Entries tagged as programming
Tuesday, December 16. 2014
We’ve Put a Worm’s Mind in a Lego Robot's Body
Via Smithsonian
-----
If the brain is a collection of electrical signals, then, if you could catalog all those those signals digitally, you might be able upload your brain into a computer, thus achieving digital immortality.
While the plausibility—and ethics—of this upload for humans can be debated, some people are forging ahead in the field of whole-brain emulation. There are massive efforts to map the connectome—all the connections in the brain—and to understand how we think. Simulating brains could lead us to better robots and artificial intelligence, but the first steps need to be simple.
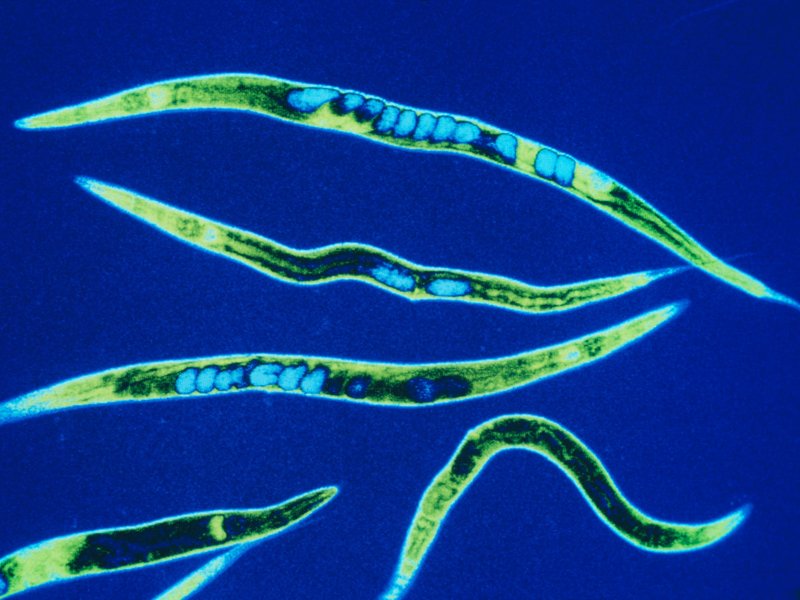
So, one group of scientists started with the roundworm Caenorhabditis elegans, a critter whose genes and simple nervous system we know intimately.
The OpenWorm project has mapped the connections between the worm’s 302 neurons and simulated them in software. (The project’s ultimate goal is to completely simulate C. elegans as a virtual organism.) Recently, they put that software program in a simple Lego robot.
The worm’s body parts and neural networks now have LegoBot equivalents: The worm’s nose neurons were replaced by a sonar sensor on the robot. The motor neurons running down both sides of the worm now correspond to motors on the left and right of the robot, explains Lucy Black for I Programmer. She writes:
---
It is claimed that the robot behaved in ways that are similar to observed C. elegans. Stimulation of the nose stopped forward motion. Touching the anterior and posterior touch sensors made the robot move forward and back accordingly. Stimulating the food sensor made the robot move forward.
---
Timothy Busbice, a founder for the OpenWorm project, posted a video of the Lego-Worm-Bot stopping and backing:
The simulation isn’t exact—the program has some simplifications on the thresholds needed to trigger a "neuron" firing, for example. But the behavior is impressive considering that no instructions were programmed into this robot. All it has is a network of connections mimicking those in the brain of a worm.
Of course, the goal of uploading our brains assumes that we aren’t already living in a computer simulation. Hear out the logic: Technologically advanced civilizations will eventually make simulations that are indistinguishable from reality. If that can happen, odds are it has. And if it has, there are probably billions of simulations making their own simulations. Work out that math, and "the odds are nearly infinity to one that we are all living in a computer simulation," writes Ed Grabianowski for io9.
Is your mind spinning yet?
Thursday, October 02. 2014
A Dating Site for Algorithms
-----
![]()
A startup called Algorithmia has a new twist on online matchmaking. Its website is a place for businesses with piles of data to find researchers with a dreamboat algorithm that could extract insights–and profits–from it all.
The aim is to make better use of the many algorithms that are developed in academia but then languish after being published in research papers, says cofounder Diego Oppenheimer. Many have the potential to help companies sort through and make sense of the data they collect from customers or on the Web at large. If Algorithmia makes a fruitful match, a researcher is paid a fee for the algorithm’s use, and the matchmaker takes a small cut. The site is currently in a private beta test with users including academics, students, and some businesses, but Oppenheimer says it already has some paying customers and should open to more users in a public test by the end of the year.
“Algorithms solve a problem. So when you have a collection of algorithms, you essentially have a collection of problem-solving things,” says Oppenheimer, who previously worked on data-analysis features for the Excel team at Microsoft.
Oppenheimer and cofounder Kenny Daniel, a former graduate student at USC who studied artificial intelligence, began working on the site full time late last year. The company raised $2.4 million in seed funding earlier this month from Madrona Venture Group and others, including angel investor Oren Etzioni, the CEO of the Allen Institute for Artificial Intelligence and a computer science professor at the University of Washington.
Etzioni says that many good ideas are essentially wasted in papers presented at computer science conferences and in journals. “Most of them have an algorithm and software associated with them, and the problem is very few people will find them and almost nobody will use them,” he says.
One reason is that academic papers are written for other academics, so people from industry can’t easily discover their ideas, says Etzioni. Even if a company does find an idea it likes, it takes time and money to interpret the academic write-up and turn it into something testable.
To change this, Algorithmia requires algorithms submitted to its site to use a standardized application programming interface that makes them easier to use and compare. Oppenheimer says some of the algorithms currently looking for love could be used for machine learning, extracting meaning from text, and planning routes within things like maps and video games.
Early users of the site have found algorithms to do jobs such as extracting data from receipts so they can be automatically categorized. Over time the company expects around 10 percent of users to contribute their own algorithms. Developers can decide whether they want to offer their algorithms free or set a price.
All algorithms on Algorithmia’s platform are live, Oppenheimer says, so users can immediately use them, see results, and try out other algorithms at the same time.
The site lets users vote and comment on the utility of different algorithms and shows how many times each has been used. Algorithmia encourages developers to let others see the code behind their algorithms so they can spot errors or ways to improve on their efficiency.
One potential challenge is that it’s not always clear who owns the intellectual property for an algorithm developed by a professor or graduate student at a university. Oppenheimer says it varies from school to school, though he notes that several make theirs open source. Algorithmia itself takes no ownership stake in the algorithms posted on the site.
Eventually, Etzioni believes, Algorithmia can go further than just matching up buyers and sellers as its collection of algorithms grows. He envisions it leading to a new, faster way to compose software, in which developers join together many different algorithms from the selection on offer.
Friday, September 05. 2014
The Internet of Things is here and there -- but not everywhere yet
Via PCWorld
-----

The Internet of Things is still too hard. Even some of its biggest backers say so.
For all the long-term optimism at the M2M Evolution conference this week in Las Vegas, many vendors and analysts are starkly realistic about how far the vaunted set of technologies for connected objects still has to go. IoT is already saving money for some enterprises and boosting revenue for others, but it hasn’t hit the mainstream yet. That’s partly because it’s too complicated to deploy, some say.
For now, implementations, market growth and standards are mostly concentrated in specific sectors, according to several participants at the conference who would love to see IoT span the world.
Cisco Systems has estimated IoT will generate $14.4 trillion in economic value between last year and 2022. But Kevin Shatzkamer, a distinguished systems architect at Cisco, called IoT a misnomer, for now.
“I think we’re pretty far from envisioning this as an Internet,” Shatzkamer said. “Today, what we have is lots of sets of intranets.” Within enterprises, it’s mostly individual business units deploying IoT, in a pattern that echoes the adoption of cloud computing, he said.
In the past, most of the networked machines in factories, energy grids and other settings have been linked using custom-built, often local networks based on proprietary technologies. IoT links those connected machines to the Internet and lets organizations combine those data streams with others. It’s also expected to foster an industry that’s more like the Internet, with horizontal layers of technology and multivendor ecosystems of products.
What’s holding back the Internet of Things
The good news is that cities, utilities, and companies are getting more familiar with IoT and looking to use it. The less good news is that they’re talking about limited IoT rollouts for specific purposes.
“You can’t sell a platform, because a platform doesn’t solve a problem. A vertical solution solves a problem,” Shatzkamer said. “We’re stuck at this impasse of working toward the horizontal while building the vertical.”
“We’re no longer able to just go in and sort of bluff our way through a technology discussion of what’s possible,” said Rick Lisa, Intel’s group sales director for Global M2M. “They want to know what you can do for me today that solves a problem.”
One of the most cited examples of IoT’s potential is the so-called connected city, where myriad sensors and cameras will track the movement of people and resources and generate data to make everything run more efficiently and openly. But now, the key is to get one municipal project up and running to prove it can be done, Lisa said.

ThroughTek, based in China, used a connected fan to demonstrate an Internet of Things device management system at the M2M Evolution conference in Las Vegas this week.
The conference drew stories of many successful projects: A system for tracking construction gear has caught numerous workers on camera walking off with equipment and led to prosecutions. Sensors in taxis detect unsafe driving maneuvers and alert the driver with a tone and a seat vibration, then report it to the taxi company. Major League Baseball is collecting gigabytes of data about every moment in a game, providing more information for fans and teams.
But for the mass market of small and medium-size enterprises that don’t have the resources to do a lot of custom development, even targeted IoT rollouts are too daunting, said analyst James Brehm, founder of James Brehm & Associates.
There are software platforms that pave over some of the complexity of making various devices and applications talk to each other, such as the Omega DevCloud, which RacoWireless introduced on Tuesday. The DevCloud lets developers write applications in the language they know and make those apps work on almost any type of device in the field, RacoWireless said. Thingworx, Xively and Gemalto also offer software platforms that do some of the work for users. But the various platforms on offer from IoT specialist companies are still too fragmented for most customers, Brehm said. There are too many types of platforms—for device activation, device management, application development, and more. “The solutions are too complex.”
He thinks that’s holding back the industry’s growth. Though the past few years have seen rapid adoption in certain industries in certain countries, sometimes promoted by governments—energy in the U.K., transportation in Brazil, security cameras in China—the IoT industry as a whole is only growing by about 35 percent per year, Brehm estimates. That’s a healthy pace, but not the steep “hockey stick” growth that has made other Internet-driven technologies ubiquitous, he said.
What lies ahead
Brehm thinks IoT is in a period where customers are waiting for more complete toolkits to implement it—essentially off-the-shelf products—and the industry hasn’t consolidated enough to deliver them. More companies have to merge, and it’s not clear when that will happen, he said.
“I thought we’d be out of it by now,” Brehm said. What’s hard about consolidation is partly what’s hard about adoption, in that IoT is a complex set of technologies, he said.
And don’t count on industry standards to simplify everything. IoT’s scope is so broad that there’s no way one standard could define any part of it, analysts said. The industry is evolving too quickly for traditional standards processes, which are often mired in industry politics, to keep up, according to Andy Castonguay, an analyst at IoT research firm Machina.
Instead, individual industries will set their own standards while software platforms such as Omega DevCloud help to solve the broader fragmentation, Castonguay believes. Even the Industrial Internet Consortium, formed earlier this year to bring some coherence to IoT for conservative industries such as energy and aviation, plans to work with existing standards from specific industries rather than write its own.
Ryan Martin, an analyst at 451 Research, compared IoT standards to human languages.
“I’d be hard pressed to say we are going to have one universal language that everyone in the world can speak,” and even if there were one, most people would also speak a more local language, Martin said.
Tuesday, May 13. 2014
How the police can trace photos back to your camera
Via ITProPortal
-----

Forensic experts have long been able to match a series of prints to the hand that left them, or a bullet to the gun that fired it. Now, the same thing is being done with the photos taken by digital cameras, and is ushering in a new era of digital crime fighting.
New technology is now allowing law enforcement officers to search through any collection of images to help track down the identity of photo-taking criminals, such as smartphone thieves and child pornographers.
Investigations in the past have shown that a digital photo can be paired with the exact same camera that took it, due to the patterns of Sensor Pattern Noise (SPN) imprinted on the photos by the camera's sensor.
Since each pattern is idiosyncratic, this allows law enforcement to "fingerprint" any photos taken. And once the signature has been identified, the police can track the criminal across the Internet, through social media and anywhere else they've kept photos.
Researchers have grabbed photos from Facebook, Flickr, Tumblr, Google+, and personal blogs to see whether one individual image could be matched to a specific user's account.
In a paper entitled "On the usage of Sensor Pattern Noise for Picture-to-Identity linking through social network accounts", the team argues that "digital imaging devices have gained an important role in everyone's life, due to a continuously decreasing price, and of the growing interest on photo sharing through social networks"
Friday, March 07. 2014
Scientists develop a lie detector for tweets
Via The Telegraph
-----

The Twitter logo displayed on a smart phone Photo: PA
Scientists have developed the ultimate lie detector for social media – a system that can tell whether a tweeter is telling the truth.
The creators of the system called Pheme, named after the Greek mythological figure known for scandalous rumour, say it can judge instantly between truth and fiction in 140 characters or less.
Researchers across Europe are joining forces to analyse the truthfulness of statements that appear on social media in “real time” and hope their system will prevent scurrilous rumours and false statements from taking hold, the Times reported.
The creators believe that the system would have proved useful to the police and authorities during the London Riots of 2011. Tweeters spread false reports that animals had been released from London Zoo and landmarks such as the London Eye and Selfridges had been set on fire, which caused panic and led to police being diverted.
Kalina Bontcheva, from the University of Sheffield’s engineering department, said that the system would be able to test information quickly and trace its origins. This would enable governments, emergency services, health agencies, journalists and companies to respond to falsehoods.
Tuesday, March 04. 2014
Should Students Be Able To Take Coding Classes For Language Credits?
Via Gizmodo
-----

The Kentucky Senate just passed a law that will let students take computer programming classes to satisfy their foreign language requirements. Do you think that's a good move?
What this new law means is, rather than taking three years of Spanish or French or whatever, kids can choose to learn to code. Sure, whether it's Java or German, they're both technically languages. But they're also two very different skills. You could easily argue that it's still very necessary for students to pick up a few years of a foreign tongue—though, on the other hand, coding is a skill that's probably a hell of a lot more practically applicable for today's high school students.
I, for one, have said countless times that if I could travel through time, I probably would have taken some computer science classes in college. Too late now, but not for Kentucky teenagers. So what do you think of this new law?
Image by Olly/Shutterstock
Wednesday, October 30. 2013
The Matterhorn like you've never seen it
Thursday, May 02. 2013
Driving Miss dAIsy: What Google’s self-driving cars see on the road
Via Slash Gear
-----
We’ve been hearing a lot about Google‘s self-driving car lately, and we’re all probably wanting to know how exactly the search giant is able to construct such a thing and drive itself without hitting anything or anyone. A new photo has surfaced that demonstrates what Google’s self-driving vehicles see while they’re out on the town, and it looks rather frightening.

The image was tweeted by Idealab founder Bill Gross, along with a claim that the self-driving car collects almost 1GB of data every second (yes, every second). This data includes imagery of the cars surroundings in order to effectively and safely navigate roads. The image shows that the car sees its surroundings through an infrared-like camera sensor, and it even can pick out people walking on the sidewalk.
Of course, 1GB of data every second isn’t too surprising when you consider that the car has to get a 360-degree image of its surroundings at all times. The image we see above even distinguishes different objects by color and shape. For instance, pedestrians are in bright green, cars are shaped like boxes, and the road is in dark blue.
However, we’re not sure where this photo came from, so it could simply be a rendering of someone’s idea of what Google’s self-driving car sees. Either way, Google says that we could see self-driving cars make their way to public roads in the next five years or so, which actually isn’t that far off, and Tesla Motors CEO Elon Musk is even interested in developing self-driving cars as well. However, they certainly don’t come without their problems, and we’re guessing that the first batch of self-driving cars probably won’t be in 100% tip-top shape.
Tuesday, March 19. 2013
Google Details Glass Mirror API At SXSW, Shows Off Gmail, NYT, Evernote And Path Integrations
Via TechCrunch
-----

At SXSW this afternoon, Google provided developers with a first glance at the Google Glass Mirror API, the main interface between Google Glass, Google’s servers and the apps that developers will write for them. In addition, Google showed off a first round of applications that work on Glass, including how Gmail works on the device, as well as integrations from companies like the New York Times, Evernote, Path and others.
The Mirror API is essentially a REST API, which should make developing for it very easy for most developers. The Glass device essentially talks to Google’s servers and the developers’ applications then get the data from there and also push it to Glass through Google’s APIs. All of this data is then presented on Glass through what Google calls “timeline cards.” These cards can include text, images, rich HTML and video. Besides single cards, Google also lets developers use what it calls bundles, which are basically sets of cards that users can navigate using their voice or the touchpad on the side of Glass.
It looks like sharing to Google+ is a built-in feature of the Mirror API, but as Google’s Timothy Jordan noted in today’s presentation, developers can always add their own sharing options, as well. Other built-in features seem to include voice recognition, access to the camera and a text-to-speech engine.
Glass Rules
Because Glass is a new and unique form factor, Jordan also noted, Google is setting a few rules for Glass apps. They shouldn’t, for example, show full news stories but only headlines, as everything else would be too distracting. For longer stories, developers can always just use Glass to read text to users.
Essentially, developers should make sure that they don’t annoy users with too many notifications, and the data they send to Glass should always be relevant. Developers should also make sure that everything that happens on Glass should be something the user expects, said Jordan. Glass isn’t the kind of device, he said, where a push notification about an update to your app makes sense.
Using Glass With Gmail, Evernote, Path and Others

As part of today’s presentation, Jordan also detailed some Glass apps Google has been working on itself, and apps that some of its partners have created. The New York Times app, for example, shows headlines and then lets you listen to a summary of the article by telling Glass to “read aloud.” Google’s own Gmail app uses voice recognition to answer emails (and it obviously shows you incoming mail, as well). Evernote’s Skitch can be used to take and share photos, and Jordan also showed a demo of social network Path running on Glass to share your location.
So far, there is no additional information about the Mirror API on any of Google’s usual sites, but we expect the company to release more information shortly and will update this post once we hear more.
Wednesday, January 09. 2013
Starting An Open-Source Project
-----
At Velocity 2011, Nicole Sullivan and I introduced CSS Lint, the first code-quality tool for CSS. We had spent the previous two weeks coding like crazy, trying to create an application that was both useful for end users and easy to modify. Neither of us had any experience launching an open-source project like this, and we learned a lot through the process.
After some initial missteps, the project finally hit a groove, and it now regularly get compliments from people using and contributing to CSS Lint. It’s actually not that hard to create a successful open-source project when you stop to think about your goals.
What Are Your Goals?
These days, it seems that anybody who writes a piece of code ends up pushing it to GitHub with an open-source license and says, “I’ve open-sourced it.” Creating an open-source project isn’t just about making your code freely available to others. So, before announcing to the world that you have open-sourced something that hasn’t been used by anyone other than you in your spare time, stop to ask yourself what your goals are for the project.
The first goal is always to create something useful. For CSS Lint, our goal was to create an extensible tool for CSS code quality that could easily fit into a developer’s workflow, whether the workflow is automated or not. Make sure that what you’re offering is useful by looking for others who are doing similar projects and figuring out how large of a user base you’re looking at.
After that, decide why you are open-sourcing the project in the first place. Is it because you just want to share what you’ve done? Do you intend to continue developing the code, or is this just a snapshot that you’re putting out into the world? If you have no intention of continuing to develop the code, then the rest of this article doesn’t apply to you. Make sure that the readme file in your repository states this clearly so that anyone who finds your project isn’t confused.
If you are going to continue developing the code, do you want to accept contributions from others? If not, then, once again, this article doesn’t apply to you. If yes, then you have some work to do. Creating an open-source project that’s conducive to outside contributions is more work than it seems. You have to create environments in which those who are unfamiliar with the project can get up to speed and be productive reasonably quickly, and that takes some planning.
This article is about starting an open-source project with these goals:
- Create something useful for the world.
- Continue to develop the code for the foreseeable future.
- Accept outside contributions.
Choosing A License
Before you share your code, the most important decision to make is what license to apply. The open-source license that you choose could greatly help or hurt your chances of attracting contributors. All licenses allow you to retain the copyright of the code you produce. While the concept of licensing is quite complex, there are a few common licenses and a few basic things you should know about each. (If you are open-sourcing a project on behalf of a company, please speak to your legal counsel before choosing a license.)
- GPL
The GNU Public License was created for the GNU project and has been credited with the rise of Linux as a viable operating system. The GPL license requires that any project using a GPL-licensed component must also be made available under the GPL. To put it simply, any project using a GPL-licensed component in any way must also be open-sourced under the GPL. There is no restriction on the use of GPL-licensed applications; the restriction only has to do with the modification and distribution of derived works. - LGPL
The Lesser GPL is a slightly more permissive version of GPL. An LGPL-licensed component may be linked to from an application without the application itself needing to be open-sourced under GPL or LGPL. In all other ways, LGPL is the same as GPL, so any derived works must also be open-sourced under GPL or LGPL. - MIT
Also called X11, this licence is permissive, allowing for the use and redistribution of code so long as the license and copyright are included along with it. MIT-licensed code may be included in proprietary code without any additional restrictions. Additionally, MIT-licensed code is GPL-compatible and can be combined with such code to create new GPL-licensed applications. - BSD3
This is also a permissive license that allows for the use and redistribution of code as long as the license and copyright are included with it. In addition, any redistribution of the code in binary form must include a license and copyright in its available documentation. The clause that sets BSD3 apart from MIT is the prohibition of using the copyright holder’s name to promote a product that uses the code. For example, if I wrote some code and licensed it under BSD3, then an application that uses that code couldn’t use my name to promote the product without my permission. BSD3-licensed code is also compatible with GPL.
There are many other open-source licenses, but these tend to be the most commonly discussed and used.
One thing to keep in mind is that Creative Commons licenses are not designed to be used with software. All of the Creative Commons licenses are intended for “creative work,” including audio, images, video and text. The Creative Commons organization itself recommends not using Creative Commons licenses for software and instead to use licenses that have been specifically formulated to cover software, as is the case with the four options discussed above.
So, which license should you choose? It largely depends on how you intend your code to be used. Because LGPL, MIT and BSD3 are all compatible with GPL, that’s not a major concern. If you want any modified versions of your code to be used only in open-source software, then GPL is the way to go. If your code is designed to be a standalone component that may be included in other applications without modification, then you might want to consider LGPL. Otherwise, the MIT or BSD3 licenses are popular choices. Individuals tend to favor the MIT license, while businesses tend to favor BSD3 to ensure that their company name can’t be used without permission.
To help you decide, look at how some popular open-source projects are licensed:
- jQuery: MIT license
- YUI: BSD3 license
- Dojo Toolkit: dual-licenced under BSD3 and Academic Free License
- Backbone: MIT license
Another option is to release your code into the public domain. Public-domain code has no copyright owner and may be used in absolutely any way. If you have no intention of maintaining control over your code or you just want to share your code with the world and not continue to develop it, then consider releasing it into the public domain.
To learn more about licenses, their associated legal issues and how licensing actually works, please read David Bushell’s “Understanding Copyright and Licenses.”
Code Organization
After deciding how to license your open-source project, it’s almost time to push your code out into the world. But before doing that, look at how the code is organized. Not all code invites contributions. If a potential contributor can’t figure out how to read through the code, then it’s highly unlikely any contribution will emerge. The way you lay out the code, in terms of file and directory structure as well as coding style, is a key aspect to consider before sharing it publicly. Don’t just throw out whatever code you have been writing into the wild; spend some time figuring out how others will view your code and what questions they might have.
For CSS Lint, we decided on a basic top-level directory structure of src for source code, lib for external dependencies, and tests for all test code. The src directory is further subdivided into directories that group together related files. All CSS Lint rules are in the rules subdirectory; all output formatters are in the formatters directory; etc. The tests directory is split up into the same subdirectories as src,
thereby indicating the relationship between the test code and the
source code. Over time, we’ve added top-level directories as needed, but
the same basic structure has been in place since the beginning.
Documentation
One of the biggest complaints about open-source projects is the lack of documentation. Documentation isn’t as fun or exciting as writing executable code, but it is critical to the success of an open-source project. The best way to discourage use of and contributions to your software is to have no documentation. This was an early mistake we made with CSS Lint. When the project launched, we had no documentation, and everyone was confused about how to use it. Don’t make the same mistake: get some documentation ready before pushing the project live.
The documentation should be easy to update and shouldn’t require a code push, because it will need to be changed very quickly in response to user feedback. This means that the best place for documentation isn’t in the same repository as the code. If your code is hosted on GitHub, then make use of the built-in wiki for each project. All of the CSS Lint documentation is in a GitHub wiki. If your code is hosted elsewhere, consider setting up your own wiki or a similar system that enables you to update the documentation in real time. A good documentation system must be easy to update, or else you will never update it.
End-User Documentation
Whether you’re creating a command-line program, an application framework, a utility library or anything else, keep the end user in mind. The end user is not the person who will be modifying the code; it’s the one who will be using the code. People were initially confused about CSS Lint’s purpose and how to use it effectively because of the lack of documentation. Your project will never gain contributors without first gaining end users. Satisfied end users are the ones who will end up becoming contributors because they see the value in what you’ve created.
Developer Guide
Even if you’ve laid out the code in a logical manner and have decent end-user documentation, contributions are not guaranteed to start flowing. You’ll need a developer guide to help get contributors up and running as quickly as possible. A good developer guide covers the following:
- How to get the source code
Yes, you would hope that contributors would be familiar with how to check out and clone a repository, but that’s not always the case. A gentle introduction to getting the source code is always appreciated. - How the code is laid out
Even though the code and directory structures should be fairly self-explanatory, writing down a description for posterity always helps. - How to set up the build system
If you are using a build system, then you’ll need to include instructions on how to set it up. These instructions should include where to get build-time dependencies that aren’t already included in the repository. - How to run a build
These are the steps necessary to run a development build and to execute unit tests. - How to contribute
Spell out the criteria for contributing to the project. If you require unit tests, then state that. If you require documentation, mention that as well. Give people a checklist of things to go over before submitting a contribution.
I spent a lot of time refining the “CSS Lint Developer Guide” based on conversations I had had with contributors and questions that others would ask. As with all documentation, the developer guide should be a living document that continues to grow as the project grows.
Use A Mailing List
All good open-source projects give people a place to go to ask questions, and the easiest way to achieve that is by setting up a mailing list. When we first launched CSS Lint, Nicole and I were inundated with questions. The problem is that those questions were coming in through many different channels. People were asking questions on Twitter as well as emailing each of us directly. That’s exactly the situation you don’t want.
Setting up a mailing list with Yahoo Groups or Google Groups is easy and free. Make sure to do that before announcing the project’s availability, and actively encourage people to use the mailing list to ask questions. Link to the mailing list prominently on the website (if you have one) or in the documentation.
The other important part of running a mailing list is to actively monitor it. Nothing is more frustrating for end users or contributors than being ignored. If you’ve set up a mailing list, take the time to monitor it and respond to people who ask questions. This is the best way to foster a community of developers around the project. Getting a decent amount of traffic onto the mailing list can take some time, but it’s worth the effort. Offer advice to people who want to contribute; suggest to people to file tickets when appropriate (don’t let the mailing list turn into a bug tracker!); and use the feedback you get from the mailing list to improve documentation.
Use Version Numbers
One common mistake made with open-source projects is neglecting to use version numbers. Version numbers are incredibly important for the long-term stability and maintenance of your project. CSS Lint didn’t use version numbers when it was first released, and I quickly realized the mistake. When bugs came in, I had no idea whether people were using the most recent version because there was no way for them to tell when the code was released. Bugs were being reported that had already been fixed, but there was no way for the end user to figure that out.
Stamping each release with an official version number puts a stake in the ground. When somebody files a bug, you can ask what version they are using and then check whether that bug has already been fixed. This greatly reduced the amount of time I spent with bug reports because I was able to quickly determine whether someone was using the most recent version.
Unless your project has been previously used and vetted, start the version number at 0.1.0 and go up incrementally with each release. With CSS Lint, we increased the second number for planned releases; so, 0.2.0 was the second planned release, 0.3.0 was the third and so on. If we needed to release a version in between planned releases in order to fix bugs, then we increased the third number. So, the second unplanned release after 0.2.0 was 0.2.2. Don’t get me wrong: there are no set rules on how to increase version numbers in a project, though there are a couple of resources worth looking at: Apache APR Versioning and Semantic Versioning. Just pick something and stick with it.
In addition to helping with tracking, version numbers do a number of other great things for your project.
Tag Versions in Source Control
When you decide on a new release, use a source-control tag to mark the state of the code for that release. I started doing this for CSS Lint as soon as we started using version numbers. I didn’t think much of it until the first time I forgot to tag a release and a bug was filed by someone looking for that tag. It turns out that developers like to check out particular versions of code.
Tie the tag obviously to the version number by including the version number directly in the tag’s name. With CSS Lint, our tags are in the format of “v0.9.9.” This will make it very easy for anyone looking through tags to figure out what those tags mean — including you, because you’ll be able to better keep track of what changes have been made in each release.
Change Logs
Another benefit of versioning is in producing change logs. Change logs are important for communicating version differences to both end users and contributors. The added benefit of tagging versions and source control is that you can automatically generate change logs based on those tags. CSS Lint’s build system automatically creates a change log for each release that includes not just the commit message but also the contributor. In this way, the change log becomes a record not only of code changes, but also of contributions from the community.
Availability Announcements
Whenever a new version of the project is available, announce its availability somewhere. Whether you do this on a blog or on the mailing list (or in both places), formally announcing that a new version is available is very important. The announcement should include any major changes made in the code, as well as who has contributed those changes. Contributors tend to contribute more if they get some recognition for their work, so reward the people who have taken the time to contribute to your project by acknowledging their contribution.
Managing Contributions
Once you have everything set up, the next step is to figure out how you will accept contributions. Your contribution model can be as informal or formal as you’d like, depending on your goals. For a personal project, you might not have any formal contribution process. The developer guide would lay out what is necessary in order for the code to be merged into the repository and would state that as long as a submission follows that format, then the contribution will be accepted. For a larger project, you might want to have a more formal policy.
The first thing to look into is whether you will require a contributor license agreement (CLA). CLAs are used in many large open-source projects to protect the legal rights of the project. Every person who submits code to the project would need to fill out a CLA certifying that any contributed code is original work and that the copyright for that work is being turned over to the project. CLAs also give the project owner license to use the contribution as part of the project, and it warrants that the contributor isn’t knowingly including code to which someone else has a copyright, patent or other right. jQuery, YUI and Dojo all require CLAs for code submissions. If you are considering requiring a CLA from contributors, then getting legal advice regarding it and your licensing structure would be worthwhile.
Next, you may want to establish a hierarchy of people working on the project. Open-source projects typically have three primary designations:
- Contributor
Anyone who has had source code merged into the repository is considered a contributor. The contributor cannot access the repository directly but has submitted patches that have been accepted. - Committer
People who have direct access to the repository are committers. These people work on features and fix bugs regularly, and they submit code directly to the repository. - Reviewer
The highest level of contributor, reviewers are commanders who also have directional impact on the project. Reviewers fulfill their title by reviewing submissions from contributors and committers, approving or denying patches, promoting or demoting committers, and generally running the project.
If you’re going to have a formal hierarchy such as this, you’ll need to draft a document that describes the role of each type of contributor and how one may be promoted through the ranks. YUI has just created a formal “Contributor Model,” along with excellent documentation on roles and responsibilities.
At the moment, CSS Lint doesn’t require a CLA and doesn’t have a formal contribution model in place, but everyone should consider it as their open-source project grows.
The Proof
It probably took us about six months from its initial release to get CSS Lint to the point of being a fully functioning open-source project. Since then, over a dozen contributors have submitted code that is now included in the project. While that number might seem small by the standard of a large open-source project, we take great pride in it. Getting one external contribution is easy; getting contributions over an extended period of time is difficult.
And we know that we’ve been doing something right because of the feedback we receive. Jonathan Klein recently took to the mailing list to ask some questions and ended up submitting a pull request that was accepted into the project. He then emailed me this feedback:
I just wanted to say that I think CSS Lint is a model open-source project — great documentation, easy to extend, clean code, fast replies on the mailing list and to pull requests, and easily customizable to fit any environment. Starting to do development on CSS Lint was as easy as reading a couple of wiki pages, and the fact that you explicitly called out the typical workflow of a change made the barrier to entry extremely low. I wish more open-source projects would follow suit and make it easy to contribute.
Getting emails like this has become commonplace for CSS Lint, and it can become the norm for your project, too, if you take the time to set up a sustainable eco-system. We all want our projects to succeed, and we want people to want to contribute to them. As Jonathan said, make the barrier to entry as low as possible and developers will find ways to help out.
Quicksearch
Popular Entries
- The great Ars Android interface shootout (131491)
- Norton cyber crime study offers striking revenue loss statistics (102349)
- MeCam $49 flying camera concept follows you around, streams video to your phone (100507)
- The PC inside your phone: A guide to the system-on-a-chip (58680)
- Norton cyber crime study offers striking revenue loss statistics (58578)
Categories

Show tagged entries
Syndicate This Blog
Calendar
|
|
July '26 | |||||
| Mon | Tue | Wed | Thu | Fri | Sat | Sun |
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 | ||