Entries tagged as software
Thursday, July 12. 2012
Via Wired
-----
He called himself “MSP,” and he appeared out of nowhere, launching a
one-man flame war against a sacred cow of hardcore computing: the
command line.
The venue was TuxRadar, a news and reviews site that shines a
spotlight on the Linux operating system and other open source software.
The site had just published a piece
in praise of the command line — where you interact with a computer by
passing it line after line of text, rather than using a graphical user
interface, or GUI. “The command line isn’t a crusty, old-fashioned way
to interact with a computer, made obsolete by GUIs, but rather a
fantastically flexible and powerful way to perform tasks,” the site
said.
Then MSP appeared with his flame thrower. “There seem to be a number
of obvious errors in the introduction to this article,” he wrote. “The
command line is a crusty, old-fashioned way to interact with a computer,
made obsolete by GUIs, but a small hardcore of people who refuse to
move on still use it.”
As he likely expected, the Linux-happy commenters at TuxRadar didn’t
take kindly to his “corrections.” Dozens vehemently defended the command
line, insisting it still has a very important place in the world of
computing. And they’re right. Though the average computer user has no
need for a command line, it’s still an essential tool for developers and
system adminstrators who require access to guts of our machines — and
it’s not going away anytime soon.
“People drive cars with steering wheels and gas pedals. Does that
mean you don’t need wrenches?” says Rob Pike, who was part of the team
at Bell Labs that developed the UNIX operating system and now works at
Google, where he oversaw the creation of the Go programming language.
Back in ’70s and early ’80s, if you used a computer, you used a
command line. DOS — the disk operating system that runs atop IBM PCs —
used a command line interface, and that’s what UNIX used too. But then
came the Apple Macintosh and Microsoft Windows, and by the mid-’90s,
most of us had moved to GUIs. The GUI is more effective when you’re
navigating an operating system you’re not exactly familiar with, but
also when you’re typing large amounts of text. Your word processor, for
instance, uses a WYSIWYG, or what-you-see-is-what-you-get graphical
interface.
“Try creating a complex document in a mark-up language using a text
editor,” writes one commenter on TuxRadar. “It can be done, but
generally using a graphical WYSIWYG interface is a far faster and
accurate approach.”
GUIs have even reinvented the world of software development,
beginning with tools like Visual Basic, before extending coding tasks to
the average joe with new-age tools such as Scratch and Google’s App Inventor.
But among hardcore computer types — i.e., the audience reading
TuxRadar — the command line persists. If you’re a developer or a
sysadmin, there are times when it makes more sense to use the command
line interface, or “shell,” built into operating systems like Linux and
UNIX. “It depends on what you’re doing,” Pike tells Wired. “All
computing, at some level, is abstraction and yet deep down beneath there
are hardware instructions doing the job. It depends on the level you’re
working at.”
In some cases, command line interfaces provide access to lower levels
of a machine’s software and hardware. And they’re often easier to
manipulate with “scripts,” mini text programs that automate processes
for system adminstrators and others.
“Anyone insisting the command line is a relic of a by-gone time is
hopelessly deluded,” argues another commenter in the Tuxradar debate. “I
have a very nice [desktop] set up at home, with lots of graphical
applications, but I just find it quicker to write scripts and use the
shell than to hunt through menus to find what I want.”
But in other cases, geeks like command lines just because you have to
know what you’re doing to use it. You have to know the commands. You
can’t hunt and peck like you do with a GUI.
Pike calls the kerfuffle sparked by MSP a “sterile debate.” But MSP
insists that the command line should disappear. The problem, he writes,
is that GUIs just aren’t as effective as they should be. “When people
using a particular system say ‘the command line is better because it can
do things you can’t do in the GUI’ they are not talking about the
strengths of the command line interface, but about the shortcomings in
the GUI,” he says.
OK. Fine. But until the GUI evolves again, the command is here to stay.
Friday, June 29. 2012
Via DVICE
-----
The techno-wizards over at Google X, the company's R&D laboratory working on its self-driving cars and Project Glass,
linked 16,000 processors together to form a neural network and then had
it go forth and try to learn on its own. Turns out, massive digital
networks are a lot like bored humans poking at iPads.
The pretty amazing takeaway here is that this 16,000-processor neural
network, spread out over 1,000 linked computers, was not told to look
for any one thing, but instead discovered that a pattern revolved around cat pictures on its own.
This happened after Google presented the network with image stills
from 10 million random YouTube videos. The images were small thumbnails,
and Google's network was sorting through them to try and learn
something about them. What it found — and we have ourselves to blame for
this — was that there were a hell of a lot of cat faces.
"We never told it during the training, 'This is a cat,'" Jeff Dean, a Google fellow working on the project, told the New York Times. "It basically invented the concept of a cat. We probably have other ones that are side views of cats."
The network itself does not know what a cat is like you and I do. (It
wouldn't, for instance, feel embarrassed being caught watching
something like this
in the presence of other neural networks.) What it does realize,
however, is that there is something that it can recognize as being the
same thing, and if we gave it the word, it would very well refer to it
as "cat."
So, what's the big deal? Your computer at home is more than powerful
enough to sort images. Where Google's neural network differs is that it
looked at these 10 million images, recognized a pattern of cat faces,
and then grafted together the idea that it was looking at something
specific and distinct. It had a digital thought.
Andrew Ng, a computer scientist at Stanford University who is
co-leading the study with Dean, spoke to the benefit of something like a
self-teaching neural network: "The idea is that instead of having teams
of researchers trying to find out how to find edges, you instead throw a
ton of data at the algorithm and you let the data speak and have the
software automatically learn from the data." The size of the network is
important, too, and the human brain is "a million times larger in terms
of the number of neurons and synapses" than Google X's simulated mind,
according to the researchers.
"It'd be fantastic if it turns out that all we need to do is take
current algorithms and run them bigger," Ng added, "but my gut feeling
is that we still don't quite have the right algorithm yet."
The full article&videos @The New York Times
Thursday, June 28. 2012
Via The Laboratorium
By James Grimmelmann
Professor of Law
-----
At today’s hearing
of the Subcommittee on Intellectual Property, Competition and the
Internet of the House Judiciary Committee, I referred to an attempt to
“sabotage” the forthcoming Do Not Track standard. My written testimony
discussed a number of other issues as well, but Do Not Track was
clearly on the Representatives’ minds: I received multiple questions on
the subject. Because of the time constraints, oral answers at a
Congressional hearing are not the place for detail, so in this blog
post, I will expand on my answers this morning, and explain why I think
that word is appropriate to describe the current state of play.
Background
For years, advertising networks have offered the option to opt out
from their behavioral profiling. By visiting a special webpage provided
by the network, users can set a browser cookie saying, in effect, “This
user should not be tracked.” This system, while theoretically offering
consumers choice about tracking, suffers from a series of problems that
make it frequently ineffective in practice. For one thing, it relies
on repetitive opt-out: the user needs to visit multiple opt-out pages, a
daunting task given the large and constantly shifting list of
advertising companies, not all of which belong to industry groups with
coordinated opt-out pages. For another, because it relies on
cookies—the same vector used to track users in the first place—it is
surprisingly fragile. A user who deletes cookies to protect her privacy
will also delete the no-tracking cookie, thereby turning tracking back
on. The resulting system is a monkey’s paw: unless you ask for what you want in exactly the right way, you get nothing.
The idea of a Do Not Track header gradually emerged
in 2009 and 2010 as a simpler alternative. Every HTTP request by which
a user’s browser asks a server for a webpage contains a series of headers
with information about the webpage requested and the browser. Do Not
Track would be one more. Thus, the user’s browser would send, as part
of its request, the header:
DNT: 1
The presence of such a header would signal to the website that the
user requests not to be tracked. Privacy advocates and technologists
worked to flesh out the header; privacy officials in the United States
and Europe endorsed it. The World Wide Web Consortium (W3C) formed a
public Tracking Protection Working Group with a charter to design a technical standard for Do Not Track.
Significantly, a W3C standard is not law. The legal effect of Do Not
Track will come from somewhere else. In Europe, it may be enforced directly on websites under existing data protection law. In the United States, legislation has been introduced in the House and Senate
that would have the Federal Trade Commission promulgate Do Not Track
regulations. Without legislative authority, the FTC could not require
use of Do Not Track, but would be able to treat a website’s false claims
to honor Do Not Track as a deceptive trade practice. Since most online
advertising companies find it important from a public relations point
of view to be able to say that they support consumer choice, this last
option may be significant in practice. And finally, in an important recent paper,
Joshua Fairfield argues that use of the Do Not Track header itself
creates an enforceable contract prohibiting tracking under United States
law.
In all of these cases, the details of the Do Not Track standard will
be highly significant. Websites’ legal duties are likely to depend on
the technical duties specified in the standard, or at least be strongly
influenced by them. For example, a company that promises to be Do Not
Track compliant thereby promises to do what is required to comply with
the standard. If the standard ultimately allows for limited forms of
tracking for click-fraud prevention, the company can engage in those
forms of tracking even if the user sets the header. If not, it cannot.
Thus, there is a lot at stake in the Working Group’s discussions.
Internet Explorer and Defaults
On May 31, Microsoft announced that Do Not Track would be on by default
in Internet Explorer 10. This is a valuable feature, regardless of how
you feel about behavioral ad targeting itself. A recurring theme of
the online privacy wars is that unusably complicated privacy interfaces
confuse users in ways that cause them to make mistakes and undercut
their privacy. A default is the ultimate easy-to-use privacy control.
Users who care about what websites know about them do not need to
understand the details to take a simple step to protect themselves.
Using Internet Explorer would suffice by itself to prevent tracking from
a significant number of websites.
This is an important principle. Technology can empower users to
protect their privacy. It is impractical, indeed impossible, for users
to make detailed privacy choices about every last detail of their online
activities. The task of getting your privacy right is profoundly
easier if you have access to good tools to manage the details.
Antivirus companies compete vigorously to manage the details of malware
prevention for users. So too with privacy: we need thriving markets in
tools under the control of users to manage the details.
There is immense value if users can delegate some of their privacy
decisions to software agents. These delegation decisions should be dead
simple wherever possible. I use Ghostery
to block cookies. As tools go, it is incredibly easy to use—but it
still is not easy enough. The choice of browser is a simple choice, one
that every user makes. That choice alone should be enough to count as
an indication of a desire for privacy. Setting Do Not Track by default
is Microsoft’s offer to users. If they dislike the setting, they can
change it, or use a different browser.
The Pushback
Microsoft’s move intersected with a long-simmering discussion on the
Tracking Protection Working Group’s mailing list. The question of Do
Not Track defaults had been one of the first issues the Working Group raised when it launched in September 2011. The draft text that emerged by the spring remains painfully ambiguous on the issue. Indeed, the group’s May 30 teleconference—the
day before Microsoft’s announcement—showed substantial disagreement
about defaults and what a server could do if it believed it was seeing a
default Do Not Track header, rather than one explicitly set by the
user. Antivirus software AVG includes a cookie-blocking tool
that sets the Do Not Track header, which sparked extensive discussion
about plugins, conflicting settings, and explicit consent. And the last
few weeks following Microsoft’s announcement have seen a renewed debate
over defaults.
Many industry participants object to Do Not Track by default.
Technology companies with advertising networks have pushed for a crucial
pair of positions:
- User agents (i.e. browsers and apps) that turned on Do Not Track by default would be deemed non-compliant with the standard.
- Websites that received a request from a noncompliant user agent would be free to disregard a DNT: 1 header.
This position has been endorsed by representatives the three
companies I mentioned in my testimony today: Yahoo!, Google, and Adobe.
Thus, here is an excerpt from an email to the list by Shane Wiley from Yahoo!:
If you know that an UA is non-compliant, it should be fair to NOT
honor the DNT signal from that non-compliant UA and message this back to
the user in the well-known URI or Response Header.
Here is an excerpt from an email to the list by Ian Fette from Google:
There’s other people in the working group, myself included, who feel that
since you are under no obligation to honor DNT in the first place (it is
voluntary and nothing is binding until you tell the user “Yes, I am
honoring your DNT request”) that you already have an option to reject a
DNT:1 request (for instance, by sending no DNT response headers). The
question in my mind is whether we should provide websites with a mechanism
to provide more information as to why they are rejecting your request, e.g.
“You’re using a user agent that sets a DNT setting by default and thus I
have no idea if this is actually your preference or merely another large
corporation’s preference being presented on your behalf.”
And here is an excerpt from an email to the list by Roy Fielding from Adobe:
The server would say that the non-compliant browser is broken and
thus incapable of transmitting a true signal of the user’s preferences.
Hence, it will ignore DNT from that browser, though it may provide
other means to control its own tracking. The user’s actions are
irrelevant until they choose a browser capable of communicating
correctly or make use of some means other than DNT.
Pause here to understand the practical implications of writing this
position into the standard. If Yahoo! decides that Internet Explorer 10
is noncompliant because it defaults on, then users who picked Internet
Explorer 10 to avoid being tracked … will be tracked. Yahoo! will claim
that it is in compliance with the standard and Internet Explorer 10 is
not. Indeed, there is very little that an Internet Explorer 10 user
could do to avoid being tracked. Because her user agent is now flagged
by Yahoo! as noncompliant, even if she manually sets the header herself,
it will still be ignored.
The Problem
A cynic might observe how effectively this tactic neutralizes the
most serious threat that Do Not Track poses to advertisers: that people
might actually use it. Manual opt-out cookies are tolerable
because almost no one uses them. Even Do Not Track headers that are off
by default are tolerable because very few people will use them.
Microsoft’s and AVG’s decisions raise the possibility that significant
numbers of web users would be removed from tracking. Pleasing user
agent noncompliance is a bit of jujitsu, a way of meeting the threat
where it is strongest. The very thing that would make Internet Explorer
10’s Do Not Track setting widely used would be the very thing to
“justify” ignoring it.
But once websites have an excuse to look beyond the header they
receive, Do Not Track is dead as a practical matter. A DNT:1 header is
binary: it is present or it is not. But second-guessing interface
decisions is a completely open-ended question. Was the check box to
enable Do Not Track worded clearly? Was it bundled with some other user
preference? Might the header have been set by a corporate network
rather than the user? These are the kind of process questions that can
be lawyered to death. Being able to question whether a user really meant her Do Not Track header is a license to ignore what she does mean.
Return to my point above about tools. I run a browser with multiple
plugins. At the end of the day, these pieces of software collaborate to
set a Do Not Track header, or not. This setting is under my control: I
can install or uninstall any of the software that was responsible for
it. The choice of header is strictly between me and my user agent. As far as the Do Not Track specification is concerned,
websites should adhere to a presumption of user competence: whatever
value the header has, it has with the tacit or explicit consent of the
user.
Websites are not helpless against misconfigured software. If they
really think the user has lost control over her own computer, they have a
straightforward, simple way of finding out. A website can display a
popup window or an overlay, asking the user whether she really wants to
enable Do Not Track, and explaining the benefits disabling it would
offer. Websites have every opportunity to press their case for
tracking; if that case is as persuasive as they claim, they should have
no fear of making it one-on-one to users.
This brings me to the bitterest irony of Do Not Track defaults. For
more than a decade, the online advertising industry has insisted that
notice and an opportunity to opt out is sufficient choice for consumers.
It has fought long and hard against any kind of heightened consent
requirement for any of its practices. Opt-out, in short, is good
enough. But for Do Not Track, there and there alone, consumers
allegedly do not understand the issues, so consent must be explicit—and opt-in only.
Now What?
It is time for the participants in the Tracking Protection Working
Group to take a long, hard look at where the process is going. It is
time for the rest of us to tell them, loudly, that the process is going
awry. It is true that Do Not Track, at least in the present regulatory
environment, is voluntary. But it does not follow that the standard
should allow “compliant” websites to pick and choose which pieces to
comply with. The job of the standard is to spell out how a user agent
states a Do Not Track request, and what behavior is required of websites
that choose to implement the standard when they receive such a request.
That is, the standard must be based around a simple principle:
A Do Not Track header expresses a meaning, not a process.
The meaning of “DNT: 1” is that the receiving website should not
track the user, as spelled out in the rest of the standard. It is not
the website’s concern how the header came to be set.
No means no, and Do Not Track means Do Not Track.
Thursday, June 14. 2012
Via ZDNet
By Steven J. Vaughan-Nichols
-----
There’s no doubt about it. Android, especially Ice Cream Sandwich (ICS), version 4.0, already offers more than what is coming in Apple’s forthcoming iOS 6. But, Android has its own flaws.
True, as Tom Henderson, principal researcher for ExtremeLabs and a colleague, told me, there’s a “Schwarzschild
radius surrounding Apple. It’s not just a reality distortion field;
it’s a whole new dimension. Inside, time slows and light never escapes–
as time compresses to an amorphous mass.
“Coddled, stroked, and massaged,” Henderson continued, “Apple users
start to sincerely believe the distortions regarding the economic life,
the convenience, and the subtle beauties of their myriad products.
Unknowingly, they sacrifice their time, their money, their privacy, and
soon, their very souls. Comparing Apple with Android, the parallels to
Syria and North Korea come to mind, despot-led personality cults.”
I wouldn’t go that far. While I prefer Android, I can enjoy using iOS
devices as well. Besides, Android fans can be blind to its faults just
as much as the most besotted Apple fan.
For example, it’s true that ICS has all the features that iOS 6 will eventually have, but you can only find ICS on 7.1 percent of all currently running Android devices. Talk to any serious Android user, and you’ll soon hear complaints about how they can’t update their systems.
You name an Android vendor-HTC, Motorola, Samsung, etc. -and I can
find you a customer who can’t update their smartphone or tablet to the
latest and greatest version of the operating system. The techie Android
fanboy response to this problem is just “ROOT IT.” It’s not that easy.
First, the vast majority of Android users are as about as able to
root their smartphone as I am to run a marathon. Second, alternative
Android device firmwares don’t always work with every device. Even the
best of them, Cyanogen ICS, can have trouble with some devices.
Besides, while Cyanogen supports many smartphones and tablets, it doesn’t support all of them.
For example, there’s still no stable CyanogenMod 7 (Android 3.x) firmware for Barnes & Noble’s Nook Tablet. Sometimes even when there is support, such as there is for the popular Samsung Galaxy Tab 10.1, there are driver troubles that keep the camera from working for many users.
Another issue is consistency. When you buy an iPhone or an iPad you
know exactly what the interface is going to work and look like. With
Android devices, you never know quite what you’re going to get. We talk
about ICS as if it’s one thing-and it is from a developer’s
viewpoint-but ICS on different phones such as the HTC One X doesn’t look or feel much like say the Samsung Galaxy S III.
A related issue is that the iOS interface is simply cleaner and more
user-friendly than any Android interface I’d yet to see. One of Apple’s
slogans is “It just works.” Well, actually sometimes it doesn’t work.
ITunes, for example, has been annoying me for years now. But, when it
comes to device interfaces, iOS does just work. Android implementations,
far too often, doesn’t.
So, yes, Android does more today than Apple’s iOS promises to do
tomorrow, but that’s only part of the story. The full story includes
that iOS is very polished and very closed, while Android is somewhat
messy and very open. To me, it’s that last bit-that Apple is purely
proprietary while Android is largely open source-based-that insures that
I’m going to continue to use Android devices.
Now, if only Google can get everyone on the same page with updates and the interface, I’ll be perfectly happy!
Monday, June 04. 2012
Via LinuxInsider
-----
Bigger may be better if you're from Texas, but
it's becoming increasingly clear to the rest of us that it really is a
small world after all.
Case in point? None other than what one might reasonably call the invasion of tiny Linux PCs going on all around us.
We've got the Raspberry Pi,
we've got the Cotton Candy. Add to those the
Mele A1000, the
VIA APC, the
MK802 and more, and it's becoming increasingly difficult not to compute like a Lilliputian.
Where's it all going? That's what Linux bloggers have been pondering
in recent days. Down at the seedy Broken Windows Lounge the other night,
Linux Girl got an earful.
It's 'Fantastic'
"Linux has been heading towards one place for many years now: complete and total world domination!" quipped
Thoughts on Technology blogger and
Bodhi Linux lead developer Jeff Hoogland.
"All joking aside, these new devices simply further showcase Linux's
unmatched ability to be flexible across an array of different devices of
all sizes and power," Hoogland added.
"Having a slew of devices that are powerful enough for users to
browse the web -- which, let's be honest, is all a good deal of people
do these days -- for under 100 USD is fantastic," he concluded.
'It Only Gets More Exciting'
Similarly, "I believe that the medley of tiny Linux PCs we're seeing
hitting the market lately is the true sign of the Post PC Era,"
suggested Google+ blogger
Linux Rants.
"The smartphone started it, but the Post PC Era will begin in earnest
when the functionality that we currently see in the home computer is
replaced by numerous small appliance-type devices," Linux Rants
explained. "These tiny Linux PCs are the harbinger of those appliances
-- small, low-cost, programmable devices that can be made into virtually
anything the owner desires."
Other devices we're already seeing include "the oven that you can
turn on with a text message, the espresso machine that you can control
with a text message, home security  systems and cars that can be controlled from your smartphone," he
added. "This is where the Post PC Era begins, and it only gets more
exciting from here."
systems and cars that can be controlled from your smartphone," he
added. "This is where the Post PC Era begins, and it only gets more
exciting from here."
'There Is No Reason Not to Do It'
This is "definitely the wave of the future," agreed Google+ blogger Kevin O'Brien.
"Devices of all kinds are getting smaller and smaller, while
simultaneously increasing their power," O'Brien explained. "Exponential
growth does that over time.
"My phone in my pocket right now has more computing power than the
rockets that went to the moon," he added. "And if you look ahead, a few
more turns of exponential growth means we'll have the equivalent of a
full desktop computer the size of an SD card within a few years."
At that point, "everything starts to be computerized, because adding a
little intelligence is so cheap there is no reason not to do it,"
O'Brien concluded.
'We're Approaching That Future'
Indeed, "many including myself have long been harping on the fact that
today's computers are orders of magnitude faster than early systems on
which we ran graphic interfaces and got work done, and yet are dismissed
as toys,"
Hyperlogos blogger Martin Espinoza told Linux Girl.
"A friend suggested to me once that eventually microwave ovens would
contain little Unix servers 'on a chip' because that would be basically
all you could get, because it would actually be cheaperto use
such a system when given the cost of developing an alternative," he
said. "Seeing the cost of these new products it looks to me like we're
approaching that future rapidly.
"There has always been demand for low-cost computers, and the massive
proliferation of low-cost, low-power cores has pushed their price down
to the point where we can finally have them," Espinoza concluded.
"Even adjusted for inflation," he said, "many of these computers are
an order of magnitude cheaper than the cheapest useful home computers
from the time when personal computing began to gain popularity, and yet
they are certainly powerful enough to serve many roles including many
people's main or even only 'computer.'"
'It Gives Me Hope'
Consultant and Slashdot blogger Gerhard Mack was similarly enthusiastic.
"I love it," Mack told Linux Girl.
"When I was a child, my parents brought home all sorts of fun things
to tinker with, and I learned while doing it," he explained. "But these
last few years it seems like the learning electronics and their
equivalents have disappeared into a mass of products that are only for
what the manufacturer designed them for and nothing else.
"I am loving the return of my ability to tinker," Mack concluded. "It
gives me hope that there can be a next generation of kids who can love
the enjoyment of simply creating things."
'They Look a Bit Expensive'
Not everyone was thrilled, however.
"Okay, I am not all that excited about the invasion of the tiny PC," admitted Roberto Lim, a lawyer and blogger on
Mobile Raptor.
"With 7-inch Android tablets with capacitive displays, running
Android 4.0 and with access to Google (Nasdaq: GOOG) Play's Android app
market, 8 GB or storage expandable via a Micro SD card, 1080p video
playback, a USB port and HDMI out and 3000 to 4000 mAh batteries starting at US$90, it is a bit hard to get excited about these tiny PCs," Lim explained.
"Despite the low prices of the tiny PCs, they all look a bit
expensive when compared to what is already in the market," he opined.
'These Devices Have a Niche'
The category really isn't even all that new, Slashdot blogger hairyfeet opined.
"There have been mini ARM-based Linux boxes for several years now,"
he explained. "From portable media players to routers to set-top boxes,
there are a ton of little bitty boxes running embedded Linux."
It's not even quite right to call such devices PCs "because PC has an
already well-defined meaning: it was originally 'IBM PC compatible,'"
hairyfeet added. "Even if you give them the benefit of the doubt, PCs
have always been general use computers, and these things are FAR from
general use."
Rather, "they are designed with a very specific and narrow job in
mind," he said. "Trying to use them as general computers would just be
painful."
So, "in the end these devices have a niche, just as routers and
beagleboards and the pi does, but that niche is NOT general purpose in
any way, shape, or form," hairyfeet concluded.
'Opportunities for Specialists'
Chris Travers, a Slashdot blogger who works on the Ledger SMB project,
considered the question through the lens of evolutionary ecology.
"In any ecological system an expanding niche allows for
differentiation, and a contracting niche requires specialization,"
Travers pointed out. 'So, for example, if a species of moth undergoes a
population explosion, predators of that moth will often specialize and
be more picky as to what prey they go after."
The same thing happens with markets, Travers suggested.
"When a market expands, it provides opportunities for specialists,
but when it contracts, only the generalists can survive," he told Linux
Girl.
'Niche Environments'
The tiny new devices are "replacements for desktop and laptop systems in niche environments," Travers opined.
"In many environments these may be far more capable than traditional systems," he added.
The bottom line, though, "is that the Linux market is growing at a healthy rate," Travers concluded.
'The Right Way to Do IT'
"Moore's Law allows the world to do more with less hardware and so does FLOSS," blogger
Robert Pogson told Linux Girl. "It's the right way to do IT rather than paying a bunch for the privilege of running the hardware we own."
Last year was a turning point, Pogson added.
"More people bought small, cheap computers running Linux than that
other OS, and the world saw that things were fine without Wintel," he
explained. "2012 will bring more of the same." By the end of this year, in fact, "the use of GNU/Linux on small
cheap computers doing what we used to do with huge hair-drying Wintel
PCs will be mainstream in many places on Earth," Pogson predicted. "In
2012 we will see a major decline in the number of PCs running that other
OS. We will see major shelf-space given to Linux PCs at retail."
Monday, May 14. 2012
Via ReadWrite
----- 
Last September, during the f8 Developers’ Conference, Facebook CTO Bret Taylor said that the company had no plans for a “central app repository” – an app store. Today, Facebook is changing its tune. The social giant has announced App Center,
a section of Facebook dedicated to discovering and deploying
high-quality apps on the company’s platform. The App Center will push
apps to iPhone, Android and the mobile Web, giving Facebook its first
true store for mobile app discovery.
The departure from Facebook’s previous company line
comes as the social platform ramps up its mobile offerings to make money
from its hundreds of millions of mobile users. This is not your
father's app store, though.
Let's start with the requirements. Facebook has announced a strict
set of style and quality guidelines to get apps placed in App
Center. Apps that are considered high-quality, as decided by Facebook’s
Insights analytics platform, will get prominent placement. Quality is
determined by user ratings and app engagement. Apps that receive poor
ratings or do not meet Facebook’s quality guidelines won't be listed.
Whether or not an app is a potential Facebook App Center candidate hinges on several factors. It must
• have a canvas page (a page that sets the app's permissions on Facebook’s platform)
• be built for iOS, Android or the mobile Web
• use a Facebook Login or be a website that uses a Facebook Login.
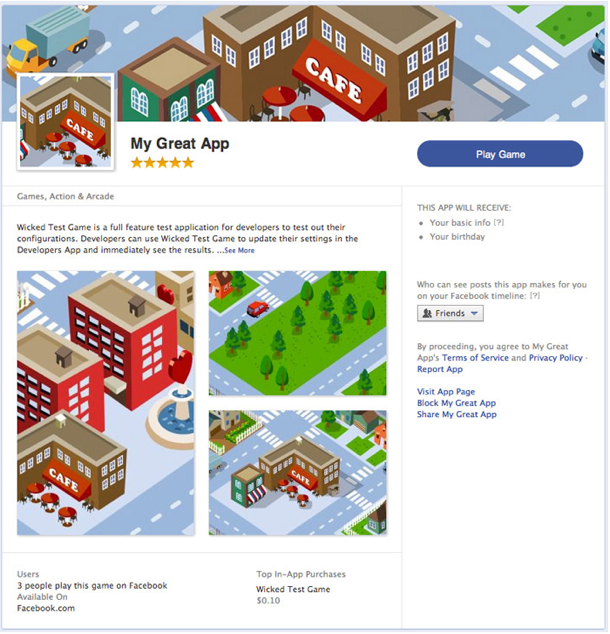
Facebook is in a tricky spot with App Center. It will house not only
apps that are specifically run through its platform but also iOS and
Android apps. Thus it needs to achieve a balance between competition and
cooperation with some of the most powerful forces in the tech universe.
If an app in App Center requires a download, the download link on the
app’s detail page will bring the user to the appropriate app repository,
either Apple's App Store or Android’s Google Play.
One of the more interesting parts of App Center is that Facebook will
allow paid apps. This is a huge move for Facebook as it provides a
boost to its Credits payment service. One of the benefits of having a
store is that whoever controls the store also controls transactions
arising from the items in it, whether payments per download or in-app
purchases. This will go a long way towards Facebook’s goal of monetizing
its mobile presence without relying on advertising.

Facebook App Center Icon Guidelines
Developers interested in publishing apps to Facebook’s App Center should take a look at both the guidelines and the tutorial
that outlines how to upload the appropriate icons, how to request
permissions, how to use Single Sign On (SSO, a requirement for App
Center) and the app detail page.
This is a good move for Facebook. It will give the company several
avenues to start making money off of mobile but also strengthen its
position as one of the backbones of the Web. For instance, App Center is
both separate from iOS and Android but also a part of it. Through App
Center, Facebook can direct traffic to its apps, monitor who and how
users are downloading applications and keep itself at the center of the
user experience.
Friday, May 11. 2012
Via makeuseof
-----
The cloud storage scene has heated up recently, with a long-awaited
entry by Google and a revamped SkyDrive from Microsoft. Dropbox has gone
unchallenged by the major players for a long time, but that’s changed –
both Google and Microsoft are now challenging Dropbox on its own turf,
and all three services have their own compelling features. One thing’s
for sure – Dropbox is no longer the one-size-fits-all solution.
These three aren’t the only cloud storage services – the cloud
storage arena is full of services with different features and
priorities, including privacy-protecting encryption and the ability to
synchronize any folder on your system.
Dropbox
introduced cloud storage to the masses, with its simple approach to
cloud storage and synchronization – a single magic folder that follows
you everywhere. Dropbox deserves credit for being a pioneer in this
space and the new Google Drive and SkyDrive both build on the foundation
that Dropbox laid.
Dropbox doesn’t have strong integration with any ecosystems – which
can be a good thing, as it is an ecosystem-agnostic approach that isn’t
tied to Google, Microsoft, Apple, or any other company’s platform.

Dropbox today is a compelling and mature offering supporting a wide
variety of platforms. Dropbox offers less free storage than the other
services (unless you get involved in their referral scheme) and its
prices are significantly higher than those of competing services – for
example, an extra 100GB is four times more expensive with Dropbox compared to Google Drive.
- Supported Platforms: Windows, Mac, Linux, Android, iOS, Blackberry, Web.
- Free Storage: 2 GB (up to 16 GB with referrals).
- Price for Additional Storage: 50 GB for $10/month, 100 GB for $20/month.
- File Size Limit: Unlimited.
- Standout Features: the Public folder is an easy way to share files.
Other services allow you to share files, but it isn’t quite as easy.
You can sync files from other computers running Dropbox over the local
network, speeding up transfers and taking a load off your Internet
connection.

Google Drive is the evolution of Google Docs,
which already allowed you to upload any file – Google Drive bumps the
storage space up from 1 GB to 5 GB, offers desktop sync clients, and
provides a new web interface and APIs for web app developers.
Google Drive is a serious entry from Google, not just an afterthought like the upload-any-file option was in Google Docs.

Its integration with third-party web apps – you can install apps and
associate them with file types in Google Drive – shows Google’s vision
of Google Drive being a web-based hard drive that eventually replaces
the need for desktop sync clients entirely.
- Supported Platforms: Windows, Mac, Android, Web, iOS (coming soon), Linux (coming soon).
- Free Storage: 5 GB.
- Price for Additional Storage: 25 GB for $2.49/month, 100 GB for $4.99/month.
- File Size Limit: 10 GB.
- Standout Features: Deep search with automatic OCR and image recognition, web interface that can launch files directly in third-party web apps.

You can actually purchase up to 16 TB of storage space with Google Drive – for $800/month!
Microsoft released a revamped SkyDrive
the day before Google Drive launched, but Google Drive stole its
thunder. Nevertheless, SkyDrive is now a compelling product,
particularly for people into Microsoft’s ecosystem of Office web apps, Windows Phone, and Windows 8, where it’s built into Metro by default.
Like Google with Google Drive, Microsoft’s new SkyDrive product imitates the magic folder pioneered by Dropbox.

Microsoft offers the most free storage space at 7 GB – although this is down from the original 25 GB. Microsoft also offers good prices for additional storage.
- Supported Platforms: Windows, Mac, Windows Phone, iOS, Web.
- Free Storage: 7 GB.
- Price for Additional Storage: 20 GB for $10/year, 50 GB for $25/year, 100 GB for $50/year
- File Size Limit: 2 GB
- Standout Features: Ability to fetch unsynced files from outside the synced folders on connected PCs, if they’ve been left on.

Other Services
SugarSync is a popular
alternative to Dropbox. It offers a free 5 GB of storage and it lets you
choose the folders you want to synchronize – a feature missing in the
above services, although you can use some tricks
to synchronize other folders. SugarSync also has clients for mobile
platforms that don’t get a lot of love, including Symbian, Windows
Mobile, and Blackberry (Dropbox also has a Blackberry client).

Amazon also offers their own cloud storage service, known as Amazon Cloud Drive.
There’s one big problem, though – there’s no official desktop sync
client. Expect Amazon to launch their own desktop sync program if
they’re serious about competing in this space. If you really want to use Amazon Cloud Drive, you can use a third-party application to access it from your desktop.

Box is popular, but its 25 MB file
size limit is extremely low. It also offers no desktop sync client
(except for businesses). While Box may be a good fit for the enterprise,
it can’t stand toe-to-toe with the other services here for consumer
cloud storage and syncing.
If you’re worried about the privacy of your data, you can use an encrypted service, such as SpiderOak or Wuala, instead. Or, if you prefer one of these services, use an app like BoxCryptor to encrypt files and store them on any cloud storage service.
Thursday, May 10. 2012
Via Christian Babski
-----

Remember your first time being sick in front of a screen!
Web Wolfenstein
Wednesday, May 02. 2012
Via Christian Babski
-----

The Internet is about (if it is not already a terminated task!) to become a pretty classical media. Country's boundaries were raised up on the net, making unavailable some contents depending on the world region you are browsing from (pretty weird, middle-age based concept of what the Internet must be)... We are now heavily targeted by many advertisements all around contents we are trying to access from the Web, pop-up blockers are now totally useless as advertisements took fairly advantage of HTML evolution. It is more and more difficult to ignore these advertisements, and even by closing them, one already produces/gives an information to Big Brother. There is less and less ways to escape, and by reading the following article, it looks like we are not supposed to escape... by the way. Responsive Advertising article
The opportunity to set up an alternative network (satellite based?) may be the only way to get a new [commercially virgin] web... Let's call it The Veb... underlying the need of a step back from where we are nowadays.
Tuesday, May 01. 2012
Via Christian Babski
-----

It looks like that Microsoft is about to propose the access to an operating system design to control your... home. The prototype seems to be accessible freely for non-commercial use.
Here is the abstract and a direct link to the research program's web page:
It is no secret that homes are ever-increasing
hotbeds of new technology such as set-top boxes, game consoles, wireless
routers, home automation devices, tablets, smart phones, and security
cameras. This innovation is breeding heterogeneity and complexity that
frustrates even technically-savvy users’ attempts to improve day-to-day
life by implementing functionality that uses these devices in
combination. For instance, it is impossible for most users to view video
captured by their security camera on their smartphone when they are not
at home. Heterogeneity across devices and across homes also makes it
difficult to develop applications that solve these problems in a way
that work across a range of homes.
To simplify the management of technology and to simplify the
development of applications in the home, we are developing an "operating
system" for the home. HomeOS provides a centralized, holistic control
of devices in the home. It provides to users intuitive controls to
manage their devices. It provided to developers high-level abstractions
to orchestrate the devices in the home. HomeOS is coupled with
a HomeStore through which users can easily add obtain applications that
are compatible with devices in their homes and obtain any additional
devices that are needed to enable desired applications.
HomeOS
|

