How anonymous are you when browsing online? If you're not sure, head
to StayInvisible, where you'll get an immediate online privacy test
revealing what identifiable information is being collected in your
browser.
The site displays the location (via IP address) and
language collected, possible tracking cookies, and other browser
features that could create a unique fingerprint of your browser and session.
If you'd prefer your browsing to be private and anonymous, we have lotsof guidesfor that. Although StayInvisible no longer has the list of proxy tools we mentioned previously, the site is also still useful if you want to test your proxy or VPN server's effectiveness. (Could've come in handy too for a certain CIA director and his biographer.)
Governments around the world made nearly 21,000 requests for access to Google data in the first six months of this year, according to the search engine.
Its Transparency Reportindicates government surveillance of online lives is rising sharply.
The US government made the most demands, asking for details 7,969 times in the first six months of 2012.
Turkey topped the list for requests to remove content.
Government 'bellwether'
Google, in common with other technology and communication companies, regularly receives requests from government agencies and courts around the world to have access to content.
It has been publishing its Transparency Report twice a year since 2009 and has seen a steady rise in government demands for data. In its first report in 2009, it received 12,539 requests. The latest figure stands at 20,939.
"This is the sixth time we've released this
data, and one trend has become clear: government surveillance is on the
rise," Google said in a blog post.
The report acts as a bellwether for government behaviour around the world, a Google spokeswoman told the BBC.
"It reflects laws on the ground. For example in Turkey there
are specific laws about defaming public figures whereas in Germany we
get requests to remove neo-Nazi content," she said.
"And in Brazil we get a lot of requests to remove content
during elections because there is a law banning parodies of candidates.
"We hope that the report will shed light on how governments interact
with online services and how laws are reflected in online behaviour,"
she added.
The US has consistently topped the charts for data requests. France, Germany, Italy, Spain and the UK are also in the top 10.
In France and Germany it complied with fewer than half of all
requests. In the UK it complied with 64% of requests and 90% of
requests from the US.
Removing content
Google said the top three reasons cited by government for content removal were defamation, privacy and security.
Worldwide authorities made 1,789 requests for Google to remove content, up from 1,048 requests for the last six months of 2011.
In the period from January to June, Turkey made 501 requests for content removal.
These included 148 requests related to Mustafa Kemal Ataturk -
the first president of Turkey, the current government, national
identity and values.
Others included claims of pornography, hate speech and copyright.
Google has its own criteria for whether it will remove
content - the request must be specific, relate to a specific web address
and have come from a relevant authority.
In one example from the UK, Google received a request from
police to remove 14 search results that linked to sites allegedly
criticising the police and claiming individuals were involved in
obscuring crimes. It did not remove the content.
Security cameras that watch you, and predict what you'll do next, sound like science fiction. But a team from Carnegie Mellon University says their computerized surveillance software will be capable of "eventually predicting" what you're going to do.
Computerized surveillance can predict what
people will do next -- it's called "activity forecasting" -- and
eventually sound the alarm if the action is not permitted. Click for
larger image.
(Credit:
Carnegie Mellon University)
Computer software programmed to detect and report illicit behavior could
eventually replace the fallible humans who monitor surveillance
cameras.
The U.S. government has funded the development of so-called automatic
video surveillance technology by a pair of Carnegie Mellon University
researchers who disclosed details about their work this week --
including that it has an ultimate goal of predicting what people will do
in the future.
"The main applications are in video surveillance, both civil and military," Alessandro Oltramari, a postdoctoral researcher at Carnegie Mellon who has a Ph.D. from Italy's University of Trento, told CNET yesterday.
Oltramari and fellow researcher Christian Lebiere
say automatic video surveillance can monitor camera feeds for
suspicious activities like someone at an airport or bus station
abandoning a bag for more than a few minutes. "In this specific case,
the goal for our system would have been to detect the anomalous
behavior," Oltramari says.
Think of it as a much, much smarter version of a red light camera: the
unblinking eye of computer software that monitors dozens or even
thousands of security camera feeds could catch illicit activities that
human operators -- who are expensive and can be distracted or sleepy --
would miss. It could also, depending on how it's implemented, raise
similar privacy and civil liberty concerns.
Alessandro Oltramari, left, and Christian
Lebiere say their software will "automatize video-surveillance, both in
military and civil applications."
(Credit:
Carnegie Mellon University)
A paper (PDF)
the researchers presented this week at the Semantic Technology for
Intelligence, Defense, and Security conference outside of Washington,
D.C. -- today's sessions are reserved
only for attendees with top secret clearances -- says their system aims
"to approximate human visual intelligence in making effective and
consistent detections."
Their Army-funded research, Oltramari and Lebiere claim, can go further
than merely recognizing whether any illicit activities are currently
taking place. It will, they say, be capable of "eventually predicting"
what's going to happen next.
This approach relies heavily on advances by machine vision researchers,
who have made remarkable strides in last few decades in recognizing
stationary and moving objects and their properties. It's the same vein
of work that led to Google's self-driving cars, face recognition software used on Facebook and Picasa, and consumer electronics like Microsoft's Kinect.
When it works well, machine vision can detect objects and people -- call
them nouns -- that are on the other side of the camera's lens.
But to figure out what these nouns are doing, or are allowed to do, you
need the computer science equivalent of verbs. And that's where
Oltramari and Lebiere have built on the work of other Carnegie Mellon
researchers to create what they call a "cognitive engine" that can
understand the rules by which nouns and verbs are allowed to interact.
Their cognitive engine incorporates research, called activity
forecasting, conducted by a team led by postdoctoral fellow Kris Kitani,
which tries to understand what humans will do by calculating which
physical trajectories are most likely. They say their software "models
the effect of the physical environment on the choice of human actions."
Both projects are components of Carnegie Mellon's Mind's Eye
architecture, a DARPA-created project that aims to develop smart cameras
for machine-based visual intelligence.
Predicts Oltramari: "This work should support human operators and automatize
video-surveillance, both in military and civil applications."
European data protection regulators have demanded Google change its privacy policy,
though the French-led team did not conclude that the search giant’s
actions amounted to something illegal. The investigation, by the Commission Nationale de l’Informatique
(CNIL), argued that Google’s decision to condense the privacy policies
of over sixty products into a single agreement – and at the same time
increase the amount of inter-service data sharing – could leave users
unclear as to how different types of information (as varied as search
terms, credit card details, or phone numbers) could be used by the
company.
“The Privacy Policy makes no difference in terms of processing
between the innocuous content of search query and the credit card number
or the telephone communications of the user” the CNIL points out, “all
these data can be used equally for all the purposes in the Policy.” That
some web users merely interact passively with Google products, such as
adverts, also comes in for heightened attention, with those users
getting no explanation at all as to how their actions might be tracked
or stored.
“EU Data protection authorities ask Google to provide
clearer and more comprehensive information about the collected data and
purposes of each of its personal data processing operations. For
instance, EU Data protection authorities recommend the implementation of
a presentation with three levels of detail to ensure that information
complies with the requirements laid down in the Directive and does not
degrade the users’ experience. The ergonomics of the Policy could also
be improved with interactive presentations” CNIL
In a letter to Google [pdf
link] – signed by the CNIL and other authorities from across Europe –
the concerns are laid out in full, together with some suggestions as to
how they can be addressed. For instance, the search company could
“develop interactive presentations that allow users to navigate easily
through the content of the policies” and “provide additional and precise
information about data that have a significant impact on users
(location, credit card data, unique device identifiers, telephony,
biometrics).”
Ironically, one of Google’s arguments for initially changing its
policy system was that a single, harmonized agreement would be easier
for users to read through and understand. It also insisted that the
data-sharing aspects were little changed from before.
“The CNIL, all the authorities among the Working Party and data
protection authorities from other regions of the world expect Google to
take effective and public measures to comply quickly and commit itself
to the implementation of these recommendations” the commission
concluded. Google has a 3-4 month period to enact the changes requested,
or it could face the threat of sanctions.
“We have received the report and are reviewing it now” Peter Fleischer, Google’s global privacy counsel, told TechCrunch.
“Our new privacy policy demonstrates our long-standing commitment to
protecting our users’ information and creating great products. We are
confident that our privacy notices respect European law.”
Inter-individual variation in facial shape is one of the most noticeable
phenotypes in humans, and it is clearly under genetic regulation;
however, almost nothing is known about the genetic basis of normal human
facial morphology. We therefore conducted a genome-wide association
study for facial shape phenotypes in multiple discovery and replication
cohorts, considering almost ten thousand individuals of European descent
from several countries. Phenotyping of facial shape features was based
on landmark data obtained from three-dimensional head magnetic resonance
images (MRIs) and two-dimensional portrait images. We identified five
independent genetic loci associated with different facial phenotypes,
suggesting the involvement of five candidate genes—PRDM16, PAX3, TP63, C5orf50, and COL17A1—in
the determination of the human face. Three of them have been implicated
previously in vertebrate craniofacial development and disease, and the
remaining two genes potentially represent novel players in the molecular
networks governing facial development. Our finding at PAX3
influencing the position of the nasion replicates a recent GWAS of
facial features. In addition to the reported GWA findings, we
established links between common DNA variants previously associated with
NSCL/P at 2p21, 8q24, 13q31, and 17q22 and normal facial-shape
variations based on a candidate gene approach. Overall our study implies
that DNA variants in genes essential for craniofacial development
contribute with relatively small effect size to the spectrum of normal
variation in human facial morphology. This observation has important
consequences for future studies aiming to identify more genes involved
in the human facial morphology, as well as for potential applications of
DNA prediction of facial shape such as in future forensic applications.
Introduction
The morphogenesis and
patterning of the face is one of the most complex events in mammalian
embryogenesis. Signaling cascades initiated from both facial and
neighboring tissues mediate transcriptional networks that act to direct
fundamental cellular processes such as migration, proliferation,
differentiation and controlled cell death. The complexity of human
facial development is reflected in the high incidence of congenital
craniofacial anomalies, and almost certainly underlies the vast spectrum
of subtle variation that characterizes facial appearance in the human
population.
Facial appearance has
a strong genetic component; monozygotic (MZ) twins look more similar
than dizygotic (DZ) twins or unrelated individuals. The heritability of
craniofacial morphology is as high as 0.8 in twins and families [1], [2], [3]. Some craniofacial traits, such as facial height and position of the lower jaw, appear to be more heritable than others [1], [2], [3].
The general morphology of craniofacial bones is largely genetically
determined and partly attributable to environmental factors [4]–[11]. Although genes have been mapped for various rare craniofacial syndromes largely inherited in Mendelian form [12],
the genetic basis of normal variation in human facial shape is still
poorly understood. An appreciation of the genetic basis of facial shape
variation has far reaching implications for understanding the etiology
of facial pathologies, the origin of major sensory organ systems, and
even the evolution of vertebrates [13], [14].
In addition, it is feasible to speculate that once the majority of
genetic determinants of facial morphology are understood, predicting
facial appearance from DNA found at a crime scene will become useful as
investigative tool in forensic case work [15]. Some externally visible human characteristics, such as eye color [16]–[18] and hair color [19], can already be inferred from a DNA sample with practically useful accuracies.
In a recent candidate
gene study carried out in two independent European population samples,
we investigated a potential association between risk alleles for
non-syndromic cleft lip with or without cleft palate (NSCL/P) and nose
width and facial width in the normal population [20].
Two NSCL/P associated single nucleotide polymorphisms (SNPs) showed
association with different facial phenotypes in different populations.
However, facial landmarks derived from 3-Dimensional (3D) magnetic
resonance images (MRI) in one population and 2-Dimensional (2D) portrait
images in the other population were not completely comparable, posing a
challenge for combining phenotype data. In the present study, we focus
on the MRI-based approach for capturing facial morphology since previous
facial imaging studies by some of us have demonstrated that MRI-derived
soft tissue landmarks represent a reliable data source [21], [22].
In geometric
morphometrics, there are different ways to deal with the confounders of
position and orientation of the landmark configurations, such as (1)
superimposition [23], [24] that places the landmarks into a consensus reference frame; (2) deformation [25]–[27], where shape differences are described in terms of deformation fields of one object onto another; and (3) linear distances [28], [29],
where Euclidean distances between landmarks instead of their
coordinates are measured. Rationality and efficacy of these approaches
have been reviewed and compared elsewhere [30]–[32].
We briefly compared these methods in the context of our genome-wide
association study (GWAS) (see Methods section) and applied them when
appropriate.
We extracted facial
landmarks from 3D head MRI in 5,388 individuals of European origin from
Netherlands, Australia, and Germany, and used partial Procrustes
superimposition (PS) [24], [30], [33]
to superimpose different sets of facial landmarks onto a consensus 3D
Euclidean space. We derived 48 facial shape features from the
superimposed landmarks and estimated their heritability in 79 MZ and 90
DZ Australian twin pairs. Subsequently, we conducted a series of GWAS
separately for these facial shape dimensions, and attempted to replicate
the identified associations in 568 Canadians of European (French)
ancestry with similar 3D head MRI phenotypes and additionally sought
supporting evidence in further 1,530 individuals from the UK and 2,337
from Australia for whom facial phenotypes were derived from 2D portrait
images.
Wearable computing is all the rage this year as Google pulls back the
curtain on their Glass technology, but some scientists want to take the
idea a stage further. The emerging field of stretchable electronics is
taking advantage of new polymers that allow you to not just wear your
computer but actually become a part of the circuitry. By embedding the
wiring into a stretchable polymer, these cutting edge devices resemble
human skin more than they do circuit boards. And with a whole host of
possible medical uses, that’s kind of the point.
A Cambridge, Massachusetts startup called MC10 is leading the way
in stretchable electronics. So far, their products are fairly simple.
There’s a patch that’s meant to be installed right on the skin like a
temporary tattoo that can sense whether or not the user is hydrated as
well as an inflatable balloon catheter that can measure the electronic
signals of the user’s heartbeat to search for irregularities like
arrythmias. Later this year, they’re launching a mysterious product with
Reebok that’s expected to take advantage of the technology’s ability to
detect not only heartbeat but also respiration, body temperature, blood
oxygenation and so forth.
The joy of stretchable electronics is that the manufacturing process
is not unlike that of regular electronics. Just like with a normal
microchip, gold electrodes and wires are deposited on to thin silicone wafers,
but they’re also embedded in the stretchable polymer substrate. When
everything’s in place, the polymer substrate with embedded circuitry can
be peeled off and later installed on a new surface. The components that
can be added to stretchable surface include sensors, LEDs, transistors,
wireless antennas and solar cells for power.
For now, the technology is still the nascent stages, but scientists
have high hopes. In the future, you could wear a temporary tattoo that
would monitor your vital signs, or doctors might install stretchable
electronics on your organs to keep track of their behavior. Stretchable
electronics could also be integrated into clothing or paired with a
smartphone. Of course, if all else fails, it’ll probably make for some
great children’s toys.
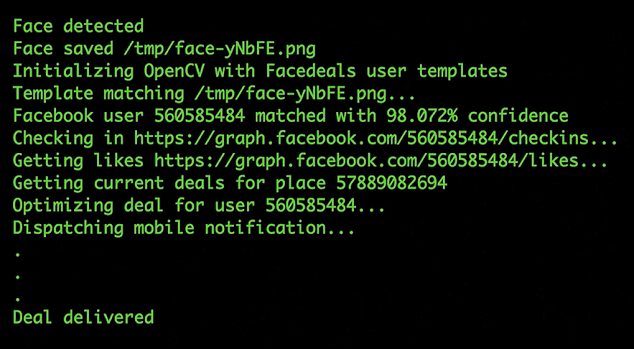
Facedeals - a new
camera that can recognise shoppers from their Facebook pictures as they
enter a shop, and then offer them discounts
A promotional video created to promote the concept shows drinkers
entering a bar, and then being offerend cheap drinks as they are
recognised.
'Facebook
check-ins are a powerful mechanism for businesses to deliver discounts
to loyal customers, yet few businesses—and fewer customers—have realized
it,' said Nashville-based advertising agency Redpepper.
They are already trialling the scheme in firms close to their office.
'A search for businesses with active deals in our area turned up a measly six offers.
'The
odds we’ll ever be at one of those six spots are low (a strip club and
photography studio among them), and the incentives for a check-in are
not nearly enticing enough for us to take the time.
'So we set out to evolve the check-in and sweeten the deal, making both irresistible.
'We call it Facedeals.'
The Facedeal camera can identify faces when
people walk in by comparing Facebook pictures of people who have signed
up to the service
Facebook recently hit the
headlines when it bought face.com, an Israeli firm that pioneered the
use of face recognition technology online.
The social networking giant uses the software to recognise people in uploaded pictures, allowing it to accurately spot friends.
The software uses a complex algorithm to find the correct person from their Facebook pictures
The Facebook camera requires people to have authorised the Facedeals app through their Facebook account.
This verifies your most recent photo tags and maps the biometric data of your face.
The system then learns what a user looks like as more pictures are approved.
This data is then used to identify you in the real world.
In a demonstration video, the firm behind the
camera showed it being used to offer free drinks to customers if they
signed up to the system.
At today’s hearing
of the Subcommittee on Intellectual Property, Competition and the
Internet of the House Judiciary Committee, I referred to an attempt to
“sabotage” the forthcoming Do Not Track standard. My written testimony
discussed a number of other issues as well, but Do Not Track was
clearly on the Representatives’ minds: I received multiple questions on
the subject. Because of the time constraints, oral answers at a
Congressional hearing are not the place for detail, so in this blog
post, I will expand on my answers this morning, and explain why I think
that word is appropriate to describe the current state of play.
Background
For years, advertising networks have offered the option to opt out
from their behavioral profiling. By visiting a special webpage provided
by the network, users can set a browser cookie saying, in effect, “This
user should not be tracked.” This system, while theoretically offering
consumers choice about tracking, suffers from a series of problems that
make it frequently ineffective in practice. For one thing, it relies
on repetitive opt-out: the user needs to visit multiple opt-out pages, a
daunting task given the large and constantly shifting list of
advertising companies, not all of which belong to industry groups with
coordinated opt-out pages. For another, because it relies on
cookies—the same vector used to track users in the first place—it is
surprisingly fragile. A user who deletes cookies to protect her privacy
will also delete the no-tracking cookie, thereby turning tracking back
on. The resulting system is a monkey’s paw: unless you ask for what you want in exactly the right way, you get nothing.
The idea of a Do Not Track header gradually emerged
in 2009 and 2010 as a simpler alternative. Every HTTP request by which
a user’s browser asks a server for a webpage contains a series of headers
with information about the webpage requested and the browser. Do Not
Track would be one more. Thus, the user’s browser would send, as part
of its request, the header:
DNT: 1
The presence of such a header would signal to the website that the
user requests not to be tracked. Privacy advocates and technologists
worked to flesh out the header; privacy officials in the United States
and Europe endorsed it. The World Wide Web Consortium (W3C) formed a
public Tracking Protection Working Group with a charter to design a technical standard for Do Not Track.
Significantly, a W3C standard is not law. The legal effect of Do Not
Track will come from somewhere else. In Europe, it may be enforced directly on websites under existing data protection law. In the United States, legislation has been introduced in the House and Senate
that would have the Federal Trade Commission promulgate Do Not Track
regulations. Without legislative authority, the FTC could not require
use of Do Not Track, but would be able to treat a website’s false claims
to honor Do Not Track as a deceptive trade practice. Since most online
advertising companies find it important from a public relations point
of view to be able to say that they support consumer choice, this last
option may be significant in practice. And finally, in an important recent paper,
Joshua Fairfield argues that use of the Do Not Track header itself
creates an enforceable contract prohibiting tracking under United States
law.
In all of these cases, the details of the Do Not Track standard will
be highly significant. Websites’ legal duties are likely to depend on
the technical duties specified in the standard, or at least be strongly
influenced by them. For example, a company that promises to be Do Not
Track compliant thereby promises to do what is required to comply with
the standard. If the standard ultimately allows for limited forms of
tracking for click-fraud prevention, the company can engage in those
forms of tracking even if the user sets the header. If not, it cannot.
Thus, there is a lot at stake in the Working Group’s discussions.
Internet Explorer and Defaults
On May 31, Microsoft announced that Do Not Track would be on by default
in Internet Explorer 10. This is a valuable feature, regardless of how
you feel about behavioral ad targeting itself. A recurring theme of
the online privacy wars is that unusably complicated privacy interfaces
confuse users in ways that cause them to make mistakes and undercut
their privacy. A default is the ultimate easy-to-use privacy control.
Users who care about what websites know about them do not need to
understand the details to take a simple step to protect themselves.
Using Internet Explorer would suffice by itself to prevent tracking from
a significant number of websites.
This is an important principle. Technology can empower users to
protect their privacy. It is impractical, indeed impossible, for users
to make detailed privacy choices about every last detail of their online
activities. The task of getting your privacy right is profoundly
easier if you have access to good tools to manage the details.
Antivirus companies compete vigorously to manage the details of malware
prevention for users. So too with privacy: we need thriving markets in
tools under the control of users to manage the details.
There is immense value if users can delegate some of their privacy
decisions to software agents. These delegation decisions should be dead
simple wherever possible. I use Ghostery
to block cookies. As tools go, it is incredibly easy to use—but it
still is not easy enough. The choice of browser is a simple choice, one
that every user makes. That choice alone should be enough to count as
an indication of a desire for privacy. Setting Do Not Track by default
is Microsoft’s offer to users. If they dislike the setting, they can
change it, or use a different browser.
The Pushback
Microsoft’s move intersected with a long-simmering discussion on the
Tracking Protection Working Group’s mailing list. The question of Do
Not Track defaults had been one of the first issues the Working Group raised when it launched in September 2011. The draft text that emerged by the spring remains painfully ambiguous on the issue. Indeed, the group’s May 30 teleconference—the
day before Microsoft’s announcement—showed substantial disagreement
about defaults and what a server could do if it believed it was seeing a
default Do Not Track header, rather than one explicitly set by the
user. Antivirus software AVG includes a cookie-blocking tool
that sets the Do Not Track header, which sparked extensive discussion
about plugins, conflicting settings, and explicit consent. And the last
few weeks following Microsoft’s announcement have seen a renewed debate
over defaults.
Many industry participants object to Do Not Track by default.
Technology companies with advertising networks have pushed for a crucial
pair of positions:
User agents (i.e. browsers and apps) that turned on Do Not Track by default would be deemed non-compliant with the standard.
Websites that received a request from a noncompliant user agent would be free to disregard a DNT: 1 header.
This position has been endorsed by representatives the three
companies I mentioned in my testimony today: Yahoo!, Google, and Adobe.
Thus, here is an excerpt from an email to the list by Shane Wiley from Yahoo!:
If you know that an UA is non-compliant, it should be fair to NOT
honor the DNT signal from that non-compliant UA and message this back to
the user in the well-known URI or Response Header.
Here is an excerpt from an email to the list by Ian Fette from Google:
There’s other people in the working group, myself included, who feel that
since you are under no obligation to honor DNT in the first place (it is
voluntary and nothing is binding until you tell the user “Yes, I am
honoring your DNT request”) that you already have an option to reject a
DNT:1 request (for instance, by sending no DNT response headers). The
question in my mind is whether we should provide websites with a mechanism
to provide more information as to why they are rejecting your request, e.g.
“You’re using a user agent that sets a DNT setting by default and thus I
have no idea if this is actually your preference or merely another large
corporation’s preference being presented on your behalf.”
And here is an excerpt from an email to the list by Roy Fielding from Adobe:
The server would say that the non-compliant browser is broken and
thus incapable of transmitting a true signal of the user’s preferences.
Hence, it will ignore DNT from that browser, though it may provide
other means to control its own tracking. The user’s actions are
irrelevant until they choose a browser capable of communicating
correctly or make use of some means other than DNT.
Pause here to understand the practical implications of writing this
position into the standard. If Yahoo! decides that Internet Explorer 10
is noncompliant because it defaults on, then users who picked Internet
Explorer 10 to avoid being tracked … will be tracked. Yahoo! will claim
that it is in compliance with the standard and Internet Explorer 10 is
not. Indeed, there is very little that an Internet Explorer 10 user
could do to avoid being tracked. Because her user agent is now flagged
by Yahoo! as noncompliant, even if she manually sets the header herself,
it will still be ignored.
The Problem
A cynic might observe how effectively this tactic neutralizes the
most serious threat that Do Not Track poses to advertisers: that people
might actually use it. Manual opt-out cookies are tolerable
because almost no one uses them. Even Do Not Track headers that are off
by default are tolerable because very few people will use them.
Microsoft’s and AVG’s decisions raise the possibility that significant
numbers of web users would be removed from tracking. Pleasing user
agent noncompliance is a bit of jujitsu, a way of meeting the threat
where it is strongest. The very thing that would make Internet Explorer
10’s Do Not Track setting widely used would be the very thing to
“justify” ignoring it.
But once websites have an excuse to look beyond the header they
receive, Do Not Track is dead as a practical matter. A DNT:1 header is
binary: it is present or it is not. But second-guessing interface
decisions is a completely open-ended question. Was the check box to
enable Do Not Track worded clearly? Was it bundled with some other user
preference? Might the header have been set by a corporate network
rather than the user? These are the kind of process questions that can
be lawyered to death. Being able to question whether a user really meant her Do Not Track header is a license to ignore what she does mean.
Return to my point above about tools. I run a browser with multiple
plugins. At the end of the day, these pieces of software collaborate to
set a Do Not Track header, or not. This setting is under my control: I
can install or uninstall any of the software that was responsible for
it. The choice of header is strictly between me and my user agent. As far as the Do Not Track specification is concerned,
websites should adhere to a presumption of user competence: whatever
value the header has, it has with the tacit or explicit consent of the
user.
Websites are not helpless against misconfigured software. If they
really think the user has lost control over her own computer, they have a
straightforward, simple way of finding out. A website can display a
popup window or an overlay, asking the user whether she really wants to
enable Do Not Track, and explaining the benefits disabling it would
offer. Websites have every opportunity to press their case for
tracking; if that case is as persuasive as they claim, they should have
no fear of making it one-on-one to users.
This brings me to the bitterest irony of Do Not Track defaults. For
more than a decade, the online advertising industry has insisted that
notice and an opportunity to opt out is sufficient choice for consumers.
It has fought long and hard against any kind of heightened consent
requirement for any of its practices. Opt-out, in short, is good
enough. But for Do Not Track, there and there alone, consumers
allegedly do not understand the issues, so consent must be explicit—and opt-in only.
Now What?
It is time for the participants in the Tracking Protection Working
Group to take a long, hard look at where the process is going. It is
time for the rest of us to tell them, loudly, that the process is going
awry. It is true that Do Not Track, at least in the present regulatory
environment, is voluntary. But it does not follow that the standard
should allow “compliant” websites to pick and choose which pieces to
comply with. The job of the standard is to spell out how a user agent
states a Do Not Track request, and what behavior is required of websites
that choose to implement the standard when they receive such a request.
That is, the standard must be based around a simple principle:
A Do Not Track header expresses a meaning, not a process.
The meaning of “DNT: 1” is that the receiving website should not
track the user, as spelled out in the rest of the standard. It is not
the website’s concern how the header came to be set.
Microsoft has let it be known that their final release of the Internet Explorer 10
web browser software will have “Do Not Track” activated right out of
the box. This information has upset advertisers across the board as web
ad targeting – based on your online activities – is one of the current
mainstays of big-time advertiser profits. What Do Not Track, or DNT does
is to send out signal from your web browser, Internet Explorer 10 in
this case, to websites letting them know that the user refuses to be
seen in such a way.
A very similar Do Not Track feature currently exists on Mozilla’s Firefox browser
and is swiftly becoming ubiquitous around the web as a must-have
feature for web privacy. This will very likely bring about a large
change in the world of online advertising specifically as, again,
advertisers rely on invisible tracking methods so heavily. Tracking in
place today also exists on sites such as Google where your search
history will inform Google on what you’d like to see for search results, News posts, and advertisement content.
The Digital Advertising Aliance, or DAA, has countered Microsoft’s
announcement saying that the IE10 browser release would oppose
Microsoft’s agreement with the White House earlier this year. This
agreement had the DAA agreeing to recognize and obey the Do Not Track
signals from IE10 just so long as the option to have DNT activated was
not turned on by default. Microsoft Chief Privacy Officer Brendan Lynch
spoke up this week on the situation this week as well.
“In a world where consumers live a large part of their
lives online, it is critical that we build trust that their personal
information will be treated with respect, and that they will be given a
choice to have their information used for unexpected purposes.
While there is still work to do in agreeing on an industry-wide
definition of DNT, we believe turning on Do Not Track by default in IE10
on Windows 8 is an important step in this process of establishing
privacy by default, putting consumers in control and building trust
online.” – Lynch
In a privacy policy shift,
Google announced today that it will begin tracking users universally
across all its services—Gmail, Search, YouTube and more—and sharing data
on user activity across all of them. So much for the Google we signed
up for.
The change was announced in a blog post today,
and will go into effect March 1. After that, if you are signed into
your Google Account to use any service at all, the company can use that
information on other services as well. As Google puts it:
Our new Privacy Policy makes clear that, if you're signed in, we may
combine information you've provided from one service with information
from other services. In short, we'll treat you as a single user across
all our products, which will mean a simpler, more intuitive Google
experience.
This has been long coming. Google's privacy policies have been
shifting towards sharing data across services, and away from data
compartmentalization for some time. It's been consistently
de-anonymizing you, initially requiring real names with Plus, for
example, and then tying your Plus account to your Gmail account. But
this is an entirely new level of sharing. And given all of the negative
feedback that it had with Google+ privacy issues, it's especially
troubling that it would take actions that further erode users' privacy.
What this means for you is that data from the things you search for,
the emails you send, the places you look up on Google Maps, the videos
you watch in YouTube, the discussions you have on Google+ will all be
collected in one place. It seems like it will particularly affect
Android users, whose real-time location (if they are Latitude users),
Google Wallet data and much more will be up for grabs. And if you have
signed up for Google+, odds are the company even knows your real name,
as it still places hurdles in front of using a pseudonym (although it no longer explicitly requires users to go by their real names).
All of that data history will now be explicitly cross-referenced.
Although it refers to providing users a better experience (read: more
highly tailored results), presumably it is so that Google can deliver
more highly targeted ads. (There has, incidentally, never been a better
time to familiarize yourself with Google's Ad Preferences.)
So why are we calling this evil? Because Google changed the rules
that it defined itself. Google built its reputation, and its
multi-billion dollar business, on the promise of its "don't be evil"
philosophy. That's been largely interpreted as meaning that Google will
always put its users first, an interpretation that Google has cultivated
and encouraged. Google has built a very lucrative company on the
reputation of user respect. It has made billions of dollars in that
effort to get us all under its feel-good tent. And now it's pulling the
stakes out, collapsing it. It gives you a few weeks to pull your data
out, using its data-liberation service, but if you want to use Google
services, you have to agree to these rules.
Google's philosophy speaks directly to making money without doing evil. And it is very explicit in calling out advertising in the section on "evil."
But while it emphasizes that ads should be relevant, obvious, and "not
flashy," what seems to have been forgotten is a respect for its users
privacy, and established practices.
People have different privacy concerns and needs. To best serve the
full range of our users, Google strives to offer them meaningful and
fine-grained choices over the use of their personal information. We
believe personal information should not be held hostage and we are
committed to building products that let users export their personal
information to other services. We don‘t sell users' personal
information.
This crosses that line. It eliminates that fine-grained control, and
means that things you could do in relative anonymity today, will be
explicitly associated with your name, your face, your phone number come
March 1st. If you use Google's services, you have to agree to this new
privacy policy. Yet a real concern for various privacy concerns would
recognize that I might not want Google associating two pieces of
personal information.
And much worse, it is an explicit reversal of its previous policies. As Google noted in 2009:
Previously, we only offered Personalized Search for signed-in users,
and only when they had Web History enabled on their Google Accounts.
What we're doing today is expanding Personalized Search so that we can
provide it to signed-out users as well. This addition enables us to
customize search results for you based upon 180 days of search activity
linked to an anonymous cookie in your browser. It's completely separate
from your Google Account and Web History (which are only available to
signed-in users). You'll know when we customize results because a "View
customizations" link will appear on the top right of the search results
page. Clicking the link will let you see how we've customized your
results and also let you turn off this type of customization.