers on older equipment. But these networks were being held back by
compatibility.
That’s where LTE comes in. The “long term” part means: “Hey, it’s time
to make a big, big change that will break things for the better.”
LTE needs its own space, man
LTE has “evolved” beyond 3G networks by incorporating new radio
technology and adopting new spectrum. It allows much higher speeds than
GSM-compatible standards through better encoding and wider channels.
(It’s more “spectrally efficient,” in the jargon.)
LTE is more flexible than earlier GSM-evolved flavors, too: Where GSM’s
3G variants use 5 megahertz (MHz) channels, LTE can use a channel size
from 1.4 MHz to 20 MHz; this lets it work in markets where spectrum is
scarce and sliced into tiny pieces, or broadly when there are wide
swaths of unused or reassigned frequencies. In short, the wider the
channel—everything else being equal—the higher the throughput.
Speeds are also boosted through MIMO (multiple input, multiple output),
just as in 802.11n Wi-Fi. Multiple antennas allow two separate
benefits: better reception, and multiple data streams on the same
spectrum.
LTE complications
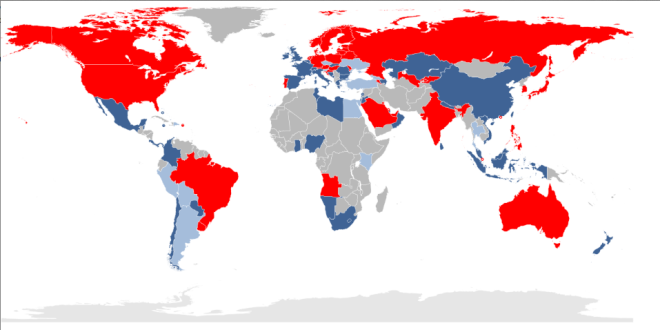
This map, courtesy Wikipedia,
shows countries in varying states of LTE readiness. Those in red have
commercial service; dark blue countries have LTE networks planned and
deploying; light blue countries are investigating LTE, and grey
countries have no LTE service at all.
Unfortunately, in practice, LTE implementation gets sticky: There are 33 potential bands for LTE, based on a carrier’s local regulatory domain. In contrast, GSM has just 14 bands,
and only five of those are widely used. (In broad usage, a band is two
sets of paired frequencies, one devoted to upstream traffic and the
other committed to downstream. They can be a few MHz apart or hundreds
of MHz apart.)
And while LTE allows voice, no standard has yet been agreed upon;
different carriers could ultimately choose different approaches, leaving
it to handset makers to build multiple methods into a single phone,
though they’re trying to avoid that. In the meantime, in the U.S.,
Verizon and AT&T use the older CDMA and GSM networks for voice
calls, and LTE for data.
LTE in the United States
Of the four major U.S. carriers, AT&T, Verizon, and Sprint have LTE networks, with T-Mobile set to start supporting LTE
in the next year. But that doesn’t mean they’re set to play nice. We
said earlier that current LTE frequencies are divided up into 33
spectrum bands: With the exception of AT&T and T-Mobile, which share
frequencies in band 4, each of the major U.S. carriers has its own
band. Verizon uses band 13; Sprint has spectrum in band 26; and AT&T
holds band 17 in addition to some crossover in band 4.
In addition, smaller U.S. carriers, like C Spire, U.S. Cellular, and Clearwire, all have their own separate piece of the spectrum pie: C Spire and U.S. Cellular use band 12, while Clearwire uses band 41.
As such, for a manufacturer to support LTE networks in the United States alone,
it would need to build a receiver that could tune into seven different
LTE bands—let alone the various flavors of GSM-evolved or CDMA networks.
With the iPhone, Apple tried to cut through the current Gordian Knot by
releasing two separate models, the A1428 and A1429, which cover a
limited number of different frequencies depending on where they’re
activated. (Apple has kindly released a list of countries
that support its three iPhone 5 models.) Other companies have chosen to
restrict devices to certain frequencies, or to make numerous models of
the same phone.
Banded together
Other solutions are coming. Qualcomm made a regulatory filing in June
regarding a seven-band LTE chip, which could be in shipping devices
before the end of 2012 and could allow a future iPhone to be activated
in different fashions. Within a year or so, we should see
most-of-the-world phones, tablets, and other LTE mobile devices that
work on the majority of large-scale LTE networks.
That will be just in time for the next big thing: LTE-Advanced, the true
fulfillment of what was once called 4G networking, with rates that
could hit 1 Gbps in the best possible cases of wide channels and short
distances. By then, perhaps the chip, handset, and carrier worlds will
have converged to make it all work neatly together.
At today’s hearing
of the Subcommittee on Intellectual Property, Competition and the
Internet of the House Judiciary Committee, I referred to an attempt to
“sabotage” the forthcoming Do Not Track standard. My written testimony
discussed a number of other issues as well, but Do Not Track was
clearly on the Representatives’ minds: I received multiple questions on
the subject. Because of the time constraints, oral answers at a
Congressional hearing are not the place for detail, so in this blog
post, I will expand on my answers this morning, and explain why I think
that word is appropriate to describe the current state of play.
Background
For years, advertising networks have offered the option to opt out
from their behavioral profiling. By visiting a special webpage provided
by the network, users can set a browser cookie saying, in effect, “This
user should not be tracked.” This system, while theoretically offering
consumers choice about tracking, suffers from a series of problems that
make it frequently ineffective in practice. For one thing, it relies
on repetitive opt-out: the user needs to visit multiple opt-out pages, a
daunting task given the large and constantly shifting list of
advertising companies, not all of which belong to industry groups with
coordinated opt-out pages. For another, because it relies on
cookies—the same vector used to track users in the first place—it is
surprisingly fragile. A user who deletes cookies to protect her privacy
will also delete the no-tracking cookie, thereby turning tracking back
on. The resulting system is a monkey’s paw: unless you ask for what you want in exactly the right way, you get nothing.
The idea of a Do Not Track header gradually emerged
in 2009 and 2010 as a simpler alternative. Every HTTP request by which
a user’s browser asks a server for a webpage contains a series of headers
with information about the webpage requested and the browser. Do Not
Track would be one more. Thus, the user’s browser would send, as part
of its request, the header:
DNT: 1
The presence of such a header would signal to the website that the
user requests not to be tracked. Privacy advocates and technologists
worked to flesh out the header; privacy officials in the United States
and Europe endorsed it. The World Wide Web Consortium (W3C) formed a
public Tracking Protection Working Group with a charter to design a technical standard for Do Not Track.
Significantly, a W3C standard is not law. The legal effect of Do Not
Track will come from somewhere else. In Europe, it may be enforced directly on websites under existing data protection law. In the United States, legislation has been introduced in the House and Senate
that would have the Federal Trade Commission promulgate Do Not Track
regulations. Without legislative authority, the FTC could not require
use of Do Not Track, but would be able to treat a website’s false claims
to honor Do Not Track as a deceptive trade practice. Since most online
advertising companies find it important from a public relations point
of view to be able to say that they support consumer choice, this last
option may be significant in practice. And finally, in an important recent paper,
Joshua Fairfield argues that use of the Do Not Track header itself
creates an enforceable contract prohibiting tracking under United States
law.
In all of these cases, the details of the Do Not Track standard will
be highly significant. Websites’ legal duties are likely to depend on
the technical duties specified in the standard, or at least be strongly
influenced by them. For example, a company that promises to be Do Not
Track compliant thereby promises to do what is required to comply with
the standard. If the standard ultimately allows for limited forms of
tracking for click-fraud prevention, the company can engage in those
forms of tracking even if the user sets the header. If not, it cannot.
Thus, there is a lot at stake in the Working Group’s discussions.
Internet Explorer and Defaults
On May 31, Microsoft announced that Do Not Track would be on by default
in Internet Explorer 10. This is a valuable feature, regardless of how
you feel about behavioral ad targeting itself. A recurring theme of
the online privacy wars is that unusably complicated privacy interfaces
confuse users in ways that cause them to make mistakes and undercut
their privacy. A default is the ultimate easy-to-use privacy control.
Users who care about what websites know about them do not need to
understand the details to take a simple step to protect themselves.
Using Internet Explorer would suffice by itself to prevent tracking from
a significant number of websites.
This is an important principle. Technology can empower users to
protect their privacy. It is impractical, indeed impossible, for users
to make detailed privacy choices about every last detail of their online
activities. The task of getting your privacy right is profoundly
easier if you have access to good tools to manage the details.
Antivirus companies compete vigorously to manage the details of malware
prevention for users. So too with privacy: we need thriving markets in
tools under the control of users to manage the details.
There is immense value if users can delegate some of their privacy
decisions to software agents. These delegation decisions should be dead
simple wherever possible. I use Ghostery
to block cookies. As tools go, it is incredibly easy to use—but it
still is not easy enough. The choice of browser is a simple choice, one
that every user makes. That choice alone should be enough to count as
an indication of a desire for privacy. Setting Do Not Track by default
is Microsoft’s offer to users. If they dislike the setting, they can
change it, or use a different browser.
The Pushback
Microsoft’s move intersected with a long-simmering discussion on the
Tracking Protection Working Group’s mailing list. The question of Do
Not Track defaults had been one of the first issues the Working Group raised when it launched in September 2011. The draft text that emerged by the spring remains painfully ambiguous on the issue. Indeed, the group’s May 30 teleconference—the
day before Microsoft’s announcement—showed substantial disagreement
about defaults and what a server could do if it believed it was seeing a
default Do Not Track header, rather than one explicitly set by the
user. Antivirus software AVG includes a cookie-blocking tool
that sets the Do Not Track header, which sparked extensive discussion
about plugins, conflicting settings, and explicit consent. And the last
few weeks following Microsoft’s announcement have seen a renewed debate
over defaults.
Many industry participants object to Do Not Track by default.
Technology companies with advertising networks have pushed for a crucial
pair of positions:
User agents (i.e. browsers and apps) that turned on Do Not Track by default would be deemed non-compliant with the standard.
Websites that received a request from a noncompliant user agent would be free to disregard a DNT: 1 header.
This position has been endorsed by representatives the three
companies I mentioned in my testimony today: Yahoo!, Google, and Adobe.
Thus, here is an excerpt from an email to the list by Shane Wiley from Yahoo!:
If you know that an UA is non-compliant, it should be fair to NOT
honor the DNT signal from that non-compliant UA and message this back to
the user in the well-known URI or Response Header.
Here is an excerpt from an email to the list by Ian Fette from Google:
There’s other people in the working group, myself included, who feel that
since you are under no obligation to honor DNT in the first place (it is
voluntary and nothing is binding until you tell the user “Yes, I am
honoring your DNT request”) that you already have an option to reject a
DNT:1 request (for instance, by sending no DNT response headers). The
question in my mind is whether we should provide websites with a mechanism
to provide more information as to why they are rejecting your request, e.g.
“You’re using a user agent that sets a DNT setting by default and thus I
have no idea if this is actually your preference or merely another large
corporation’s preference being presented on your behalf.”
And here is an excerpt from an email to the list by Roy Fielding from Adobe:
The server would say that the non-compliant browser is broken and
thus incapable of transmitting a true signal of the user’s preferences.
Hence, it will ignore DNT from that browser, though it may provide
other means to control its own tracking. The user’s actions are
irrelevant until they choose a browser capable of communicating
correctly or make use of some means other than DNT.
Pause here to understand the practical implications of writing this
position into the standard. If Yahoo! decides that Internet Explorer 10
is noncompliant because it defaults on, then users who picked Internet
Explorer 10 to avoid being tracked … will be tracked. Yahoo! will claim
that it is in compliance with the standard and Internet Explorer 10 is
not. Indeed, there is very little that an Internet Explorer 10 user
could do to avoid being tracked. Because her user agent is now flagged
by Yahoo! as noncompliant, even if she manually sets the header herself,
it will still be ignored.
The Problem
A cynic might observe how effectively this tactic neutralizes the
most serious threat that Do Not Track poses to advertisers: that people
might actually use it. Manual opt-out cookies are tolerable
because almost no one uses them. Even Do Not Track headers that are off
by default are tolerable because very few people will use them.
Microsoft’s and AVG’s decisions raise the possibility that significant
numbers of web users would be removed from tracking. Pleasing user
agent noncompliance is a bit of jujitsu, a way of meeting the threat
where it is strongest. The very thing that would make Internet Explorer
10’s Do Not Track setting widely used would be the very thing to
“justify” ignoring it.
But once websites have an excuse to look beyond the header they
receive, Do Not Track is dead as a practical matter. A DNT:1 header is
binary: it is present or it is not. But second-guessing interface
decisions is a completely open-ended question. Was the check box to
enable Do Not Track worded clearly? Was it bundled with some other user
preference? Might the header have been set by a corporate network
rather than the user? These are the kind of process questions that can
be lawyered to death. Being able to question whether a user really meant her Do Not Track header is a license to ignore what she does mean.
Return to my point above about tools. I run a browser with multiple
plugins. At the end of the day, these pieces of software collaborate to
set a Do Not Track header, or not. This setting is under my control: I
can install or uninstall any of the software that was responsible for
it. The choice of header is strictly between me and my user agent. As far as the Do Not Track specification is concerned,
websites should adhere to a presumption of user competence: whatever
value the header has, it has with the tacit or explicit consent of the
user.
Websites are not helpless against misconfigured software. If they
really think the user has lost control over her own computer, they have a
straightforward, simple way of finding out. A website can display a
popup window or an overlay, asking the user whether she really wants to
enable Do Not Track, and explaining the benefits disabling it would
offer. Websites have every opportunity to press their case for
tracking; if that case is as persuasive as they claim, they should have
no fear of making it one-on-one to users.
This brings me to the bitterest irony of Do Not Track defaults. For
more than a decade, the online advertising industry has insisted that
notice and an opportunity to opt out is sufficient choice for consumers.
It has fought long and hard against any kind of heightened consent
requirement for any of its practices. Opt-out, in short, is good
enough. But for Do Not Track, there and there alone, consumers
allegedly do not understand the issues, so consent must be explicit—and opt-in only.
Now What?
It is time for the participants in the Tracking Protection Working
Group to take a long, hard look at where the process is going. It is
time for the rest of us to tell them, loudly, that the process is going
awry. It is true that Do Not Track, at least in the present regulatory
environment, is voluntary. But it does not follow that the standard
should allow “compliant” websites to pick and choose which pieces to
comply with. The job of the standard is to spell out how a user agent
states a Do Not Track request, and what behavior is required of websites
that choose to implement the standard when they receive such a request.
That is, the standard must be based around a simple principle:
A Do Not Track header expresses a meaning, not a process.
The meaning of “DNT: 1” is that the receiving website should not
track the user, as spelled out in the rest of the standard. It is not
the website’s concern how the header came to be set.
If Facebook were a country, a conceit that founder Mark Zuckerberg has entertained in public, its 900 million members would make it the third largest in the world.
It would far outstrip any regime past or present in how intimately
it records the lives of its citizens. Private conversations, family
photos, and records of road trips, births, marriages, and deaths all
stream into the company's servers and lodge there. Facebook has
collected the most extensive data set ever assembled on human social
behavior. Some of your personal information is probably part of it.
And yet, even as Facebook has embedded itself into modern life, it
hasn't actually done that much with what it knows about us. Now that
the company has gone public, the pressure to develop new sources of
profit (see "The Facebook Fallacy")
is likely to force it to do more with its hoard of information. That
stash of data looms like an oversize shadow over what today is a modest
online advertising business, worrying privacy-conscious Web users (see "Few Privacy Regulations Inhibit Facebook")
and rivals such as Google. Everyone has a feeling that this
unprecedented resource will yield something big, but nobody knows quite
what.
Heading Facebook's effort to figure out what can be learned from all our data is Cameron Marlow,
a tall 35-year-old who until recently sat a few feet away from
Zuckerberg. The group Marlow runs has escaped the public attention that
dogs Facebook's founders and the more headline-grabbing features of its
business. Known internally as the Data Science Team, it is a kind of
Bell Labs for the social-networking age. The group has 12
researchers—but is expected to double in size this year. They apply
math, programming skills, and social science to mine our data for
insights that they hope will advance Facebook's business and social
science at large. Whereas other analysts at the company focus on
information related to specific online activities, Marlow's team can
swim in practically the entire ocean of personal data that Facebook
maintains. Of all the people at Facebook, perhaps even including the
company's leaders, these researchers have the best chance of discovering
what can really be learned when so much personal information is
compiled in one place.
Facebook has all this information because it has found ingenious
ways to collect data as people socialize. Users fill out profiles with
their age, gender, and e-mail address; some people also give additional
details, such as their relationship status and mobile-phone number. A
redesign last fall introduced profile pages in the form of time lines
that invite people to add historical information such as places they
have lived and worked. Messages and photos shared on the site are often
tagged with a precise location, and in the last two years Facebook has
begun to track activity elsewhere on the Internet, using an addictive
invention called the "Like" button.
It appears on apps and websites outside Facebook and allows people to
indicate with a click that they are interested in a brand, product, or
piece of digital content. Since last fall, Facebook has also been able
to collect data on users' online lives beyond its borders automatically:
in certain apps or websites, when users listen to a song or read a news
article, the information is passed along to Facebook, even if no one
clicks "Like." Within the feature's first five months, Facebook
catalogued more than five billion instances
of people listening to songs online. Combine that kind of information
with a map of the social connections Facebook's users make on the site,
and you have an incredibly rich record of their lives and interactions.
"This is the first time the world has seen this scale and quality
of data about human communication," Marlow says with a
characteristically serious gaze before breaking into a smile at the
thought of what he can do with the data. For one thing, Marlow is
confident that exploring this resource will revolutionize the scientific
understanding of why people behave as they do. His team can also help
Facebook influence our social behavior for its own benefit and that of
its advertisers. This work may even help Facebook invent entirely new
ways to make money.
Contagious Information
Marlow eschews the collegiate programmer style of Zuckerberg and
many others at Facebook, wearing a dress shirt with his jeans rather
than a hoodie or T-shirt. Meeting me shortly before the company's
initial public offering in May, in a conference room adorned with a
six-foot caricature of his boss's dog spray-painted on its glass wall,
he comes across more like a young professor than a student. He might
have become one had he not realized early in his career that Web
companies would yield the juiciest data about human interactions.
In 2001, undertaking a PhD at MIT's Media Lab, Marlow created a
site called Blogdex that automatically listed the most "contagious"
information spreading on weblogs. Although it was just a research
project, it soon became so popular that Marlow's servers crashed.
Launched just as blogs were exploding into the popular consciousness and
becoming so numerous that Web users felt overwhelmed with information,
it prefigured later aggregator sites such as Digg and Reddit. But Marlow
didn't build it just to help Web users track what was popular online.
Blogdex was intended as a scientific instrument to uncover the social
networks forming on the Web and study how they spread ideas. Marlow went
on to Yahoo's research labs to study online socializing for two years.
In 2007 he joined Facebook, which he considers the world's most powerful
instrument for studying human society. "For the first time," Marlow
says, "we have a microscope that not only lets us examine social
behavior at a very fine level that we've never been able to see before
but allows us to run experiments that millions of users are exposed to."
Marlow's team works with managers across Facebook to find patterns
that they might make use of. For instance, they study how a new feature
spreads among the social network's users. They have helped Facebook
identify users you may know but haven't "friended," and recognize those
you may want to designate mere "acquaintances" in order to make their
updates less prominent. Yet the group is an odd fit inside a company
where software engineers are rock stars who live by the mantra "Move
fast and break things." Lunch with the data team has the feel of a
grad-student gathering at a top school; the typical member of the group
joined fresh from a PhD or junior academic position and prefers to talk
about advancing social science than about Facebook as a product or
company. Several members of the team have training in sociology or
social psychology, while others began in computer science and started
using it to study human behavior. They are free to use some of their
time, and Facebook's data, to probe the basic patterns and motivations
of human behavior and to publish the results in academic journals—much
as Bell Labs researchers advanced both AT&T's technologies and the
study of fundamental physics.
It may seem strange that an eight-year-old company without a
proven business model bothers to support a team with such an academic
bent, but Marlow says it makes sense. "The biggest challenges Facebook
has to solve are the same challenges that social science has," he says.
Those challenges include understanding why some ideas or fashions spread
from a few individuals to become universal and others don't, or to what
extent a person's future actions are a product of past communication
with friends. Publishing results and collaborating with university
researchers will lead to findings that help Facebook improve its
products, he adds.
For one example of how Facebook can serve as a proxy for examining
society at large, consider a recent study of the notion that any person
on the globe is just six degrees of separation from any other. The
best-known real-world study, in 1967, involved a few hundred people
trying to send postcards to a particular Boston stockholder. Facebook's
version, conducted in collaboration with researchers from the University
of Milan, involved the entire social network as of May 2011, which
amounted to more than 10 percent of the world's population. Analyzing
the 69 billion friend connections among those 721 million people showed
that the world is smaller than we thought: four intermediary friends are
usually enough to introduce anyone to a random stranger. "When
considering another person in the world, a friend of your friend knows a
friend of their friend, on average," the technical paper pithily
concluded. That result may not extend to everyone on the planet, but
there's good reason to believe that it and other findings from the Data
Science Team are true to life outside Facebook. Last year the Pew
Research Center's Internet & American Life Project found that 93
percent of Facebook friends had met in person. One of Marlow's
researchers has developed a way to calculate a country's "gross national
happiness" from its Facebook activity by logging the occurrence of
words and phrases that signal positive or negative emotion. Gross
national happiness fluctuates in a way that suggests the measure is
accurate: it jumps during holidays and dips when popular public figures
die. After a major earthquake in Chile in February 2010, the country's
score plummeted and took many months to return to normal. That event
seemed to make the country as a whole more sympathetic when Japan
suffered its own big earthquake and subsequent tsunami in March 2011;
while Chile's gross national happiness dipped, the figure didn't waver
in any other countries tracked (Japan wasn't among them). Adam Kramer,
who created the index, says he intended it to show that Facebook's data
could provide cheap and accurate ways to track social trends—methods
that could be useful to economists and other researchers.
Other work published by the group has more obvious utility for
Facebook's basic strategy, which involves encouraging us to make the
site central to our lives and then using what it learns to sell ads. An early study
looked at what types of updates from friends encourage newcomers to the
network to add their own contributions. Right before Valentine's Day
this year a blog post from the Data Science Team
listed the songs most popular with people who had recently signaled on
Facebook that they had entered or left a relationship. It was a hint of
the type of correlation that could help Facebook make useful predictions
about users' behavior—knowledge that could help it make better guesses
about which ads you might be more or less open to at any given time.
Perhaps people who have just left a relationship might be interested in
an album of ballads, or perhaps no company should associate its brand
with the flood of emotion attending the death of a friend. The most
valuable online ads today are those displayed alongside certain Web
searches, because the searchers are expressing precisely what they want.
This is one reason why Google's revenue is 10 times Facebook's. But
Facebook might eventually be able to guess what people want or don't
want even before they realize it.
Recently the Data Science Team has begun to use its unique
position to experiment with the way Facebook works, tweaking the
site—the way scientists might prod an ant's nest—to see how users react.
Eytan Bakshy, who joined Facebook last year after collaborating with
Marlow as a PhD student at the University of Michigan, wanted to learn
whether our actions on Facebook are mainly influenced by those of our
close friends, who are likely to have similar tastes. That would shed
light on the theory that our Facebook friends create an "echo chamber"
that amplifies news and opinions we have already heard about. So he
messed with how Facebook operated for a quarter of a billion users. Over
a seven-week period, the 76 million links that those users shared with
each other were logged. Then, on 219 million randomly chosen occasions,
Facebook prevented someone from seeing a link shared by a friend. Hiding
links this way created a control group so that Bakshy could assess how
often people end up promoting the same links because they have similar
information sources and interests.
He found that our close friends strongly sway which information we
share, but overall their impact is dwarfed by the collective influence
of numerous more distant contacts—what sociologists call "weak ties." It
is our diverse collection of weak ties that most powerfully determines
what information we're exposed to.
That study provides strong evidence against the idea that social networking creates harmful "filter bubbles," to use activist Eli Pariser's
term for the effects of tuning the information we receive to match our
expectations. But the study also reveals the power Facebook has. "If
[Facebook's] News Feed is the thing that everyone sees and it controls
how information is disseminated, it's controlling how information is
revealed to society, and it's something we need to pay very close
attention to," Marlow says. He points out that his team helps Facebook
understand what it is doing to society and publishes its findings to fulfill a public duty to transparency. Another recent study,
which investigated which types of Facebook activity cause people to
feel a greater sense of support from their friends, falls into the same
category.
But Marlow speaks as an employee of a company that will prosper
largely by catering to advertisers who want to control the flow of
information between its users. And indeed, Bakshy is working with
managers outside the Data Science Team to extract advertising-related
findings from the results of experiments on social influence.
"Advertisers and brands are a part of this network as well, so giving
them some insight into how people are sharing the content they are
producing is a very core part of the business model," says Marlow.
Facebook told prospective investors before its IPO that people
are 50 percent more likely to remember ads on the site if they're
visibly endorsed by a friend. Figuring out how influence works could
make ads even more memorable or help Facebook find ways to induce more
people to share or click on its ads.
Social Engineering
Marlow says his team wants to divine the rules of online social
life to understand what's going on inside Facebook, not to develop ways
to manipulate it. "Our goal is not to change the pattern of
communication in society," he says. "Our goal is to understand it so we
can adapt our platform to give people the experience that they want."
But some of his team's work and the attitudes of Facebook's leaders show
that the company is not above using its platform to tweak users'
behavior. Unlike academic social scientists, Facebook's employees have a
short path from an idea to an experiment on hundreds of millions of
people.
In April, influenced in part by conversations over dinner with his
med-student girlfriend (now his wife), Zuckerberg decided that he
should use social influence within Facebook to increase organ donor
registrations. Users were given an opportunity to click a box on their
Timeline pages to signal that they were registered donors, which
triggered a notification to their friends. The new feature started a
cascade of social pressure, and organ donor enrollment increased by a
factor of 23 across 44 states.
Marlow's team is in the process of publishing results from the
last U.S. midterm election that show another striking example of
Facebook's potential to direct its users' influence on one another.
Since 2008, the company has offered a way for users to signal that they
have voted; Facebook promotes that to their friends with a note to say
that they should be sure to vote, too. Marlow says that in the 2010
election his group matched voter registration logs with the data to see
which of the Facebook users who got nudges actually went to the polls.
(He stresses that the researchers worked with cryptographically
"anonymized" data and could not match specific users with their voting
records.)
This is just the beginning. By learning more about how small changes
on Facebook can alter users' behavior outside the site, the company
eventually "could allow others to make use of Facebook in the same way,"
says Marlow. If the American Heart Association wanted to encourage
healthy eating, for example, it might be able to refer to a playbook of
Facebook social engineering. "We want to be a platform that others can
use to initiate change," he says.
Advertisers, too, would be eager to know in greater detail what
could make a campaign on Facebook affect people's actions in the outside
world, even though they realize there are limits to how firmly human
beings can be steered. "It's not clear to me that social science will
ever be an engineering science in a way that building bridges is," says
Duncan Watts, who works on computational social science at Microsoft's
recently opened New York research lab and previously worked alongside
Marlow at Yahoo's labs. "Nevertheless, if you have enough data, you can
make predictions that are better than simply random guessing, and that's
really lucrative."
Doubling Data
Like other social-Web companies, such as Twitter, Facebook has
never attained the reputation for technical innovation enjoyed by such
Internet pioneers as Google. If Silicon Valley were a high school, the
search company would be the quiet math genius who didn't excel socially
but invented something indispensable. Facebook would be the annoying kid
who started a club with such social momentum that people had to join
whether they wanted to or not. In reality, Facebook employs hordes of
talented software engineers (many poached from Google and other
math-genius companies) to build and maintain its irresistible club. The
technology built to support the Data Science Team's efforts is
particularly innovative. The scale at which Facebook operates has led it
to invent hardware and software that are the envy of other companies
trying to adapt to the world of "big data."
In a kind of passing of the technological baton, Facebook built
its data storage system by expanding the power of open-source software
called Hadoop, which was inspired by work at Google and built at Yahoo.
Hadoop can tame seemingly impossible computational tasks—like working on
all the data Facebook's users have entrusted to it—by spreading them
across many machines inside a data center. But Hadoop wasn't built with
data science in mind, and using it for that purpose requires
specialized, unwieldy programming. Facebook's engineers solved that
problem with the invention of Hive, open-source software that's now
independent of Facebook and used by many other companies. Hive acts as a
translation service, making it possible to query vast Hadoop data
stores using relatively simple code. To cut down on computational
demands, it can request random samples of an entire data set, a feature
that's invaluable for companies swamped by data. Much of Facebook's data
resides in one Hadoop store more than 100 petabytes (a million
gigabytes) in size, says Sameet Agarwal, a director of engineering at
Facebook who works on data infrastructure, and the quantity is growing
exponentially. "Over the last few years we have more than doubled in
size every year," he says. That means his team must constantly build
more efficient systems.
All this has given Facebook a unique level of expertise, says Jeff Hammerbacher,
Marlow's predecessor at Facebook, who initiated the company's effort to
develop its own data storage and analysis technology. (He left Facebook
in 2008 to found Cloudera, which develops Hadoop-based systems to
manage large collections of data.) Most large businesses have paid
established software companies such as Oracle a lot of money for data
analysis and storage. But now, big companies are trying to understand
how Facebook handles its enormous information trove on open-source
systems, says Hammerbacher. "I recently spent the day at Fidelity
helping them understand how the 'data scientist' role at Facebook was
conceived ... and I've had the same discussion at countless other
firms," he says.
As executives in every industry try to exploit the opportunities
in "big data," the intense interest in Facebook's data technology
suggests that its ad business may be just an offshoot of something much
more valuable. The tools and techniques the company has developed to
handle large volumes of information could become a product in their own
right.
Mining for Gold
Facebook needs new sources of income to meet investors'
expectations. Even after its disappointing IPO, it has a staggeringly
high price-to-earnings ratio that can't be justified by the barrage of
cheap ads the site now displays. Facebook's new campus in Menlo Park,
California, previously inhabited by Sun Microsystems, makes that
pressure tangible. The company's 3,500 employees rattle around in enough
space for 6,600. I walked past expanses of empty desks in one building;
another, next door, was completely uninhabited. A vacant lot waited
nearby, presumably until someone invents a use of our data that will
justify the expense of developing the space.
One potential use would be simply to sell insights mined from the information. DJ Patil,
data scientist in residence with the venture capital firm Greylock
Partners and previously leader of LinkedIn's data science team, believes
Facebook could take inspiration from Gil Elbaz, the inventor of
Google's AdSense ad business, which provides over a quarter of Google's
revenue. He has moved on from advertising and now runs a fast-growing
startup, Factual,
that charges businesses to access large, carefully curated collections
of data ranging from restaurant locations to celebrity body-mass
indexes, which the company collects from free public sources and by
buying private data sets. Factual cleans up data and makes the result
available over the Internet as an on-demand knowledge store to be tapped
by software, not humans. Customers use it to fill in the gaps in their
own data and make smarter apps or services; for example, Facebook itself
uses Factual for information about business locations. Patil points out
that Facebook could become a data source in its own right, selling
access to information compiled from the actions of its users. Such
information, he says, could be the basis for almost any kind of
business, such as online dating or charts of popular music. Assuming
Facebook can take this step without upsetting users and regulators, it
could be lucrative. An online store wishing to target its promotions,
for example, could pay to use Facebook as a source of knowledge about
which brands are most popular in which places, or how the popularity of
certain products changes through the year.
Hammerbacher agrees that Facebook could sell its data science and
points to its currently free Insights service for advertisers and
website owners, which shows how their content is being shared on
Facebook. That could become much more useful to businesses if Facebook
added data obtained when its "Like" button tracks activity all over the
Web, or demographic data or information about what people read on the
site. There's precedent for offering such analytics for a fee: at the
end of 2011 Google started charging $150,000 annually for a premium
version of a service that analyzes a business's Web traffic.
Back at Facebook, Marlow isn't the one who makes decisions about
what the company charges for, even if his work will shape them. Whatever
happens, he says, the primary goal of his team is to support the
well-being of the people who provide Facebook with their data, using it
to make the service sm
Of all the noises that my children will not understand, the one that is
nearest to my heart is not from a song or a television show or a jingle.
It's the sound of a modem connecting with another modem across the
repurposed telephone infrastructure. It was the noise of being part of
the beginning of the Internet.
I heard that sound again this week on Brendan Chillcut's simple and wondrous site: The Museum of Endangered Sounds.
It takes technological objects and lets you relive the noises they
made: Tetris, the Windows 95 startup chime, that Nokia ringtone,
television static. The site archives not just the intentional sounds --
ringtones, etc -- but the incidental ones, like the mechanical noise a
VHS tape made when it entered the VCR or the way a portable CD player
sounded when it skipped. If you grew up at a certain time, these sounds
are like technoaural nostalgia whippets. One minute, you're browsing the
Internet in 2012, the next you're on a bus headed up I-5 to an 8th
grade football game against Castle Rock in 1995.
The noises our technologies make, as much as any music, are the soundtrack to an era. Soundscapes
are not static; completely new sets of frequencies arrive, old things
go. Locomotives rumbled their way through the landscapes of 19th century
New England, interrupting Nathaniel Hawthorne-types' reveries in Sleepy
Hollows. A city used to be synonymous with the sound of horse hooves
and the clatter of carriages on the stone streets. Imagine the people
who first heard the clicks of a bike wheel or the vroom of a car engine.
It's no accident that early films featuring industrial work often
include shots of steam whistles, even though in many (say, Metropolis)
we can't hear that whistle.
When I think of 2012, I will think of the overworked fan of my laptop
and the ding of getting a text message on my iPhone. I will think of
the beep of the FastTrak in my car as it debits my credit card so I can
pass through a toll onto the Golden Gate Bridge. I will think of Siri's
uncanny valley voice.
But to me, all of those sounds -- as symbols of the era in which I've
come up -- remain secondary to the hissing and crackling of the modem
handshake. I first heard that sound as a nine-year-old. To this day, I
can't remember how I figured out how to dial the modem of our old
Zenith. Even more mysterious is how I found the BBS number to call or
even knew what a BBS was. But I did. BBS were dial-in communities, kind
of like a local AOL.
You could post messages and play games, even chat with people on the
bigger BBSs. It was personal: sometimes, you'd be the only person
connected to that community. Other times, there'd be one other person,
who was almost definitely within your local prefix.
When we moved to Ridgefield, which sits outside Portland, Oregon, I had a summer with no
friends and no school: The telephone wire became a lifeline. I
discovered Country Computing, a BBS I've eulogized before,
located in a town a few miles from mine. The rural Washington BBS world
was weird and fun, filled with old ham-radio operators and
computer nerds. After my parents' closed up
shop for the work day, their "fax line" became my modem line, and I
called across the I-5 to play games and then, slowly, to participate in
the
nascent community.
In the beginning of those sessions, there was the sound, and the sound was data.
Fascinatingly, there's no good guide to the what the beeps and hisses
represent that I could find on the Internet. For one, few people care
about the technical details of 1997's hottest 56k modems. And for
another, whatever good information exists out there predates the popular
explosion of the web and the all-knowing Google.
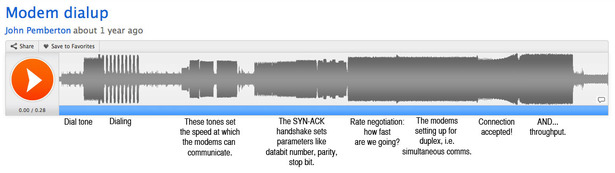
So, I asked on Twitter and was rewarded with an accessible and elegant explanation from another user whose nom-de-plume is Miso Susanowa.
(Susanowa used to run a BBS.) I transformed it into the annotated
graphic below, which explains the modem sound part-by-part. (You can
click it to make it bigger.)
This is a choreographed sequence that allowed these digital devices to
piggyback on an analog telephone network. "A phone line carries only the small range of frequencies in
which most human conversation takes place: about 300 to 3,300 hertz," Glenn Fleishman explained in the Times back in 1998. "The
modem works within these limits in creating sound waves to carry data
across phone lines." What you're hearing is the way 20th century technology tunneled through a 19th century network;
what you're hearing is how a network designed to send the noises made
by your muscles as they pushed around air came to transmit anything, or
the almost-anything that can be coded in 0s and 1s.
The frequencies of the modem's sounds represent
parameters for further communication. In the early going, for example,
the modem that's been dialed up will play a note that says, "I can go
this fast." As a wonderful old 1997 website explained, "Depending on the speed the modem is trying to talk at, this tone will have a
different pitch."
That is to say, the sounds weren't a sign that data was being
transferred: they were the data being transferred. This noise was the
analog world being bridged by the digital. If you are old enough to
remember it, you still knew a world that was analog-first.
Long before I actually had this answer in hand, I could sense that the
patterns of the beats and noise meant something. The sound would move
me, my head nodding to the beeps that followed the initial connection.
You could feel two things trying to come into sync: Were they computers
or me and my version of the world?
As I learned again today, as I learn every day, the answer is both.
Microsoft has let it be known that their final release of the Internet Explorer 10
web browser software will have “Do Not Track” activated right out of
the box. This information has upset advertisers across the board as web
ad targeting – based on your online activities – is one of the current
mainstays of big-time advertiser profits. What Do Not Track, or DNT does
is to send out signal from your web browser, Internet Explorer 10 in
this case, to websites letting them know that the user refuses to be
seen in such a way.
A very similar Do Not Track feature currently exists on Mozilla’s Firefox browser
and is swiftly becoming ubiquitous around the web as a must-have
feature for web privacy. This will very likely bring about a large
change in the world of online advertising specifically as, again,
advertisers rely on invisible tracking methods so heavily. Tracking in
place today also exists on sites such as Google where your search
history will inform Google on what you’d like to see for search results, News posts, and advertisement content.
The Digital Advertising Aliance, or DAA, has countered Microsoft’s
announcement saying that the IE10 browser release would oppose
Microsoft’s agreement with the White House earlier this year. This
agreement had the DAA agreeing to recognize and obey the Do Not Track
signals from IE10 just so long as the option to have DNT activated was
not turned on by default. Microsoft Chief Privacy Officer Brendan Lynch
spoke up this week on the situation this week as well.
“In a world where consumers live a large part of their
lives online, it is critical that we build trust that their personal
information will be treated with respect, and that they will be given a
choice to have their information used for unexpected purposes.
While there is still work to do in agreeing on an industry-wide
definition of DNT, we believe turning on Do Not Track by default in IE10
on Windows 8 is an important step in this process of establishing
privacy by default, putting consumers in control and building trust
online.” – Lynch
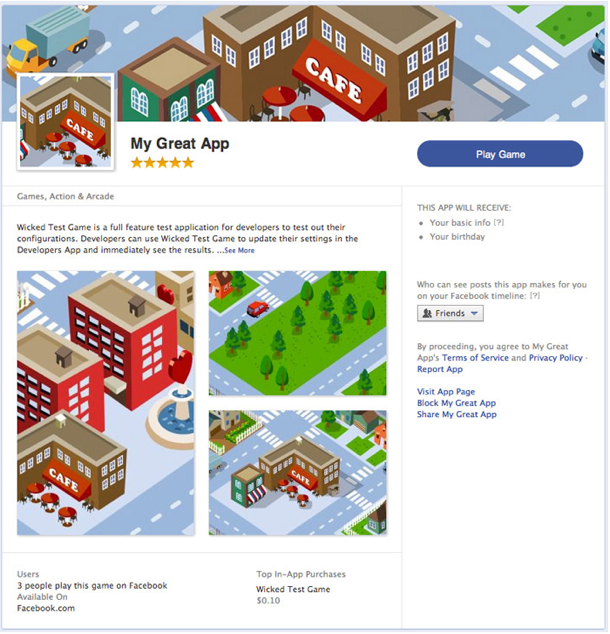
Last September, during the f8 Developers’ Conference, Facebook CTO Bret Taylor said that the company had no plans for a “central app repository” – an app store. Today, Facebook is changing its tune. The social giant has announced App Center,
a section of Facebook dedicated to discovering and deploying
high-quality apps on the company’s platform. The App Center will push
apps to iPhone, Android and the mobile Web, giving Facebook its first
true store for mobile app discovery.
The departure from Facebook’s previous company line
comes as the social platform ramps up its mobile offerings to make money
from its hundreds of millions of mobile users. This is not your
father's app store, though.
Let's start with the requirements. Facebook has announced a strict
set of style and quality guidelines to get apps placed in App
Center. Apps that are considered high-quality, as decided by Facebook’s
Insights analytics platform, will get prominent placement. Quality is
determined by user ratings and app engagement. Apps that receive poor
ratings or do not meet Facebook’s quality guidelines won't be listed.
Whether or not an app is a potential Facebook App Center candidate hinges on several factors. It must
• have a canvas page (a page that sets the app's permissions on Facebook’s platform)
• be built for iOS, Android or the mobile Web
• use a Facebook Login or be a website that uses a Facebook Login.
Facebook is in a tricky spot with App Center. It will house not only
apps that are specifically run through its platform but also iOS and
Android apps. Thus it needs to achieve a balance between competition and
cooperation with some of the most powerful forces in the tech universe.
If an app in App Center requires a download, the download link on the
app’s detail page will bring the user to the appropriate app repository,
either Apple's App Store or Android’s Google Play.
One of the more interesting parts of App Center is that Facebook will
allow paid apps. This is a huge move for Facebook as it provides a
boost to its Credits payment service. One of the benefits of having a
store is that whoever controls the store also controls transactions
arising from the items in it, whether payments per download or in-app
purchases. This will go a long way towards Facebook’s goal of monetizing
its mobile presence without relying on advertising.
Facebook App Center Icon Guidelines
Developers interested in publishing apps to Facebook’s App Center should take a look at both the guidelines and the tutorial
that outlines how to upload the appropriate icons, how to request
permissions, how to use Single Sign On (SSO, a requirement for App
Center) and the app detail page.
This is a good move for Facebook. It will give the company several
avenues to start making money off of mobile but also strengthen its
position as one of the backbones of the Web. For instance, App Center is
both separate from iOS and Android but also a part of it. Through App
Center, Facebook can direct traffic to its apps, monitor who and how
users are downloading applications and keep itself at the center of the
user experience.