Google is attempting to shunt users away from old browsers by
intentionally serving up a stale version of the ad giant's search
homepage to those holdouts.
The tactic appears to be falling in line with Mountain View's policy on its other Google properties, such as Gmail, which the company declines to fully support on aged browsers.
However, it was claimed on Friday in a Google discussion thread
that the multinational had unceremoniously dumped a past its
sell-by-date version of the Larry Page-run firm's search homepage on
those users who have declined to upgrade their Opera and Safari
browsers.
A user with the moniker DJSigma wrote on the forum:
A few minutes ago, Google's homepage reverted to the old version for
me. I'm using Opera 12.17. If I search for something, the results are
shown with the current Google look, but the homepage itself is the old
look with the black bar across the top. It seems to affect only the
Google homepage and image search. If I click on "News", for instance,
it's fine.
I've tried clearing cookies and deleting the browser cache/persistent
storage. I've tried disabling all extensions. I've tried masking the
browser as IE and Firefox. It doesn't matter whether I'm signed in or
signed out. Nothing works. Please fix this!
In a later post, DJSigma added that there seemed to be a glitch on Google search.
If I go to the Google homepage, I get served the old version of the
site. If I search for something, the results show up in the current
look. However, if I then try and type something into the search box
again, Google search doesn't work at all. I have to go back to the
homepage every time to do a new search.
The Opera user then said that the problem appeared to be
"intermittent". Others flagged up similar issues on the Google forum
and said they hoped it was just a bug.
While someone going by the name MadFranko008 added:
Phew ... thought it was just me and I'd been hacked or something ...
Same problem here everything "Google" has reverted back to the old style
of several years ago.
Tested on 3 different computers and different OS's & browsers ...
All have the same result, everything google has gone back to the old
style of several years ago and there's no way to change it ... Even the
copyright has reverted back to 2013!!!
Some Safari 5.1.x and Opera 12.x netizens were able to
fudge the system by customising their browser's user agent. But others
continued to complain about Google's "clunky", old search homepage.
A
Google employee, meanwhile, said that the tactic was deliberate in a
move to flush out stick-in-the-mud types who insisted on using older
versions of browsers.
"Thanks for the reports. I want to assure
you this isn't a bug, it's working as intended," said a Google worker
going by the name nealem. She added:
We’re continually making improvements to Search, so we can only
provide limited support for some outdated browsers. We encourage
everyone to make the free upgrade to modern browsers - they’re more
secure and provide a better web experience overall.
In a separate thread, as spotted by a Reg
reader who brought this sorry affair to our attention, user
MadFranko008 was able to show that even modern browsers - including the
current version of Chrome - were apparently spitting out glitches on
Apple Mac computers.
Google then appeared to have resolved the search "bug" spotted in Chrome.
To translate one language into another, find the linear
transformation that maps one to the other. Simple, say a team of Google
engineers
Computer
science is changing the nature of the translation of words and
sentences from one language to another. Anybody who has tried BabelFish or Google Translate will know that they provide useful translation services but ones that are far from perfect.
The
basic idea is to compare a corpus of words in one language with the
same corpus of words translated into another. Words and phrases that
share similar statistical properties are considered equivalent.
The
problem, of course, is that the initial translations rely on
dictionaries that have to be compiled by human experts and this takes
significant time and effort.
Now Tomas Mikolov and a couple of
pals at Google in Mountain View have developed a technique that
automatically generates dictionaries and phrase tables that convert one
language into another.
The new technique does not rely on versions
of the same document in different languages. Instead, it uses data
mining techniques to model the structure of a single language and then
compares this to the structure of another language.
“This method
makes little assumption about the languages, so it can be used to extend
and refine dictionaries and translation tables for any language pairs,”
they say.
The new approach is relatively straightforward. It
relies on the notion that every language must describe a similar set of
ideas, so the words that do this must also be similar. For example, most
languages will have words for common animals such as cat, dog, cow and
so on. And these words are probably used in the same way in sentences
such as “a cat is an animal that is smaller than a dog.”
The same
is true of numbers. The image above shows the vector representations of
the numbers one to five in English and Spanish and demonstrates how
similar they are.
This is an important clue. The new trick is to represent an entire language using the relationship between its words. The
set of all the relationships, the so-called “language space”, can be
thought of as a set of vectors that each point from one word to another.
And in recent years, linguists have discovered that it is possible to
handle these vectors mathematically. For example, the operation ‘king’ –
‘man’ + ‘woman’ results in a vector that is similar to ‘queen’.
It
turns out that different languages share many similarities in this
vector space. That means the process of converting one language into
another is equivalent to finding the transformation that converts one
vector space into the other.
This turns the problem of translation
from one of linguistics into one of mathematics. So the problem for the
Google team is to find a way of accurately mapping one vector space
onto the other. For this they use a small bilingual dictionary compiled
by human experts–comparing same corpus of words in two different
languages gives them a ready-made linear transformation that does the
trick.
Having identified this mapping, it is then a simple matter
to apply it to the bigger language spaces. Mikolov and co say it works
remarkably well. “Despite its simplicity, our method is surprisingly
effective: we can achieve almost 90% precision@5 for translation of
words between English and Spanish,” they say.
The method can be
used to extend and refine existing dictionaries, and even to spot
mistakes in them. Indeed, the Google team do exactly that with an
English-Czech dictionary, finding numerous mistakes.
Finally, the
team point out that since the technique makes few assumptions about the
languages themselves, it can be used on argots that are entirely
unrelated. So while Spanish and English have a common Indo-European
history, Mikolov and co show that the new technique also works just as
well for pairs of languages that are less closely related, such as
English and Vietnamese.
That’s a useful step forward for the
future of multilingual communication. But the team says this is just the
beginning. “Clearly, there is still much to be explored,” they
conclude.
Ref: arxiv.org/abs/1309.4168: Exploiting Similarities among Languages for Machine Translation
Want to see CERN's Geneva lab, where the Large Hadron Collider (LHC) is installed, from the inside? You're in luck, cause Google has added Street View imagery from inside CERN's facilities to its Google Maps service.
The imagery shows CERN's laboratories, control centers and
underground tunnels. Highlights include the Large Hadron Collider, the
7000-ton ATLAS detector, and ALICE, a heavy-ion detector on the LHC
ring.
To capture the images, Google's Street View team worked with CERN for
two weeks in 2011. Google has been on fire lately when it comes to
Street View. A few weeks ago, the service launched a 360-degree tour of
Galápagos Islands; two days before that, the Moto X manufacturing facility was added to Street View, and in August, Google added some of the world's best zoos to Street View.
Check out the imagery here and tell us what you think in the comments.
Google faces financial sanctions in France after failing to comply
with an order to alter how it stores and shares user data to conform to
the nation's privacy laws.
The enforcement follows an analysis led by European data protection
authorities of a new privacy policy that Google enacted in 2012,
France's privacy watchdog, the Commission Nationale de L'Informatique et des Libertes, said Friday on its website.
Google was ordered in June by the CNIL to comply with French data
protection laws within three months. But Google had not changed its
policies to comply with French laws by a deadline on Friday, because the
company said that France's data protection laws did not apply to users
of certain Google services in France, the CNIL said.
The company "has not implemented the requested changes," the CNIL said.
As a result, "the chair of the CNIL will now designate a rapporteur
for the purpose of initiating a formal procedure for imposing sanctions,
according to the provisions laid down in the French data protection
law," the watchdog said. Google could be fined a maximum of €150,000
($202,562), or €300,000 for a second offense, and could in some
circumstances be ordered to refrain from processing personal data in
certain ways for three months.
What bothers France
The CNIL took issue with several areas of Google's data policies, in
particular how the company stores and uses people's data. How Google
informs users about data that it processes and obtains consent from
users before storing tracking cookies were cited as areas of concern by
the CNIL.
In a statement, Google said that its privacy policy respects European
law. "We have engaged fully with the CNIL throughout this process, and
we'll continue to do so going forward," a spokeswoman said.
Google is also embroiled with European authorities in an antitrust
case for allegedly breaking competition rules. The company recently
submitted proposals to avoid fines in that case.
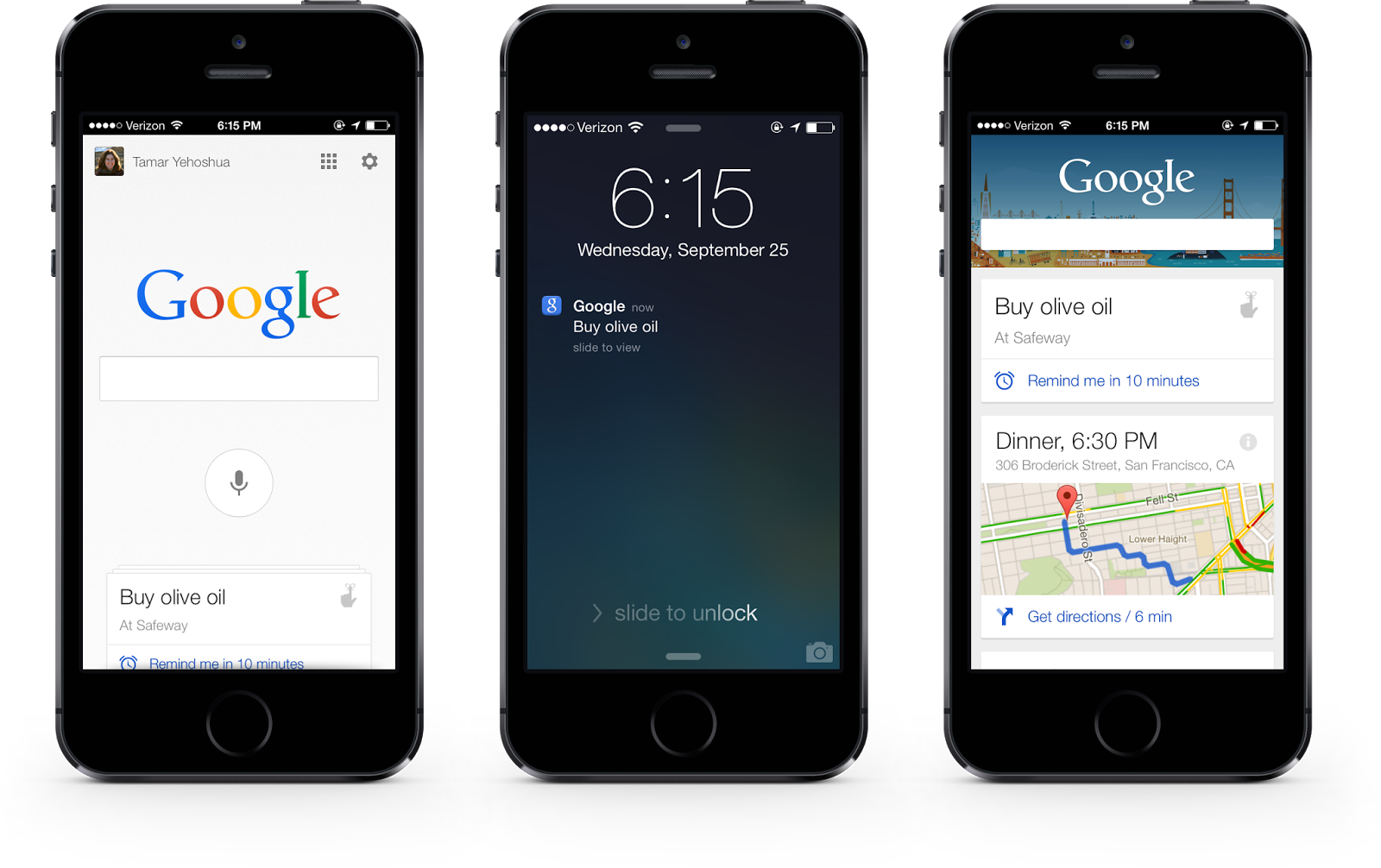
Google is turning 15 tomorrow and, fittingly, it’s celebrating the occasion
by announcing a couple of new features for Google Search. The mobile
search interface, for example, is about to get a bit of a redesign with
results that are clustered on cards “so you can focus on the answers
you’re looking for.”
Those
answers, Google today announced, are also getting better. Thanks to its
Knowledge Graph, the company continues to push to give users answers
instead of just links, and with today’s update, it’s now featuring the
ability to use the Knowledge Graph to compare things. If you want to
compare the nutritional value of olive oil to butter, for example,
Google Search will now give you a comparison chart with lots of details.
The same holds true for other things, including dog breed and celestial
objects. Google says it plans to expand this feature to more things
over time.
Also new in this update is the ability to use Knowledge Graph to
filter results. Say you ask Google: “Tell me about Impressionist
artists.” Now, you’ll see who these artists are, and a new bar on top of
the results will allow you dive in to learn more about them and to
switch to learn more about abstract art, for example.
On mobile, Google is now making it easier to use your voice to set
reminders and have those synced between devices. So you can say “Ok
Google, Remind me to buy butter at Safeway” on your Nexus tablet and
when you walk into the store with your iPhone, you’ll get that reminder.
To enable this, Google will roll out a new version of its Search app
for iPhone and iPad in the next few weeks.
With regard to notifications, it’s also worth noting that Google is now adding Google Now push notifications to its iPhone app, which will finally make Google Now useful on Apple’s platform.
We’ve been hearing a lot about Google‘s
self-driving car lately, and we’re all probably wanting to know how
exactly the search giant is able to construct such a thing and drive
itself without hitting anything or anyone. A new photo has surfaced that
demonstrates what Google’s self-driving vehicles see while they’re out
on the town, and it looks rather frightening.
The image was tweeted
by Idealab founder Bill Gross, along with a claim that the self-driving
car collects almost 1GB of data every second (yes, every second). This
data includes imagery of the cars surroundings in order to effectively
and safely navigate roads. The image shows that the car sees its
surroundings through an infrared-like camera sensor, and it even can
pick out people walking on the sidewalk.
Of course, 1GB of data every second isn’t too surprising when you
consider that the car has to get a 360-degree image of its surroundings
at all times. The image we see above even distinguishes different
objects by color and shape. For instance, pedestrians are in bright
green, cars are shaped like boxes, and the road is in dark blue.
However, we’re not sure where this photo came from, so it could
simply be a rendering of someone’s idea of what Google’s self-driving
car sees. Either way, Google says that we could see self-driving cars
make their way to public roads in the next five years or so, which actually isn’t that far off, and Tesla Motors CEO Elon Musk is even interested in developing self-driving cars as well. However, they certainly don’t come without their problems, and we’re guessing that the first batch of self-driving cars probably won’t be in 100% tip-top shape.
Over the eons I've been a fan of, and sucker for, each latest automated system to "simplify" and "bring order to" my life. Very early on this led me to the beautiful-and-doomed Lotus Agenda for my DOS computers, and Actioneer for the early Palm. For the last few years Evernote has been my favorite, and I really like it. Still I always have the roving eye.
So naturally I have already downloaded the Android version of Google's new app
for collecting notes, photos, and info, called Google Keep, with logo
at right. This early version has nothing like Evernote's power or
polish, but you can see where Google is headed.
Here's the problem: Google now has a
clear enough track record of trying out, and then canceling,
"interesting" new software that I have no idea how long Keep will be
around. When Google launched its Google Health service five years ago,
it had an allure like Keep's: here was the one place you could store
your prescription info, test results, immunization records, and so on
and know that you could get at them as time went on. That's how I used
it -- until Google cancelled this "experiment" last year. Same with
Google Reader, and all the other products in the Google Graveyard that Slate produced last week.
After Reader's demise, many people noted
the danger of ever relying on a company's free offerings. When a
company is charging money for a product -- as Evernote does for all
above its most basic service, and same for Dropbox and SugarSync -- you
understand its incentive for sticking with that product. The company
itself might fail, but as long as it's in business it's unlikely just to
get bored and walk away, as Google has from so many experiments. These
include one called Google Notebook, which had some similarities to Keep,
and which I also liked, and which Google abandoned recently.
So: I trust Google for search, the core of how it stays in business. Similarly for Maps and Earth, which have tremendous public-good side effects but also are integral to Google's business. Plus Gmail and Drive, which keep you in the Google ecosystem. But do I trust Google with Keep? No.
The idea looks promising, and you can see how it could end up as an
integral part of the Google Drive strategy. But you could also imagine
that two or three years from now this will be one more "interesting"
experiment Google has gotten tired of.
Until I know a reason that it's in Google's long-term interest to keep Keep going, I'm
not going to invest time in it or lodge info there. The info could of
course be extracted or ported somewhere else -- Google has been very
good about helping people rescue data from products it has killed -- but
why bother getting used to a system that might go away? And I don't
understand how Google can get anyone to rely on its experimental
products unless it has a convincing answer for the "how do we know you
won't kill this?" question.
At SXSW this afternoon, Google provided developers with a first
glance at the Google Glass Mirror API, the main interface between Google
Glass, Google’s servers and the apps that developers will write for
them. In addition, Google showed off a first round of applications that
work on Glass, including how Gmail works on the device, as well as
integrations from companies like the New York Times, Evernote, Path and
others.
The Mirror API is essentially a REST API,
which should make developing for it very easy for most developers. The
Glass device essentially talks to Google’s servers and the developers’
applications then get the data from there and also push it to Glass
through Google’s APIs. All of this data is then presented on Glass
through what Google calls “timeline cards.” These cards can include
text, images, rich HTML and video. Besides single cards, Google also
lets developers use what it calls bundles, which are basically sets of
cards that users can navigate using their voice or the touchpad on the
side of Glass.
It looks like sharing to Google+ is a built-in feature of the Mirror
API, but as Google’s Timothy Jordan noted in today’s presentation,
developers can always add their own sharing options, as well. Other
built-in features seem to include voice recognition, access to the
camera and a text-to-speech engine.
Glass Rules
Because Glass is a new and unique form factor, Jordan also noted,
Google is setting a few rules for Glass apps. They shouldn’t, for
example, show full news stories but only headlines, as everything else
would be too distracting. For longer stories, developers can always just
use Glass to read text to users.
Essentially, developers should make sure that they don’t annoy users
with too many notifications, and the data they send to Glass should
always be relevant. Developers should also make sure that everything
that happens on Glass should be something the user expects, said Jordan.
Glass isn’t the kind of device, he said, where a push notification
about an update to your app makes sense.
Using Glass With Gmail, Evernote, Path and Others
As
part of today’s presentation, Jordan also detailed some Glass apps
Google has been working on itself, and apps that some of its partners
have created. The New York Times app, for example, shows headlines and
then lets you listen to a summary of the article by telling Glass to
“read aloud.” Google’s own Gmail app uses voice recognition to answer
emails (and it obviously shows you incoming mail, as well). Evernote’s
Skitch can be used to take and share photos, and Jordan also showed a
demo of social network Path running on Glass to share your location.
So far, there is no additional information about the Mirror API on
any of Google’s usual sites, but we expect the company to release more
information shortly and will update this post once we hear more.
Google will be conducting a 45-day public trial
with the FCC to create a centralized database containing information on
free spectrum. The Google Spectrum Database will analyze TV white
spaces, which are unused spectrum between TV stations, that can open
many doors for possible wireless spectrum expansion in the future. By
unlocking these white spaces, wireless providers will be able to provide
more coverage in places that need it.
The public trial brings Google
one step closer to becoming a certified database administrator for
white spaces. Currently the only database administrators are Spectrum
Bridge, Inc. and Telcordia Technologies, Inc. Many other companies are
applying to be certified, including a big dog like Microsoft. With companies like Google and Microsoft becoming certified, discovery of white spaces should increase monumentally.
Google’s trial allows all industry stakeholders, including
broadcasters, cable, wireless microphone users, and licensed spectrum
holders, to provide feedback to the Google Spectrum Database. It also
allows anyone to track how much TV white space is available in their
given area. This entire process is known as dynamic spectrum sharing.
Google’s trial, as well as the collective help of all the other
spectrum data administrators, will help unlock more wireless spectrum.
It’s a necessity as there is an increasing number of people who are
wirelessly connecting to the internet via smartphones, laptops, tablets,
and other wireless devices. This trial will open new doors to more
wireless coverage (especially in dead zones), Wi-Fi hotspots, and other
“wireless technologies”.